目录标题
- 实验1
- 实验内容
- 绘制散点图
- 将数据保存到MySQL
# import os
# os.getcwd()
import findspark
findspark.init()
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
实验1
实验内容
通过DataFrame API或者Spark SQL对数据源进行修改列类型、查询、排序、去重、分组、过滤等操作。
实验1: 已知SalesOrders\part-00000是csv格式的订单主表数据,它共包含4列,分别表示:订单ID、下单时间、用户ID、订单状态
(1) 以上述文件作为数据源,生成DataFrame,列名依次为:order_id, order_date, cust_id, order_status,列类型依次为:int, timestamp, int, string。然后并查看其前10行数据(列数据不能被截断)和表结构
from pyspark.sql.types import TimestampType
# 生成DataFrame
dfs = spark.read.csv(r"file:\D:\juniortwo\spark\Spark2023-02-20\SalesOrders\part-00000",\
header = False,inferSchema = True)
# 修改列名
dfs = dfs.withColumnRenamed('_c0','order_id')\
.withColumnRenamed('_c1','order_date')\
.withColumnRenamed('_c2','cust_id')\
.withColumnRenamed('_c3','order_status')
# 修改列类型
dfs = dfs.withColumn('order_date',dfs['order_date'].cast("timestamp"))
# 查看前10行和表结构
dfs.printSchema()
dfs.show(10,truncate=False)
root
|-- order_id: integer (nullable = true)
|-- order_date: timestamp (nullable = true)
|-- cust_id: integer (nullable = true)
|-- order_status: string (nullable = true)
+--------+-------------------+-------+---------------+
|order_id|order_date |cust_id|order_status |
+--------+-------------------+-------+---------------+
|1 |2013-07-25 00:00:00|11599 |CLOSED |
|2 |2013-07-25 00:00:00|256 |PENDING_PAYMENT|
|3 |2013-07-25 00:00:00|12111 |COMPLETE |
|4 |2013-07-25 00:00:00|8827 |CLOSED |
|5 |2013-07-25 00:00:00|11318 |COMPLETE |
|6 |2013-07-25 00:00:00|7130 |COMPLETE |
|7 |2013-07-25 00:00:00|4530 |COMPLETE |
|8 |2013-07-25 00:00:00|2911 |PROCESSING |
|9 |2013-07-25 00:00:00|5657 |PENDING_PAYMENT|
|10 |2013-07-25 00:00:00|5648 |PENDING_PAYMENT|
+--------+-------------------+-------+---------------+
only showing top 10 rows
(2) 仅显示(1)中DataFrame的order_status列,并对该列去重、降序排序(注意检查结果对不对)
方法一:使用DataFrame API:select(), distinct(), orderBy()
# 去重
dfs2 = dfs.select('order_status').distinct()
# 降序排序
dfs2 = dfs2.orderBy('order_status', ascending = False)
dfs2.show()
+---------------+
| order_status|
+---------------+
|SUSPECTED_FRAUD|
| PROCESSING|
|PENDING_PAYMENT|
| PENDING|
| PAYMENT_REVIEW|
| ON_HOLD|
| COMPLETE|
| CLOSED|
| CANCELED|
+---------------+
方法二:使用Spark SQL
from pyspark.sql.functions import col
dfs.createOrReplaceTempView('dfs_view')
dfs2_2 = spark.sql("select distinct order_status from dfs_view \
order by order_status desc")
# dfs2_2.orderBy(col('order_status').desc()).show()
dfs2_2.show()
+---------------+
| order_status|
+---------------+
|SUSPECTED_FRAUD|
| PROCESSING|
|PENDING_PAYMENT|
| PENDING|
| PAYMENT_REVIEW|
| ON_HOLD|
| COMPLETE|
| CLOSED|
| CANCELED|
+---------------+
(3) 将(1)中DataFrame的order_id列更改为string类型,然后查看其Schema是否更改成功
方法一:使用DataFrame API:withColumn()
from pyspark.sql.types import StringType
dfs3 = dfs.withColumn('order_id',dfs['order_id'].cast(StringType()))
dfs3.printSchema()
root
|-- order_id: string (nullable = true)
|-- order_date: timestamp (nullable = true)
|-- cust_id: integer (nullable = true)
|-- order_status: string (nullable = true)
方法二:使用Spark SQL
dfs.createOrReplaceTempView("dfs3_view")
dfs3_2 = spark.sql("select cast(order_id as string) from dfs3_view")
dfs3_2.printSchema()
root
|-- order_id: string (nullable = true)
(4) 找出(1)中DataFrame的order_id大于10,小于20的行,并通过show()方法显示
方法一:使用DataFrame API:filter()
dfs4 = dfs.filter("order_id>10").filter("order_id<20")
dfs4.show()
+--------+-------------------+-------+---------------+
|order_id| order_date|cust_id| order_status|
+--------+-------------------+-------+---------------+
| 11|2013-07-25 00:00:00| 918| PAYMENT_REVIEW|
| 12|2013-07-25 00:00:00| 1837| CLOSED|
| 13|2013-07-25 00:00:00| 9149|PENDING_PAYMENT|
| 14|2013-07-25 00:00:00| 9842| PROCESSING|
| 15|2013-07-25 00:00:00| 2568| COMPLETE|
| 16|2013-07-25 00:00:00| 7276|PENDING_PAYMENT|
| 17|2013-07-25 00:00:00| 2667| COMPLETE|
| 18|2013-07-25 00:00:00| 1205| CLOSED|
| 19|2013-07-25 00:00:00| 9488|PENDING_PAYMENT|
+--------+-------------------+-------+---------------+
方法二:使用Spark SQL
dfs.createOrReplaceTempView("dfs4_view")
dfs4_2 = spark.sql("select order_id,order_date,cust_id,order_status from dfs4_view\
where order_id>10 and order_id<20")
dfs4_2.show()
+--------+-------------------+-------+---------------+
|order_id| order_date|cust_id| order_status|
+--------+-------------------+-------+---------------+
| 11|2013-07-25 00:00:00| 918| PAYMENT_REVIEW|
| 12|2013-07-25 00:00:00| 1837| CLOSED|
| 13|2013-07-25 00:00:00| 9149|PENDING_PAYMENT|
| 14|2013-07-25 00:00:00| 9842| PROCESSING|
| 15|2013-07-25 00:00:00| 2568| COMPLETE|
| 16|2013-07-25 00:00:00| 7276|PENDING_PAYMENT|
| 17|2013-07-25 00:00:00| 2667| COMPLETE|
| 18|2013-07-25 00:00:00| 1205| CLOSED|
| 19|2013-07-25 00:00:00| 9488|PENDING_PAYMENT|
+--------+-------------------+-------+---------------+
(5) 根据(1)中DataFrame, 找出order_status等于COMPLETE或者CLOSED的订单,并分组统计这两种状态的订单数量。通过show()方法显示
方法一:使用DataFrame API:filter(), groupBy()
dfs.filter("order_status in ('COMPLETE','CLOSED')")\
.groupBy('order_status').count().show()
+------------+-----+
|order_status|count|
+------------+-----+
| COMPLETE|22899|
| CLOSED| 7556|
+------------+-----+
方法二:使用Spark SQL
dfs.createOrReplaceTempView("dfs5_view")
spark.sql("select order_status, count(order_status) as count from dfs5_view \
where order_status == 'COMPLETE' or order_status == 'CLOSED' \
group by order_status").show()
+------------+-----+
|order_status|count|
+------------+-----+
| COMPLETE|22899|
| CLOSED| 7556|
+------------+-----+
(6) 根据(1)中DataFrame, 分别统计2013年和2014年的订单数量
方法一:使用DataFrame API:withColumn(), groupBy(), count()
# dfs.show(1000)
from pyspark.sql.functions import year
dfs.withColumn('order_date',year('order_date'))\
.groupBy('order_date').count().show()
+----------+-----+
|order_date|count|
+----------+-----+
| 2013|30662|
| 2014|38221|
+----------+-----+
dfs.printSchema()
root
|-- order_id: integer (nullable = true)
|-- order_date: timestamp (nullable = true)
|-- cust_id: integer (nullable = true)
|-- order_status: string (nullable = true)
方法二:使用Spark SQL
dfs.createOrReplaceTempView("dfs6_view")
spark.sql("select year(order_date) as order_date, count(year(order_date)) \
as count from dfs6_view\
group by year(order_date)").show()
+----------+-----+
|order_date|count|
+----------+-----+
| 2013|30662|
| 2014|38221|
+----------+-----+
(7) 根据(1)中DataFrame, 找出下单次数最多的前10个客户ID
方法一:使用DataFrame API
from pyspark.sql.functions import col
dfs.withColumn('cust_id',col('cust_id'))\
.groupBy('cust_id').count()\
.orderBy('count',ascending = False).show(10)
+-------+-----+
|cust_id|count|
+-------+-----+
| 569| 16|
| 12431| 16|
| 5897| 16|
| 6316| 16|
| 12284| 15|
| 5654| 15|
| 5283| 15|
| 221| 15|
| 4320| 15|
| 5624| 15|
+-------+-----+
only showing top 10 rows
方法二:使用Spark SQL
dfs.createOrReplaceTempView("dfs7_view")
spark.sql("select cust_id,count(cust_id) as count from dfs7_view \
group by cust_id order by count desc").show(10)
+-------+-----+
|cust_id|count|
+-------+-----+
| 569| 16|
| 12431| 16|
| 5897| 16|
| 6316| 16|
| 12284| 15|
| 5654| 15|
| 5283| 15|
| 4320| 15|
| 221| 15|
| 5624| 15|
+-------+-----+
only showing top 10 rows
(8) 根据(1)中DataFrame的order_date列,创建一个新列,该列数据是order_date距离今天的天数
方法一:使用DataFrame API
from pyspark.sql.functions import current_date,datediff
dfs.withColumn('days',datediff(col('order_date'),current_date())).show()
+--------+-------------------+-------+---------------+-----+
|order_id| order_date|cust_id| order_status| days|
+--------+-------------------+-------+---------------+-----+
| 1|2013-07-25 00:00:00| 11599| CLOSED|-3542|
| 2|2013-07-25 00:00:00| 256|PENDING_PAYMENT|-3542|
| 3|2013-07-25 00:00:00| 12111| COMPLETE|-3542|
| 4|2013-07-25 00:00:00| 8827| CLOSED|-3542|
| 5|2013-07-25 00:00:00| 11318| COMPLETE|-3542|
| 6|2013-07-25 00:00:00| 7130| COMPLETE|-3542|
| 7|2013-07-25 00:00:00| 4530| COMPLETE|-3542|
| 8|2013-07-25 00:00:00| 2911| PROCESSING|-3542|
| 9|2013-07-25 00:00:00| 5657|PENDING_PAYMENT|-3542|
| 10|2013-07-25 00:00:00| 5648|PENDING_PAYMENT|-3542|
| 11|2013-07-25 00:00:00| 918| PAYMENT_REVIEW|-3542|
| 12|2013-07-25 00:00:00| 1837| CLOSED|-3542|
| 13|2013-07-25 00:00:00| 9149|PENDING_PAYMENT|-3542|
| 14|2013-07-25 00:00:00| 9842| PROCESSING|-3542|
| 15|2013-07-25 00:00:00| 2568| COMPLETE|-3542|
| 16|2013-07-25 00:00:00| 7276|PENDING_PAYMENT|-3542|
| 17|2013-07-25 00:00:00| 2667| COMPLETE|-3542|
| 18|2013-07-25 00:00:00| 1205| CLOSED|-3542|
| 19|2013-07-25 00:00:00| 9488|PENDING_PAYMENT|-3542|
| 20|2013-07-25 00:00:00| 9198| PROCESSING|-3542|
+--------+-------------------+-------+---------------+-----+
only showing top 20 rows
方法二:使用Spark SQL
dfs.createOrReplaceTempView("dfs8_view")
spark.sql("select order_id,order_date,cust_id,order_status,datediff(order_date,\
current_date) as days from dfs8_view").show()
+--------+-------------------+-------+---------------+-----+
|order_id| order_date|cust_id| order_status| days|
+--------+-------------------+-------+---------------+-----+
| 1|2013-07-25 00:00:00| 11599| CLOSED|-3542|
| 2|2013-07-25 00:00:00| 256|PENDING_PAYMENT|-3542|
| 3|2013-07-25 00:00:00| 12111| COMPLETE|-3542|
| 4|2013-07-25 00:00:00| 8827| CLOSED|-3542|
| 5|2013-07-25 00:00:00| 11318| COMPLETE|-3542|
| 6|2013-07-25 00:00:00| 7130| COMPLETE|-3542|
| 7|2013-07-25 00:00:00| 4530| COMPLETE|-3542|
| 8|2013-07-25 00:00:00| 2911| PROCESSING|-3542|
| 9|2013-07-25 00:00:00| 5657|PENDING_PAYMENT|-3542|
| 10|2013-07-25 00:00:00| 5648|PENDING_PAYMENT|-3542|
| 11|2013-07-25 00:00:00| 918| PAYMENT_REVIEW|-3542|
| 12|2013-07-25 00:00:00| 1837| CLOSED|-3542|
| 13|2013-07-25 00:00:00| 9149|PENDING_PAYMENT|-3542|
| 14|2013-07-25 00:00:00| 9842| PROCESSING|-3542|
| 15|2013-07-25 00:00:00| 2568| COMPLETE|-3542|
| 16|2013-07-25 00:00:00| 7276|PENDING_PAYMENT|-3542|
| 17|2013-07-25 00:00:00| 2667| COMPLETE|-3542|
| 18|2013-07-25 00:00:00| 1205| CLOSED|-3542|
| 19|2013-07-25 00:00:00| 9488|PENDING_PAYMENT|-3542|
| 20|2013-07-25 00:00:00| 9198| PROCESSING|-3542|
+--------+-------------------+-------+---------------+-----+
only showing top 20 rows
# dfs.show()
绘制散点图
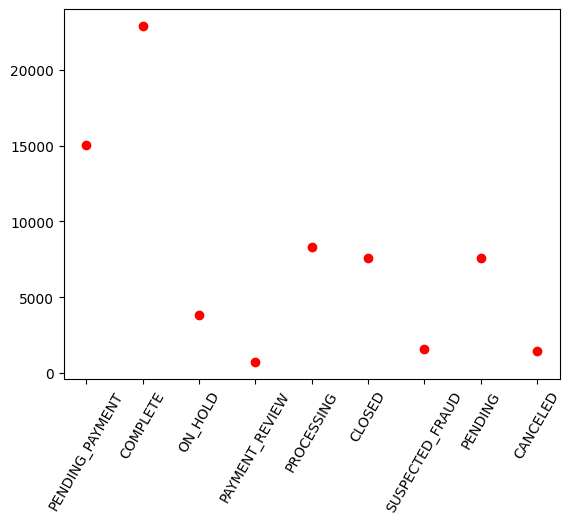
(9) 根据(1)中DataFrame, 利用散点图显示各个订单状态(order_status)的订单个数
# 统计各个状态的个数
dfs9 = dfs.withColumn('order_status',col('order_status'))\
.groupBy('order_status').count()
# 将Spark DataFrame转变到Pandas DataFrame
pandasDF = dfs9.toPandas()
pandasDF
| order_status | count | |
|---|---|---|
| 0 | PENDING_PAYMENT | 15030 |
| 1 | COMPLETE | 22899 |
| 2 | ON_HOLD | 3798 |
| 3 | PAYMENT_REVIEW | 729 |
| 4 | PROCESSING | 8275 |
| 5 | CLOSED | 7556 |
| 6 | SUSPECTED_FRAUD | 1558 |
| 7 | PENDING | 7610 |
| 8 | CANCELED | 1428 |
# 绘制散点图
import pandas as pd
import matplotlib.pyplot as plt
# pandasDF.plot(x = 'order_status', y = 'count') #折线图
plt.scatter(x = pandasDF['order_status'], y = pandasDF['count'], c = 'red')
# plt.xticks(x = pandasDF['order_status'], rotation='vertical') # vertical垂直
plt.xticks(x = pandasDF['order_status'], rotation=60) #旋转60度
plt.show()
import os
os.getcwd()
'D:\\juniortwo\\spark'
将数据保存到MySQL
(10) 将(1)中DataFrame数据保存到MySQL中
本实验,需要把本地Hadoop安装目录中etc/hadoop/core-site.xml中的添加的代码注释掉,否则就会在读取文件的相对路径前面添加hdfs的路径。如果需要提交到yarn时,再把这里的注释去掉。
这里注释掉之后,保存或者读取文件时可以使用相对路径,否则都需要使用绝对路径,不然就会报错,或者jupyter notebook长时间没有反应。
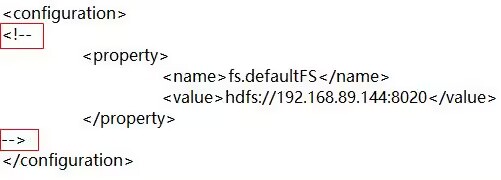
# 导包
import pandas as pd
import findspark
findspark.init()
from pyspark.sql import SparkSession
# 重启内核后再执行
spark = SparkSession \
.builder \
.config("spark.driver.extraClassPath", "mysql-connector-java-8.0.27.jar") \
.getOrCreate()
#这里采用的绝对路径,相对路径容易出错
dfs = spark.read.csv(r"file:\D:\juniortwo\spark\Spark2023-02-20\SalesOrders\part-00000",\
header = False,inferSchema = True)
#把已有数据列改成和目标mysql表的列的名字相同
# 将Spark DataFrame转变到Pandas DataFrame
df_1 = dfs.toDF("order_id","order_date","cust_id","order_status")
print(df_1.show())
+--------+--------------------+-------+---------------+
|order_id| order_date|cust_id| order_status|
+--------+--------------------+-------+---------------+
| 1|2013-07-25 00:00:...| 11599| CLOSED|
| 2|2013-07-25 00:00:...| 256|PENDING_PAYMENT|
| 3|2013-07-25 00:00:...| 12111| COMPLETE|
| 4|2013-07-25 00:00:...| 8827| CLOSED|
| 5|2013-07-25 00:00:...| 11318| COMPLETE|
| 6|2013-07-25 00:00:...| 7130| COMPLETE|
| 7|2013-07-25 00:00:...| 4530| COMPLETE|
| 8|2013-07-25 00:00:...| 2911| PROCESSING|
| 9|2013-07-25 00:00:...| 5657|PENDING_PAYMENT|
| 10|2013-07-25 00:00:...| 5648|PENDING_PAYMENT|
| 11|2013-07-25 00:00:...| 918| PAYMENT_REVIEW|
| 12|2013-07-25 00:00:...| 1837| CLOSED|
| 13|2013-07-25 00:00:...| 9149|PENDING_PAYMENT|
| 14|2013-07-25 00:00:...| 9842| PROCESSING|
| 15|2013-07-25 00:00:...| 2568| COMPLETE|
| 16|2013-07-25 00:00:...| 7276|PENDING_PAYMENT|
| 17|2013-07-25 00:00:...| 2667| COMPLETE|
| 18|2013-07-25 00:00:...| 1205| CLOSED|
| 19|2013-07-25 00:00:...| 9488|PENDING_PAYMENT|
| 20|2013-07-25 00:00:...| 9198| PROCESSING|
+--------+--------------------+-------+---------------+
only showing top 20 rows
None
spark = SparkSession \
.builder \
.config("spark.driver.extraClassPath", "mysql-connector-java-8.0.27.jar") \
.getOrCreate()
df_1.write.format("jdbc").options(
url="jdbc:mysql://127.0.0.1:3306/dftest",
driver="com.mysql.cj.jdbc.Driver",
dbtable="sale_order",
user="root",
password="123456").mode('overwrite').save()
(11) 将(1)中DataFrame数据根据order_status列值的不同进行划分,并保存为parquet格式
dfs.write.parquet(r"file:\D:\juniortwo\spark\parquet_result01.parquet",\
partitionBy="order_status", mode="overwrite")
(12) 根据(11)的输出,读取order_status=CANCELED文件夹中的parquet文件内容并显示
dfs12 = spark.read.parquet(r"file:\D:\juniortwo\spark\parquet_result01.parquet")
dfs12.printSchema()
root
|-- order_id: integer (nullable = true)
|-- order_date: timestamp (nullable = true)
|-- cust_id: integer (nullable = true)
|-- order_status: string (nullable = true)
dfs12.filter("order_status='CANCELED'").show()
+--------+-------------------+-------+------------+
|order_id| order_date|cust_id|order_status|
+--------+-------------------+-------+------------+
| 50|2013-07-25 00:00:00| 5225| CANCELED|
| 112|2013-07-26 00:00:00| 5375| CANCELED|
| 527|2013-07-28 00:00:00| 5426| CANCELED|
| 552|2013-07-28 00:00:00| 1445| CANCELED|
| 564|2013-07-28 00:00:00| 2216| CANCELED|
| 607|2013-07-28 00:00:00| 6376| CANCELED|
| 649|2013-07-28 00:00:00| 7261| CANCELED|
| 667|2013-07-28 00:00:00| 4726| CANCELED|
| 716|2013-07-29 00:00:00| 2581| CANCELED|
| 717|2013-07-29 00:00:00| 8208| CANCELED|
| 738|2013-07-29 00:00:00| 10042| CANCELED|
| 753|2013-07-29 00:00:00| 5094| CANCELED|
| 929|2013-07-30 00:00:00| 8482| CANCELED|
| 955|2013-07-30 00:00:00| 8117| CANCELED|
| 962|2013-07-30 00:00:00| 9492| CANCELED|
| 1013|2013-07-30 00:00:00| 1903| CANCELED|
| 1169|2013-07-31 00:00:00| 3971| CANCELED|
| 1186|2013-07-31 00:00:00| 11947| CANCELED|
| 1190|2013-07-31 00:00:00| 12360| CANCELED|
| 1313|2013-08-01 00:00:00| 3471| CANCELED|
+--------+-------------------+-------+------------+
only showing top 20 rows