目录
- 1. 数据库约束
- 1.1 约束类型
- 1.2 NULL约束
- 1.3 UNIQUE:唯一约束
- 1.4 DEFAULT:默认值约束
- 1.5 PRIMARY KEY:主键约束
- 1.6 FOREIGN KEY:外键约束
- 1.7 CHECK约束
- 2 表之间的关系
- 2.1 一对一
- 2.2 一对多
- 2.3 多对多
- 3 新增
- 4 查询
- 4.1 聚合查询
- 4.1.1 聚合函数
- 4.1.2 GROUP BY
- 4.1.3 HAVING
- 4.2 联合查询
- 4.2.1 内连接
- 4.2.2 外连接
- 4.2.3 自连接
- 4.2.4 子查询
- 4.2.5 合并查询
1. 数据库约束
1.1 约束类型
- NOT NULL : 指示某列不能存储 NULL 值。
- UNIQUE :保证某列的每行必须有唯一的值。
- DEFAULT :规定没有给列赋值时的默认值。
- PRIMARY KEY :NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。
- FOREIGN KEY :保证一个表中的数据匹配另一个表中的值的参照完整性。
- CHECK :保证列中的值符合指定的条件。对于MySQL数据库,对CHECK子句进行分析,但是忽略CHECK子句。
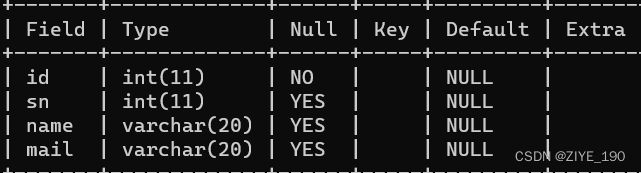
1.2 NULL约束
创建表时,可以指定某列不为空:
-- 重新设置学生表结构
DROP TABLE IF EXISTS student;
CREATE TABLE student (
id INT NOT NULL,
sn INT,
name VARCHAR(20),
mail VARCHAR(20)
);
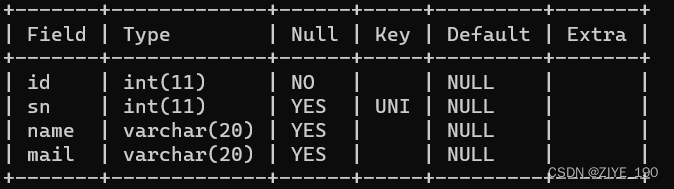
1.3 UNIQUE:唯一约束
指定sn列为唯一的、不重复的:
-- 重新设置学生表结构
DROP TABLE IF EXISTS student;
CREATE TABLE student (
id INT NOT NULL,
sn INT UNIQUE,
name VARCHAR(20),
mail VARCHAR(20)
);
1.4 DEFAULT:默认值约束
指定插入数据时,name列为空,默认值unkown:
-- 重新设置学生表结构
DROP TABLE IF EXISTS student;
CREATE TABLE student (
id INT NOT NULL,
sn INT UNIQUE,
name VARCHAR(20) DEFAULT 'unkown',
mail VARCHAR(20)
);
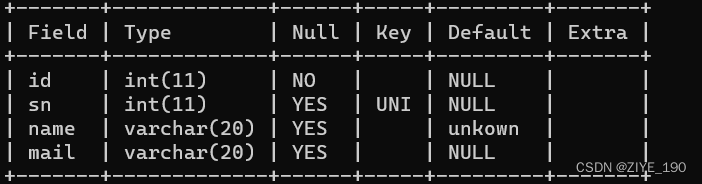
1.5 PRIMARY KEY:主键约束
指定id列为主键:
-- 重新设置学生表结构
DROP TABLE IF EXISTS student;
CREATE TABLE student (
id INT NOT NULL PRIMARY KEY,
sn INT UNIQUE,
name VARCHAR(20) DEFAULT 'unkown',
mail VARCHAR(20)
);
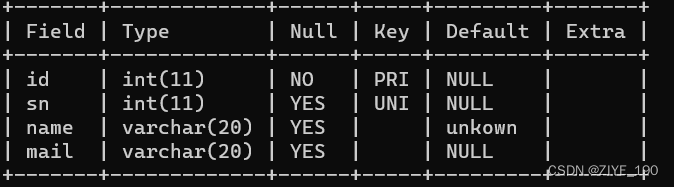
对于整数类型的主键,常配搭自增长auto_increment来使用。插入数据对应字段不给值时,使用最大值+1。
-- 主键是 NOT NULL 和 UNIQUE 的结合,可以不用 NOT NULL
id INT PRIMARY KEY auto_increment,
1.6 FOREIGN KEY:外键约束
外键用于关联其他表的主键或唯一键,
语法:
foreign key (字段名) references 主表(列)
- 创建班级表classes,id为主键:
-- 创建班级表
DROP TABLE IF EXISTS classes;
CREATE TABLE classes (
id INT PRIMARY KEY auto_increment,
name VARCHAR(20)
);
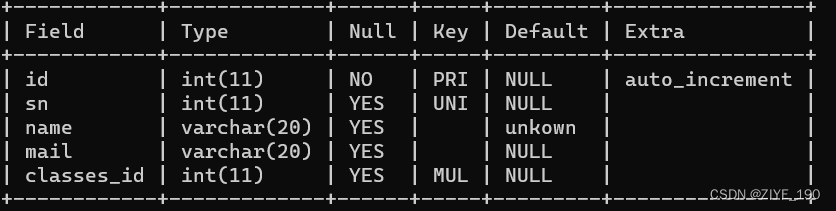
- 创建学生表student,一个学生对应一个班级,一个班级对应多个学生。使用id为主键,classes_id为外键,关联班级表id
-- 重新设置学生表结构
DROP TABLE IF EXISTS student;
CREATE TABLE student (
id INT PRIMARY KEY auto_increment,
sn INT UNIQUE,
name VARCHAR(20) DEFAULT 'unkown',
mail VARCHAR(20),
classes_id int,
FOREIGN KEY (classes_id) REFERENCES classes(id)
);
1.7 CHECK约束
MySQL使用时不报错,但忽略该约束:
drop table if exists user;
create table user (
id int,
name varchar(20),
sex varchar(1),
check (sex ='男' or sex='女')
);
2 表之间的关系
2.1 一对一

2.2 一对多

2.3 多对多
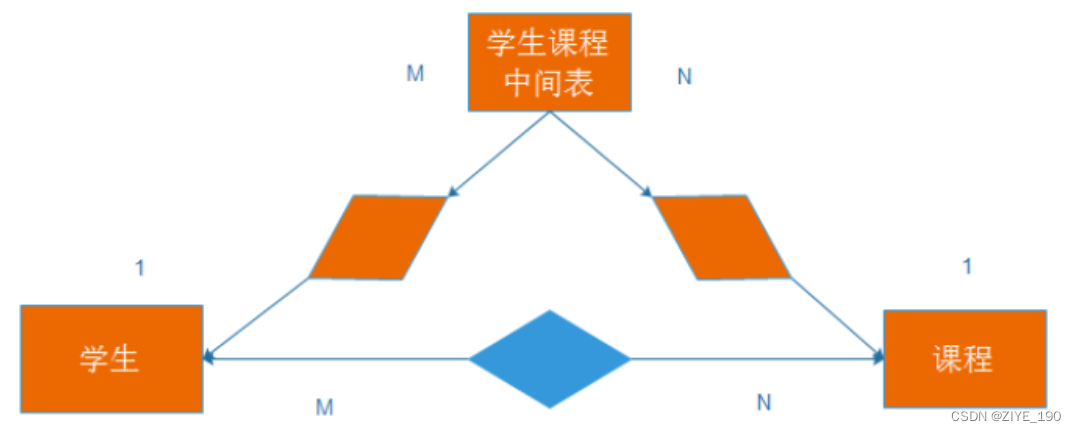
- 创建课程表
-- 创建课程表
DROP TABLE IF EXISTS course;
CREATE TABLE course (
id INT PRIMARY KEY auto_increment,
name VARCHAR(20)
);
- 创建学生课程中间表,考试成绩表
-- 创建课程学生中间表:考试成绩表
DROP TABLE IF EXISTS score;
CREATE TABLE score (
id INT PRIMARY KEY auto_increment,
score DECIMAL(3, 1),
student_id int,
course_id int,
FOREIGN KEY (student_id) REFERENCES student(id),
FOREIGN KEY (course_id) REFERENCES course(id)
);
3 新增
插入查询结果
INSERT INTO table_name [(column [, column ...])] SELECT ...
示例:
-- 创建用户表
DROP TABLE IF EXISTS test_user;
CREATE TABLE test_user (
id INT primary key auto_increment,
name VARCHAR(20) comment '姓名',
age INT comment '年龄',
email VARCHAR(20) comment '邮箱',
sex varchar(1) comment '性别',
mobile varchar(20) comment '手机号'
);
-- 将学生表中的所有数据复制到用户表
insert into test_user(name, email) select name, mail from student;
4 查询
4.1 聚合查询
4.1.1 聚合函数
| 函数 | 说明 |
|---|---|
| COUNT([DISTINCT] expr) | 返回查询到的数据的 数量 |
| SUM([DISTINCT] expr) | 返回查询到的数据的 总和,不是数字没有意义 |
| AVG([DISTINCT] expr) | 返回查询到的数据的 平均值,不是数字没有意义 |
| MAX([DISTINCT] expr) | 返回查询到的数据的 最大值,不是数字没有意义 |
| MIN([DISTINCT] expr) | 返回查询到的数据的 最小值,不是数字没有意义 |
4.1.2 GROUP BY
SELECT 中使用 GROUP BY 子句可以对指定列进行分组查询。需要满足:使用 GROUP BY 进行分组查询时,SELECT 指定的字段必须是“分组依据字段”,其他字段若想出现在SELECT 中则必须包含在聚合函数中。
select column1, sum(column2), .. from table group by column1,column3;
4.1.3 HAVING
GROUP BY 子句进行分组以后,需要对分组结果再进行条件过滤时,不能使用 WHERE 语句,而需要用HAVING
select column1, sum(column2), .. from table group by column1,column3 having ...;
4.2 联合查询
4.2.1 内连接
语法:
select 字段 from 表1 别名1 [inner] join 表2 别名2 on 连接条件 and 其他条件;
select 字段 from 表1 别名1,表2 别名2 where 连接条件 and 其他条件;
4.2.2 外连接
外连接分为左外连接和右外连接。如果联合查询,左侧的表完全显示我们就说是左外连接;右侧的表完全显示我们就说是右外连接。
语法:
-- 左外连接,表1完全显示
select 字段名 from 表名1 left join 表名2 on 连接条件;
-- 右外连接,表2完全显示
select 字段 from 表名1 right join 表名2 on 连接条件;
内连接和外连接的区别:
- 内连接必须满足连接条件和其他条件才会返回
- 外连接满足连接条件和其他条件,或满足其他条件,外表存在(即使不满足连接条件) 也可以返回
4.2.3 自连接
自连接是指在同一张表连接自身进行查询。应用场景主要是同个字段,不同行之间进行比较
语法:
select t1.*, .. from table t1,table t2 where t1.column1 = t2.column1 and ...;
4.2.4 子查询
子查询是指嵌入在其他sql语句中的select语句,也叫嵌套查询
- 单行子查询:返回一行记录的子查询
select *, .. from table1 where column1 = (select column1 from table1 where ... );
- 多行子查询:返回多行记录的子查询
- [NOT] IN关键字:
select *, .. from table1 where column1 in (select column1 from table2 where ... or ... );
- [NOT] EXISTS关键字:
select *, .. from table1 where exists (select column1 from table2 where (... or ... ) and table1.column1 = table2.column1);
- 在from子句中使用子查询:子查询语句出现在from子句中。这里要用到数据查询的技巧,把一个子查询当做一个临时表使用
4.2.5 合并查询
在实际应用中,为了合并多个select的执行结果,可以使用集合操作符 union,union all。使用UNION和UNION ALL时,前后查询的结果集中,字段需要一致。
- union
select * from table1 where ...
union
select * from table2 where ...;
该操作符用于取得两个结果集的并集。当使用该操作符时,会自动去掉结果集中的重复行
- union all
select * from table1 where ...
union all
select * from table2 where ...;
该操作符用于取得两个结果集的并集。当使用该操作符时,不会去掉结果集中的重复行