前言:近期,一个线上的项目,请求出现了大量接口超时的问题,找了几个小时原因,最终发现是因为数据库服务器的磁盘满了,在此记录一下寻找的过程以及发现的问题,以备后续参考。
环境:
- 项目服务器(CentOS 64-bit 7.9)
- OpenJDK 1.8.0_272
- 数据库服务器(CentOS 64-bit 7.9)
- Mysql 5.7.19-log
(1).出现问题
下午5点多,有人向我们反馈,所有开放接口调用时都出现了请求超时的问题,日志输出如下:
cn.hutool.http.HttpException: Read timed out
简而言之就是Http请求出现了超时的问题。
(2).检查服务
既然是请求超时,第一个想到的就是服务会不会挂掉了,于是进服务器看了下,发现服务正常,日志也显示有收到请求。
(3).检查网络
既然服务没有问题,那么有没有可能网络出现了问题,因为这阵子确实有改变过网络环境,于是联系了他们的运维,互相ping了一下,没有问题,带上服务的端口telnet一下,也没有问题,于是,尝试用curl请求接口,发现接口的鉴权验证也能正常拦截鉴权错误的请求,此时基本确定了网络没有问题。

但由于鉴权的基本验证并没有走MySQL,只有在鉴权通过以后,才会在MySQL记录请求信息,所以这里的错误鉴权并没有出现超时的问题。
(4).检查端口
使用lsof指令查看端口,发现有很多状态是CLOSE_WAIT的连接,所以可以判断出问题原因是有大量的请求没有正常返回(包括前端页面请求、开放接口请求和设备使用的接口请求)
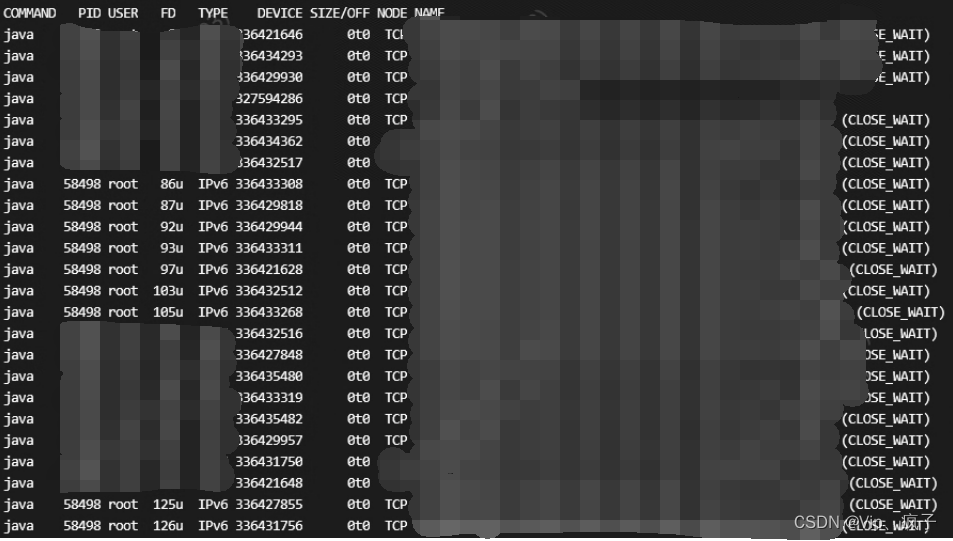
(5).重启服务
确认接口逻辑没有问题后,感觉问题可能是连接数量太多,导致大量的CLOSE_WAIT。
有没有可能是有人攻击服务器?于是尝试将服务的端口关闭,只对特定的ip开放。设置完成后,尝试重新请求接口,发现鉴权错误的请求还是能正常返回,于是构造了一个鉴权正确的请求,发现请求出现一直等待响应的问题,于是确认问题出在服务这边,但具体原因仍然未知。
于是尝试重启大法,看看能不能解决问题。结果,服务起不来了,且一直卡在初始化设备状态的逻辑。看了下日志输出,确认是卡在了数据库执行操作上。
(6).检查数据库
进入数据库服务器,发现数据库可以正常登录并执行查询语句,所以怀疑是不是有死锁的问题,执行show engine innodb status;后发现并没有死锁,检查了数据库服务器的连接情况,没有发现异常,线索又中断了…
在无奈之下,尝试重启数据库服务,结果,数据库服务起不来了,提示以下异常:
Starting MySQL... [ERROR] The server quit without updating PID file
这提示有锤子用啊…于是查看MySQL的异常日志,找到最近的[ERROR]标签,终于找到了问题:
mysqld: File '/data/.../.../log/mysql-bin.~rec~' not found (Errcode: 28 - No space left on device)
恍然大悟,没有磁盘空间了嘛,于是执行了一下df -hl,结果…
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/VG--xxxxx 400G 400G 28K 100% /data
这样都所有东西都解释通了:
- 只涉及数据库查询操作的都能正常返回(其它情况则导致请求发送成功,但一直等待返回值)
- 数据库没有执行完成,导致请求走不下去,所以出现请求发送成功,但服务端一直没有正常返回的问题
- 接口没有返回就导致客户端请求超时后强行断开,导致大量的CLOSE_WAIT
- 数据库跑不起来
瞬间感觉吃进了一斤答辩…
于是查看了占用较大的文件,发现数据库的慢日志文件slow.log占用特别大,里面记录了所有的数据库操作,但是明明在my.cnf配置了long_query_time = 1,为啥还会记录执行时间不到1s的日志呢?
不过先不管这么多了,把服务恢复才是首要任务,于是备份并删除慢日志,重启MySQL
Starting MySQL... [OK]
感觉心里的石头终于落地了
(7).再次重启服务
在数据库启动完成后,重启项目的中间件(因为中间件没有问题,所以上文省略了),重启服务,再次请求开放接口,发现正确的鉴权也能正常返回,至此,服务恢复正常。
遗留的问题:
- 服务端在请求执行时间过长的情况下不会自动断开
- 数据库在SQL语句执行时间过长的情况下没有自动断开
- 数据库慢日志记录了执行时间小于long_query_time的记录