Scrapy框架基本使用流程
前言
本文中介绍 Scrapy 框架的基本使用流程,并以抓取汽车之家二手车数据为例进行讲解。
正文
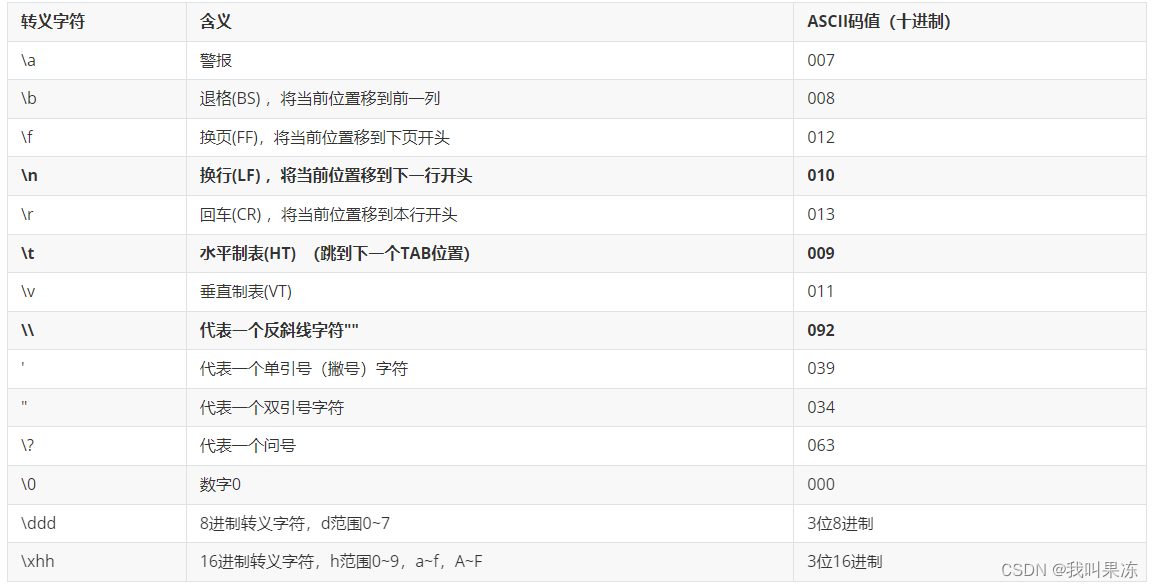
1、Scrapy框架基本使用流程
-
创建爬虫项目:
scrapy startprojecct 项目名 -
cd到项目文件夹:
cd 项目名 -
创建爬虫文件:
scrapy genspider 爬虫文件名 浏览器地址栏中的域名 -
定义抓取的数据结构:编写 items.py 文件
import scrapy class 项目名item(scrapy.Item): scrapy.Field() price = scrapy.Field() link = scrapy.Field() ... ... -
爬虫文件解析提取数据:编写 爬虫文件名.py 文件
import scrapy from ..items import 项目名item class 类名Spider(scrapy.Spider): name = "爬虫文件名" # 爬虫名 allowed_domains = ["浏览器地址栏中的域名"] # 允许爬取的域名:在创建爬虫文件的时候指定的域名 start_urls = [""] # 第一页的url地址 def parse(self, response): 解析提取数据 item=项目名item() item["name"]=xxx # 数据交给管道文件处理的方法 yield item # 需要进行跟进的url地址,如何交给调度器入队列 yield scrapy.Request(url=url, callback=self.parse) -
管道文件处理爬虫文件提取的数据:编写 pipelines.py 文件
class 项目名spiderPipeline: def process_item(self, item, spider): # 具体处理数据的代码 return item -
全局配置:编写 settings.py 文件
ROBOTSTXT_OBEY = False # robots协议 CONCURRENT_REQUESTS = 32 # 最大并发数 DOWNLOAD_DELAY = 1 # 下载延迟时间 COOKIES_ENABLED = False # Cookies检查 DEFAULT_REQUEST_HEADERS = { "Cookie": "", "User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko)" } # 请求头 ITEM_PIPELINES = { # 项目目录名.模块名.类名:优先级(1-1000不等) } # 开启管道 -
运行爬虫:run.py
在项目文件夹下创建: run.py 文件并运行from scrapy import cmdline cmdline.execute('scrapy crawl 爬虫文件名'.split())
2、scrapy框架项目启动方式
-
基于start_urls启动:从爬虫文件的start_urls变量中遍历url地址,交给调度器入队列,把下载器返回的响应对象交给爬虫文件的parse()函数处理
-
重写start_requests()方法:去掉start_urls变量
def start_requests(self): 生成要爬取的url地址 利用scrapy.Requst()交给调度器
3、基于Scrapy框架实现汽车之家二手车数据抓取
-
项目需求:抓取汽车名称、价格、链接
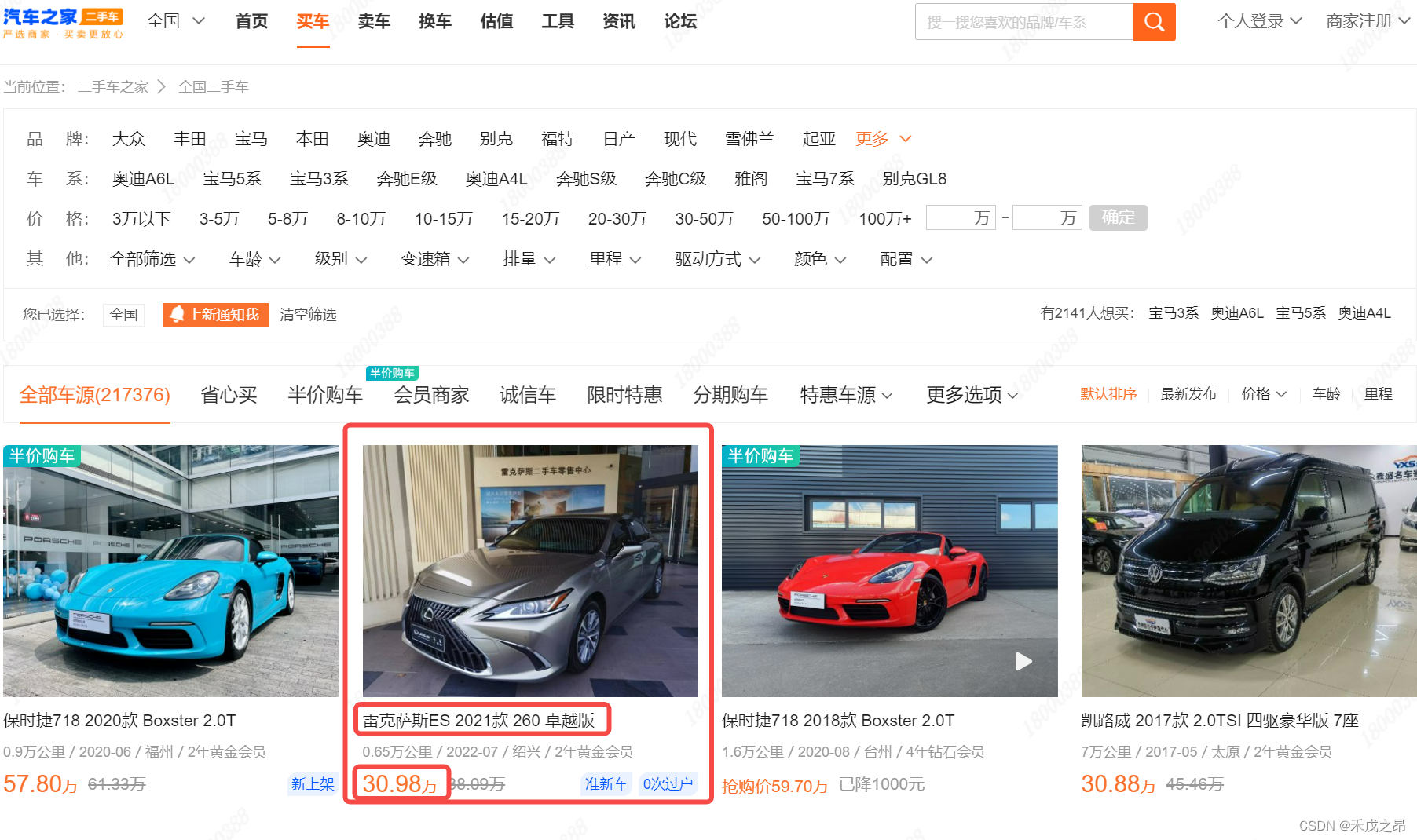
-
url地址规律:
https://www.che168.com/china/a0_0msdgscncgpi1ltocsp1exx0/ https://www.che168.com/china/a0_0msdgscncgpi1ltocsp2exx0/ https://www.che168.com/china/a0_0msdgscncgpi1ltocsp3exx0/ https://www.che168.com/china/a0_0msdgscncgpi1ltocsp4exx0/ ... https://www.che168.com/china/a0_0msdgscncgpi1ltocsp{}exx0/ -
创建项目和爬虫文件:
scrapy startproject CarSpider # 创建项目 cd CarSpider # 进入项目目录 scrapy genspider car www.che168.com # 创建爬虫文件 -
item.py:定义要抓取的数据结构,定义的方式是抓取什么数据,就写什么字段
import scrapy class CarspiderItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() # 汽车的名称、价格、和详情页链接,相当于定义了一个字典,只赋值了key,未赋值value name = scrapy.Field() price = scrapy.Field() link = scrapy.Field() -
car.py:爬虫文件,提取具体的数据,给item赋值,将数据交给管道(yield item)
start_url :存放第一页的url地址,在此项目中可以采用第二种项目启动方式,重写start_requests() 方法,一次性生成所有要抓取的url地址,并一次性交给调度器入队列class CarSpider(scrapy.Spider): name = "car" allowed_domains = ["www.che168.com"] # i = 1 # 1、删除掉 start_urls 变量 # start_urls = ["https://www.che168.com/china/a0_0msdgscncgpi1ltocsp1exx0/"] # 从第一页开始 def start_requests(self): """ 2、重写 start_requests() 方法:一次性生成所有要抓取的url地址,并一次性交给调度器入队列 :return: """ for i in range(1, 3): url = "https://www.che168.com/china/a0_0msdgscncgpi1ltocsp{}exx0/".format(i) # 交给调度器入队列,并指定解析函数 yield scrapy.Request(url=url, callback=self.detail_page) def detail_page(self, response): item = CarspiderItem() # 给item.py的CarspiderItem类做实例化 # 先写基准xpath //body/div/div/ul/li li_list = response.xpath("//body/div/div/ul[@class='viewlist_ul']/li") for li in li_list: item["name"] = li.xpath("./@carname").get() item["price"] = li.xpath("./@price").get() item["link"] = li.xpath("./a/@href").get() yield item # yield item:把抓取的数据提交给管道文件处理response.xpath() 使用说明:结果为列表,列表中元素为选择器对象 ,
[<selector xpath='xxx' data='A'>,<selector xpath='xxx' data='B'> ]
列表.extract():序列化列表中所有选择器为字符串[‘A’,‘B’]
列表.extract_first()|get():序列化并提取第1个数据 ‘A’ -
pipelines.py:管道文件
# useful for handling different item types with a single interface import pymysql from .settings import * from itemadapter import ItemAdapter class CarspiderPipeline: def process_item(self, item, spider): print(item["name"], item["price"], item["link"]) # 打印,执行具体的数据处理 return item -
settings.py:进行全局配置
BOT_NAME = "CarSpider" SPIDER_MODULES = ["CarSpider.spiders"] NEWSPIDER_MODULE = "CarSpider.spiders" # Obey robots.txt rules ROBOTSTXT_OBEY = False # 设置日志级别:DEBUG < INFO < WARNING < ERROR < CARITICAL LOG_LEVEL = 'INFO' # 保存日志文件 LOG_FILE = 'car.log' # See also autothrottle settings and docs DOWNLOAD_DELAY = 1 # Override the default request headers: DEFAULT_REQUEST_HEADERS = { "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8", "Accept-Language": "en", "User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko)" } # Configure item pipelines # See https://docs.scrapy.org/en/latest/topics/item-pipeline.html # 开启管道 ITEM_PIPELINES = { # 项目目录名.模块名.类名:优先级(1-1000不等) "CarSpider.pipelines.CarspiderPipeline": 300, # "CarSpider.pipelines.CarMysqlPipeline": 400 } # Set settings whose default value is deprecated to a future-proof value REQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7" TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor" FEED_EXPORT_ENCODING = "utf-8" # 设置数据导出的编码"utf-8" "gb18030" -
run.py:写程序入口函数 , scrapy.cfg同目录
from scrapy import cmdline cmdline.execute('scrapy crawl car'.split()) -
运行效果