文章目录
- 工具查看内存分配
- Java内存模型
- 访问对象方式
- GC
- 为什么Survivor要分为两个区域(S0和S1)?
- Survivor 为什么不分更多块呢?
- 对象的生命周期
- 小知识
工具查看内存分配
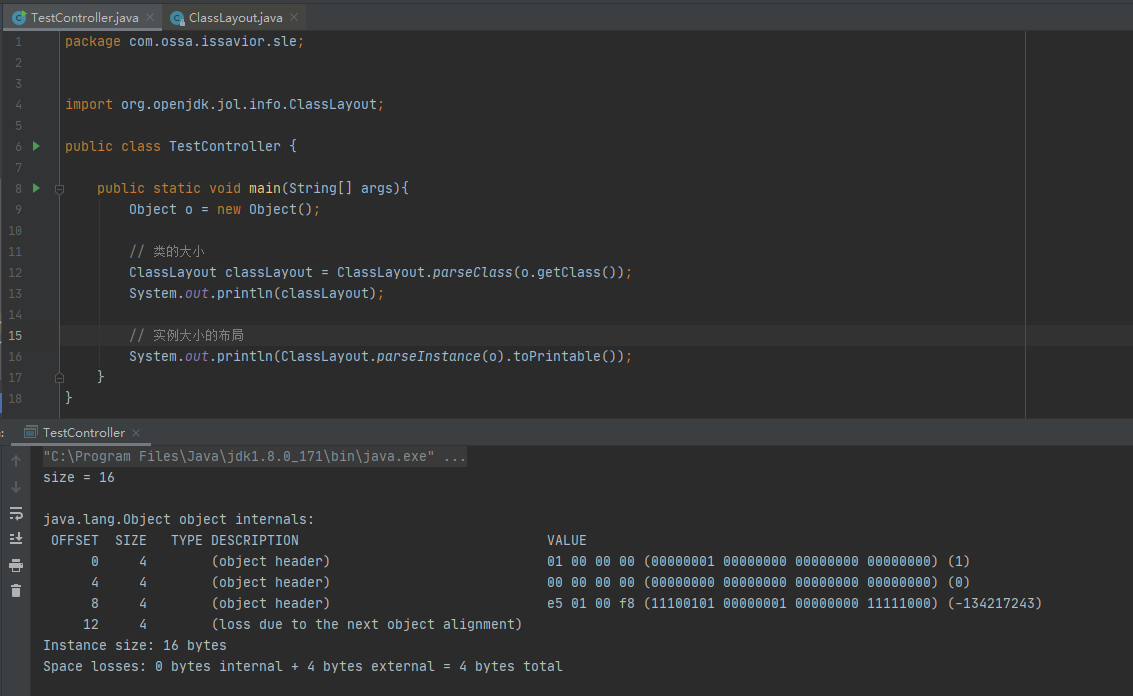
Object o = new Object();占用多少字节,我们借助openjdk的工具来看一下:
Maven依赖
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.10</version>
</dependency>
代码:
package com.ossa.issavior.sle;
import org.openjdk.jol.info.ClassLayout;
public class TestController {
public static void main(String[] args){
Object o = new Object();
// 类的大小
ClassLayout classLayout = ClassLayout.parseClass(o.getClass());
System.out.println(classLayout);
// 实例大小的布局
System.out.println(ClassLayout.parseInstance(o).toPrintable());
}
}
Java内存模型
可以看到new Object()占用16个字节,我们来看一下Java内存模型。

jvm默认是开启了指针压缩:
-XX:+UseCompressedOops 开启指针压缩
-XX:-UseCompressedOops 关闭指针压缩
压缩之后类型指针只占4个字节,否则占用8个字节。
访问对象方式
创建好一个对象之后,访问对象方式有两种:句柄访问和直接指针访问。
句柄访问:使用句柄访问的话,Java虚拟机会在堆内划分出一块内存来存储句柄池,那么对象当中存储的就是句柄地址,然后句柄池中才会存储对象实例数据和对象类型数据地址。
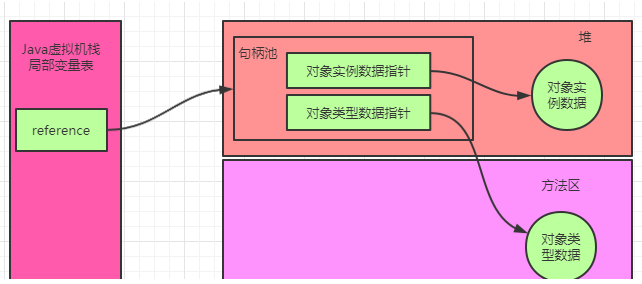
直接指针访问(Hot Spot虚拟机采用的方式): 直接指针访问的话对象中就会直接存储对象类型数据。
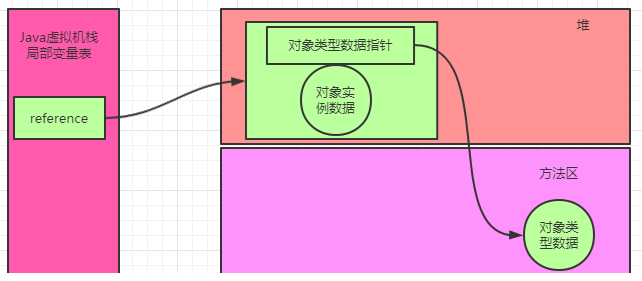
上面图形中我们很容易对比,就是如果使用句柄访问的时候,会多了一次指针定位,但是他也有一个好处就是,假如一个对象被移动(地址改变了),那么只需要改变句柄池的指向就可以了,不需要修改reference对象内的指向,而如果使用直接指针访问,就还需要到局部变量表内修改reference指向。
GC
在Java对象头当中的Mark Word存储了对象的分代年龄,那么什么是分代年龄呢?
一个对象的分代年龄可以理解为垃圾回收次数,当一个对象经过一次垃圾回收之后还存在,那么分代年龄就会加1,在64位的虚拟机中,分代年龄占了4位,最大值为15。分代年龄默认为0000,随着垃圾回收次数,会逐渐递增。
Java堆内存中按照分代年龄来划分,分为Young区和Old区,对象分配首先会到Young区,达到一定分代年龄(-XX:MaxTenuringThreshold可以设置大小,默认为15)就会进入Old区(注意:如果一个对象太大,那么就会直接进入Old区)。
再把Young区再次划分一下,分为2个区:Eden区和Survivor区。
最后把Survivor区给一分为二。
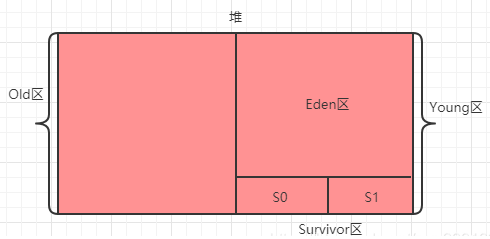
这个时候工作流程又变成这样了: 首先还是在Eden区分配空间,Eden区满了之后触发GC,GC之后把幸存对象 复制到S0区(S1区是空的),然后继续在Eden区分配对象,再次触发GC之后如果发现S0区放不下了(产生空间碎片,实际还有空间),那么就把S0区对象复制到S1区,并把幸存对象也复制到S1区,这时候S0区是空的了,并依次反复操作,假如说S0区或者S1区空间对象复制移动了之后还是放不下,那就说明这时候是真的满了,那就去老年区借点空间过来(这就是担保机制,老年代需要提供这种空间分配担保),假如说老年区空间也不够了,那就会触发Full GC,如果还是不够,那就会抛出OutOfMemeoyError异常了。
注意:为了确保S0和S1两个区域之间每次复制都能顺利进行,S0和S1两个区的大小必须要保持一致,而且同一时间有一个区域一定是空的。虽然说这种做法是会导致了一小部分空间的浪费,但是综合其他性能的提升来说,是值得的。
当Young区的对象达到设置的分代年龄之后,对象会进入Old区,Old区满了之后会触发Full GC,如果还是清理不掉空间,那么就抛出OutOfMemeoyError异常。
这里还存在两个问题:
为什么Survivor要分为两个区域(S0和S1)?
设置两个 Survivor 区最大的好处就是解决内存碎片化。
假设一下,Survivor 如果只有一个区域会怎样?
刚刚新建的对象在Eden中,一旦Eden满了,触发一次Minor GC,Eden中的存活对象就会被移动到Survivor区。这样继续循环下去,下一次Eden满了的时候,问题来了,如果采用复制算法:Survivor区域很容易就满了,会频繁Minor GC;如果是标记清除,在新生代这种经常会消亡的区域,采用标记清除必然会让内存产生严重的碎片化。
如果Survivor 有2个区域,所以每次 Minor GC,会将之前 Eden 区和 From 区中的存活对象复制到 To 区域。第二次 Minor GC 时,From 与 To 职责兑换,这时候会将 Eden 区和 To 区中的存活对象再复制到 From 区域,以此反复。这种复制算法保证了S1中来自S0和Eden两部分的存活对象占用连续的内存空间,避免了碎片化的发生。
Survivor 为什么不分更多块呢?
这种机制最大的好处就是,整个过程中,永远有一个 Survivor space 是空的,另一个非空的 Survivor space 是无碎片的。
那么,Survivor 为什么不分更多块呢?比方说分成三个、四个、五个?显然,如果 Survivor 区再细分下去,每一块的空间就会比较小,容易导致 Survivor 区满,两块 Survivor 区可能是经过权衡之后的最佳方案。
对象的生命周期
一个对象会在Eden区,S0区,S1区,Old区不断流转(当然,一开始就会被回收的短命对象除外),我们可以得到下面的一个流程图:
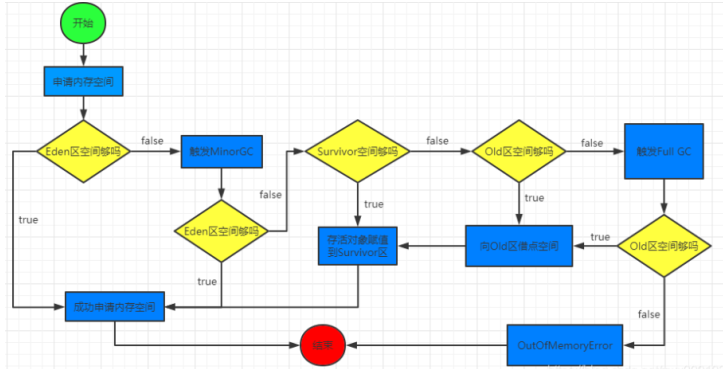
小知识
垃圾回收:简称GC。
Minor GC:针对新生代的GC
Major GC:针对老年代的GC,一般老年代触发GC的同时也会触发Minor GC,也就等于触发了Full GC。
Full GC:新生代+老年代同时发生GC。
Young区:新生代
Old区:老年代
Eden区:暂时没发现有什么中文翻译(伊甸园?)
Surcivor区:幸存区
S0和S1:也称之为from区和to区,注意from和to两个区是不断互换身份的,且S0和S1一定要相等,并且保证一块区域是空的