重磅推荐专栏: 《Transformers自然语言处理系列教程》
手把手带你深入实践Transformers,轻松构建属于自己的NLP智能应用!
1. 概要
使用预训练语言模型的小样本学习(处理只有少量标签或没有标签的数据)已成为比较普遍的解决方案。
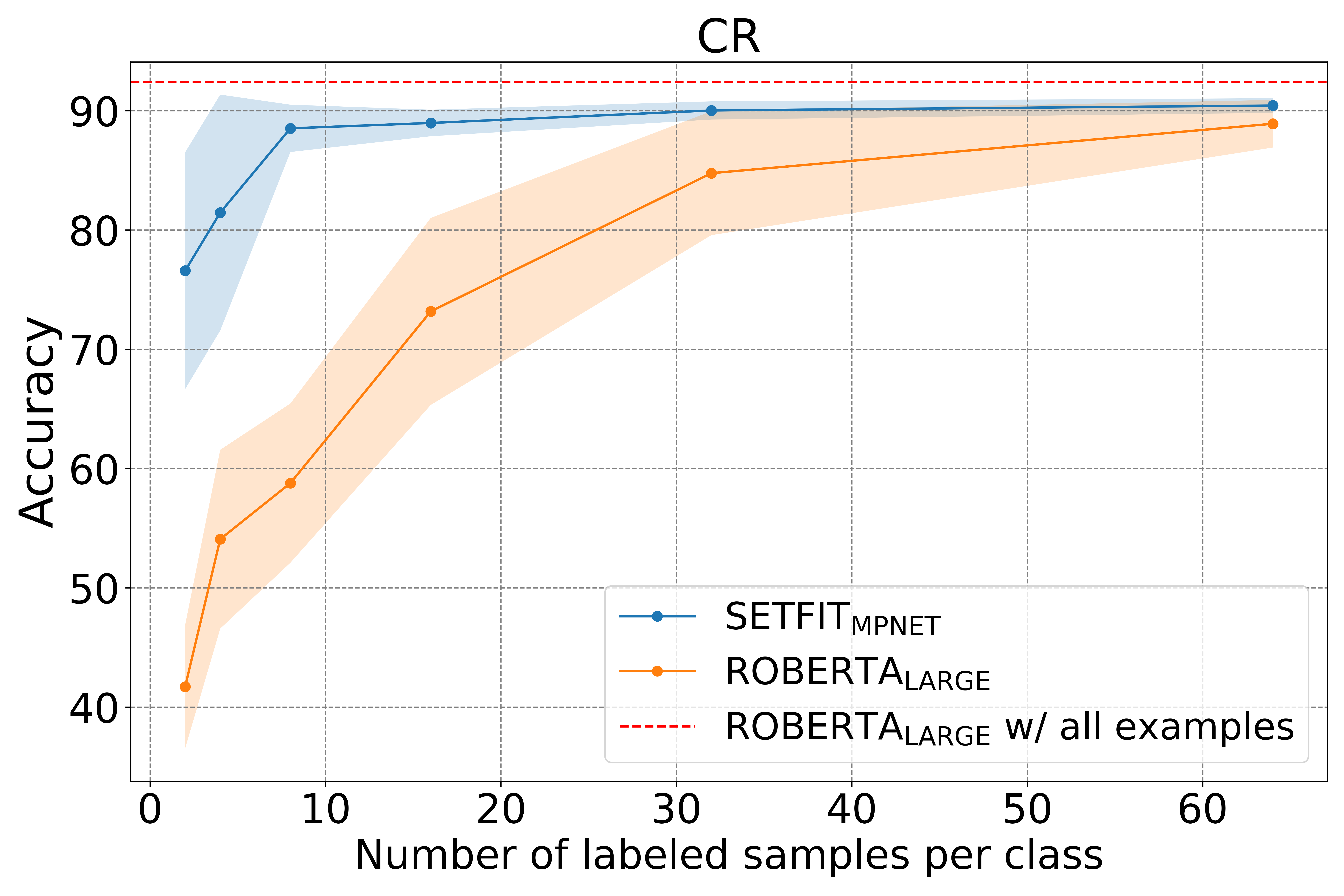
SetFit:一种用于对 Sentence Transformers 进行少量微调的高效框架。SetFit 用很少的标记数据实现了高精度——例如,在客户评论 (CR) 情绪数据集上每个类只有 8 个标记样本,SetFit 在 3k 个样本的完整训练集上与微调 RoBERTa Large 相比,如图1-1所示,具有竞争力表现:
与其他小样本学习方法相比,SetFit 有几个独特的特点:
-
没有提示(prompts )或语言器(verbalisers):当前的小样本微调技术需要手工制作的提示(prompts )或语言器(verbalisers)将样本转换为适合底层语言模型的格式。SetFit 通过直接从少量带标签的文本示例生成丰富的embeddings 来完全免除prompts 。
-
训练速度快:SetFit 不需要像 T0 或 GPT-3 这样的大型模型来实现高精度。因此,训练和运行推理的速度通常快一个数量级(或更多)。
-
多语言支持:SetFit 可以与 Hub 上的任何 Sentence Transformer 一起使用,这意味着你可以通过简单地微调多语言checkpoint来对多种语言的文本进行分类。
-
论文: https://arxiv.org/pdf/2209.11055.pdf
-
代码:https://github.com/huggingface/setfit
2. 原理
SetFit原理比较简单,它设计考虑了效率和简单性。SetFit 首先在少量标记示例(通常每个类 8 或 16 个)上微调 Sentence Transformer 模型。接下来是在微调的 Sentence Transformer 生成的embeddings上训练分类器头。SetFit 利用 Sentence Transformers 的能力基于成对的句子生成密集embeddings 。如图2-1所示:
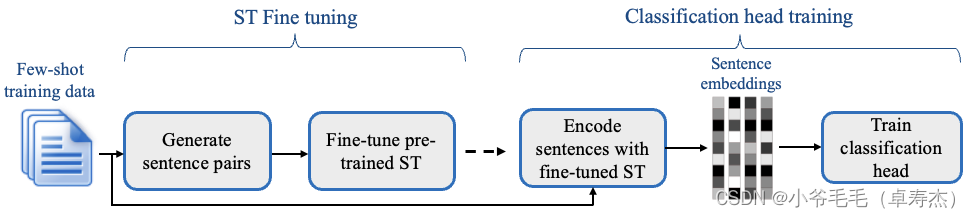

- 在初始微调阶段,它通过对比训练利用有限的标记输入数据,其中正负对由类内和类外选择创建,如图2-2所示。然后,Sentence Transformer 模型对这些对(或三元组)进行训练,并为每个样本生成密集向量。
- 在第二步中,分类头使用各自的类标签对编码embeddings进行训练。在推理时,未见过的样本通过微调的 Sentence Transformer,生成一个embedding ,当将其送到分类头时,输出一个类标签预测结果。
只需将基本的 Sentence Transformer 模型切换为多语言模型,SetFit 就可以在多语言环境中无缝运行。
3. 实验
3.1 效果表现
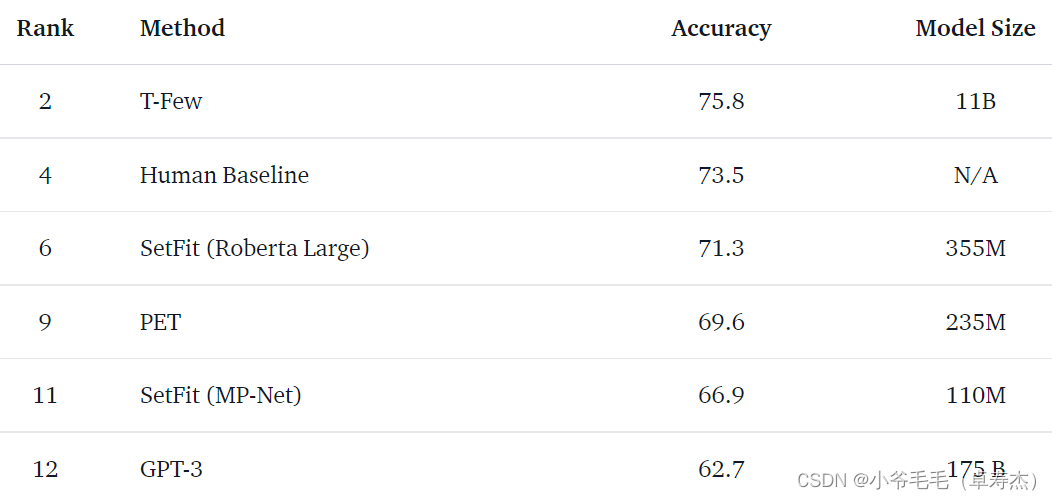
虽然基于比现有的少样本方法小得多的模型,但 SetFit 在各种基准测试中的表现与sota的少样本方法相当或更好。如图3-1所示,在RAFT(一个 few-shot 分类基准)上,具有 3.55 亿个参数的 SetFit Roberta 优于 PET 和 GPT-3。它仅仅在人类平均表现和 110 亿个参数 T-few(这个模型的大小是 SetFit Roberta 的 30 倍) 水平之下。SetFit 在 11 项 RAFT 任务中的 7 项上也优于人类基线。
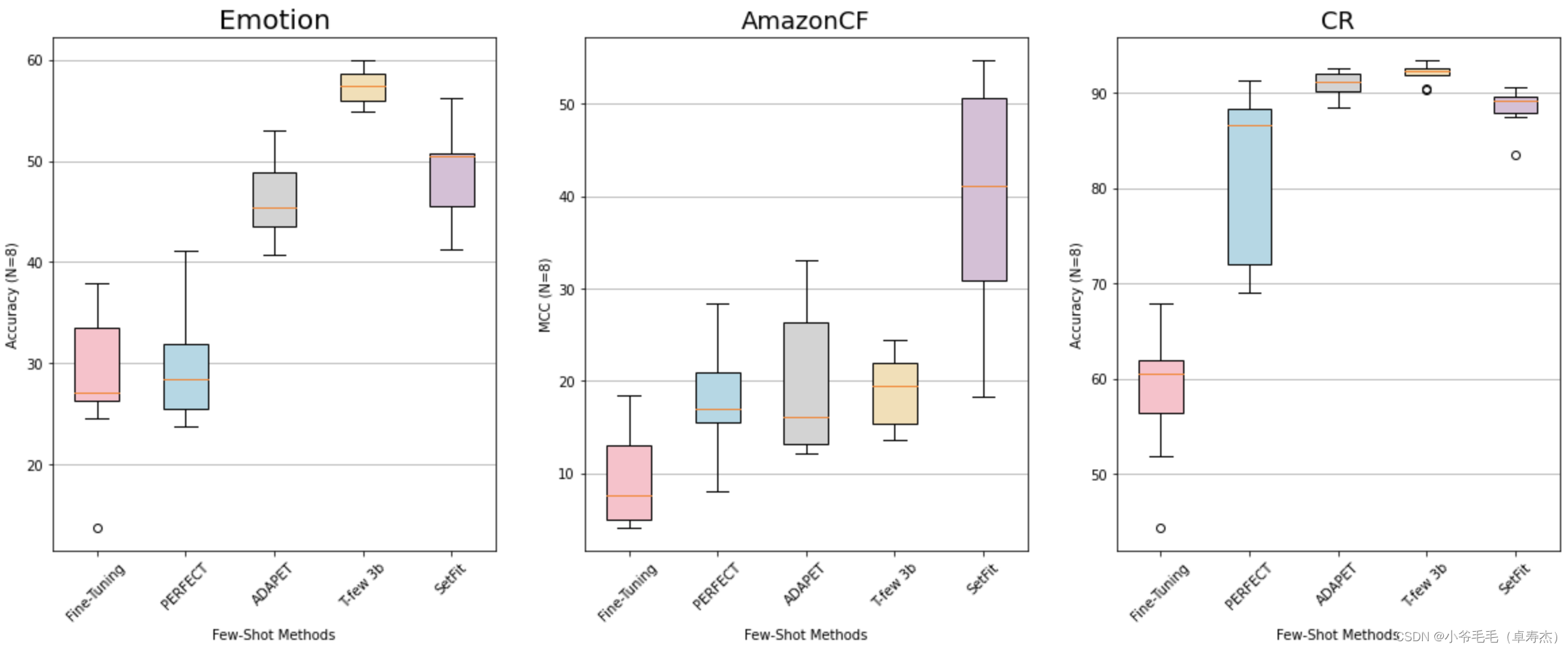
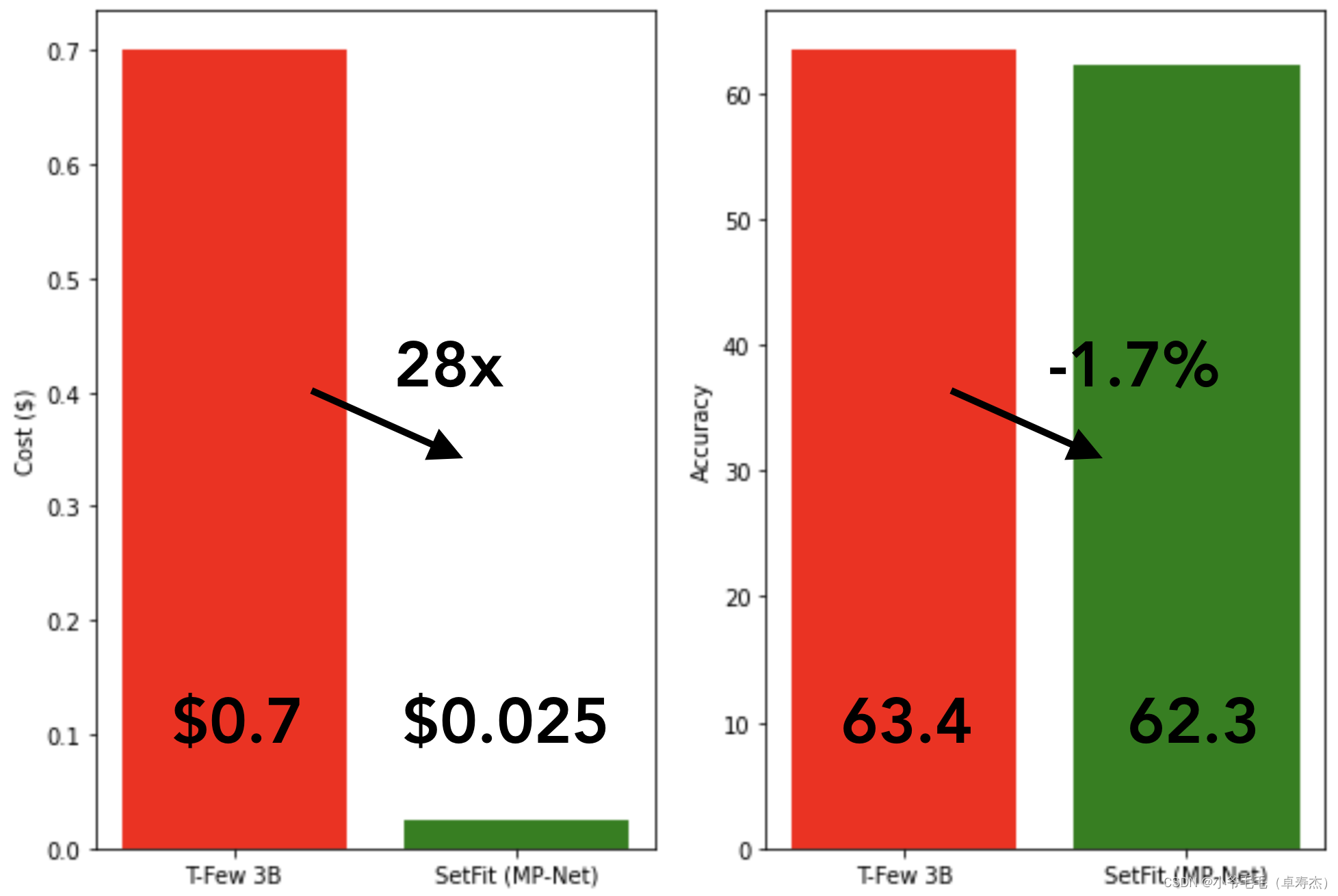
在其他数据集上,SetFit 在各种任务中表现出稳健性。如下图3-2所示,每个类只有 8 个示例,它基本上优于 PERFECT、ADAPET 和微调的 vanilla transformer。SetFit 也取得了与 T-Few 3B 相当的结果,尽管它无需提示且体积小 27 倍。
3.2 训练和推理速度
由于 SetFit 使用相对较小的模型实现了高精度,因此它的训练速度非常快,而且成本要低得多。例如,使用 8 个标记示例在 NVIDIA V100 上训练 SetFit 仅需 30 秒,成本为 0.025 美元。相比之下,训练 T-Few 3B 需要 NVIDIA A100,耗时 11 分钟,同一实验的成本约为 0.7 美元——高出 28 倍。事实上,SetFit 可以像 Google Colab 上的那样在单个 GPU 上运行,你甚至可以在几分钟内在 CPU 上训练 SetFit!如图3-3所示,SetFit带来了提速,模型性能却与T-Few 3B相当。预测和蒸馏 SetFit 模型也可以获得类似的收益,可以带来 123 倍的加速!
4. 实践:零样本文本分类
SetFit还可以做零样本文本分类。我们需要做的第一件事是创建一个合成样本的虚拟数据集。我们可以通过将 add_templated_examples() 函数来完成此操作。此函数需要一些主要内容:
- 用于分类的候选标签列表。 我们将在此处使用参考数据集中的标签。
- 用于生成示例的模板。 默认情况下,它是“This sentence is {}”,其中{}将由候选标签名称之一填充
- 样本量 N,这将为每个类创建 N 个合成示例。 作者发现 N=8 通常效果最好。
dataset_id = "emotion"
model_id = "sentence-transformers/paraphrase-mpnet-base-v2"
from datasets import load_dataset
reference_dataset = load_dataset(dataset_id)
# 从“label”列中提取 ClassLabel 特征
label_features = reference_dataset["train"].features["label"]
# 用于分类的标签名称
candidate_labels = label_features.names
candidate_labels
['sadness', 'joy', 'love', 'anger', 'fear', 'surprise']
from datasets import Dataset
from setfit import add_templated_examples
# 用合成样本填充的虚拟数据集
dummy_dataset = Dataset.from_dict({})
train_dataset = add_templated_examples(dummy_dataset, candidate_labels=candidate_labels, sample_size=8)
train_dataset
由于我们的数据集有 6 个类别,我们选择的样本大小为 8,因此我们的合成数据集包含 6×8=48 个样本。
Dataset({
features: ['text', 'label'],
num_rows: 48
})
我们看几个例子:
train_dataset.shuffle()[:3]
{'text': ['This sentence is love',
'This sentence is fear',
'This sentence is joy'],
'label': [2, 4, 1]}
用这样虚拟数据集来微调模型,在预测看看效果:
from setfit import SetFitModel
model = SetFitModel.from_pretrained(model_id)
from setfit import SetFitTrainer
trainer = SetFitTrainer(
model=model,
train_dataset=train_dataset,
eval_dataset=reference_dataset["test"]
)
trainer.train()
zeroshot_metrics = trainer.evaluate()
zeroshot_metrics
{'accuracy': 0.5345}
我们在尝试一下用 Hugging Face 的 zero-shot-classification:
from transformers import pipeline
pipe = pipeline("zero-shot-classification", device=0)
zeroshot_preds = pipe(reference_dataset["test"]["text"], batch_size=16, candidate_labels=candidate_labels)
zero-shot-classification pipeline 默认用的是 facebook/bart-large-mnli。注意,该方法 生成预测结果所需的时间比 SetFit 长将近 5 倍! 好的,那么它的性能如何?
preds = [label_features.str2int(pred["labels"][0]) for pred in zeroshot_preds]
import evaluate
metric = evaluate.load("accuracy")
transformers_metrics = metric.compute(predictions=preds, references=reference_dataset["test"]["label"])
transformers_metrics
与 SetFit 相比,这种方法的性能要差得多:
{'accuracy': 0.3765}
看来 SetFit 真的是——即简单,又高效,还性能好 !666666666666666…