作者
metaapp-推荐广告研发部:臧若舟,朱越,司灵通
1 背景
推荐场景大模型在国内的使用很早,早在 10 年前甚至更早,百度已经用上了自研的大规模分布式的 parameter server 系统结合上游自研的 worker 来实现 TB 级别的万亿参数的稀疏模型。后来,各家平台也陆续基于这种方案,开发了自己的分布式训练系统,普遍特点是大量使用 id embedding,因此参数量巨大,模型大小也非常夸张。当然,随着开源训练工具 TensorFlow/Pytorch 的流行,使用 TensorFlow/Pytorch 作为 worker,结合自研 ps 的方案也十分流行。究其原因,以 TensorFlow 为例,虽然内置了分布式训练系统,但是对于大规模 id embedding 的支持却非常糟糕,无法作为完整的平台使用。而使用 TensorFlow+ 自研 ps 的方案也存在不少问题,比如自研 ps 一般对于特征输入都有特定的要求、二次开发成本比较高等。

一个典型的分布式 worker-ps 架构
2 业务介绍
metaapp- 推荐广告研发部,主要负责 metaapp 拳头产品 233 乐园的首页信息流的推荐和广告系统,是比较传统的推广搜组。我们在 2020 年之前也是采用了 TensorFlow+ 自研分布式 ps 的方案,模型大小在接近 TB 级别(业务体量较小),整个方案的迭代和维护成本都比较高。
在这种背景下,经过多方考量,阿里云机器学习平台 PAI 开源的 DeepRec(脱胎于 PAI-TF),作为支持了淘宝搜索、猜你喜欢、定向、直通车等核心业务的训练平台,直接基于 TensorFlow 做二次开发,针对稀疏模型在分布式、图优化、算子、Runtime 等方面进行了深度的性能优化,并且完全开源。
而因为我们公司本身跟阿里云有着深度的合作,阿里云也主动介绍了当时还是内部项目的 DeepRec 给我们尝试。在近 2 年的工作后,DeepRec 已经全量用于我们的模型训练和线上 inference,并且取得了显著的性能提升和成本下降。
3 稀疏模型训练
3.1 EmbeddingVariable 多级存储
由于模型参数量大,一些特征的 embedding 大小达到了接近 TB 级别,完全基于内存存储对于成本的要求过高,因此自然而然就会想到多级存储:将最热的 embedding 放在显存或者内存里,其余的可以分级放在 PMEM、SSD 等成本较低的存储介质中。而 DeepRec 中 提供了基于 EmbeddingVariable 的 Embedding 多级存储功能。DeepRec 目前对于 embedding 存放在各种存储介质的支持已经相当完善。
下面介绍下我们团队升级 DeepRec 在存储这一块的过程和经验:
3.1.1 compaction 的性能问题
我们原本基于自研的分布式 parameter server,而当时 PMEM 类的存储介质还不普及,因此我们选择了比较高性能的 SSD 作为多级存储介质。于是我们自然而然采用了类 leveldb(rocksdb)的方案作为 SSD 存储方案。但这种方案在模型训练时,由于参数不断增加和更新,后台会进行频繁的 compaction,此时会有严重的写放大问题导致 ps 的读取时间大大延长,从而导致模型训练的瓶颈几乎都在 ps 侧。ps:据说 rocksdb 在 2022 年底的 7.5.3 版本大幅改进了 compaction 的性能,在后台 compaction 时几乎不会影响读取的性能。
3.1.2 DeepRec 的方案
而在早期我们试用 DeepRec 时,DeepRec 的 EmbeddingVariable 对于 SSD 存储的方案同样是基于 leveldb,因此同样遇到了跟我们自研的方案类似的问题。后续我们将此问题的测试结果反馈给了 DeepRec 相关的同学,他们基于此后续推出了基于 SSDHASH 的存储方案,大大提升了 compaction 时的读取性能,因此模型训练基于不再受困于 ps 的读取性能问题。后续又进一步了基于 SSDHASH 的同步和异步两种 compaction 的方式。使用同步 compaction 时,向 SSD 写入数据和 compaction 将会使用同一个线程,异步时则各使用一个线程。这里也推荐大家使用这种方案。
3.1.3 压缩模型大小
进一步的,如果能把模型大小控制在数十 GB,那 ps 的性能就可以进一步提升了。因为采用 DeepRec,自定义各种压缩方式的算子变得非常轻松。我们调研并实现了了多篇 embedding 压缩方向的 paper,最后采用了 binary code 的方式实现了 embedding 的 multihash 方案,可以自由控制 embedding 的大小。我们尝试在最大的特征 uid embedding 上使用了 multihash,把模型大小从 800GB 降低到 40GB 以下,auc 的损失仅在千分之三左右,线上点击率下降了 1.5%;进一步的,我们通过优化序列推荐模型,更好的通过序列特征建模了用户的个性化,可以发现在序列模型的基础上把 uid embedding 换成 multihash 的方案,对于线上点击率的影响仅有 0.3% 左右,因此可以放心全量 multihash 方案。我们也把基于 multihash 的 embedding variable 算子以 pr 的形式提交给了 DeepRec。
3.2 基于 GPU 的分布式训练
在解决了 ps 的性能瓶颈后,模型训练的速度就和模型 Tensor 计算的算力近似线性相关了。而近几年随着序列模型的发展,搜广推的矩阵计算复杂度也在显著提升。此时使用 gpu+ 大 batch size 来代替 cpu 作为 worker 的方案,无论在性能还是成本控制上都有巨大的优势。而阿里云机器学习平台 PAI 开源的 HybridBackend 平台就支持了基于 GPU 的分布式训练方案,并且深度支持了 DeepRec。
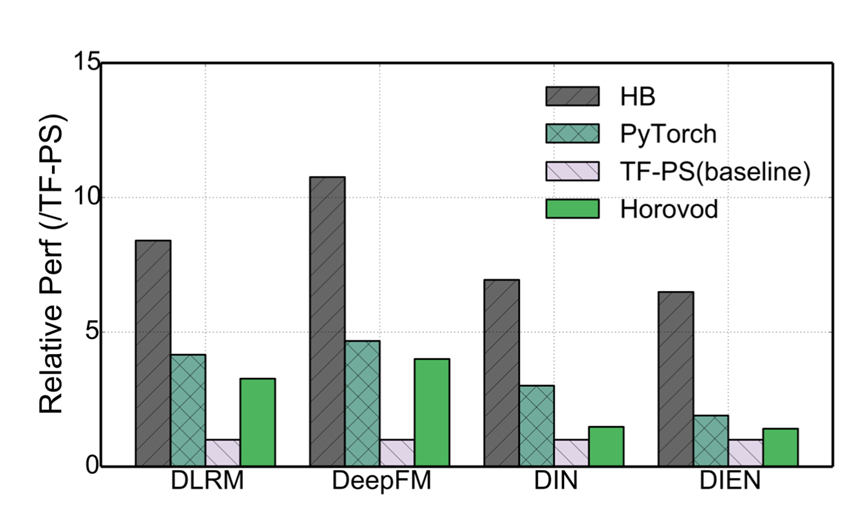
可以看到使用 hb 的方案在训练速度上对比 TF-PS 原生方案的优势。
3.2.1 模型参数完全放在显存里
想要充分释放 gpu 的算力,减少因为数据拷贝带来的性能损耗,最好的方案自然是把所有参数都放在 gpu 显存里。上面 2.1.3 提到的压缩模型大小,为这种方案提供了可能性。调大 batch size 则可以进一步提高显卡的利用率。经过测试,在这种情况下,单张 V100 显卡的算力可以超过 20 台 40core worker 节点的算力。
3.2.2 解决了多卡训练丢失数据的问题
在单机多卡训练时,我们发现和单卡训练相比有近 1/3 的数据被丢弃,这是由于 hybridbackend 默认使用所有 worker 按照 row group 平分数据的策略,以提高读取效率。当 group 数目不够均分时,多余的数据会被丢弃,当 parquet 文件较多且比较小时,该问题尤为严重。我们通过使用每个 worker 加载所有的 group,再按照 batch 平分数据的策略,极大地缓解了数据丢失的情况,读取压力也在可接收范围内,后续可考虑将两策略结合降低 worker 的读取压力。
4 模型 inference
4.1 痛点
在我们的实际场景里,线上 inference 的痛点大部分来自于维护成本。因为推荐广告业务场景,需要大量尝试各种模型在线上分配流量做 AB test,因此线上存在的模型量级大概是 10 倍的基线模型量级。而每次上线一个模型,都需要给对应的模型分配相应的资源,并且这个资源跟 AB test 的流量正相关;而每次调整 AB test 流量(比如模型效果不错,放大流量观察)的时候,又需要调整该模型分配的资源。这个过程比较难实现自动化,往往需要算法工程师手动扩缩容。
4.2 基于 Processer 库的 inference 方案解决痛点

上面这个图是我们线上实际的 inference 方案。
4.2.1 单机器运行所有模型
基于上面的痛点,我们给出的方案是使用大规格机器(比如 128C,512G 内存)来做线上 inference,然后每台机器都会有线上所有的模型实例。每台机器运行一个 serving-proxy 会自动的管理所有的模型进程,包括模型上下线、模型更新等。这种方案的好处是整个维护成本基本没有了,所有事情基本都自动化完成了。因为线上整体的流量相对稳定(比如扩大 AB test 模型的流量,自然基线模型流量就减少了,整体是稳定的),所以各个模型之间资源竞争也不需要重新分配资源。
4.2.2 基于 DeepRec 提供的 Processer 库
DeepRec Serving Processor 是用于线上高性能服务的 Library,可以参考文档。因为本身是一个独立的 so 包,我们可以很方便的对接到自己的 Serving RPC 框架中。我们采用 golang 语言来完成了我们自己的 serving rpc 项目,优点自然是开发成本低并且性能不错。
4.2.3 使用 DeepRec 的 Session Group
直接使用 TensorFlow 提供的 C++ 接口调用 Session::Run,无法实现多 Session 并发处理 Request,导致单 Session 无法实现 CPU 的有效利用。如果通过多 Instance 方式(多进程),无法共享底层的 Variable,导致大量使用内存,并且每个 Instance 各自加载一遍模型,严重影响资源的使用率和模型加载效率。

DeepRec 中 SessionGroup 可配置一组 Session,并且通过 Round Robin (支持用户自定义策略)方式将用户请求分发到某一个 Session。SessionGroup 对不同 Session 之间的资源进行隔离,每个 Session 拥有私有的线程池,并且支持每个线程池绑定底层的 CPU Core(numa-aware),可以最大程度地避免共享资源导致的锁冲突开销。SessionGroup 中唯一共享的资源是 Variable,所有 Session 共享底层的 Variable,并且模型加载只需要加载一次。
我们使用 session group 后,实测调整到合适的 group 数量,可以提高 50% 的 inference 性能。
4.2.4 基于 oneDNN 的优化
DeepRec 集成了英特尔开源的跨平台深度学习性能加速库 oneDNN(oneAPI Deep Neural Network Library),并且修改 oneDNN 原有的线程池,统一成 DeepRec 的 Eigen 线程池,减少了线程池切换开销,避免了不同线程池之间竞争而导致的性能下降问题。oneDNN 已经针对大量主流算子实现了性能优化,包括 MatMul、BiasAdd、LeakyReLU 等在业务场景中使用到的常见算子,为业务模型提供了强有力的性能支持。更值得一提的是, oneDNN 的算子支持 BF16 数据类型,与搭载 AMX(Advanced Matrix Extensions)指令集的第四代英特尔® 至强® 可扩展处理器同时使用,可显著提升模型训练和推理性能。在 DeepRec Serving Processor 编译选项中,只需加入“--config=mkl_threadpool”,便可轻松开启 oneDNN 优化。
4.2.5 子图优化
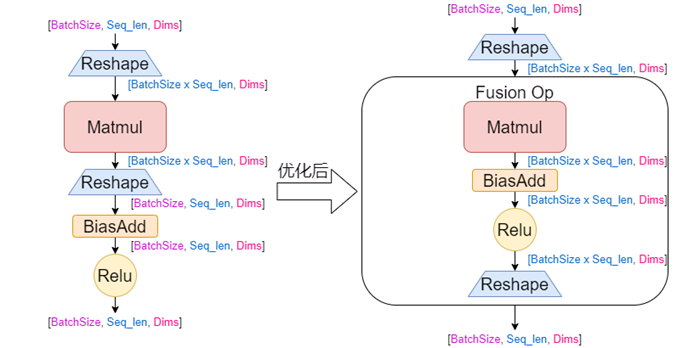
子图融合是推理性能优化的常用方法。但是对于本模型中左图所示的子图结构含有 Reshape 算子,原生 tensorflow 并没有对应结构的图优化器以及算子实现,我们通过手动融合来实现,融合前后的子图构成如下图所示。这样减少了多余算子的运行开销,减少了内存访问,提升了计算效率。再结合 oneDNN 加速融合算子,最终业务端到端加速了 10%,CPU 利用率下降 10%。
4.2.6 cost model 的设计
由于大机器的 cpu core 数较多,而我们是一台机器有所有模型的进程,那么所有模型都共享所有 cpu core 显然会造成不必要的资源竞争等。因此给不同模型设计合理的 cost model 就很有必要。我们目前采用比较简单的方式,因为基线模型和需要做 AB test 的模型资源差别较大(流量差距大),我们会给每个基线模型分配对应的 core,然后让所有非基线模型共享一组 core(总体 AB test 的流量有上限)。虽然这个方案很简单,但是取得了非常好的效果,大概有 30% 的性能提升。
5 后续规划
1、cost model 的优化,显然有更好的方案来动态的调整每个模型需要的 core。我们打算开发更好的 cost model 并提供给 DeepRec。
2、开源我们的 inference 架构方案,因为在我们的业务里,基于 DeepRec processor 设计的 inference 架构带来了巨大的便利,并且性能很好,我们预计在上半年会开源我们的 inference 架构方案,欢迎大家到时关注。