CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.CV
1.Deep RL at Scale: Sorting Waste in Office Buildings with a Fleet of Mobile Manipulators

标题:大规模深度强化学习:使用移动机械手对办公楼中的垃圾进行分类
作者:Mengyuan Yan Jessica Lin Montserrat Gonzalez Arenas Ted Xiao Daniel Kappler Daniel Ho
文章链接:https://rl-at-scale.github.io/assets/rl_at_scale.pdf
项目代码:https://rl-at-scale.github.io/



摘要:
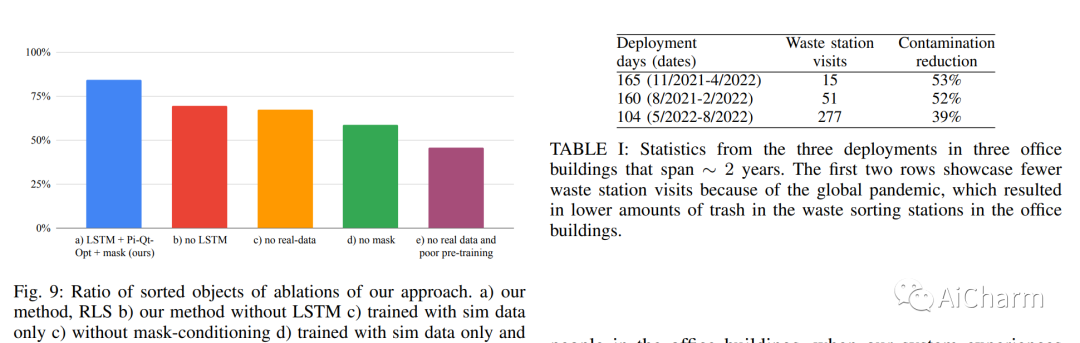
我们描述了一个用于深度强化学习机器人操作技能的系统,该系统应用于大规模的现实世界任务:分类办公楼中的可回收物和垃圾。深度 RL 策略在现实世界中的部署不仅需要有效的训练算法,还需要引导现实世界训练并实现广泛泛化的能力。为此,我们的系统——大规模强化学习 (RLS)——将来自真实世界数据的可扩展深度强化学习与来自模拟训练的引导相结合,并结合来自现有计算机视觉系统的辅助输入,以此作为促进对新对象的泛化的一种方式,同时保留端到端培训的好处。我们分析了系统中不同设计决策的权衡,并提出了大规模的实证验证,其中包括对在 24 个月的实验过程中收集的真实世界数据的培训,这些数据来自三座办公楼中的 23 个机器人,总计 9527 小时的机器人体验训练集。我们的最终验证还包括跨 240 个垃圾站配置的 4800 次评估试验,以便详细评估设计决策对我们系统的影响、包含更多真实世界数据的缩放效应以及该方法在新颖性上的性能对象。
2.Adaptive Human Matting for Dynamic Videos(CVPR 2023)

标题:动态视频的自适应人类抠图
作者:Chung-Ching Lin, Jiang Wang, Kun Luo, Kevin Lin, Linjie Li, Lijuan Wang, Zicheng Liu
文章链接:https://arxiv.org/abs/2304.06018
项目代码:https://github.com/microsoft/AdaM
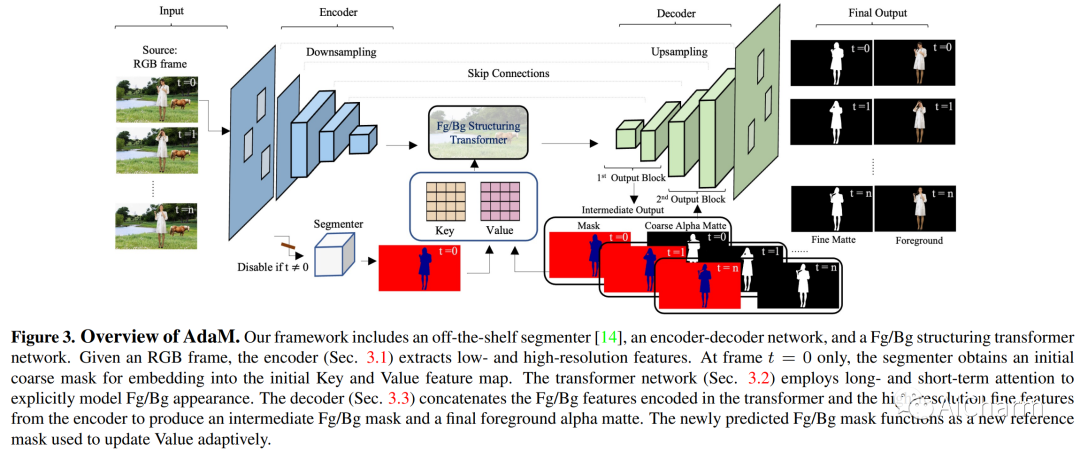
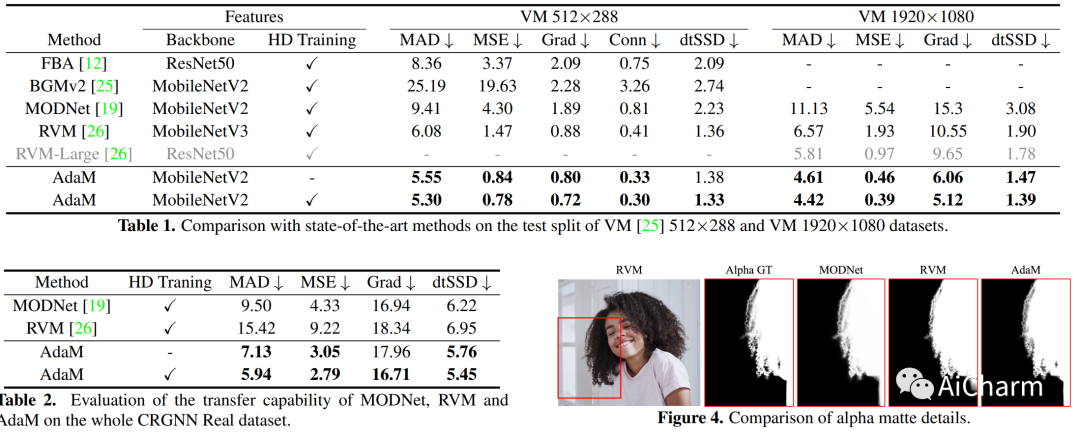
摘要:
视频抠图的最新努力集中在消除 trimap 依赖性上,因为 trimap 注释很昂贵,而且基于 trimap 的方法不太适合实时应用程序。尽管最新的 tripmap-free 方法显示出可喜的结果,但在处理高度多样化和非结构化的视频时,它们的性能往往会下降。我们通过引入动态视频的自适应遮罩(称为 Adam)来解决这一限制,该框架旨在同时区分前景和背景并捕获前景中人类主体的 alpha 遮罩细节。采用两个互连的网络设计来实现这一目标:(1) 一个编码器-解码器网络,它产生 alpha 遮罩和中间掩码,用于指导变换器自适应地解码前景和背景,以及 (2) 一个变换器网络,其中长- 和短期注意力相结合以保留空间和时间上下文,促进前景细节的解码。我们在最近引入的数据集上对我们的方法进行了基准测试和研究,表明我们的模型显着改善了复杂真实世界视频中的消光真实感和时间连贯性,并实现了新的一流泛化能力。此 https URL 提供了更多详细信息和示例。
3.ImageReward: Learning and Evaluating Human Preferences for Text-to-Image Generation

标题:ImageReward:学习和评估人类对文本到图像生成的偏好
作者:Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, Yuxiao Dong
文章链接:https://arxiv.org/abs/2304.05977
项目代码:https://github.com/THUDM/ImageReward

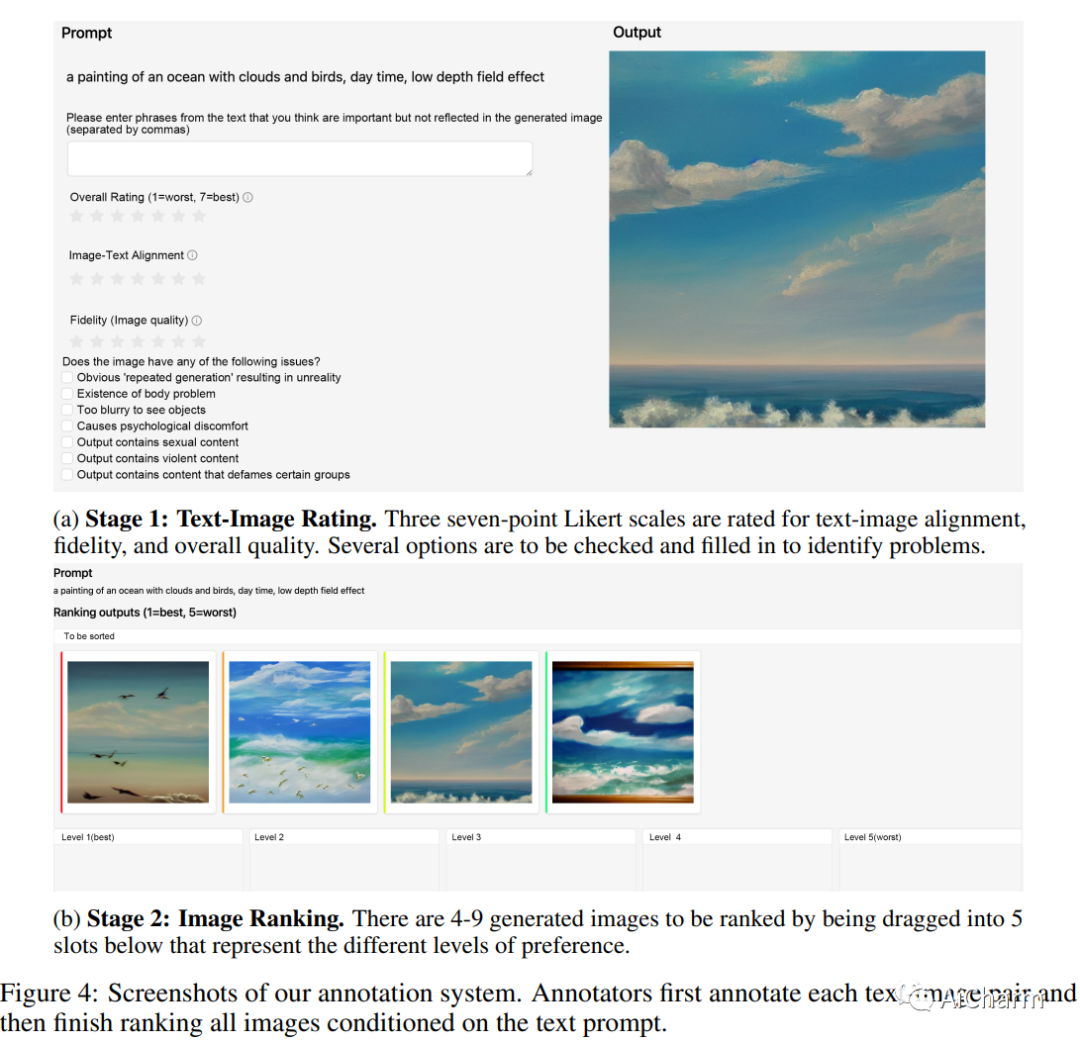

摘要:
我们提出了 ImageReward——第一个通用的文本到图像人类偏好奖励模型——来解决生成模型中的各种普遍问题,并使它们与人类价值观和偏好保持一致。它的训练基于我们的系统注释管道,涵盖评级和排名组件,收集了迄今为止 137k 专家比较的数据集。在人类评估中,ImageReward 优于现有的评分方法(例如,CLIP 38.6%),使其成为评估和改进文本到图像合成的有前途的自动指标。
更多Ai资讯:公主号AiCharm