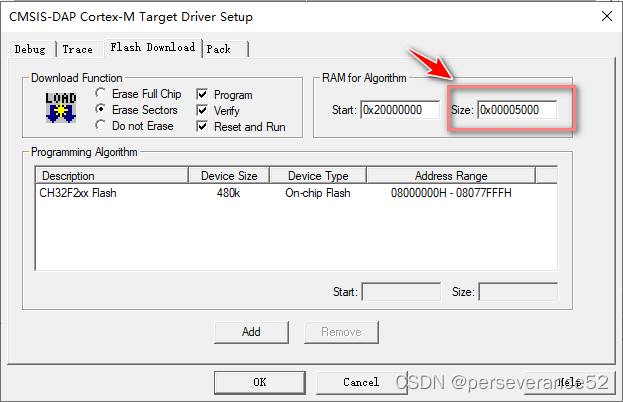
可以通过在mysql-client中执行以下 help 命令获得更多帮助:
help create table1 基本概念
在 Doris 中,数据都以表(Table)的形式进行逻辑上的描述。
1.1 Row & Column
一张表包括行(Row)和列(Column)。Row 即用户的一行数据。Column 用于描述一行数据中不同的字段。
Column 可以分为两大类:Key 和 Value。从业务角度看,Key 和 Value 可以分别对应维度列和指标列。从聚合模型的角度来说,Key 列相同的行,会聚合成一行。其中 Value 列的聚合方式由用户在建表时指定。关于更多聚合模型的介绍,可以参阅 Doris 数据模型:Data Model, Rollup & Prefix Index · apache/doris Wiki · GitHub
1.2 Tablet & Partition
在 Doris 的存储引擎中,用户数据被水平划分为若干个数据分片(Tablet,也称作数据分桶)。每个 Tablet 包含若干数据行。各个 Tablet 之间的数据没有交集,并且在物理上是独立存储的。
多个 Tablet 在逻辑上归属于不同的分区(Partition)。一个 Tablet 只属于一个 Partition。而一个 Partition 包含若干个 Tablet。因为 Tablet 在物理上是独立存储的,所以可以视为 Partition 在物理上也是独立。Tablet 是数据移动、复制等操作的最小物理存储单元。
若干个 Partition 组成一个 Table。Partition 可以视为是逻辑上最小的管理单元。数据的导入与删除,都可以或仅能针对一个 Partition 进行。
2 建表(Create Table)
使用 CREATE TABLE 命令建立一个表(Table)。更多详细参数可以查看:
HELP CREATE TABLE;首先切换数据库:
USE test_db;Doris 的建表是一个同步命令,命令返回成功,即表示建表成功。
可以通过 HELP CREATE TABLE; 查看更多帮助。
示例:
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] [database.]table_name
(column_definition1[, column_definition2, ...]
[, index_definition1[, ndex_definition12,]])
[ENGINE = [olap|mysql|broker|hive]]
[key_desc]
[COMMENT "table comment"];
[partition_desc]
[distribution_desc]
[rollup_index]
[PROPERTIES ("key"="value", ...)]
[BROKER PROPERTIES ("key"="value", ...)]2.1 字段类型
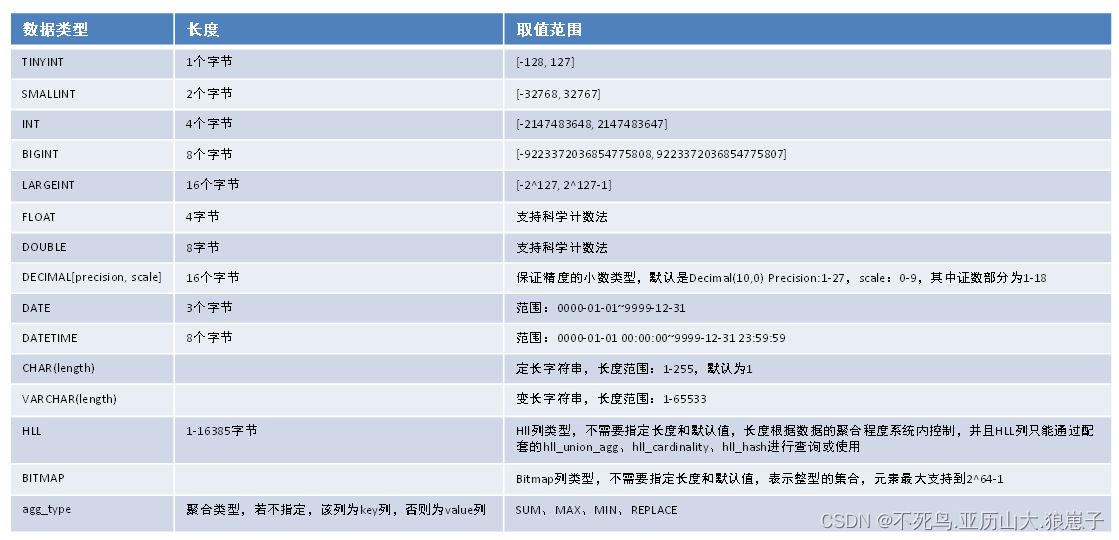
- TINYINT数据类型
长度: 长度为1个字节的有符号整型。
范围: [-128, 127]
转换: Doris可以自动将该类型转换成更大的整型或者浮点类型。使用CAST()函数可以将其转换成CHAR。
举例:
select cast(100 as char); - SMALLINT数据类型
长度: 长度为2个字节的有符号整型。
范围: [-32768, 32767]
转换: Doris可以自动将该类型转换成更大的整型或者浮点类型。使用CAST()函数可以将其转换成TINYINT,CHAR。
举例:
select cast(10000 as char);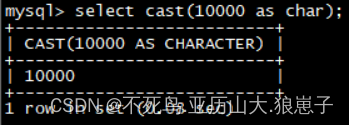
select cast(10000 as tinyint);
- INT数据类型
长度: 长度为4个字节的有符号整型。
范围: [-2147483648, 2147483647]
转换: Doris可以自动将该类型转换成更大的整型或者浮点类型。使用CAST()函数可以将其转换成TINYINT,SMALLINT,CHAR
举例:
select cast(111111111 as char);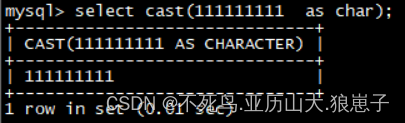
- BIGINT数据类型
长度: 长度为8个字节的有符号整型。
范围: [-9223372036854775808, 9223372036854775807]
转换: Doris可以自动将该类型转换成更大的整型或者浮点类型。使用CAST()函数可以将其转换成TINYINT,SMALLINT,INT,CHAR
举例:
select cast(9223372036854775807 as char);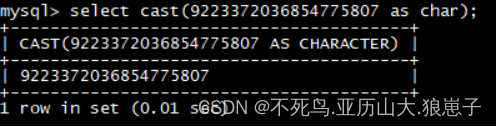
- LARGEINT数据类型
长度: 长度为16个字节的有符号整型。
范围: [-2^127, 2^127-1]
转换: Doris可以自动将该类型转换成浮点类型。使用CAST()函数可以将其转换成TINYINT,SMALLINT,INT,BIGINT,CHAR
举例:
select cast(922337203685477582342342 as double);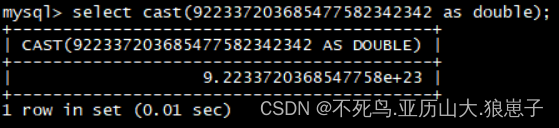
- FLOAT数据类型
长度: 长度为4字节的浮点类型。
范围: -3.40E+38 ~ +3.40E+38。
转换: Doris会自动将FLOAT类型转换成DOUBLE类型。用户可以使用CAST()将其转换成TINYINT, SMALLINT, INT, BIGINT, STRING, TIMESTAMP。
- DOUBLE数据类型
长度: 长度为8字节的浮点类型。
范围: -1.79E+308 ~ +1.79E+308。
转换: Doris不会自动将DOUBLE类型转换成其他类型。用户可以使用CAST()将其转换成TINYINT, SMALLINT, INT, BIGINT, STRING, TIMESTAMP。用户可以使用指数符号来描述DOUBLE 类型,或通过STRING转换获得。
- DECIMAL数据类型
DECIMAL[M, D]
保证精度的小数类型。M代表一共有多少个有效数字,D代表小数点后最多有多少数字。M的范围是[1,27],D的范围是[1,9],另外,M必须要大于等于D的取值。默认取值为decimal[10,0]。
precision: 1 ~ 27
scale: 0 ~ 9
lDATE数据类型
范围: [0000-01-01~9999-12-31]。默认的打印形式是’YYYY-MM-DD’。
- DATETIME数据类型
范围: [0000-01-01 00:00:00~9999-12-31 23:59:59]。默认的打印形式是’YYYY-MM-DD HH:MM:SS’。
- CHAR数据类型
范围: char[(length)],定长字符串,长度length范围1~255,默认为1。
转换:用户可以通过CAST函数将CHAR类型转换成TINYINT,,SMALLINT,INT,BIGINT,LARGEINT,DOUBLE,DATE或者DATETIME类型。
示例:
select cast(1234 as bigint);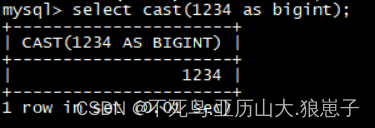
- VARCHAR数据类型
范围: char(length),变长字符串,长度length范围1~65535。
转换:用户可以通过CAST函数将CHAR类型转换成TINYINT,,SMALLINT,INT,BIGINT,LARGEINT,DOUBLE,DATE或者DATETIME类型。
示例:
select cast('2011-01-01' as date);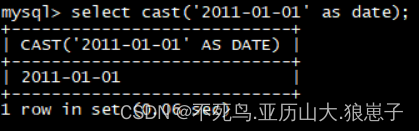
select cast('2011-01-01' as datetime);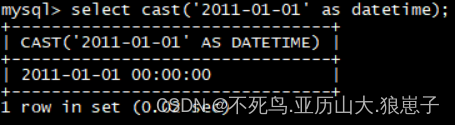
select cast(3423 as bigint);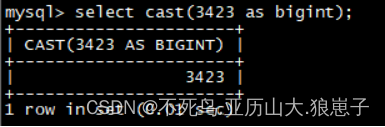
- HLL数据类型
范围:char(length),长度length范围1~16385。用户不需要指定长度和默认值、长度根据数据的聚合程度系统内控制,并且HLL列只能通过配套的hll_union_agg、hll_cardinality、hll_hash进行查询或使用
3 数据划分
Doris支持单分区和复合分区两种建表方式
单分区即数据不进行分区,数据只做 HASH 分布,也就是分桶
在复合分区中:
- 第一级称为 Partition,即分区。用户可以指定某一维度列作为分区列(当前只支持整型和时间类型的列),并指定每个分区的取值范围。
- 第二级称为 Distribution,即分桶。用户可以指定一个或多个维度列以及桶数对数据进行 HASH 分布。
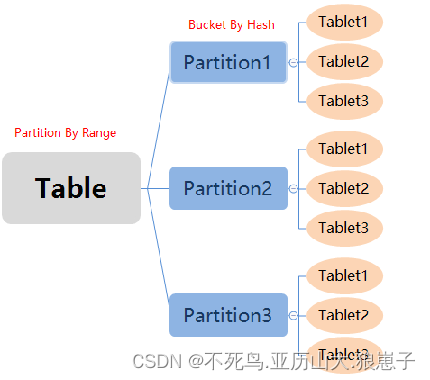
在 Doris 的存储引擎规则:
- 用户数据首先被划分成若干个分区(Partition),划分的规则通常是按照用户指定的分区列进行范围划分,比如按时间划分。
- 而在每个分区内,数据被进一步的按照Hash的方式分桶,分桶的规则是要找用户指定的分桶列的值进行Hash后分桶。每个分桶就是一个数据分片(Tablet),也是数据划分的最小逻辑单元。
- Partition 可以视为是逻辑上最小的管理单元。数据的导入与删除,都可以或仅能针对一个 Partition 进行。
- Tablet直接的数据是没有交集的,独立存储的。Tablet也是数据移动、复制等操作的最小物理存储单元。
3.1 单分区建表
建立一个名字为 table1 的逻辑表。分桶列为 siteid,桶数为 10。
这个表的 schema 如下:
- siteid:类型是INT(4字节), 默认值为10
- citycode:类型是SMALLINT(2字节)
- username:类型是VARCHAR, 最大长度为32, 默认值为空字符串
- pv:类型是BIGINT(8字节), 默认值是0; 这是一个指标列, Doris内部会对指标列做聚合操作, 这个列的聚合方法是求和(SUM)
CREATE TABLE table1
(
siteid INT DEFAULT '10',
citycode SMALLINT,
username VARCHAR(32) DEFAULT '',
pv BIGINT SUM DEFAULT '0'
)
AGGREGATE KEY(siteid, citycode, username)
DISTRIBUTED BY HASH(siteid) BUCKETS 10
PROPERTIES("replication_num" = "1");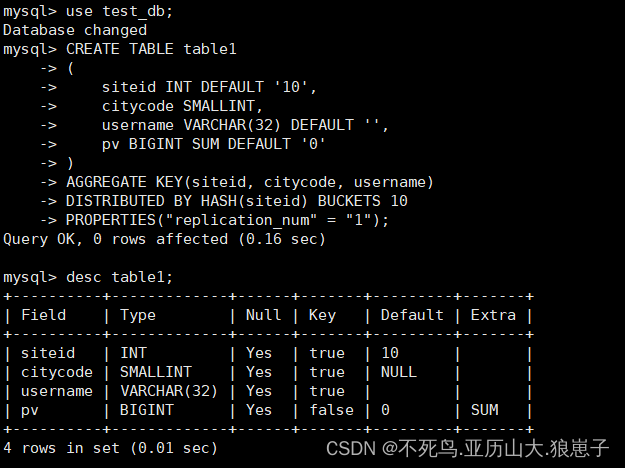
为适配不同的数据导入需求,Doris 系统提供了6种不同的导入方式。每种导入方式支持不同的数据源,存在不同的使用方式(异步,同步)。
所有导入方式都支持 csv 数据格式。其中 Broker load 还支持 parquet 和 orc 数据格式。
- Stream load
用户通过 HTTP 协议提交请求并携带原始数据创建导入。主要用于快速将本地文件或数据流中的数据导入到 Doris。导入命令同步返回导入结果。
- Insert
类似 MySQL 中的 Insert 语句,Doris 提供 INSERT INTO tbl SELECT ...; 的方式从 Doris 的表中读取数据并导入到另一张表。或者通过 INSERT INTO tbl VALUES(...); 插入单条数据。
- Broker load
通过 Broker 进程访问并读取外部数据源(如 HDFS)导入到 Doris。用户通过 Mysql 协议提交导入作业后,异步执行。通过 SHOW LOAD 命令查看导入结果。
- Multi load
用户通过 HTTP 协议提交多个导入作业。Multi Load 可以保证多个导入作业的原子生效。
- Routine load
用户通过 MySQL 协议提交例行导入作业,生成一个常驻线程,不间断的从数据源(如 Kafka)中读取数据并导入到 Doris 中。
- 通过S3协议直接导入
用户通过S3协议直接导入数据,用法和Broker Load 类似
插入数据:
Stream load方式:
curl --location-trusted -u root:123456 -H "label:table1_20210210" -H "column_separator:," -T table1_data http://node01:8030/api/test_db/table1/_stream_load 示例:
将 table1_data 导入 table1 中:vim table1_data
10,101,jim,2
11,101,grace,2
12,102,tom,2
13,102,bush,3
14,103,helen,3curl --location-trusted -u root:123456 -H "label:table1_20210210" -H "column_separator:," -T table1_data http://192.168.222.143:8030/api/test_db/table1/_stream_load
select * from table1;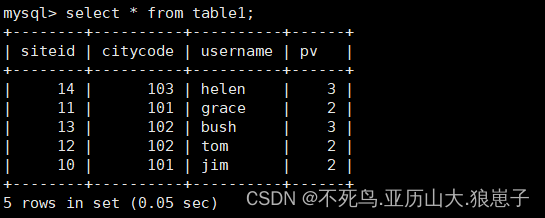
Insert方式:
直接执行语句
insert into table1 values(1,1,'user1',10);
insert into table1 values(1,1,'user1',10);
insert into table1 values(1,2,'user1',10);

注意:可以看到siteid=1 citycode=1 username=user1的数据聚合为20。
3.2 复合分区建表
建立一个名为table2的逻辑表
这个表的 schema 如下:
- event_day:类型是DATE,无默认值
- siteid:类型是INT(4字节), 默认值为10
- citycode:类型是SMALLINT(2字节)
- username:类型是VARCHAR, 最大长度为32, 默认值为空字符串
- pv:类型是BIGINT(8字节), 默认值是0; 这是一个指标列, Doris 内部会对指标列做聚合操作, 这个列的聚合方法是求和(SUM)
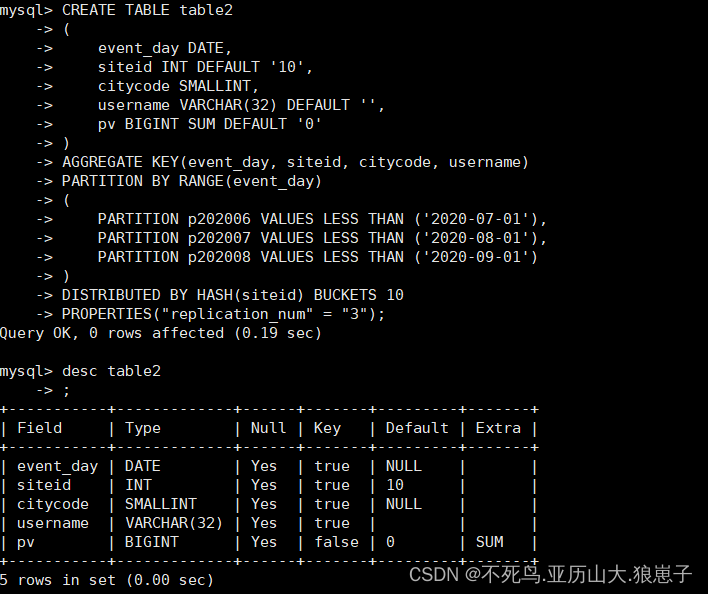
CREATE TABLE table2
(
event_day DATE,
siteid INT DEFAULT '10',
citycode SMALLINT,
username VARCHAR(32) DEFAULT '',
pv BIGINT SUM DEFAULT '0'
)
AGGREGATE KEY(event_day, siteid, citycode, username)
PARTITION BY RANGE(event_day)
(
PARTITION p202006 VALUES LESS THAN ('2020-07-01'),
PARTITION p202007 VALUES LESS THAN ('2020-08-01'),
PARTITION p202008 VALUES LESS THAN ('2020-09-01')
)
DISTRIBUTED BY HASH(siteid) BUCKETS 10
PROPERTIES("replication_num" = "3");
我们使用 event_day 列作为分区列,建立3个分区: p202106, p202107, p202108,每个分区使用 siteid 进行哈希分桶,桶数为10
- p202106:范围为 [最小值, 2021-07-01)
- p202107:范围为 [2021-07-01, 2021-08-01)
- p202108:范围为 [2021-08-01, 2020-09-01)
注意区间为左闭右开
导入数据:
将 table2_data 导入 table2 中:vim table2_data
2021-06-03|9|1|jack|3
2021-06-10|10|2|rose|2
2021-07-03|11|1|jim|2
2021-07-05|12|1|grace|2
2021-07-12|13|2|tom|2
2021-08-15|14|3|bush|3
2021-08-12|15|3|helen|3
curl --location-trusted -u root:123456 -H "label:table2_20200707" -H "column_separator:|" -T table2_data http://192.168.222.143:8030/api/test_db/table2/_stream_load
以下场景推荐使用复合分区
- 有时间维度或类似带有有序值的维度,可以以这类维度列作为分区列。分区粒度可以根据导入频次、分区数据量等进行评估。
- 历史数据删除需求:如有删除历史数据的需求(比如仅保留最近N 天的数据)。使用复合分区,可以通过删除历史分区来达到目的。也可以通过在指定分区内发送 DELETE 语句进行数据删除。
- 解决数据倾斜问题:每个分区可以单独指定分桶数量。如按天分区,当每天的数据量差异很大时,可以通过指定分区的分桶数,合理划分不同分区的数据,分桶列建议选择区分度大的列。
4 关于 Partition 和 Bucket 的数量和数据量的建议
- 一个表的 Tablet 总数量等于 (Partition num * Bucket num)。
- 一个表的 Tablet 数量,在不考虑扩容的情况下,推荐略多于整个集群的磁盘数量。
- 单个 Tablet 的数据量理论上没有上下界,但建议在 1G - 10G 的范围内。如果单个 Tablet 数据量过小,则数据的聚合效果不佳,且元数据管理压力大。如果数据量过大,则不利于副本的迁移、补齐,且会增加 Schema Change 或者 Rollup 操作失败重试的代价(这些操作失败重试的粒度是 Tablet)。
- 当 Tablet 的数据量原则和数量原则冲突时,建议优先考虑数据量原则。
- 在建表时,每个分区的 Bucket 数量统一指定。但是在动态增加分区时(ADD PARTITION),可以单独指定新分区的 Bucket 数量。可以利用这个功能方便的应对数据缩小或膨胀。
- 一个 Partition 的 Bucket 数量一旦指定,不可更改。所以在确定 Bucket 数量时,需要预先考虑集群扩容的情况。比如当前只有 3 台 host,每台 host 有 1 块盘。如果 Bucket 的数量只设置为 3 或更小,那么后期即使再增加机器,也不能提高并发度。
- 举一些例子:假设在有10台BE,每台BE一块磁盘的情况下。如果一个表总大小为 500MB,则可以考虑4-8个分片。5GB:8-16个。50GB:32个。500GB:建议分区,每个分区大小在 50GB 左右,每个分区16-32个分片。5TB:建议分区,每个分区大小在 50GB 左右,每个分区16-32个分片。
注:表的数据量可以通过 show data 命令查看,结果除以副本数,即表的数据量。