sort命令####排序
sort将文件的每一行作为一个单位相互比较,比较原则是从首字符向后依次按ASCII码进行比较,最后将它们按升序输出。(以行为单位来排序输出)
sort [选项] 参数
cat file | sort 选项
常用选项:
| 常用选项 | 作用 |
|---|---|
| -n | 按照数字进行排序(默认升序) |
| -r | 反向排序(倒序) |
| -u | 等同于uniq,表示相同的数据仅显示一行 |
| -t | 指定字段分隔符,默认使用Tab键分隔 |
| -k | 指定排序字段(不指定则默认第一个字段) |
| -f | 忽略大小写,会将小写字母都转换为大写字母来进行比较 |
| -b | 忽略每行前面的空格 |
| -o <输出文件> | 将排序后的结果转存到指定文件中 |
验证:
先准备一个文件,写一些数字
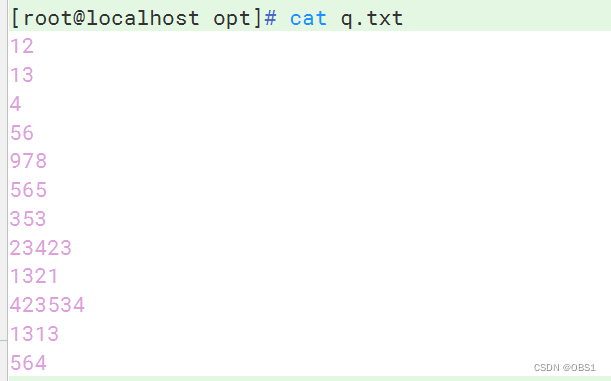
不加选项,默认按首字母排序
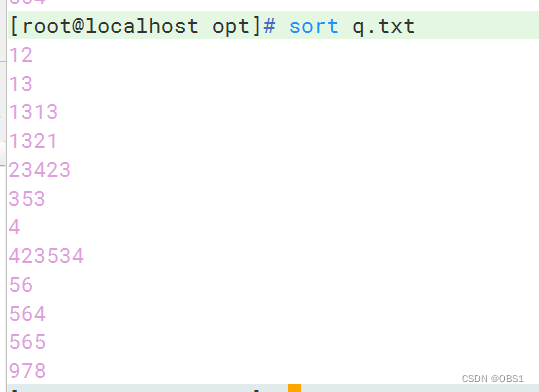
-n,按照数字排序(默认升序)
再追加-r降序排序
-t 指定分隔符, -k,指定对第几个字段进行排序
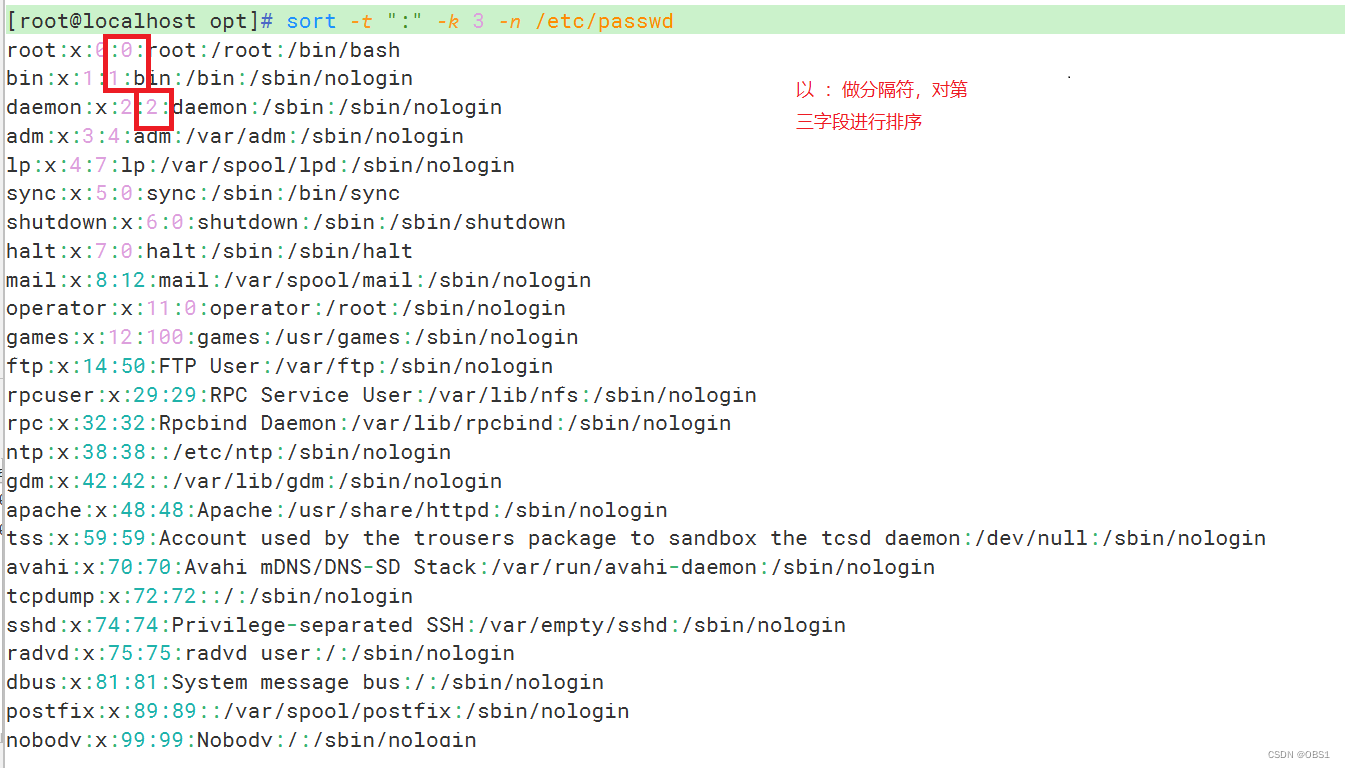
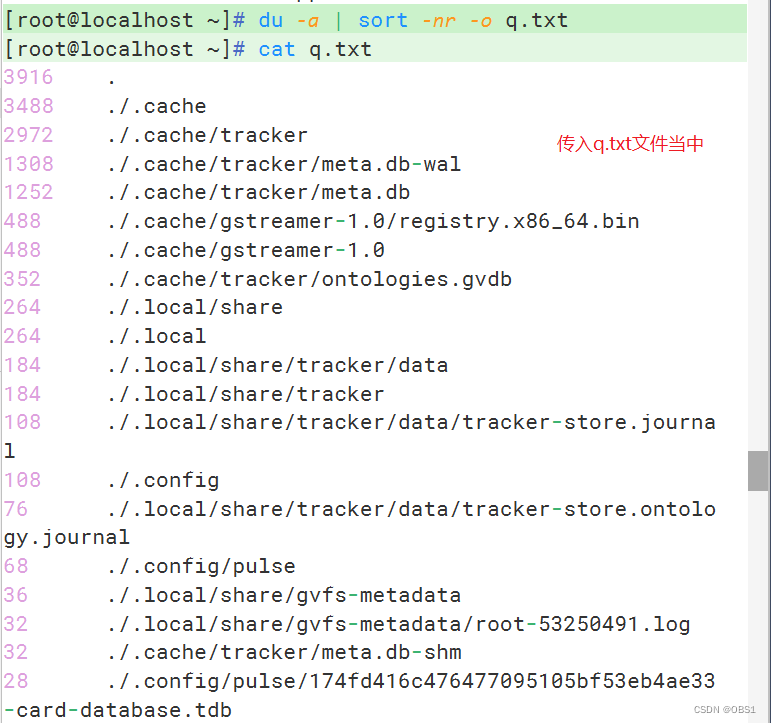
-o <输出文件> ,将排序后的结果转存到指定的文件中
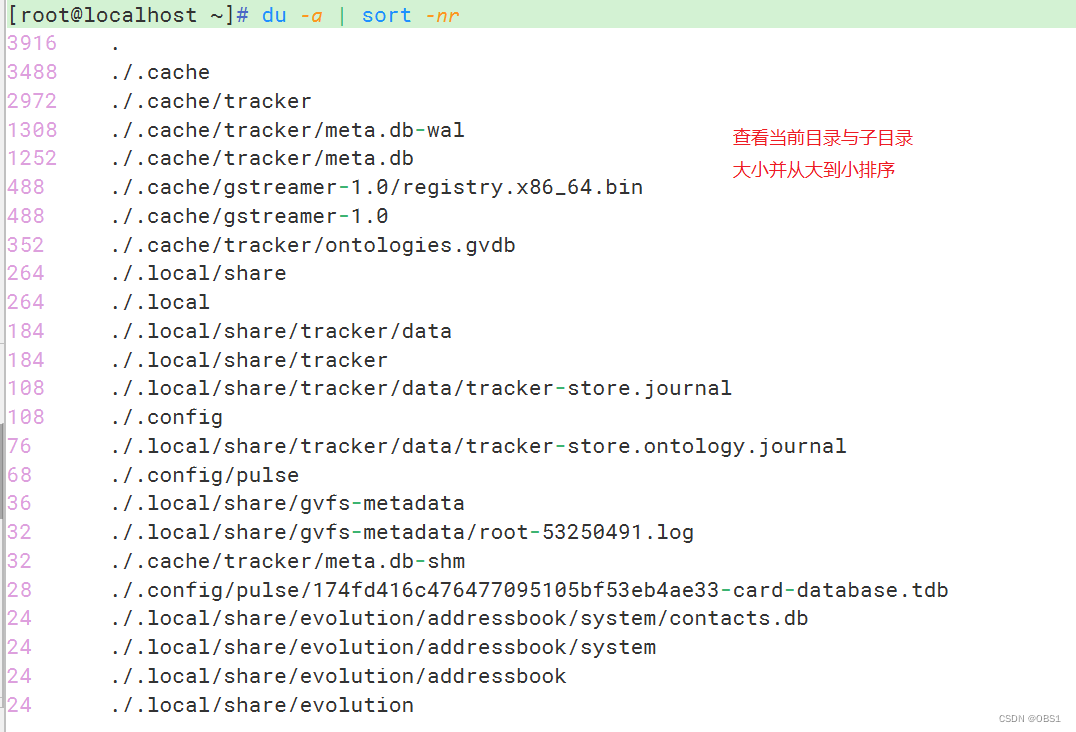
查看/data目录下所有子目录和文件占磁盘空间的大小(即查看目录的磁盘使用情况),按从大到小排序,之后将结果存入/du.txt文件中
uniq命令#####去重
uniq命令用于报告或者忽略文件中连续的重复行,常与sort命令结合使用
常用命令:
| 常用命令 | 作用 |
|---|---|
| -c | 统计连续重复的行的次数,并且合并重复的行 |
| -u | 显示仅出现一次的行(包括不连续的重复行) |
| -d | 仅显示重复出现的行(必须是连续的重复行 |
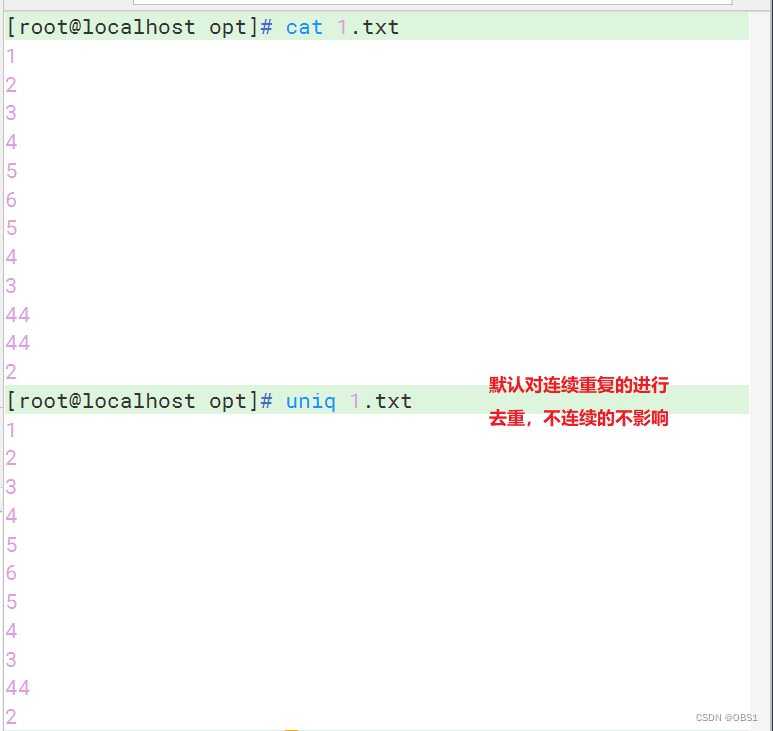
-c,显示连续重复行出现的次数,并合并重复行
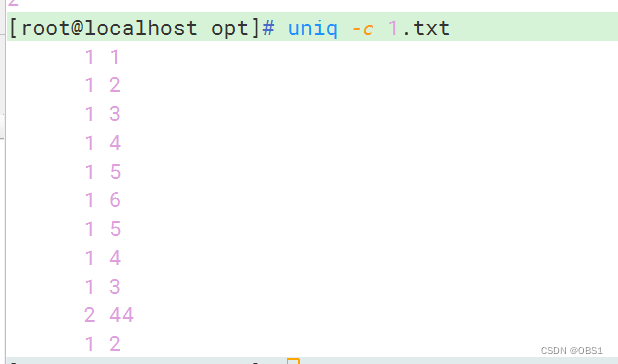
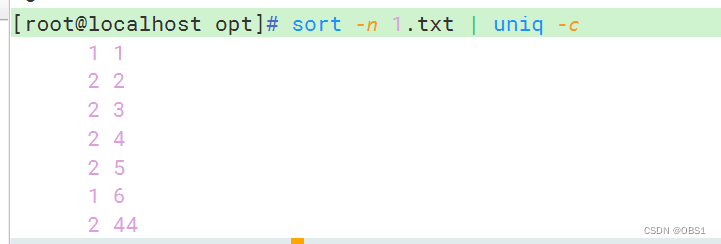
-c,与sort命令结合,统计重复出现的次数,包括不连续出现的
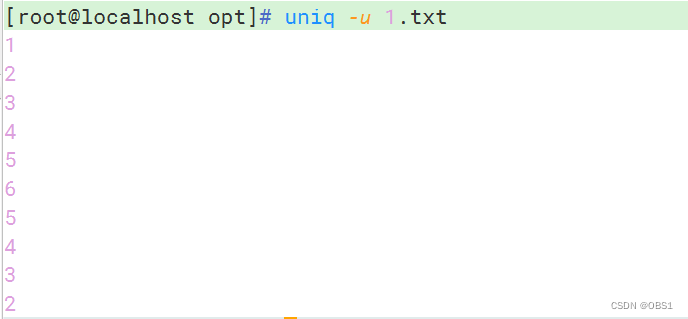
-u,显示仅出现过一次的行(包括不连续出现的行)
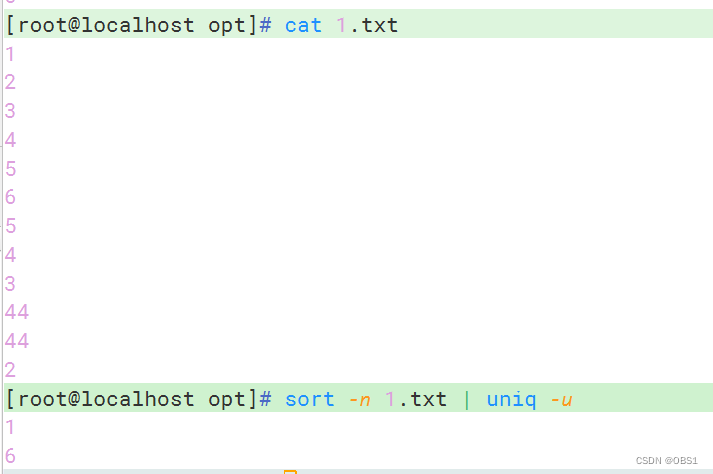
-u,与sort命令结合,显示真正仅出现过一次的行
tr命令#####删除、替换、压缩
常用命令:
| 命令 | 作用 |
|---|---|
| -c | 保留字符集1的字符,其他字符包括换行符\n用字符集2替换 |
| -d | 删除所有属于字符集1的字符 |
| -s | 将连续重复的字符串压缩成一个 |
| -t | 字符集2 替换 字符集1,不加选项效果相同 |
常用参数:
| 参数 | 说明 |
|---|---|
| 字符集1 | 指定要转换或删除的原字符集。当执行转换操作时,必须使用参数“字符集2”指定转换的目标字符集。但执行删除操作时,不需要参数“字符集2” |
| 字符集2 | 指定要转换成的目标字符集 |
tr命令的使用
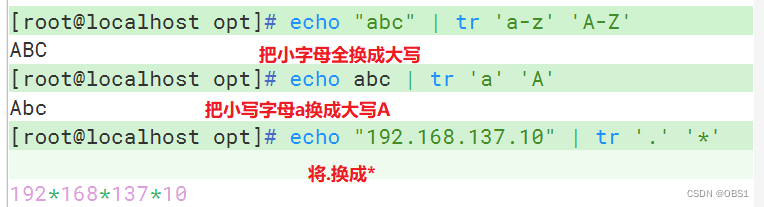

-c,保留字符集1的字符,其他字符包括换行符\n用字符集2替换

-d,删除所有属于字符集1的字符

-s,把连续重复的字符串压缩成一个

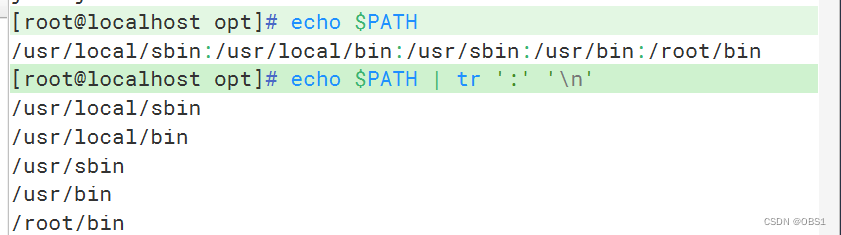
分行输出环境变量PATH中包含所有目录
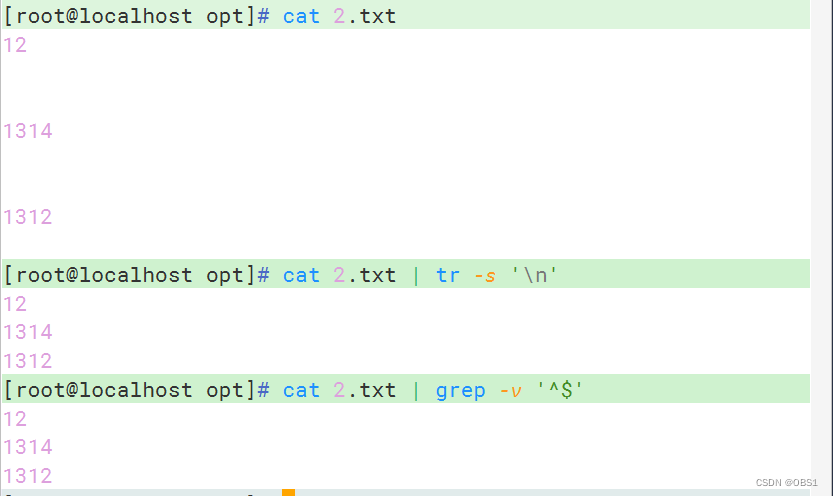
过滤文件中的非空行
cut命令####截取字段或字符串
用于显示行中的指定部分,删除文件中指定字
cut 参数
cat file | cut 选项| 命令 | 说明 |
| -b | 以字节为单位进行分割 ,仅显示行中指定直接范围的内容 |
| -d | 自定义分隔符,默认为制表符”TAB” |
| -f | 显示指定字段的内容 , 与-d一起使用 ( -指定连续字段 ,指定不连续字段) |
| -n | 取消分割多字节字符 |
| --complement | 排除所指定的字段 |
| --output-delimiter | 更改输出内容的分隔符 |
cut -d -f

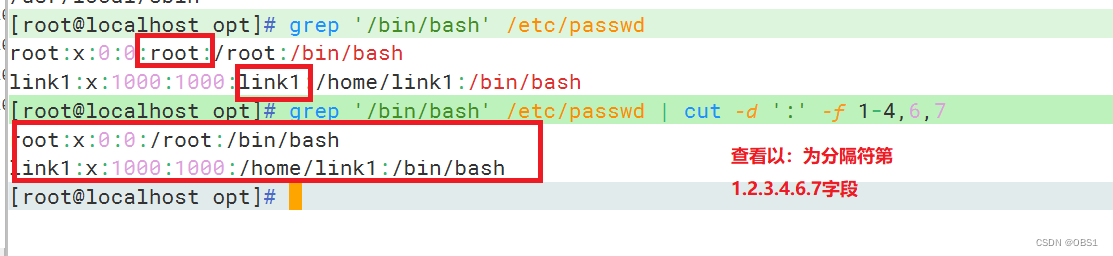
cut --complement:排除所指定的字段
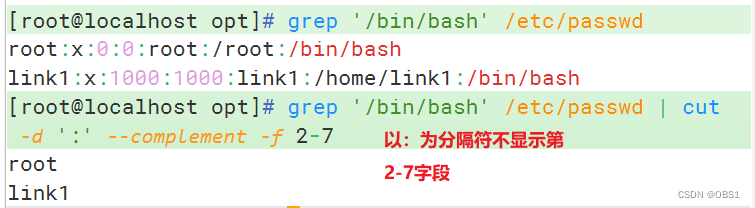
cut --output-delimiter:更改输出内容的分隔符
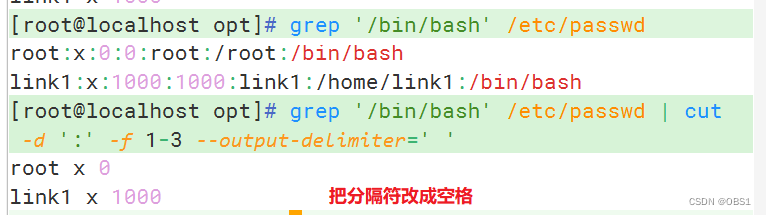
截取字符串
${i:0: 3} :下标从0开始:截取的字符长度
echo $i l cut -b 1-3 :下标从1开始起始位置-终止位置
expr substr $i 1 3 :下标从1开始 1代表起始位置3代表截取的字符长度

split命令####拆分文件
Linux下将一个大的文件拆分成若干个小文件
格式:
split 选项 参数 原始文件 拆分后文件名前缀
常用命令:
| 选项 | 作用 |
| -l | 以行数拆分 |
| -b | 以大小拆分 |

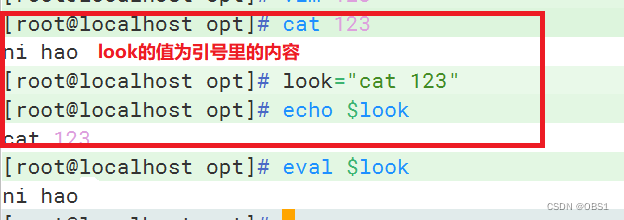
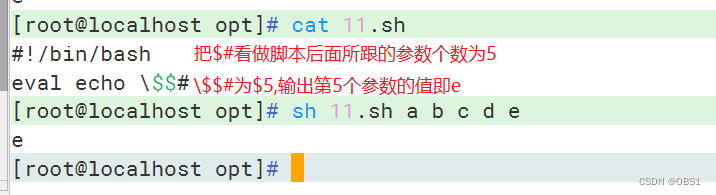
eval命令
命令字前加上eval时,shell会在执行命令之前扫描它两次。eval命令将首先会先扫描命令行进行所有的置换,然后再执行该命令。该命令适用于那些一次扫描无法实现其功能的变量。该命令对变量进行两次扫描







![[架构之路-167]-《软考-系统分析师》-4-据通信与计算机网络-3- 常见局域网与广域网](https://img-blog.csdnimg.cn/img_convert/50cbbe243a6580139ee4951c8573b843.png)