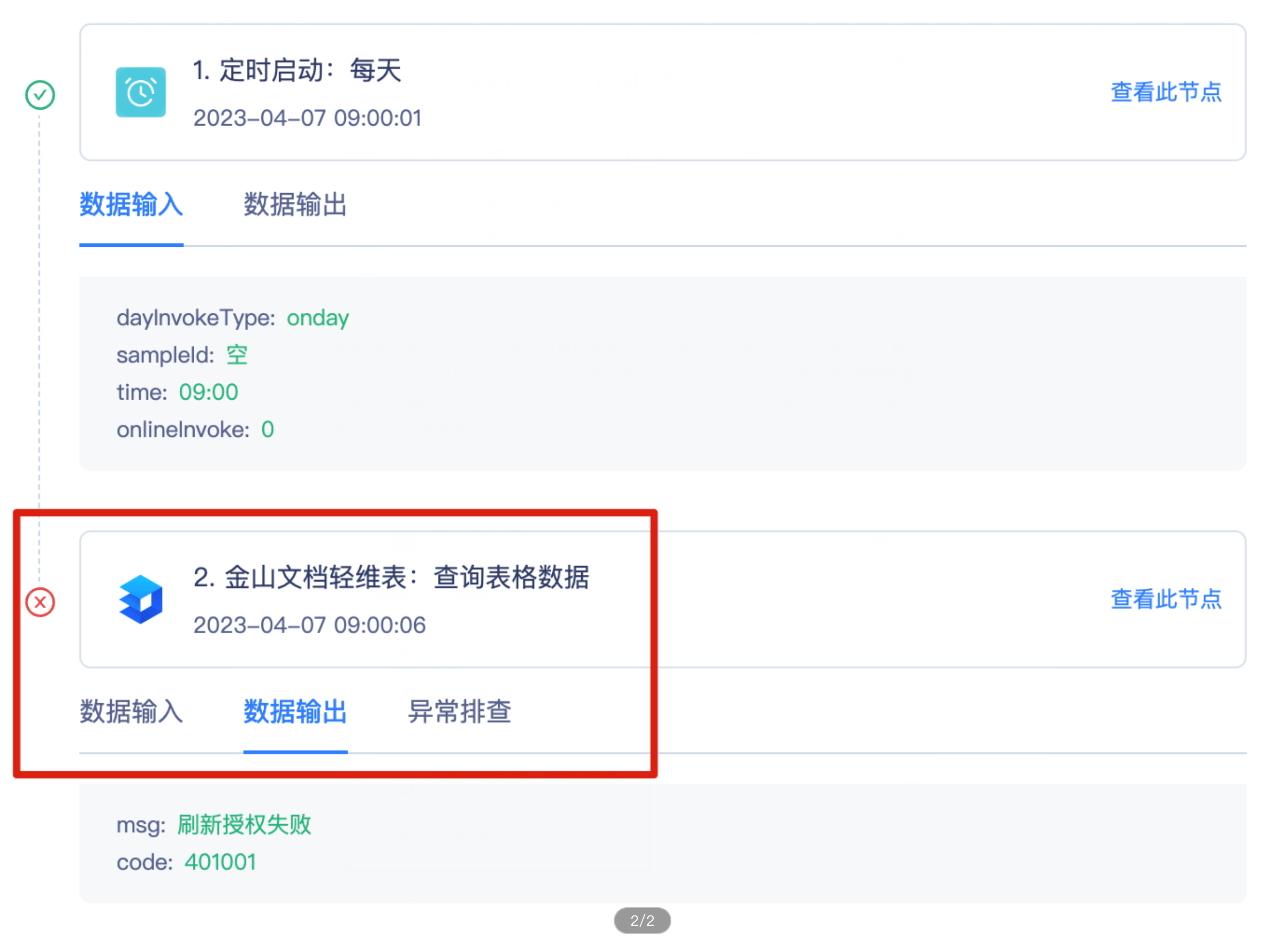
Reactor是一种高性能网络模型,在netty、redis、nginx、kafaka、memcached等重要组件,以及唯品会自研的OSP框架都有应用,Reactor模型在提升性能和解耦方面都做得非常好,其编程思想也可以运用到业务系统的开发当中,本文主要说明Reactor模型思想在库存指令模块中的运用,希望有一定的借鉴意义。
就供应链库存相关的业务知识,在此咱不赘述,可通过《写给供应链产品经理:库存管理与系统设计》(http://www.360doc.com/content/20/1208/08/72533943_950087456.shtml)一文了解相关业务知识,供应链的同学可以顺带看看写给供应链产品的系列文章,里面还涉及到订单,仓储,物流等相关业务知识。
Reactor模型介绍
Reactor 模型也叫做反应器设计模式,是一种为处理服务请求并发提交到一个或者多个服务处理器的事件设计模式,当请求抵达后,通过服务处理器将这些请求采用多路分离的方式分发给相应的请求处理器,目前多用于高并发IO场景。Doug Lea著名的文章《Scalable IO in Java》(http://gee.cs.oswego.edu/dl/cpjslides/nio.pdf)对Reactor模型做了较为详细的定义。
Reactor 模式主要由 Reactor 和处理器 Handler 这两个核心部分组成:
-
Reactor:负责监听和分发事件,事件类型包含连接事件、读写事件;
-
Handler :负责处理事件,如 read -> 业务逻辑 (decode + compute + encode)-> send;
这样理解的话,Reactor模型似乎是门面模式和策略模式的组合。此外,Reactor模式也是一种典型的事件驱动的编程模型,它逆置了程序处理的流程,其基本的思想就是好莱坞法则(Don’t call us, we’ll call you),所以Reactor模型有观察者模式的影子在。在实际的业务系统开发过程中,当处理异步任务时,事件驱动机制,能达到很好的解耦效果,所以在此简单阐述事件驱动机制。
事件驱动机制
事件驱动程序的基本结构是由一个事件收集器、一个事件发送器和一个事件处理器组成。
-
事件收集器专门负责收集所有事件,它可以是一个MQ消息的接受者,也可以一个轮询线程。
-
事件发送器负责将收集器收集到的事件分发到目标对象中。
-
事件处理器做具体的事件响应工作,它往往要到实现阶段才完全确定,因而一般定义为接口类。
在实际业务场景中,比如库存系统入库指令执行后,仍需要做推送销售库存,通知PO收货等动作。如果直接直接把这部分动作放在入库指令当中,势必造成过高的耦合度。此时如果采用事件机制就能达到很好的解偶效果,只需在入库指令完成后,生成事件,通知相应的事件处理器完成动作即可。
Reactor在网络IO中的应用
Reactor是在处理高并发网络IO请求场景中发展出来的一种编程模型,通过网络编程的一个发展过程,以Netty为例,我们可以更好的感受到Reactor模型的价值所在。
传统网络IO编程
在JDK1.4推出Java NIO之前,基于Java的所有Socket通信都采用了同步阻塞模式(BIO),这种一请求一应答的通信模型简化了上层的应用开发,但是在性能和可靠性方面却存在着巨大的瓶颈。Java最初和最原始的网络服务器程序,是用一个while循环,不断地监听端口是否有新的连接。如果有,那么就调用一个处理函数来处理,示例代码如下:
while(true){
socket = accept(); //阻塞,接收连接
handle(socket) ; //读取数据、业务处理、写入结果
}
这种方法的最大问题是:如果前一个网络连接的handle(socket)没有处理完,那么后面的连接请求没法被接收,于是后面的请求通通会被阻塞住,服务器的吞吐量就太低了。对于服务器来说,这是一个严重的问题。为了解决这个严重的连接阻塞问题,出现了一个极为经典模式:Connection Per Thread(一个线程处理一个连接)模式,早期版本的Tomcat服务器,就是这样实现的,但这种模式对应于大量的连接,需要耗费大量的线程资源,对线程资源要求太高。
因此,在很长一段时间里,大型的应用服务器都采用C或者C++语言开发,因为它们可以直接使用操作系统提供的异步I/O或者AIO能力。JDK1.4才提供新的NIO类库,但是它依然有不完善的地方。直到JDK1.7正式发布,对原来的NIO类库进行了升级,称为NIO2.0,Java才更好的支持非阻塞编程的发展和应用。
基于Java NIO,Netty实现了Reactor模型。在线程的处理上可以将Reactor模型分为:
-
单Reactor单线程模型
-
单Reactor多线程模型
-
主从Reactor多线程模型
不同的场景可以采用的不用模型来处理,如netty实现的主从Reactor多线程模型,而Redis则采用单 Reactor单线程模型,Redis 6.0引入了 IO 多线程,把读写请求数据的逻辑,用多线程处理,提升并发性能,但处理请求的逻辑依旧是单线程处理。
单Reactor单线程模型:
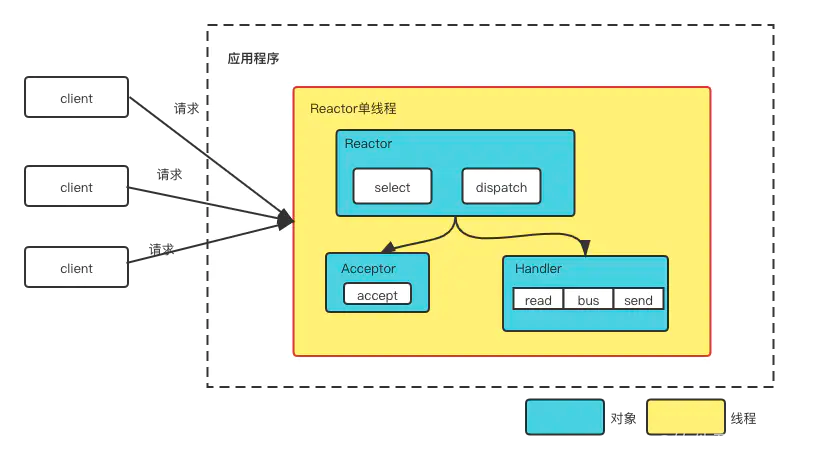
-
Reactor对象通过select监控客户端请求事件,收到事件后通过Dispatch进行分发;
-
如果是建立连接请求事件,则由Acceptor通过accept处理连接请求,然后创建Handler对象处理连接完成后的后续业务处理。如果不是连接请求事件,Reactor则会分发调用连接对应的Handler来响应;
-
Handler会完成Read->业务处理->Send的完整业务逻辑;
在单线程反应器模式中,模型简单,没有多线程、进程通信、竞争的问题。但Reactor反应器和Handler处理器,都执行在同一条线程上就会带来一个问题:当其中某个Handler阻塞时,会导致其他所有的Handler都得不到执行。在这种场景下,如果被阻塞的Handler不仅仅负责输入和输出处理的业务,还包括负责连接监听的AcceptorHandler处理器。这个是非常严重的问题,一旦AcceptorHandler处理器阻塞,会导致整个服务不能接收新的连接,使得服务器变得不可用,为此发展出了Reactor多线程模型。
单Reactor多线程模型
既然Reactor和Handler挤在一个线程会造成性能缺陷。那么,可以使用多线程,对其进行改造和演进。
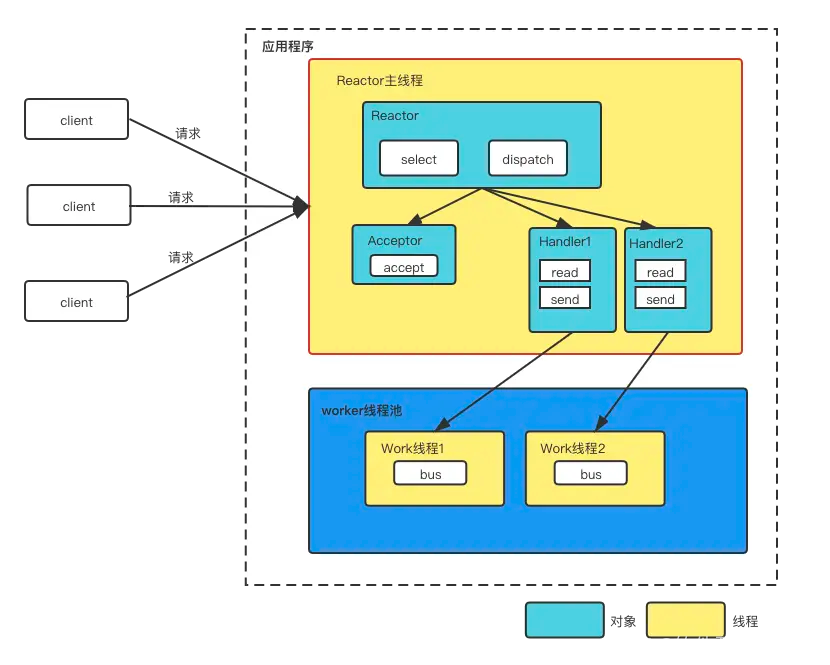
-
Reactor对象通过select监控客户端请求,当请求事件达到后,通过dispatch分发请求;
-
若是建立连接的事件,则通过Acceptor的accept处理连接请求,然后创建Handler事件来处理后续逻辑;
-
如果不是建立连接事件,则通过Reactor分发到连接对应的Handler来处理,并通过worker线程池处理业务;
-
worker线程池会分配独立的线程去完成Read->业务处理->Send的完整业务逻辑;
在多线程模式下,处理实际业务的Handler不再阻塞连接请求,可以充分利用多核CPU的能力。但多线程数据共享和访问比较复杂,Reactor依旧是单线程去处理所有的事件监听和响应,在高并发下依旧存在性能问题。
这个时候我们考虑能不能把连接事件和读写事件的监听放在不同的Reactor中呢,这样能进一步提升性能,因此又演变出了主从Reactor多线程模型。
主从reactor多线程模型
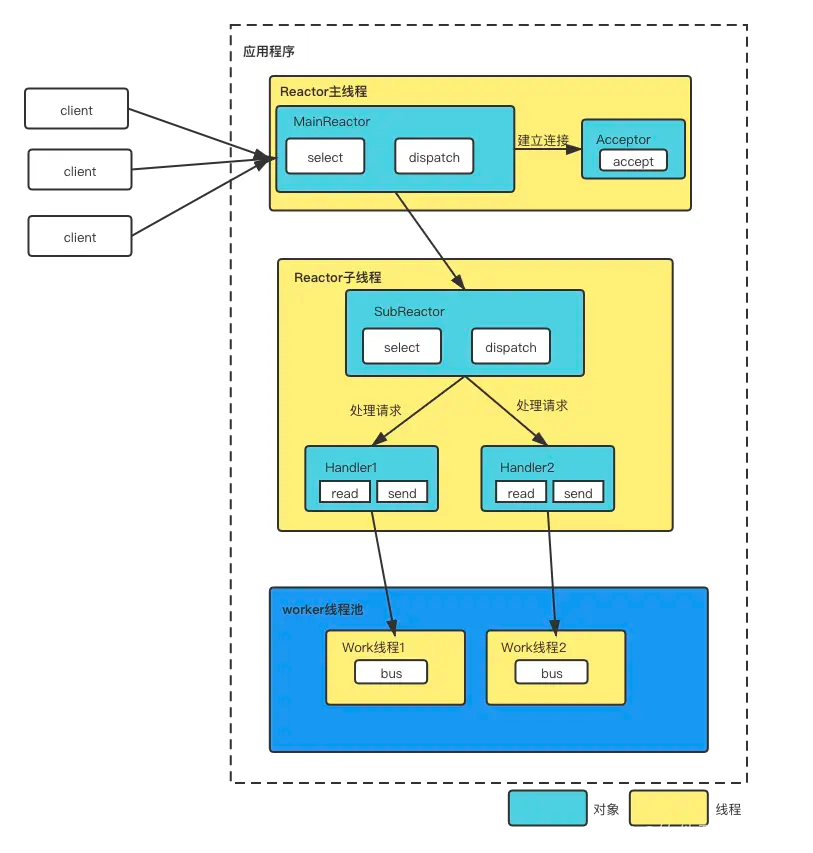
-
Reactor主线程MainReactor对象通过select监听连接事件,收到事件后,通过Acceptor处理事件;
-
当Accept处理连接事件后,MainReactor将连接分配给SubReactor;
-
SubReactor将连接加入到连接队列进行监听,并创建Handler进行各种事件处理;
-
当有新事件发生时,SubReactor将调用对应的Handler处理;
-
worker线程池会分配独立的线程去完成Read->业务处理->Send的完整业务逻辑;
在主从模式下,MainReactor主要处理连接事件,SubReactor处理IO事件,并且处理具体业务的Handler置于独立的线程池中,最大限度的提升了性能,而且扩展性和复用性都极好。
讲到这,似乎Reactor模型与生产者消费者模型极为相似,但实际还是有所区别,在生产者消费者模型中,一个或多个生产者将事件加入到一个队列中,一个或多个消费者主动地从这个队列中提取事件来处理。而Reactor模型是基于查询的,没有专门的队列去缓冲存储IO事件,查询到IO事件之后,反应器会根据不同IO选择键(事件)将其分发给对应的Handler处理器来处理。
Reactor模式和观察者模型也有相似之处,在Reactor模型中,当查询到IO事件后,服务处理程序使用单路/多路分发(Dispatch)策略,同步地分发这些IO事件。观察者模式(也被称作发布/订阅模式)它定义了一种依赖关系,让多个观察者同时监听某一个主题(Topic),这个主题对象在状态发生变化时,会通知所有观察者,它们能够执行相应的处理。在Reactor模型基本上是一个事件绑定到一个(组)Handler处理器(为提高复用性和尽可能解耦,一般一个业务处理流程会拆分成多个handler,通过责任链模式串联执行完成业务)。在观察者模式中,同一个时刻,同一个主题可以被订阅过的多个观察者处理。
好,行文至此,Reactor相关的背景知识介绍完毕,在这过程中,谈到了很多OOP原则、设计模式等编程思想。下文将介绍如何借鉴其思想运用到具体的业务系统开发当中来。
库存指令模块设计
库存指令模块的需求背景
库存是供应链之魂,库存业务知识在此不做详细叙述,感兴趣的同学可以参看前文提到的文档。我们可以简单的把库存系统理解为一个用于记录仓库货品数量的程序,货品的数量会因为某些业务形态而发生变化,具体的业务形态如下表。根据业务形态变化完成库存变更的这一功能模块,就是我们将要聊的库存指令模块。
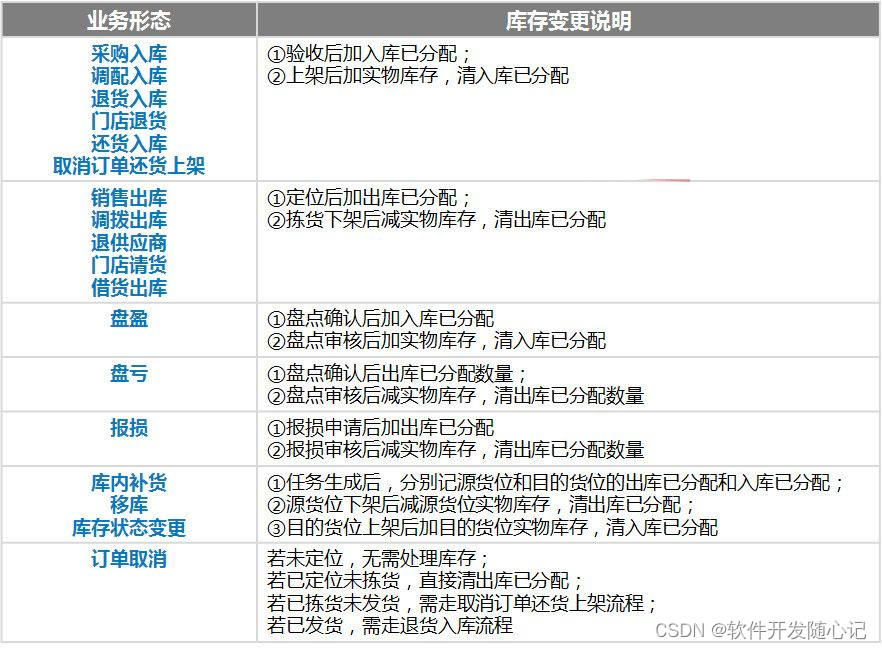
为满足库存数量随业务形态做相应的变更,库存系统需要对外暴露一系列的库存指令,这些指令和业务形态一一对应,具体的业务系统发送业务形态所对应的库存指令给到库存系统,库存系统就可根据具体的指令完成库存变更。接受外部业务系统指令,并根据指令完成相应库存变更这一功能模块就是库存指令模块。
在此业务背景下,库存指令设计会有如下几点要求:
-
对外暴露的指令接口尽可能少(1~2个),一方面便于管理指令入口,另一方面也方便调用方下发各类指令;
-
库存指令的本质是对库存做调增或调减,但外部系统所下发的库存维度较粗,无法告知库存系统需要扣减或调增的具体数据行,所以在库存内部需要定位到某(几)条具体的库存数据行。此外某些指令给到库存系统,可能需要执行多个动作,比如采购入库,就得执行扣减在途和增加在库存两个动作。鉴于此,外部业务系统下发的指令需进行拆解,指令的拆解有点类似网络IO编程中的解码操作。
-
随着业务发展指令数会增多,尽可能做到代码的解耦和高可复用性;
-
指令执行是对库存做增量操作,接口必须实现幂等,并且指令支持重试(本人归纳总结接口设计的原则:https://flowus.cn/share/8d813443-6f04-4990-a9b7-3091a111d9cc);
库存指令模块详设
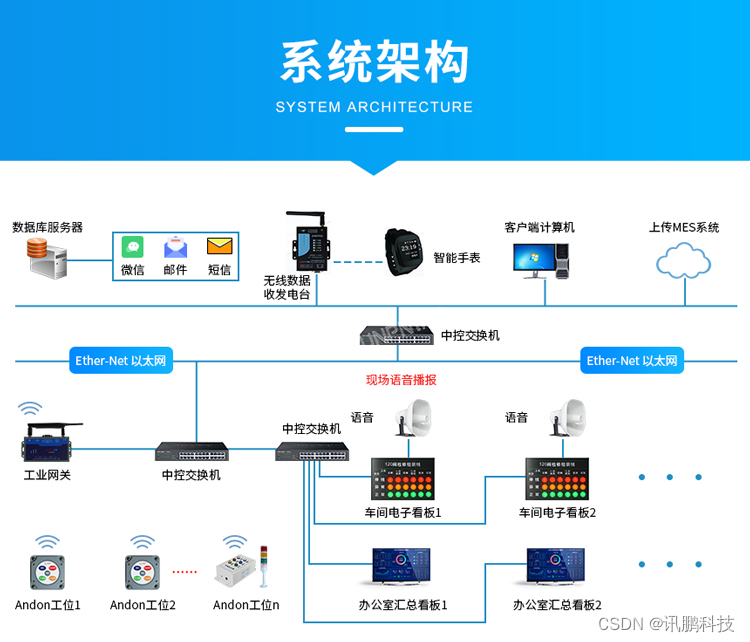
理清业务需求之后,指令的整个处理过程可拆分成指令的接收,拆解和执行,三个Reactor分别完成接收、拆解、执行功能。拆解和执行也可以放在一个Reactor模型当中,通过流水线Pipeline串联,但若如此,每种指令都需构造对应的流水线,相对复杂,分拆两个Reactor,对于业务开发者来说,需要关注的事情更少。库存指令模块整体流程设计如下图:
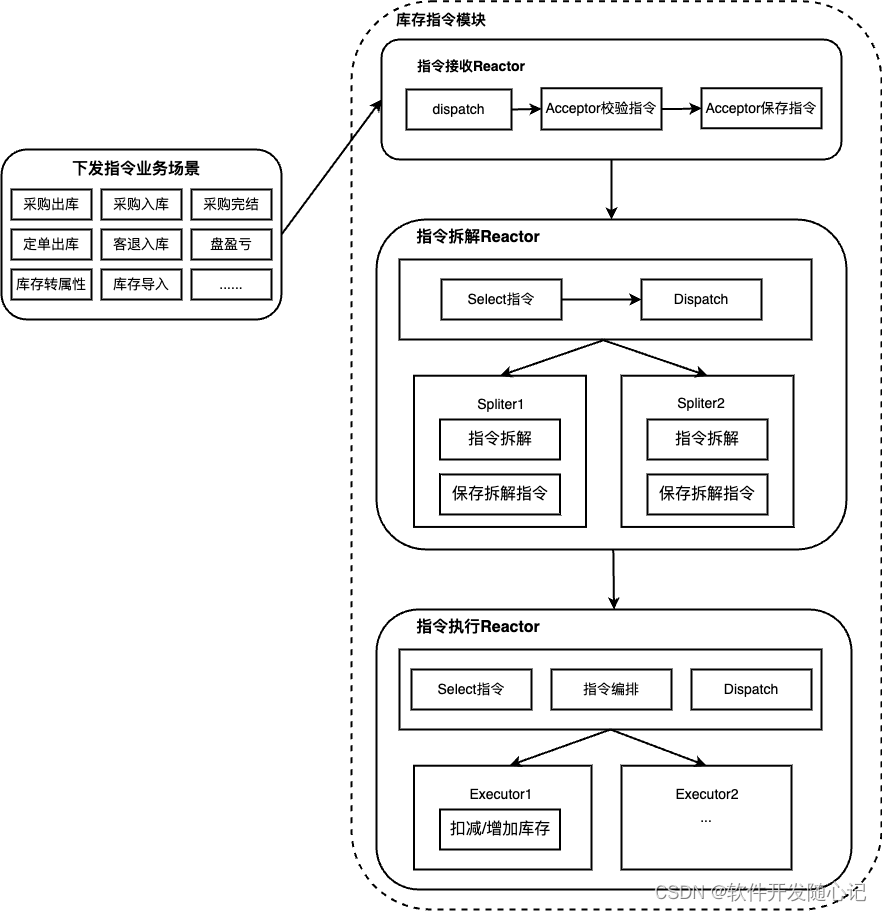
接收Reactor负责指令的校验与接收,这与主从Reactor多线程模型中MainReactor相似,但MainReactor只负责建立连接,场景单一,只需一个Accepor就可处理客户端发送的连接请求。但在指令接收Reactor中,需要对指令参数进行校验,由于各类指令所传递的参数有所不同,所以需要Dispatch分发给不同的Acceptor来完成指令的接收。在Reactor模型处理IO事件流程中,首先需完成通道(channel)的注册,在指令接收Reactor中同样如此,只是这里注册的并非channel,而是业务指令类型,这里可通过配置完成,只有配置过的指令,指令模块才会检验接收。
拆解Reactor通过不断轮询接收过来的待拆解状态指令,当发生指令拆解事件时,由分发器dispatch给到不同的spliter,spliter的工作就是完成指令的拆解,找出需要调增或调减的具体的库存数据行,或者释放占用的库存数据行。拆解完成的指令会保存到另外一张表里,这张表里的指令数据才是执行Ractor真正去执行的指令。
执行Reactor轮询待执行状态的指令,对轮训到的执行先做指令的编排,调整指令的执行顺序,然后dispatch给到不同的Execuor(指令执行器)去处理,指令的执行需要保证数据的一致性,这就需要锁的参与了,关于库存分布式锁,可以参看文章:https://blog.csdn.net/vipshop_fin_dev/article/details/126691317?spm=1001.2014.3001.5502。当业务系统需要感知指令执行结果时,Executor可回抛执行结果至具体的调用方。
在这样的设计方案下,代码耦合度较低,各类指令处理互不影响或阻塞,且接收器、拆解器、执行器,可根据具体的业务场景进行复用。
作者:西门吹雪
本人之前写的一些技术博客文章:
Mysql分布式锁设计:https://blog.csdn.net/vipshop_fin_dev/article/details/126691317
荷兰国旗&快排优化:https://blog.csdn.net/vipshop_fin_dev/article/details/120407403
JOOQ入门实践:https://blog.csdn.net/vipshop_fin_dev/article/details/117914580
ElasticSearch入门实践:https://blog.csdn.net/vipshop_fin_dev/article/details/114497429
《数据中台-让数据用起来》读书笔记:https://blog.csdn.net/vipshop_fin_dev/article/details/111412172
自动驾驶那些事:https://blog.csdn.net/vipshop_fin_dev/article/details/108431352
学习那些事:https://blog.csdn.net/vipshop_fin_dev/article/details/107497555