从上世纪90年代正式起步至今,中国数据库发展已走过近30年岁月。以2000年前后为拐点,以MySQL为首的开源数据库,在互联网厂商的推动下,逐步进入生产业务;而为了使单实例能力平庸的MySQL能够满足高性能要求,互联网厂商开始将原来的数据库与表通过各种逻辑进行拆分,形成了新的技术路线。这,就是分布式数据库。
在2023华为金融创新数据基础设施峰会,华为与一众银行、证券等金融行业伙伴,联合发布OceanData分布式数据库存储解决方案,提出以专业全闪存存储和存算分离架构,使能分布式数据库创新升级,助力金融行业数据库平滑改造。此次发布引起行业热议,什么是“分布式数据库存储解决方案”?华为为何与金融行业伙伴联合发布?又为何如此强调“存算分离”?本文将从此话题出发,详细剖析华为此次大会发布的方案内容,和背后金融行业数据库分布式改造不得不说的故事。
存算分离,金融数据库改造的重要抉择
在金融行业内,数据库使用的主要场景有核心交易、互金类APP、分析类应用、办公等内部应用等。其中核心交易场景常使用IBM大型机+DB2或小型机+Oracle,对数据库的时延、强一致性和可用性有非常高的要求;互金类应用要求数据库有高并发和易扩展能力,同时对数据一致性、数据库可用性也提出了较高的诉求,常常使用MySQL类分布式数据库+容器的技术。
如今,随着金融业务规模逐步扩大和政策形式的变化,金融行业各业务场景数据库系统正在逐步向国产数据库改造;但除了办公等非关键业务场景,核心业务场景改造仍进展缓慢。对于这一现象,其根本问题在于国产数据库,尤其是分布式数据库,大都采用存算一体架构,使其在数据层面可用性、性能和可管理性都缺乏保障,难以满足金融行业要求。

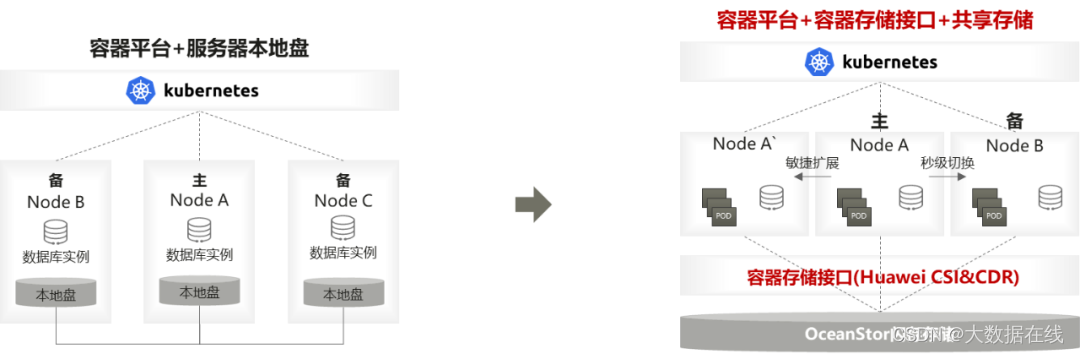
从技术角度分析,存算一体架构的数据库,的确难以满足金融核心场景诉求。存算一体架构指的是采用服务器本地盘存储数据的架构;由于服务器本地盘的可靠性不足,存算一体架构下数据库往往通过一主多备的形式提升系统可用性。但在主库和备库间同步数据时存在一组难以克服的矛盾:如果主备间采用同步复制,即备库数据库从逻辑上与主库完全一致,则严重影响主库性能;如果主备间采用半同步或者异步复制,则无法保证主备数据完全一致。这一矛盾在分布式系统性中无法调和,这也使得该类数据库几乎无法同时满足金融核心高性能和强一致性的要求。
对于金融核心场景,容灾是必要的能力。根据《商业银行数据中心监管指引》要求,总资产规模一千亿人民币以上的商业银行和省农信等,应该设立异地模式灾备中心,且要求至少达到RTO <2天、RPO 0-30分钟的容灾水平;实际上对于五大行或头部股份制核心系统,基本要求达到RTO分钟级、RPO=0的最高水平。而开始提到存算一体架构在主从复制间产生的问题,在容灾场景下表现更为显著,因为链路拉远后故障场景更为复杂(如链路抖动、光纤劣化等),而当前还没有厂商在服务器+以太网上对这一问题进行成熟优化。因此,目前采用存算一体架构的数据库,几乎都采用单集群拉远+异步复制模式,核心业务下分布式数据库强一致性容灾的案例基本没有。
在管理面上,存算一体同样存在许多问题。由于计算和存储强绑定,导致资源无法按需扩张,势必导致一边资源出现浪费;从实际落地来看,由于服务器容量有限,计算资源往往是浪费较多的一方。许多率先进行数据库分布式改造的金融用户,已拥有近万台服务器,但CPU资源利用率还不到10%;而这近万台服务器里有数十万块硬盘,对其健康度和故障的管理更是令运维大呼头疼。

对以上问题进行根因分析,除了分布式系统无法摆脱的“CAP诅咒”以外,归根结底还是因为服务器本身不太关注数据可靠性和易管理设计;而当前数据库厂商基本只具备北向满足用户功能的能力,对南向提升数据高可用、高效率管理能力缺乏技术积累,无法弥补服务器在该方面的不足,最终导致数据库整系统达不到金融核心要求。
如今,随着政策形势和业务需求变化,国产分布式数据库走向核心已是大势所趋;与其等待应用层缓慢的技术演进,把专业的事交给专业的人来做显然是更可行的办法。专业存储专注于数据高可用、高性能、易管理,技术演进已近40年,拥有丰厚的技术积累和实践经验,能够更快的闭环分布式数据库存在的诸多问题;更重要的是,使用专业存储将引导分布式数据库走向Share Storage的数据共享架构,为改变主备间数据同步这一底层逻辑提供了可行性,而这一逻辑正是分布式数据库无法摆脱性能与强一致性矛盾的根源。以上几点构成了分布式数据库走向存算分离架构的技术必然性。如今,不论是AWS Aurora、openGauss,还是PolarDB、TDSQL,都在向存算分离架构靠拢,这绝不会是一种巧合
分布式新核心,如何撑起“核心”之名?
因为各种原因,部分大型银行已经启动了核心系统分库分表改造,并使用分布式数据库打造新一代核心系统。这就是分布式新核心。然而,正如前面所述,银行核心系统对于可靠性有非常严苛的要求,而当前的分布式数据库大都无法满足,导致分布式新核心运行的业务往往并不那么核心。如何让分布式新核心撑起“核心”之名?华为OceanData分布式数据库存储解决方案给出了自己的答案。
华为OceanData分布式数据库存储解决方案基于存储同步复制技术,实现了分布式数据库的双集群容灾。相比于传统分布式数据库采用单级群拉远的方式,该方案可以有效实现集群间故障隔离,是当前唯一满足金融核心容灾要求的方案。那么华为是如何做到的呢?
以下图为例。当前分布式数据库大部分采用图左的复制方式,通过服务器间的以太网络,将 主节点日志同步到各个从节点。不论采用逻辑复制还是物理复制,该方案最大的问题是因为服务器欠缺数据高可用保障能力,需要应用层大量处理远程容灾下的脑裂、链路抖动、坏块、误码、丢包等等问题,当前任何数据库都无法提供保障;许多数据库仅通过PAXOS协议处理脑裂问题,就已经对业务性能产生巨大影响了。这也是为何当前没有分布式数据库支持RPO=0的多地强一致性容灾的原因。

华为OceanData分布式数据库存储解决方案,让分布式数据库将Redo Log流写入存储,并通过OceanStor存储强大的同步复制功能,将日志复制到远端容灾数据中心的存储当中;远端数据中心通过日志实时回放,保证了备数据库与主库的数据一致。由于有专业存储强大的复制能力保障,主库事务执行不必等待远端备库写入成功,只要日志写入完成就可以提交,使得其性能相比于当前分布式数据库大幅提升。该方案中,主数据中心和容灾数据中心的数据库是两个互相隔离的集群,从数据面到管理面都是完全隔离的,这很好的解决了因管理节点或存储故障导致整个集群发生瘫痪的问题。相信不少人已经发现,华为方案与oracle ADG实现方式有异曲同工之妙,而Oracle正式凭借企业级存储成熟而强大的复制能力做到了这一点。
除了存储同步复制以外,针对远程容灾难以解决的链路质量劣化问题,OceanData解决方案也有自己的独家解法。传统的容灾方案中,只能通过主数据中心和容灾中心间的心跳包感知复制链路劣化,需要花费数分钟时间才能察觉,并倒换到冗余的链路上,可能导致金融企业数千笔交易失败;华为的解决方案通过波分设备与存储设备联动感知的SOCC技术,可在毫秒级时间内感知到链路劣化,并在两秒内完成链路倒换,时刻保证复制链路的畅通无阻,避免因抖动对前端业务造成性能影响或者交易失败。专业存储强大而有效的可靠性保障手段,始终是金融企业核心价值的守护神;即使在分布式新核心时代,这一点也丝毫不例外。
金融微服务改造,如何拥有金融级高可靠?
容器技术以其轻量化部署和敏捷化管理的特点,开始逐步在金融行业获得广泛应用;许多金融企业选择将互联网金融APP等敏态业务部署到容器上;而对于部分传统应用,也掀起了一股微服务化改造的热潮。
根据《容器有状态应用调研报告》,由于各类应用需求,数据库是容器化部署最多的应用。然而,容器对于应用的可靠性保障机制事实上比较缺乏,尤其对于分布式数据库这类有状态应用,很多故障场景都需要人工介入保障;但对于金融企业的应用,可靠性都是最不能忽视的重要特性。想象在微服务改造环境下,成千上万个Pod同时运行,如果所有错误都需要人工介入处理,运维成本无法想象,容器集群稳定性将完全不可控。
针对这一痛点,华为OceanData分布式数据库存储解决方案通过自研容器存储接口,打造出一套高可靠又不失敏捷的分布式数据库容器化部署方案,让金融微服务改造的应用,也拥有金融级高可靠。
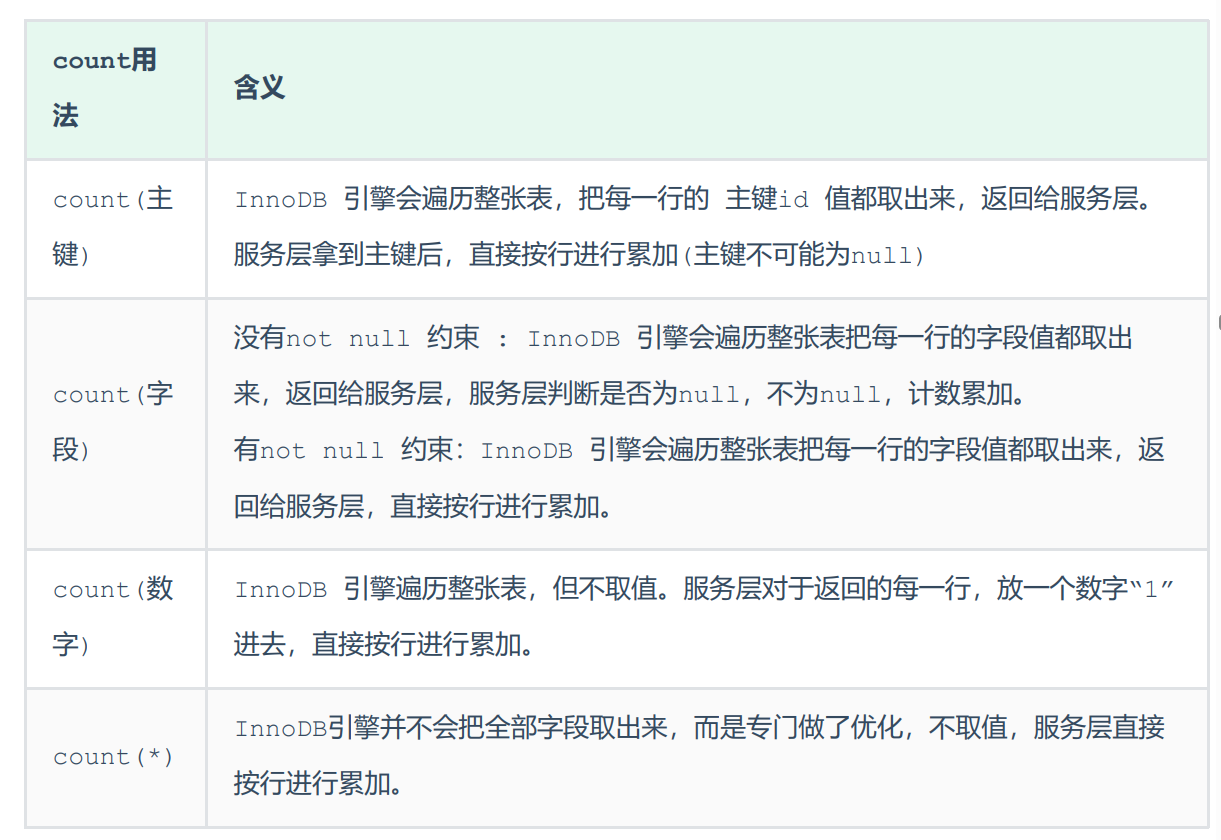
首先,我们需要介绍下传统容器的故障处理机制。以目前最常用的Kubernetes为例,在使用有状态应用时,一般采用StatefulSet控制器进行容器管理。当一个节点故障,节点上的所有Pod与Kubernetes管理节点失联;此时由于Kubernetes无法判断该节点是否真的故障了,上面的Pod和服务是否已经停止,它不会自动将Pod在另一个正常节点重新启动,以避免引起不可预测的业务错误。此时需要人工介入,将故障的节点从集群中强行删除,Kubernetes才会重新在新的节点上拉起Pod和服务。
即使解决了故障拉起问题,采用存算一体架构的数据库还会面临另一个问题:数据恢复。由于故障节点本地盘上的数据无法访问,新节点需要全量重构数据后才能成为真正的从库,这往往依赖于主节点到从节点的复制。根据业务压力,单节点重构一般耗时6-10小时,期间业务性能和可靠性都会受到影响。
针对上述痛点,华为OceanData分布式数据库存储解决方案从两方面着手,提升数据库可靠性。
首先,还是基于存算分离,将数据库改造为Share Storage架构,通过专业存储保障数据高可用,服务器故障数据不丢;当新节点拉起时,可将数据重新挂载给新节点,只需要增量同步故障恢复期间写入的数据即可,这样补从时间可缩短至5分钟左右,对业务影响和可靠性风险都大大降低了。
其次,通过存储与主机间的IO状态,主动感知服务器故障,并通过华为自研容器存储接口实现故障节点的主动驱逐,并将故障POD的PV挂载给新拉起的POD,弥补原生Kubernetes依赖人工处理故障的问题。华为解决方案依托存算分离优势,有效解决了云原生应用中存在的固有问题,使金融微服务改造真正达到金融级高可用要求。
传统核心应用分布式数据库,不分库分表行不行?
说完了分布式改造的场景,最后来讨论这个话题:使用分布式数据库,能不能不分库分表?相信这是许多DBA的心声。传统核心做分布式改造,涉及到大库表的拆分、切片,存储过程的改写,上层业务要做单元化修正、事务一致性保证、串并逻辑修正等,这些都需要花费大量时间和人力,且很难做到完美。即使完成了改造,跨表Join和事务执行效率等还是降低许多,很多存储过程无法使用,大事务无法使用,对后期的开发也造成了许多困难。
分库分表虽然在高并发场景的确有一定优势,但对于大部分非互联网企业而言,其代价和收益不成正比。是否有办法帮助金融企业平滑渡过这最难的一关呢?华为OceanData分布式数据库存储解决方案同样给出了回应。
追本溯源,为什么分布式数据库需要分库分表?其根本动机是,以MySQL为代表的开源生态数据库,其实例能力完全无法与Oracle等商用数据库比拟。Oracle在使用RAC以后,可以多实例并发读写,性能强上加强,单个节点故障也不影响业务;而MySQL等由于不支持RAC,多节点最多只能一写多读,性能有瓶颈,且主从切换业务会断,为了减少性能影响面和爆炸半径,只能做分库分表。假如能让MySQL这类开源生态数据库,也拥有多读多写的能力,甚至拥有和RAC类似的机制,是否可以不需要再分库分表了呢?
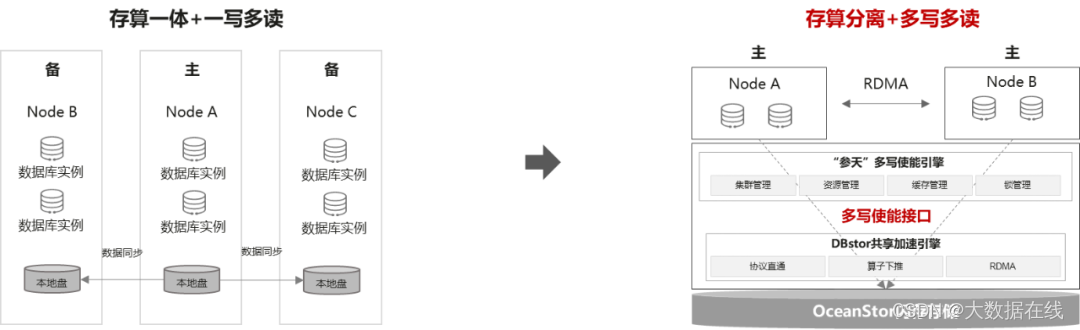
华为OceanData分布式数据库存储解决方案正是从这一突破口入手破解难题。华为在共享存储的基础上,推出了多写使能接口,包含两大引擎—“参天”多写使能引擎和“DBStor”共享加速引擎—以实现MySQL等开源生态的多读多写。
“参天”多写使能引擎在ShareStorage的基础上,进一步实现ShareMemory。它将传统在持久化层分布式改造的逻辑,改为在缓存层分布式改造;通过缓存层高性能数据处理和RDMA的高性能通信能力,弥补持久化层数据同步带来的性能与可靠性问题。“参天”多写使能引擎主要完成了四大功能:
- 全局资源管理:完成全局节点资源的注册、页面与锁资源的传输等工作,将散布在各个节点缓存中的资源进行统一管理与调配,是全局并发读写提供执行层面保障;
- 全局锁管理:完成不同节点间锁资源的请求、释放等管理逻辑,支持spinlock、分布式latch、死锁检测等,它是全局并发读写时的事务一致性的主要保障者;
- 全局页面管理:完成不同节点间的页面资源的加载、请求、释放等管理逻辑,它为全局资源视图的一致性提供逻辑层面保障,以支持并发读写和分布式MVCC;
- 全局集群管理:完成在共享存储上注册节点信息,管理各自节点的进程状态、网络状态等,并与其它节点及共享存储互通状态信息的工作;单节点故障时,会触发仲裁、选主等故障恢复流程,与共享存储共同确保整集群对外正常提供业务。
在全局一份数据共享的基础上,“参天”多写使能引擎解决了缓存层上的数据统一,使得过去的主从节点间可以保持实时强一致性,进化为多主架构,进而实现并发读写,大大提升了数据库集群的性能、吞吐量和可靠性。
“DBStor”共享加速引擎主要是在ShareStorage的基础上实现读写能力增强,其主要功能包括:
- 数据库IO协议栈简化:减少主机侧数据库IO在数据库、文件系统、块设备间频繁的上下文切换,进而降低IO直通时延;
- 数据库算子下推:感知数据库语义,并将大表扫描等部分SQL运算下推至存储完成,并提供索引存储,大幅优化SQL执行效率;
- 高速网络:通过华为NoF+高速网络处理IO,大幅优化传输时延,保障网络稳定无抖动。
“DBStor”共享加速引擎增强了开源数据库的执行效率,使其性能大幅增加,大大弥补了其与Oracle之间的处理能力差距。
从过去到现在,金融核心系统的诉求并没有发生根本变化,因此解题思路也应该是相似的。华为OceanData分布式数据库存储解决方案秉承这一理念,以专业存储+创新引擎,填补了分布式数据库在Oracle ASM和 RAC上缺乏对标产品的空白,将持久化层分布式逻辑转移到缓存层,破解了“分布式数据库必分库分表”的业界难题。从当前现网实践效果来看,大表性能已经基本匹配Oracle;节点故障业务不中断,可靠性也已向Oracle看齐。自此,核心系统分布式数据库改造,终于有了免分库分表的平滑改造方案。
在需求与政策的大趋势,金融行业数据库改造已经在所难免。但是,不论是哪一种改造方式,高可用都是金融行业不变的核心诉求。过去几十年来,通过传统数据库与高可靠专业存储的良好配合,金融行业逐步形成了值得信赖的高可用系统建设体系;如今,在分布式数据库新生态下反复摸爬与碰壁中,我们可以看到存算分离+专业存储体系,依然是数据库高可靠的坚实守护者。