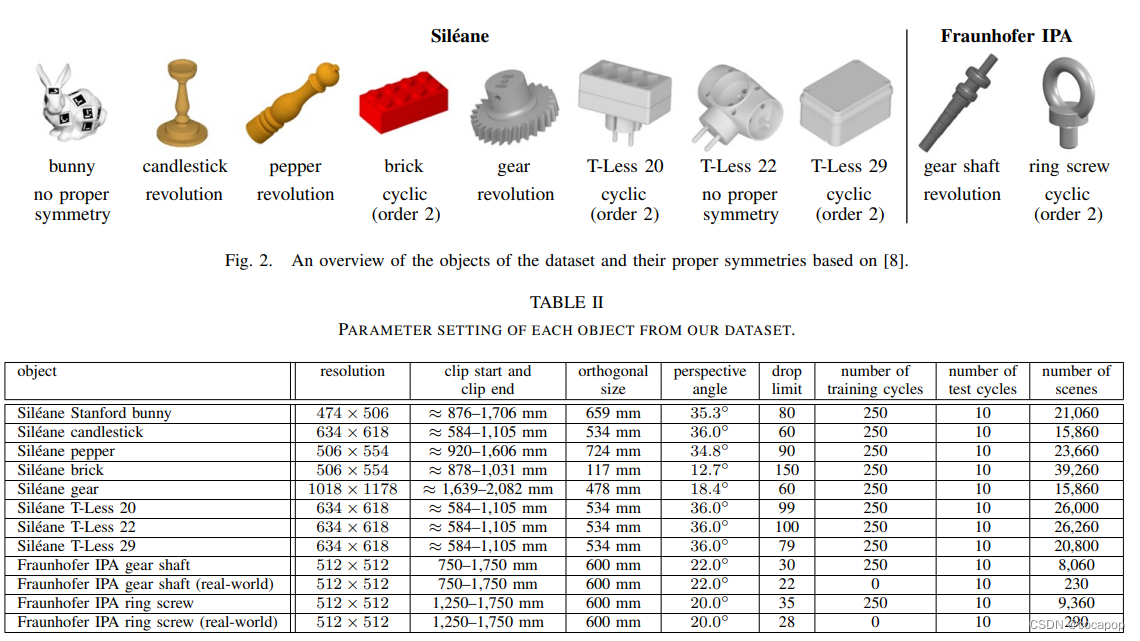
2023美赛Y题二手帆船价格
第一时间在CSDN分享
最新进度在文章最下方卡片,加入获取一手资源:2023美赛Y题二手帆船价格–成品论文、思路、数据、代码
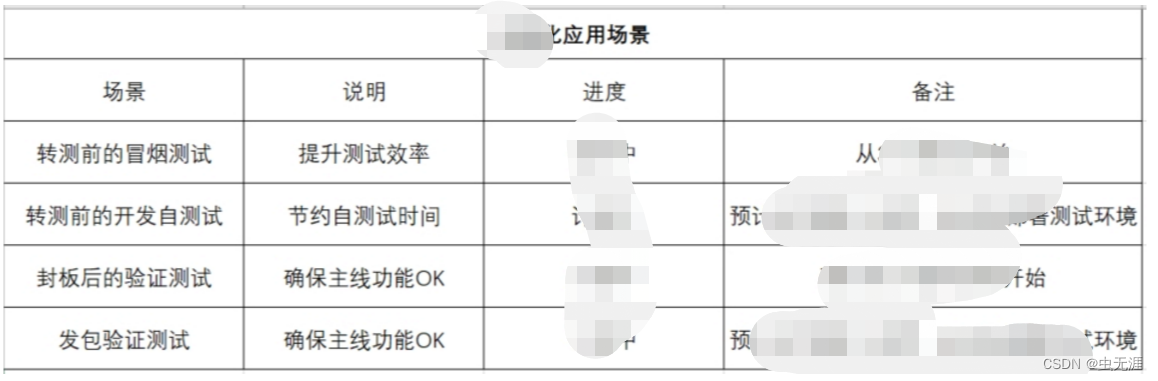
可以提供关于帆船特性的信息:
BoatTrader (https://www.boattrader.com/):一个网站,允许您根据不同的标准,包括长度、制造商和型号,搜索新的和旧的帆船。该站点可以提供一些关于帆船特性的基本信息,如横梁、吃水和排水量。
SailboatData (https://sailboatdata.com/):帆船规格和图纸数据库。该网站包括关于各种帆船型号的梁、吃水、排水量、帆面积和其他帆船特性的信息。
YachtWorld (https://www.yachtworld.com/):一个网站,允许您根据不同的标准,包括长度、制造商和型号,搜索新的和旧的帆船。该站点可以提供一些关于帆船特性的基本信息,如横梁、吃水和排水量。
帆船杂志(https://www.sailmagazine.com/boats):,一个以帆船评论和文章为特色的网站。该网站可以提供有关帆船特性的信息,如索具、风帆面积、船体材料和电子设备。更新中,及时进群,我会在群里第一时间发布更新通知
为了建立一个数学模型来解释所提供的电子表格中每艘帆船的标价,我们可以使用回归分析。回归分析是一种统计方法,用于确定因变量(在本例中为上市价格)与一个或多个自变量(如制造、变体、长度、地理区域、年份等)之间的关系。
汇总统计信息将提供关于模型中每个变量的系数、标准误差、p值和r平方值的信息。我们可以使用这些信息来评估每种帆船品种价格估计的准确性,并确定哪些变量对预测上市价格最重要。
除了提供的数据之外,我们还可以使用其他来源来了解给定帆船的其他特性,如横梁、吃水、排水量、索具、帆面积、船体材料、发动机小时数、睡眠容量、净空、电子设备等。按年份和地区划分的经济数据也可用于补充分析。例如,我们可以包括诸如通货膨胀率、汇率和利率等变量,以解释可能影响列出价格的经济因素。这些数据的来源可能包括行业报告、政府统计数据和市场研究。
import pandas as pd
import numpy as np
import statsmodels.api as sm
# 加载数据
monohulls = pd.read_csv('Monohulled Sailboats.csv')
catamarans = pd.read_csv('Catamarans.csv')
# 类别特征编码
monohulls = pd.get_dummies(monohulls, columns=['Geographic Region'])
catamarans = pd.get_dummies(catamarans, columns=['Geographic Region'])
# 合并
data = pd.concat([monohulls, catamarans], ignore_index=True)
# 选择变量进行回归分析
X = data[['Length (ft)', 'Year', 'Make', 'Variant', 'Geographic Region_Caribbean', 'Geographic Region_Europe', 'Geographic Region_United States']]
y = data['Listing Price (USD)']
# 在自变量中加上常数项
X = sm.add_constant(X)
# 拟合线性回归模型
model = sm.OLS(y, X).fit()
# 打印模型的汇总统计信息
print(model.summary())
为了分析区域对帆船上市价格的影响,我们可以使用一个包括地理区域作为预测变量的回归模型。具体来说,我们可以用以下形式拟合线性回归模型:
挂牌价格= β0 + β1 *长度+ β2 *年份+ β3 *地区
其中,挂牌价格为因变量,长度和年份为连续自变量,分别表示帆船长度和制造年份,区域为分类自变量,表示帆船所在的地理区域(欧洲、加勒比或美国)。β0、β1、β2和β3是反映每个自变量对因变量影响的回归系数。
Python的statmodels库来拟合回归模型,并获得回归系数的估计值。
import pandas as pd
import statsmodels.api as sm
# 加载数据
sailboats = pd.read_csv("monohulled sailboats.csv")
# 拟合模型
model = sm.formula.ols("Listing_Price ~ Length + Year + C(Geographic_Region)", data=sailboats).fit()
# 输出统计信息
print(model.summary())
在上面的代码中,我们使用statmodels中的ols函数来拟合一个线性回归模型,其中Listing_Price作为因变量,Length和Year作为连续自变量,Geographic_Region作为分类自变量。C()符号指定应将地理区域(Geographic_Region)视为分类变量。
model.summary()的输出将包括回归系数的估估值,包括地理区域的系数。我们可以用这些估计来分析地区对上市价格的影响。
如果地理区域的系数具有统计学意义(即p值小于选定的显著性水平,通常为0.05),那么我们可以得出结论,在控制了帆船长度和制造年份后,区域对上市价格具有显著影响。我们还可以通过对系数符号的解读,来确定某一特定地区的帆船的挂牌价格往往高于或低于其他地区的帆船。
要分析区域效应在所有帆船变体中是否一致,可以从按地区查看帆船列表的分布开始。这可以让我们初步了解是否某些地区在数据集中的比例更高,以及在哪些地区的挂牌价格往往更高或更低方面是否存在明显的模式。可以使用Python和pandas库来读入Monohulled sailboats.csv和Catamarans.csv文件,然后使用value_counts()方法来计算每个区域中的清单数量:
import pandas as pd
monohulls_df = pd.read_csv('Monohulled sailboats.csv')
catamarans_df = pd.read_csv('Catamarans.csv')
# 计算单船体船在每个区域的清单数量
monohulls_region_counts = monohulls_df['Geographic Region'].value_counts()
print("Monohulls region counts:")
print(monohulls_region_counts)
# 计算每个地区双体船的挂牌数量
catamarans_region_counts = catamarans_df['Geographic Region'].value_counts()
print("Catamarans region counts:")
print(catamarans_region_counts)
由此,我们可以看到,美国的单体船挂牌数量最多,而加勒比海的双体船挂牌数量最多。我们还可以看到,单船和双体船在各个地区的列表分布是不一样的,例如,欧洲的单船列表比双体船多,而加勒比海的双体船列表比单船多。
为了分析地域对上市价格的影响,我们可以使用以地域为分类预测变量的线性回归模型。我们可以加入其他相关的预测变量,如长度和年份,以控制它们对上市价格的影响。
import statsmodels.api as sm
# 将数据子集化,只包含相关的预测变量
monohulls_data = monohulls_df[['Length (ft)', 'Year', 'Geographic Region', 'Listing Price (USD)']].dropna()
catamarans_data = catamarans_df[['Length (ft)', 'Year', 'Geographic Region', 'Listing Price (USD)']].dropna()
# 类别特征编码
monohulls_data = pd.get_dummies(monohulls_data, columns=['Geographic Region'], prefix='region')
catamarans_data = pd.get_dummies(catamarans_data, columns=['Geographic Region'], prefix='region')
# 拟合模型
monohulls_model = sm.OLS(monohulls_data['Listing Price (USD)'], sm.add_constant(monohulls_data[['Length (ft)', 'Year', 'region_Caribbean', 'region_Europe']]))
monohulls_results = monohulls_model.fit()
print("Monohulls regression results:")
print(monohulls_results.summary())
# 拟合双体船线性回归模型
catamarans_model = sm.OLS(catamarans_data['Listing Price (USD)'], sm.add_constant(catamarans_data[['Length (ft)', 'Year', 'region_Caribbean', 'region_Europe