一、环境
地址:启智社区:https://openi.pcl.ac.cn/
二、计算卡介绍

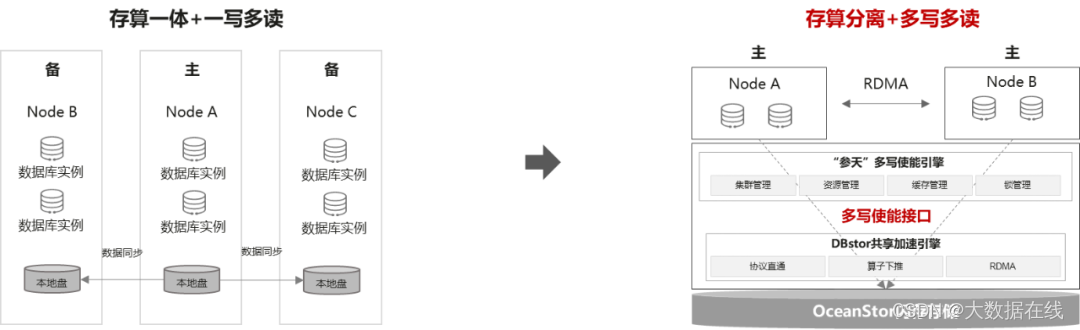
云燧T20是基于邃思2.0芯片打造的面向数据中心的第二代人工智能训练加速卡,具有模型覆盖面广、性能强、软件生态开放等特点,可支持多种人工智能训练场景。同时具备灵活的可扩展性,提供业界领先的人工智能算力集群方案。
优势特点
- 澎湃算力 高精训练
- 专属通道 算力扩展
- 广泛支持 生态友好
- 工具开放 高效开发
三、代码仓
https://openi.pcl.ac.cn/Enflame/GCU_Pytorch1.10.0_Example
四、模型+数据集
Resnet+imagenet_raw
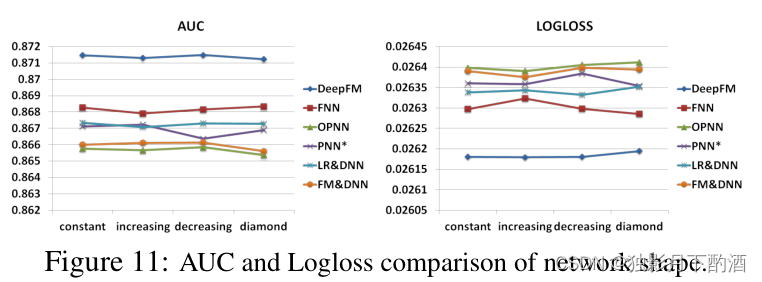
五、运行结果
单卡单Epoch
"model": "resnet50",
"local_rank": 0,
"batch_size": 256,
"epochs": 1,
"training_step_per_epoch": -1,
"eval_step_per_epoch": -1,
"acc1": 6.467013835906982,
"acc5": 20.52951431274414,
"device": "dtu",
"skip_steps": 2,
"train_fps_mean": 706.7805865954374,
"train_fps_min": 668.1171056579481,
"train_fps_max": 755.529550208285,
"training_time": "0:12:27"
fps_mean:706.78
acc1:6.47
运行时间:12分27秒
8卡单Epoch
"model": "resnet50",
"local_rank": 5,
"batch_size": 256,
"epochs": 1,
"training_step_per_epoch": -1,
"eval_step_per_epoch": -1,
"acc1": 3.02734375,
"acc5": 12.5,
"device": "dtu",
"skip_steps": 2,
"train_fps_mean": 704.4055937610347,
"train_fps_min": 702.2026238348252,
"train_fps_max": 706.744240295003,
"training_time": "0:07:04"
fps_mean:704.41
acc1:3.03
运行时间:7分04秒
8卡线性度:99.72%
单卡100Epoch
"model": "resnet50",
"local_rank": 0,
"batch_size": 64,
"epochs": 100,
"training_step_per_epoch": -1,
"eval_step_per_epoch": -1,
"acc1": 87.13941955566406,
"acc5": 97.31570434570312,
"device": "dtu",
"skip_steps": 2,
"train_fps_mean": 488.19604076742735,
"train_fps_min": 249.3976374646114,
"train_fps_max": 568.624496005538,
"training_time": "4:45:13"
fps_mean:488.19604076742735
acc1:87.14
运行时间:4小时45分钟13秒
8卡100Epochs
"model": "resnet50",
"local_rank": 0,
"batch_size": 64,
"epochs": 100,
"training_step_per_epoch": -1,
"eval_step_per_epoch": -1,
"acc1": 82.2265625,
"acc5": 96.875,
"device": "dtu",
"skip_steps": 2,
"train_fps_mean": 481.25022732778297,
"train_fps_min": 267.4726081053424,
"train_fps_max": 509.6326762775301,
"training_time": "1:18:22"
fps_mean:481.25
acc1:82.22
运行时间:1小时18分22秒
线性度:98.58%
六、代码迁移示例
https://openi.pcl.ac.cn/OpenIOSSG/MNIST_PytorchExample_GCU/src/branch/master/train_for_c2net.py
七、心得建议
心得
通过查阅代码示例很快就可以掌握从CPU/GPU迁移代码到GCU上运行的方法。除了运行燧原科技提供的代码外,在前阵子学习李沐老师d2l pytorch代码的时候自己也尝试过迁移到gcu上运行,总体来说大部分都可以顺利迁移,此外有时候自己以前跑过的一些基于torch的notebook代码有些根据示例修改成gcu运行也能成功跑起来。
唯一遇到的问题就是有时候运行会出现一长串在编译的运行提示,不知道这是什么情况,而且这类情况通常运行时间会比GPU要久一点,也许可能是代码哪里不对,后期在看看,这类情况遇到的不多。
对于GCU的运行速度总体感觉还是可以的,根据README运行DEMO代码也非常方便。
建议
- 使用GCU总体感觉速度还是蛮快的,后期准备有时间做一下和CPU以及GPU平台的速度精度对比看看。
- 现在的脚本训练没有过程输出,可以通过修改py文件添加log输出,但是个人建议如果能有个教程指导初学者如何去添加log输出的代码示例会更好,初学者不一定知道如何去修改
- GCU平台有没有可能在未来支持更多的框架,例如tensorflow,mindspore等等
- 唯一不方便的就是demo代码如果需要修改超参必须找到对应的sh脚本文件修改,如果能够实现创建任务的时候直接修改超参的话感觉会方便一点。