概念
学习的指标
如何得到所有学习数据的损失函数的总和
- 一个一个计算?
- 如果数据量大的话,费时费力
太难受了吧
从训练数据中获取小数据mini-batch
对每个小数据进行批量学习
首先读入mnist数据集
import numpy as np
# 实现从训练数据中随机选择指定个数的数据的代码
import os, sys
sys.path.append(os.pardir)
from dataset.mnist import load_mnist # 表示从dataset目录中的mnist.py文件中导入想要的东西
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
print(x_train.shape)
print(t_train.shape)
D:\ANACONDA\envs\pytorch\python.exe C:/Users/Administrator/Desktop/DeepLearning/ch04/wgw_test.py
(60000, 784)
(60000, 10)
Process finished with exit code 0
- 得到了训练数据的个数
- 训练输入的维数
- 28*28 784个
- 其实这个也就是输入层的神经元的个数
- t表示标签数据(监督数据)
- 是10维的
现在开始随机获取10个数据
使用numpy中的random函数来帮个忙
代码
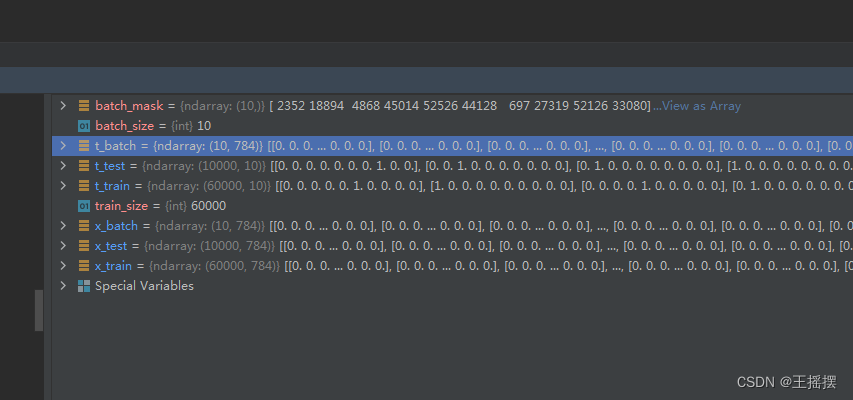
train_size = x_train.shape[0]
batch_size = 10
batch_mask = np.random.choice(train_size, batch_size) # choice函数返回的是ndarray类型的数据
# print(type(batch_mask))
x_batch=x_train[batch_mask]
t_batch=x_train[batch_mask]
相当于选取了一个随机数种子
- 得到的是种子的索引
- 然后根据索引在数组中拿到对应的值
结果
和电视台的收视率一样
- 通过随机选择的小批量数据作为全体训练数据的近似值
监督数据的理解
监督数据就是用来考察训练数据的呗
完整代码
import numpy as np
# 实现从训练数据中随机选择指定个数的数据的代码
import os, sys
sys.path.append(os.pardir)
from dataset.mnist import load_mnist # 表示从dataset目录中的mnist.py文件中导入想要的东西
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
# 让我来康康训练数据和监督数据的规模
# print(x_train.shape)
# print(t_train.shape)
train_size = x_train.shape[0]
batch_size = 10
batch_mask = np.random.choice(train_size, batch_size) # choice函数返回的是ndarray类型的数据
# print(type(batch_mask))
x_batch=x_train[batch_mask]
t_batch=x_train[batch_mask]