RPC 漫谈:序列化问题
何为序列
对于计算机而言,一切数据皆为二进制序列。但编程人员为了以人类可读可控的形式处理这些二进制数据,于是发明了数据类型和结构的概念,数据类型用以标注一段二进制数据的解析方式,数据结构用以标注多段(连续/不连续)二进制数据的组织方式。
例如以下程序结构体:
type User struct {
Name string
Email string
}
Name 和 Email 分别表示两块独立(或连续,或不连续)的内存空间(数据),结构体变量本身也有一个内存地址。
在单进程中,我们可以通过分享该结构体地址来交换数据。但如果要将该数据通过网络传输给其他机器的进程,我们需要现将该 User 对象中不同的内存空间,编码成一段连续二进制表示,此即为「序列化」。而对端机器收到了该二进制流以后,还需要能够认出该数据为 User 对象,解析为程序内部表示,此即为「反序列化」。
序列化和反序列化,就是将同一份数据,在人的视角和机器的视角之间相互转换。
序列化过程
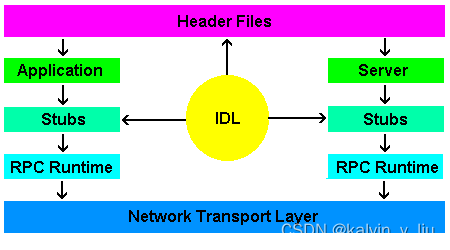
定义接口描述(IDL)
为了传递数据描述信息,同时也为了多人协作的规范,我们一般会将描述信息定义在一个由 IDL(Interface Description Languages) 编写的定义文件中,例如下面这个 Protobuf 的 IDL 定义:
message User {
string name = 1;
string email = 2;
}
生成 Stub 代码
无论使用什么样的序列化方法,最终的目的是要变成程序中里的一个对象,虽然序列化方法往往是语言无关的,但这段将内存空间与程序内部表示(如 struct/class)相绑定的过程却是语言相关的,所以很多序列化库才会需要提供对应的编译器,将 IDL 文件编译成目标语言的 Stub 代码。
Stub 代码内容一般分为两块:
类型结构体生成(即目标语言的 Struct[Golang]/Class[Java] )
序列化/反序列化代码生成(将二进制流与目标语言结构体相转换)
下面是一段 Thrift 生成的的序列化 Stub 代码:
type User struct {
Name string `thrift:"name,1" db:"name" json:"name"`
Email string `thrift:"email,2" db:"email" json:"email"`
}
//写入 User struct
func (p *User) Write(oprot thrift.TProtocol) error {
if err := oprot.WriteStructBegin("User"); err != nil {
return thrift.PrependError(fmt.Sprintf("%T write struct begin error: ", p), err) }
if p != nil {
if err := p.writeField1(oprot); err != nil { return err }
if err := p.writeField2(oprot); err != nil { return err }
}
if err := oprot.WriteFieldStop(); err != nil {
return thrift.PrependError("write field stop error: ", err) }
if err := oprot.WriteStructEnd(); err != nil {
return thrift.PrependError("write struct stop error: ", err) }
return nil
}
// 写入 name 字段
func (p *User) writeField1(oprot thrift.TProtocol) (err error) {
if err := oprot.WriteFieldBegin("name", thrift.STRING, 1); err != nil {
return thrift.PrependError(fmt.Sprintf("%T write field begin error 1:name: ", p), err) }
if err := oprot.WriteString(string(p.Name)); err != nil {
return thrift.PrependError(fmt.Sprintf("%T.name (1) field write error: ", p), err) }
if err := oprot.WriteFieldEnd(); err != nil {
return thrift.PrependError(fmt.Sprintf("%T write field end error 1:name: ", p), err) }
return err
}
// 写入 email 字段
func (p *User) writeField2(oprot thrift.TProtocol) (err error) {
if err := oprot.WriteFieldBegin("email", thrift.STRING, 2); err != nil {
return thrift.PrependError(fmt.Sprintf("%T write field begin error 2:email: ", p), err) }
if err := oprot.WriteString(string(p.Email)); err != nil {
return thrift.PrependError(fmt.Sprintf("%T.email (2) field write error: ", p), err) }
if err := oprot.WriteFieldEnd(); err != nil {
return thrift.PrependError(fmt.Sprintf("%T write field end error 2:email: ", p), err) }
return err
}
可以看到,为了把 User 对象给序列化成二进制,它 hard code 了整个结构体在内存中的组织方式和顺序,并且分别对每个字段去做强制类型转换。如果我们新增了一个字段,就需要重新编译 Stub 代码并要求所有 Client 进行升级更新(当然不需要用到新字段可以不用更新)。反序列化的步骤也是类似。
上述这段冗长的代码还只是我们用于演示的一个最简单的消息结构,对于生产环境中的真实消息类型,这段 Stub 代码会更加复杂。
Stub 代码生成只是为了解决跨语言调用的问题,并不是必须项。如果你的调用方与被调用方都是同一种语言,且未来一定能够保证都是同一种语言,这种情况也会选择直接用目标语言去写 IDL 定义,跳过编译的步骤,例如 Thrift 里的 drift 项目就是利用 Java 直接去写定义文件:
@ThriftStruct
public class User
{
private final String name;
private final String email;
@ThriftConstructor
public User(String name, String email)
{
this.name = name;
this.email = email;
}
@ThriftField(1)
public String getName()
{
return name;
}
@ThriftField(2)
public String getEmail()
{
return email;
}
}
我们前面说了,序列化本身的意义就在于提供人和机器视角对数据认识的一种转换。传统的思路是通过一个中间结构体,而这类方式是通过提供操作函数。
不过这类方式有一个通病就是仅仅只是提供了操作数据的能力,但是牺牲了程序编写者自己去管理数据的便利性。比如如果我们想知道这个 User 结构有哪些字段,除非序列化编译后的代码提供给了你这个能力,否则你将对一串二进制无从下手。比如你想直接把这个 User 对象和一些 ORM 工具组合存进数据库,你必须自己手写一个新的 User struct,然后挨个字段赋值。
这类序列化框架大多用在那些数据定义不怎么变化的核心基础设施服务,例如数据库,消息队列这类。如果用在日常业务开发,或许性价比不是很高。
最后
我们经常听到网上有人讨论,哪个序列化协议性能更好。其实如果我们真的认真去研究各类序列化方案,很容易会发现,序列化协议本身只是一份文档,它的性能优劣取决于你怎么去实现。不同语言实现,同语言不同方式方法的实现,都会对最终的易用性和性能产生巨大的影响。你完全可以把 Protobuf 的协议用 Flatbuffer 的方式去实现,能够提升非常多的性能,但未必就是你想要的。
与性能相比更为重要的是先弄清楚我们在序列化的各种问题中,希望解决哪些,愿意放弃哪些,有了明确的需求才能选择到适合的序列化方案,并且真的遇到问题时也能快速知道这个问题是否是可解的,如何解。