以下内容只针对 Win10 系统
1. 环境安装
(1) 安装Java并配置环境变量
https://www.oracle.com/java/technologies/downloads/#java8-windows
(2) 安装Scala
https://www.scala-lang.org/ 或 https://github.com/lampepfl/dotty/releases/tag/3.2.2
配置环境变量,在系统环境变量path中新增D:\app\Scala\scala3-3.2.2\bin

完成后打开cmd 输入scala测试一下

(3) 安装Spark
前往链接 spark doanload page 安装
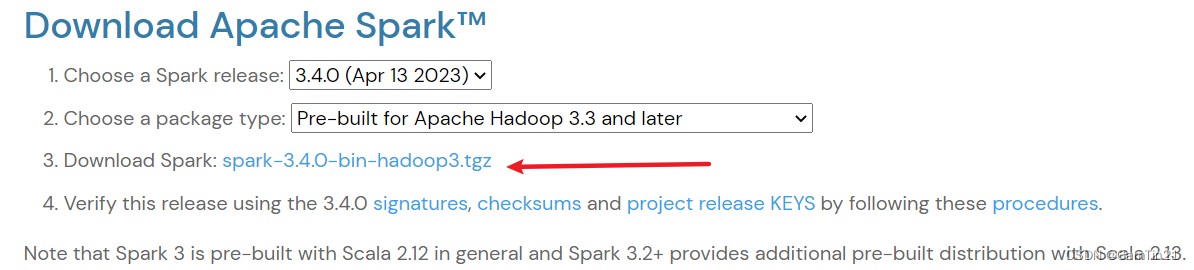
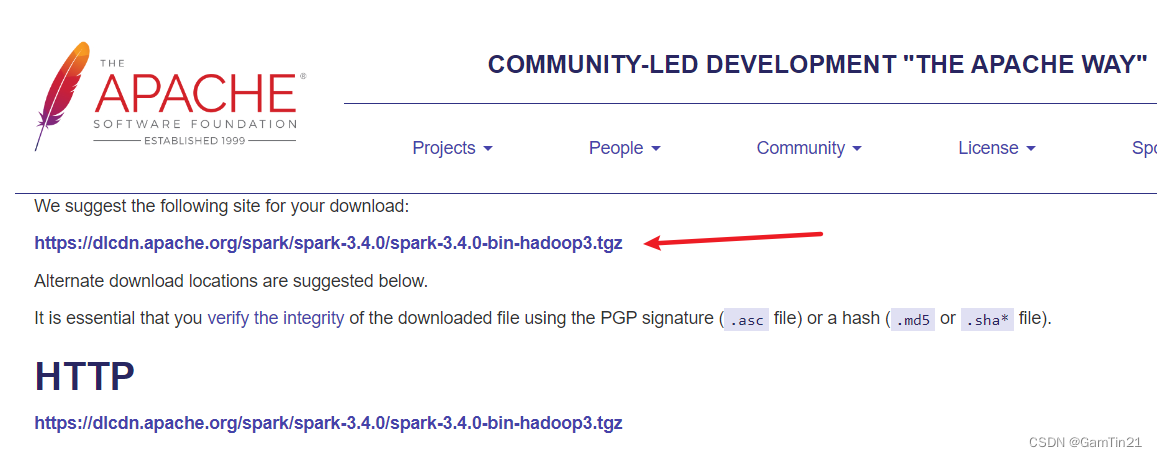
点击进入下一个页面,下载压缩包文件spark-3.4.0-bin-hadoop3.tgz
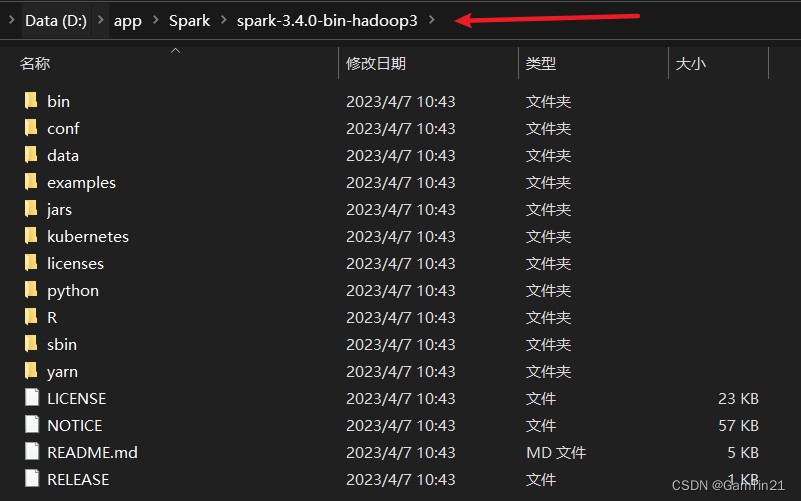
将文件解压到你想要的文件夹目录中,我的是这样子的
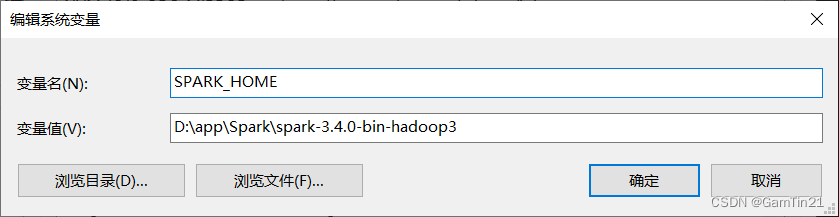
接着配置环境变量,在系统变量中新增以下配置。变量名一定要命名为SPARK_HOME,否则接下来运行程序的时候会因为找不到这个变量而出错
在环境变量path中新增以下配置

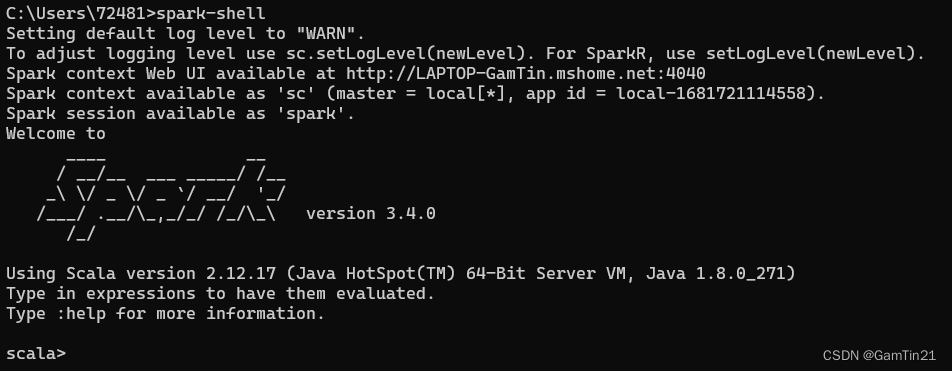
CMD中输入spark-shell看看成功了没
(4) 安装Hadoop
https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.2.4/hadoop-3.2.4.tar.gz
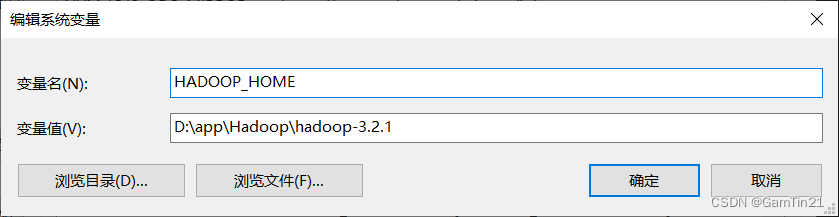
配置环境变量,在系统变量中新增以下配置。变量名一定要命名为HADOOP_HOME,变量值替换为你安装hadoop的目录
在path中添加以下配置

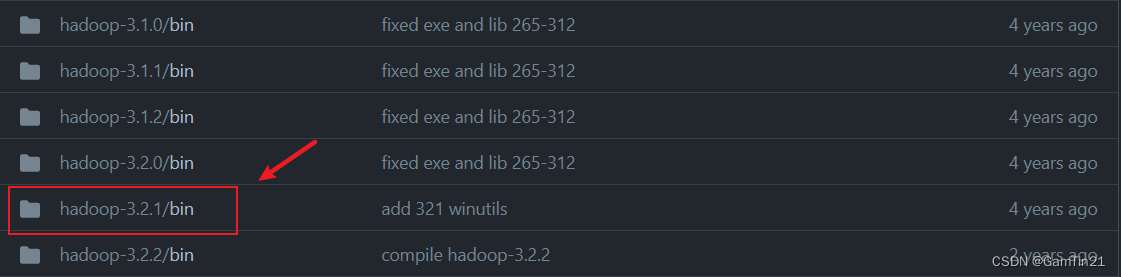
接下来前往 cdarlint/winutils 这个地址,下载你Hadoop所对应版本的winutils,这里我的Hadoop版本是 3.2.1,则下载下图中的版本
将bin里面的文件下载下来
然后将这些文件全部放到你Hadoop安装目录的bin文件夹中。CMD输入hadoop version看看成功了没

(5) 安装python
如果系统中使用Anaconda来控制python的版本,则在系统环境变量中添加以下配置(假设Anaconda安装在D:\tools\Anaconda\中,则直接在后面加python.exe即可)

然后在path中添加

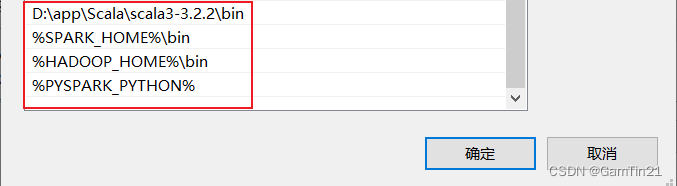
(6) 检查
如果以上环境全部安装完成并完成配置,则系统环境变量path中会有以下配置
2. 测试
以下为测试input.txt文件
word count from Wikipedia the free encyclopedia
the word count is the number of words in a document or passage of text Word counting may be needed when a text
is required to stay within certain numbers of words This may particularly be the case in academia legal
proceedings journalism and advertising Word count is commonly used by translators to determine the price for
the translation job Word counts may also be used to calculate measures of readability and to measure typing
and reading speeds usually in words per minute When converting character counts to words a measure of five or
six characters to a word is generally used Contents Details and variations of definition Software In fiction
In non fiction See also References Sources External links Details and variations of definition
This section does not cite any references or sources Please help improve this section by adding citations to
reliable sources Unsourced material may be challenged and removed
Variations in the operational definitions of how to count the words can occur namely what counts as a word and
which words don't count toward the total However especially since the advent of widespread word processing there
is a broad consensus on these operational definitions and hence the bottom line integer result
The consensus is to accept the text segmentation rules generally found in most word processing software including how
word boundaries are determined which depends on how word dividers are defined The first trait of that definition is that a space any of various whitespace
characters such as a regular word space an em space or a tab character is a word divider Usually a hyphen or a slash is too
Different word counting programs may give varying results depending on the text segmentation rule
details and on whether words outside the main text such as footnotes endnotes or hidden text) are counted But the behavior
of most major word processing applications is broadly similar However during the era when school assignments were done in
handwriting or with typewriters the rules for these definitions often differed from todays consensus
Most importantly many students were drilled on the rule that certain words don't count usually articles namely a an the but
sometimes also others such as conjunctions for example and or but and some prepositions usually to of Hyphenated permanent
compounds such as follow up noun or long term adjective were counted as one word To save the time and effort of counting
word by word often a rule of thumb for the average number of words per line was used such as 10 words per line These rules
have fallen by the wayside in the word processing era the word count feature of such software which follows the text
segmentation rules mentioned earlier is now the standard arbiter because it is largely consistent across documents and
applications and because it is fast effortless and costless already included with the application As for which sections of
a document count toward the total such as footnotes endnotes abstracts reference lists and bibliographies tables figure
captions hidden text the person in charge teacher client can define their choice and users students workers can simply
select or exclude the elements accordingly and watch the word count automatically update Software Modern web browsers
support word counting via extensions via a JavaScript bookmarklet or a script that is hosted in a website Most word
processors can also count words Unix like systems include a program wc specifically for word counting
As explained earlier different word counting programs may give varying results depending on the text segmentation rule
details The exact number of words often is not a strict requirement thus the variation is acceptable
In fiction Novelist Jane Smiley suggests that length is an important quality of the novel However novels can vary
tremendously in length Smiley lists novels as typically being between and words while National Novel Writing Month
requires its novels to be at least words There are no firm rules for example the boundary between a novella and a novel
is arbitrary and a literary work may be difficult to categorise But while the length of a novel is to a large extent up
to its writer lengths may also vary by subgenre many chapter books for children start at a length of about words and a
typical mystery novel might be in the to word range while a thriller could be over words
The Science Fiction and Fantasy Writers of America specifies word lengths for each category of its Nebula award categories
Classification Word count Novel over words Novella to words Novelette to words Short story under words
In non fiction The acceptable length of an academic dissertation varies greatly dependent predominantly on the subject
Numerous American universities limit Ph.D. dissertations to at most words barring special permission for exceeding this limit
使用python运行以下程序看看,运行之前使用pip install pyspark安装pyspark包
from pyspark import SparkConf # Spark Configuration
from pyspark import SparkContext # Spark Context
conf = SparkConf().setMaster("local[*]")
spark = SparkContext(conf=conf)
rdd_init = spark.textFile("input.txt")
rdd_init.collect()
rdd_flatmap = rdd_init.flatMap(lambda line: line.split(" ")) ## Return PipelinedRDD
rdd_flatmap.collect() ## flatmap, 对元素内部继续进行 map,深层次的 map
kv = rdd_flatmap.map(lambda word: (word, 1))
wordCounts = kv.reduceByKey(lambda a, b: a + b)
wordCounts = wordCounts.map(lambda x: (x[1], x[0])).sortByKey((False))
print(wordCounts.collect())
wordCounts.coalesce(1).saveAsTextFile("./output/")
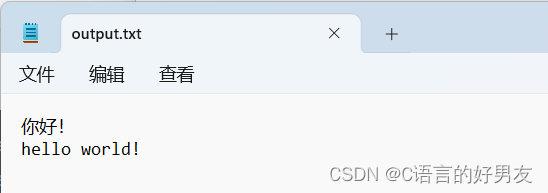
运行成功则可以在output文件夹中看到以下内容,其中part-00000则包含了所有单词统计信息

![[SWPUCTF] 2021新生赛之(NSSCTF)刷题记录 ①](https://img-blog.csdnimg.cn/a085f20bd96945be8e5572d55425dba3.png)