皮尔逊相关系数的python实现
- 一、相关系数公式
- 二、python实现
- 法1:直接按公式算
- 法2:调用numpy中的corrcoef方法
- 法3:调用scipy.stats中的pearsonr方法
- 法4:调用pandas.Dataframe中的corr方法
一、相关系数公式
R的值在-1和1之间,包括-1和1。
公式1:
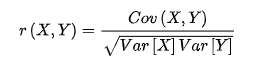
其中,Cov(X,Y)为X与Y的协方差,Var[X]为X的方差,Var[Y]为Y的方差。
或者公式2:
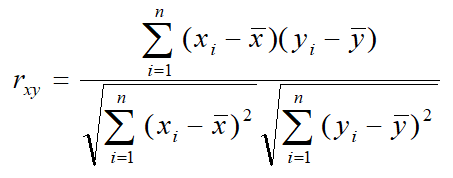
可以转换为公式3:
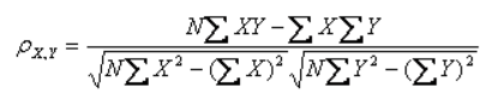
二、python实现
法1:直接按公式算
代码
import numpy as np
import math
x = np.array([1, 2, 3])
y = np.array([2, 4, 5])
# 方法1:利用公式2
def get_r1(x, y): # R
if len(x) == len(y):
x_ave = sum(x) / len(x)
y_ave = sum(y) / len(y)
numerator = sum([(i - x_ave) * (j - y_ave) for i, j in zip(x, y)])
d = sum([(i - x_ave) ** 2 for i in x]) * sum([(j - y_ave) ** 2 for j in y])
denominator = math.sqrt(d)
return numerator / denominator
else:
return None
r = get_r1(x, y)
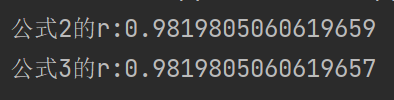
print(f"公式2的r:{r}")
# 方法2:利用公式3
def get_r(x, y): # R
if len(x) == len(y):
n = len(x)
sum_xy = np.sum(np.sum(x * y))
sum_x = np.sum(np.sum(x))
sum_y = np.sum(np.sum(y))
sum_x2 = np.sum(np.sum(x * x))
sum_y2 = np.sum(np.sum(y * y))
pc = (n * sum_xy - sum_x * sum_y) / np.sqrt((n * sum_x2 - sum_x * sum_x) * (n * sum_y2 - sum_y * sum_y))
return pc
else:
return None
p = get_r(x, y)
print(f"公式3的r:{p}")
法2:调用numpy中的corrcoef方法
方法:
numpy.corrcoef(x, y=None, rowvar=True, bias=<无值>, ddof=<无值>)
参数:
x:array_like,包含多个变量和观测值的1-D或2-D数组,x的每一行代表一个变量,每一列都是对所有这些变量的单一观察。
y:array_like,可选,另外一组变量和观察,y具有与x相同的形状。
rowvar:bool, 可选,如果rowvar为True(默认值),则每行代表一个变量,并在列中显示。否则,转换关系:每列代表一个变量,而行包含观察。
bias:没有效果,请勿使用。自1.10.0版开始不推荐使用。
ddof:没有效果,请勿使用。自1.10.0版开始不推荐使用。
返回值: R : ndarray,变量的相关系数矩阵。
功能: 计算矩阵的相关系数,返回Pearson乘积矩相关系数的矩阵。
代码
import numpy as np
x = np.array([1, 2, 3])
y = np.array([2, 4, 5])
p = np.corrcoef(x, y)
print(p)

法3:调用scipy.stats中的pearsonr方法
方法:
pearsonr(x, y)
参数:
输入:x为特征,y为目标变量.
x:(N,) array_like,Input array。
y:(N,) array_like,Input array。
注: p值越小,表示相关系数越显著,一般p值在500个样本以上时有较高的可靠性。
返回值:
r : float,皮尔逊相关系数,[-1,1]之间。
p-value : float,Two-tailed p-value(双尾P值)。
代码
import numpy as np
from scipy.stats import pearsonr
x = np.array([1, 2, 3])
y = np.array([2, 4, 5])
pc = pearsonr(x, y)
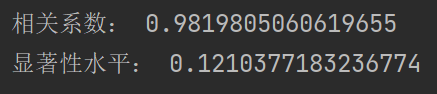
print("相关系数:", pc[0])
print("显著性水平:", pc[1])
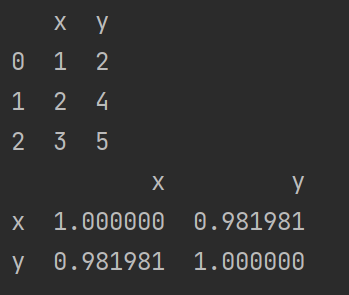
法4:调用pandas.Dataframe中的corr方法
pandas.DataFrame.corr()是pandas中DataFrame对象的方法,用于计算DataFrame中列与列之间的相关性矩阵。该方法的返回值是一个相关性矩阵,矩阵的行与列分别对应着DataFrame中的列。
方法:
corr(self,method,min_periods)
参数:
method:计算相关性的方法,包括’pearson’(默认)、‘kendall’和’spearman’
pearson:皮尔逊相关系数
kendall:肯德尔等级相关系数
spearman:斯皮尔曼等级相关系数
min_periods:计算相关性时的最小样本量,最少为1。
dropna:布尔类型的参数,设置是否在计算相关性时忽略缺失值。默认为True,即忽略缺失值。
返回值:
返回各类型之间的相关系数DataFrame表格。
代码:
import pandas as pd
data = pd.DataFrame({"x": [1, 2, 3], "y": [2, 4, 5]})
print(data)
print(data.corr("pearson"))