第一类:PEFT类论文
(我还挺喜欢的,不知道自己什么时候可以搞出这种工作
(为什么中英文穿插,利于自己写论文:)
COMPOSITIONAL P ROMPT T UNING WITH M OTIONC UES FOR O PEN - VOCABULARY V IDEO R ELATIOND ETECTION
1.定义了一个open-vocabulary的SGG,并且定义了一个适合这个任务的prompt
2.模型简介:(主要是哪里没动,动了的设计的地方是什么
FAME-ViL: Multi-Tasking Vision-Language Model for Heterogeneous Fashion Tasks
1.这篇论文属于 PEFT类论文,即不训练clip,参数效率提高类
2.这篇论文主打 利用一个 unified 模型(统一)来解决大部分的 fashion领域任务,文中说即多任务学习。
3.模型主要三个模块:文本encoder 和 视觉 encoder (两者都是之间由clip模型中的参数初始化的)以及一系列本文提出的adapter(嗯,就两个)
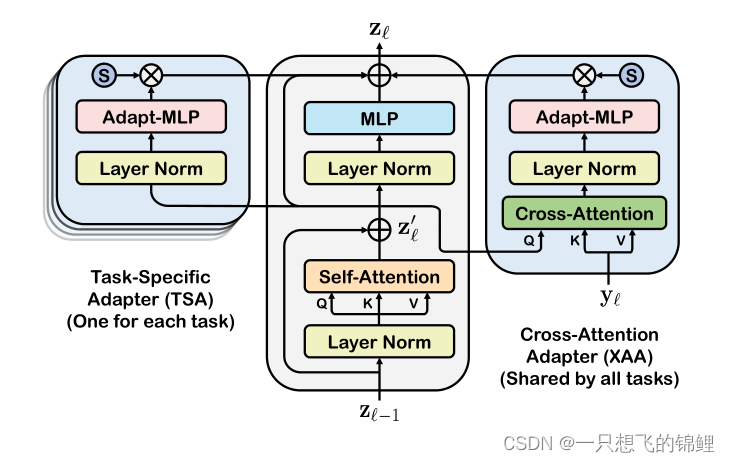
4. 接下来的多teacher 训练,也就是为了多任务提出的训练方法嘿嘿 ,这一段说的很清楚了,感觉不是很优雅,特别复杂。


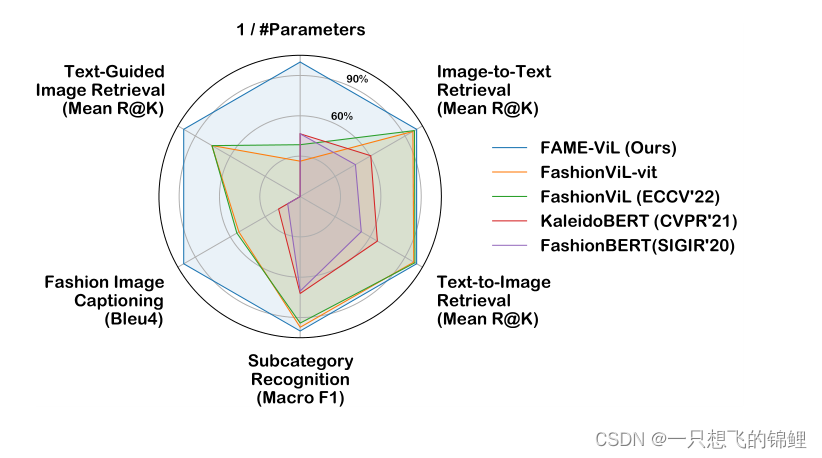
5. 实验模块 没有细看,但是那个比较图是真的好看呀
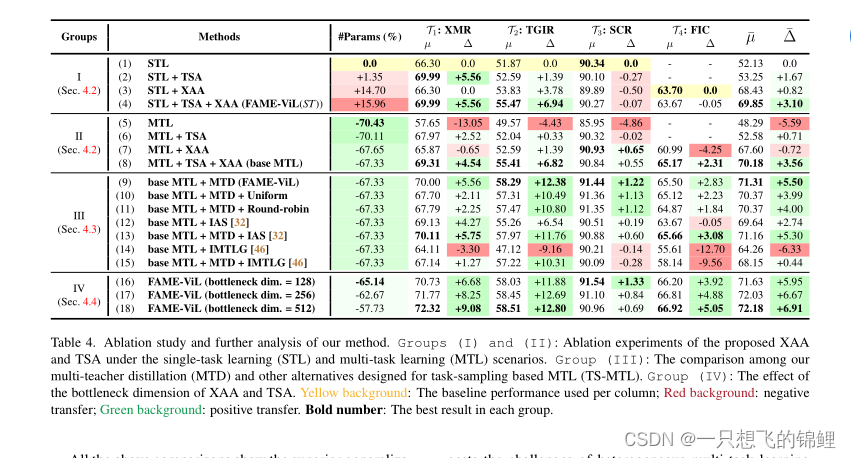
- 总结:超少的系数(基于clip)的一个统一架构(提出了两个adapter)能够解决多个fashion类任务,且效果很好,训练方法是使用的多teacher蒸馏。文中说这样效果好是因为 inter-task可以互相交流了,而且他这个方式解决了原来MTL的一些问题。
This is made possible by the proposed task-versatile architecture with cross-attention
adapters and task-specific adapters, and a scalable multi-task training pipeline with multi-teacher distillation
7.其他要点:这个知识是每个论文可以学习的嘿嘿

Vision Transformers are Parameter-Efficient Audio-Visual Learners
提出一个adapter是多模态的,能够很少参数ft一个模型(不需要在 audio数据训练,仅仅pretrain在image数据上),达到很好的效果。
Towards Fast Adaptation of Pretrained Contrastive Models for Multi-channel Video-Language Retrieval
Vision Transformers are Parameter-Efficient Audio-Visual Learners
we propose a latent audio-visual hybrid (LAVISH) adapter that adapts pretrained ViTs to audio-visual tasks by injecting a small number of trainable parameters into every layer of a frozen ViT. To efficiently fuse visual and audio cues, our LAVISH adapter uses a small set of latent tokens, which form an attention bottleneck, thus, eliminating the quadratic cost of standard cross-attention
第二类论文:总结性的
(比如总结现在的PEFT方法,得到一个范式,然后利用这个最优范式得到一个模型,这个模型比之前的都好)
(这类论文我好奇一点是,每个论文难道不会先总结之前的吗?可能是同时期不比较吧?
VINDLU : A Recipe for Effective Video-and-Language Pretraining
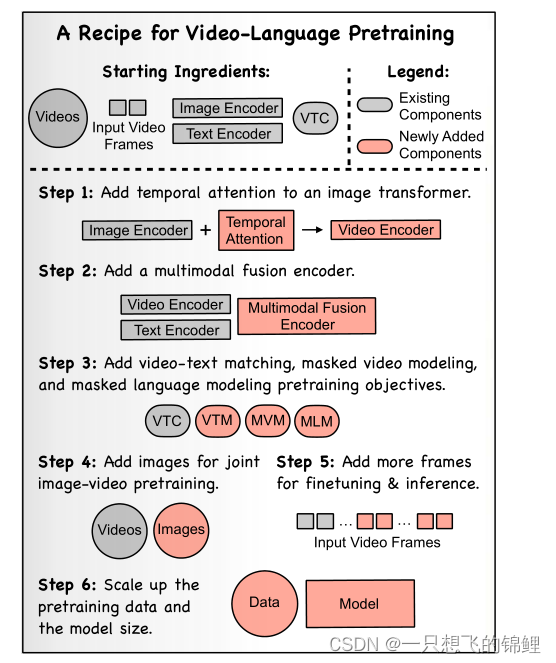
这类论文大部分是总结性的,很多组件都不是novel这篇论文提的,而是选择最优的组合成一个最优的模型,论文会有很多讨论。让读者自行选择想看的内容。
第三类:视频类的
(简单来说就是现在很多工作都是 在 图片上搞
(视频有个时序的难点
Text-Visual Prompting for Efficient 2D Temporal Video Grounding
这篇看起来特别nb,速度特别快,但是prompt居然没细说。难道现在prompt已经不新了吗?这篇是重新pretrain和finetune的,但是使用的prompt弥补了image-text 到 video-text 的gap(它是这样说的),然后速度快是因为 用的 2d 的而且可以 end-to-end(之前3d的方法都是先提取特征好了的,这块相当于fixed住了)
VoP: Text-Video Co-operative Prompt Tuning for Cross-Modal Retrieval
we propose the VoP: Text-Video Co-operative Prompt Tuning for efficient tuning on the text-video retrieval task. The proposed VoP is an end-to-end framework with both video & text prompts introducing, which can be regarded as a powerful baseline with only 0.1% trainable parameters.
Towards Fast Adaptation of Pretrained Contrastive Models for Multi-channel Video-Language Retrieval
we identify a principled model design space with two axes: how to represent videos and how to fuse video and text information. Based on categorization of recent methods, we investigate the options of representing videos using continuous feature vectors or discrete text tokens; for the fusion method, we explore the use of a multimodal transformer or a pretrained contrastive text model.
All in One: Exploring Unified Video-Language Pre-training
这篇是视频和文本直接输入,不是图片
CLIP-ViP: Adapting Pre-trained Image-Text Model to Video-Language Representation Alignment
we propose a Omnisource Cross-modal Learning method equipped with a Video Proxy mechanism on the basis of CLIP, namely CLIP-ViP.
In this paper, we investigate two questions: 1) what are the factors hindering post-pretraining CLIP to further improve the performance on video-language tasks? and 2) how to mitigate the impact of these factors? Through a series of comparative experiments and analyses, we find that the data scale and domain gap between language sources have great impacts.
Fine-tuned CLIP Models are Efficient Video Learners
In this work, we show that a simple Video Fine-tuned CLIP (ViFi-CLIP) baseline is generally sufficient to bridge the domain gap from images to videos
第四类:和前几类会有重复,但是我觉得归前四类
和上述感觉不一样,新的任务+旧的方法(呜呜呜我想做
Compositional Prompt Tuning with Motion Cues for Open-vocabulary Video Relation Detection
we present Relation Prompt (RePro) for Open-vocabulary Video Visual Relation Detection (Open-VidVRD), where conventional prompt tuning is easily biased to certain subject-object combinations and motion patterns. To this end, RePro addresses the two technical challenges of Open-VidVRD: 1) the prompt tokens should respect the two different semantic roles of subject and object, and 2) the tuning should account for the diverse spatio-temporal motion patterns of the subject-object compositions
根据特定任务设计的 prompt
TempCLR: Temporal Alignment Representation with Contrastive Learning
For long videos, given a paragraph of description where the sentences describe different segments of the video, by matching all sentence-clip pairs, the paragraph and the full video are aligned implicitly。we propose a contrastive learning framework TempCLR to compare the full video and the paragraph explicitly.We evaluate our approach on video retrieval, action step localization, and few-shot action recognition, and achieve consistent performance gain over all three tasks. Detailed ablation studies are provided to justify the approach design。
Bridge-Prompt: Towards Ordinal Action Understanding in Instructional Videos
we propose a prompt-based framework, Bridge-Prompt (Br-Prompt), to model the semantics across adjacent actions, so that it simultaneously exploits both out-of-context and contextual information from a series of ordinal actions in instructional videos. More specifically, we reformulate the individual action labels as integrated text prompts for supervision, which bridge the gap between individual action semantics. The generated text prompts are paired with corresponding video clips, and together co-train the text encoder and the video encoder via a contrastive approach. The learned vision encoder has a stronger capability for ordinal-action-related downstream tasks
根据特定任务设计的 prompt
Procedure-Aware Pretraining for Instructional Video Understanding
Our goal is to learn a video representation that is useful for downstream procedure understanding tasks in instructional videos.We build a PKG by combining information from a text-based procedural knowledge database and an unlabeled instructional video corpus and then use it to generate training pseudo labels with four novel pre-training objectives
这篇是过程图上下功夫
Learning Procedure-aware Video Representation from Instructional Videos and Their Narrations
Our method jointly learns a video representation to encode individual step concepts, and a deep probabilistic model to capture both temporal dependencies and immense individual variations in the step ordering.
这篇是a deep probabilistic model