文章目录
- 一、CDC 入湖
- 1.1、[开启binlog](https://blog.csdn.net/wuxintdrh/article/details/130142601)
- 1.2、创建测试表
- 1.2.1、创建mysql表
- 1.2.2、将 binlog 日志 写入 kafka
- 1、使用 mysql-cdc 监听 binlog
- 2、kafka 作为 sink表
- 3、写入sink 表
- 1.2.3、将 kakfa 数据写入hudi
- 1、kafak 作为 源表,flinksql 消费kafka
- 二、Bulk Insert (离线批量导入)
- 2.1、buck_insert 案例
- 2.2.1、mysql jdbc
- 2.2.2、hudi buck_insert
- 2.2.3、buck insert 写入hudi 表
- 三、Index Bootstrap (全量接增量)
- 3.1、Index Bootstrap 案例
- 四、Changelog Mode
- 4.1、基本特性
- 4.2、可选配置参数
- 4.3、案例
- 五、Append Mode
- 5.1、Inline Clustering (只支持 Copy_On_Write 表)
- 5.2、Async Clustering
- 5.3、Clustering Plan Strategy
- 六、Bucket Index
- 6.1、WITH 参数
- 6.2、与 state index 对比
- 七、Rate Limit (限流)
使用版本
hudi-0.12.1
flink-1.15.2
一、CDC 入湖
CDC(change data capture) 保证了完整数据变更,目前主要有两种方式
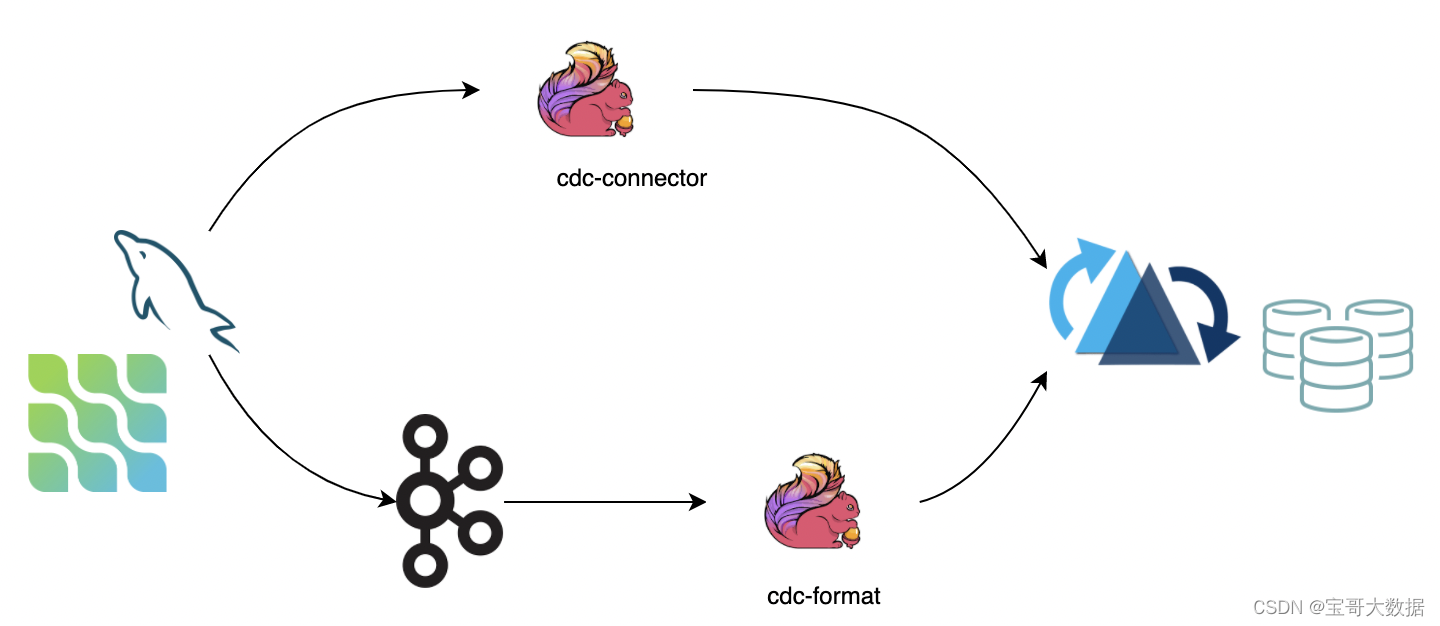
- 1、直接使用 cdc-connector 对接
DB的binlog数据导入。优点是不依赖消息队列,缺点是对 db server 造成压力。 - 2、对接 cdc format 消费 kafka 数据导入 hudi,优点是可扩展性强,缺点是依赖 kafka。
接下来我们主要介绍 第二种方式
1.1、开启binlog
1.2、创建测试表
1.2.1、创建mysql表
create database hudi_test;
use hudi_test;
-- 建表
create table person(
id int auto_increment primary key,
name varchar(30),
age int
);
1.2.2、将 binlog 日志 写入 kafka
mysql-cdc 参考: https://chbxw.blog.csdn.net/article/details/119841434
使用cdc-2.x
1、使用 mysql-cdc 监听 binlog
wget https://maven.aliyun.com/repository/central/com/ververica/flink-connector-mysql-cdc/2.0.0/flink-connector-mysql-cdc-2.0.0.jar
Flink SQL>
create database hudi_test;
use hudi_test;
create table person_binlog (
id bigint not null,
name string,
age int,
primary key (id) not enforced
) with (
'connector' = 'mysql-cdc',
'hostname' = 'chb1',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'database-name' = 'flinktest',
'table-name' = 'person'
);
使用mysql-cdc 报错
NoClassDefFoundError: org/apache/flink/shaded/guava18/com/google/common/util/concurrent/Thr
原因在于sql和非sql connector实现中对于shaded guava的处理不同,
使用 flink-sql-connector-mysql-cdc 替代 flink-connector-mysql-cdc 而且2.0.0版本不行,提升到2.2.1版本解决问题。
2、kafka 作为 sink表
-- 为了显示更清晰
Flink SQL> SET 'sql-client.execution.result-mode' = 'tableau';
[INFO] Session property has been set.
Flink SQL> SET 'execution.runtime-mode' = 'streaming';
[INFO] Session property has been set.
Flink SQL>
create table person_binlog_sink_kafka(
id bigint not null,
name string,
age int not null,
primary key (id) not enforced -- 主键
) with (
'connector' = 'upsert-kafka' -- kafka connector upsert-kafka
,'topic' = 'cdc_mysql_person_sink'
,'properties.zookeeper.connect' = 'chb1:2181'
,'properties.bootstrap.servers' = 'chb1:9092'
,'key.format' = 'json'
,'value.format' = 'json'
);
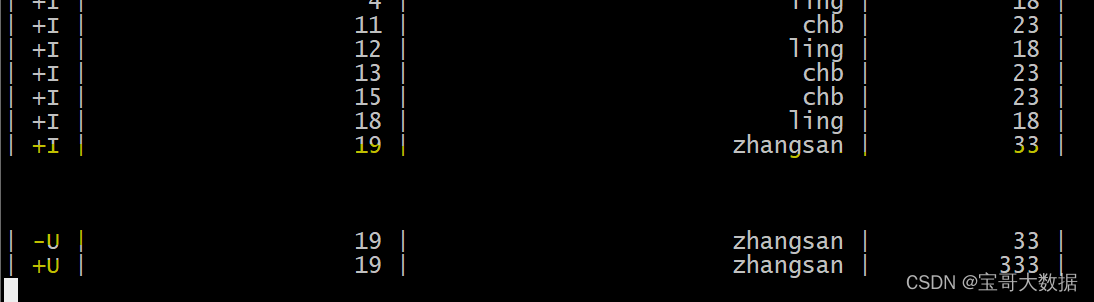
3、写入sink 表
Flink SQL>
insert into person_binlog_sink_kafka
select * from person_binlog;
1.2.3、将 kakfa 数据写入hudi
1、kafak 作为 源表,flinksql 消费kafka
Flink SQL>
create table person_binlog_source_kafka (
id bigint not null,
name string,
age int not null
) with (
'connector' = 'kafka'
,'topic' = 'cdc_mysql_person_sink'
,'properties.bootstrap.servers' = 'chb1:9092'
,'format' = 'json'
,'scan.startup.mode' = 'earliest-offset'
,'properties.group.id' = 'testGroup'
);
2、创建hudi目标表
Flink SQL>
create table person_binlog_sink_hudi (
id bigint not null,
name string,
age int not null,
primary key (id) not enforced -- 主键
) with (
'connector' = 'hudi',
'path' = 'hdfs://chb3:8020/hudi_db/person_binlog_sink_hudi',
'table.type' = 'MERGE_ON_READ',
'write.option' = 'insert'
);
3、将 kafka 中数据 写入 hudi
Flink SQL>
insert into person_binlog_sink_hudi
select * from person_binlog_source_kafka;
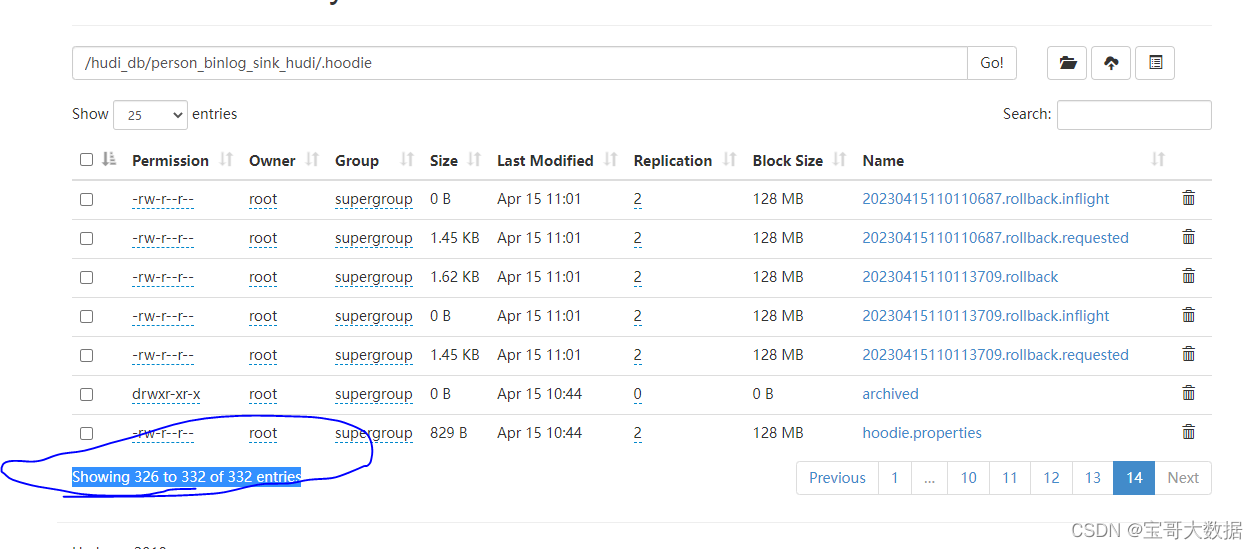
插入20条数据,产生332个小文件, 小文件问题
二、Bulk Insert (离线批量导入)
如果数据源来源于其他系统,可以使用批量导入数据功能,快速的将存量数据导入hudi。
- 1、消除了序列化和数据合并。由于跳过了重复数据删除,用户需要保证数据的唯一性。
- 2、在批处理执行模式下效率更高。默认情况下,批处理执行模式将输入记录按分区路径进行排序,并写入Hudi,避免频繁切换文件句柄导致写性能下降。
Flink SQL>
SET 'execution.runtime-mode' = 'streaming'; // 默认是流模式
SET 'execution.checkpointing.interval' = '0'; // 关闭checkpoint, batch模式不支持checkpoint
- 3、
bulk_insert的并行度由write.tasks指定。并行度会影响小文件的数量。理论上,bulk_insert的并行度是桶的数量(特别是,当每个桶写入到最大文件大小时,它将切换到新的文件句柄。最后,文件的数量>= write.bucket_assign.tasks。
| 参数名 | 是否必选 | 默认值 | 备注 |
|---|---|---|---|
write.operation | true | upsert | 设置为bulk_insert 开启功能 |
write.tasks | false | 4 | bulk_insert 的并行度, 文件数量 >= write.bucket_assign.tasks |
write.bulk_insert.shuffle_input | false | true | 写入前是否根据输入字段(分区) shuffle。启用此选项将减少小文件的数量,但可能存在数据倾斜的风险 |
write.bulk_insert.sort_input | false | true | 写入前是否根据输入字段(partition字段)对数据进行排序。当一个 write task写多个分区时,启用该选项将减少小文件的数量。 |
write.sort.memory | false | 128 | 排序算子 可用的 managed memory 默认128 MB 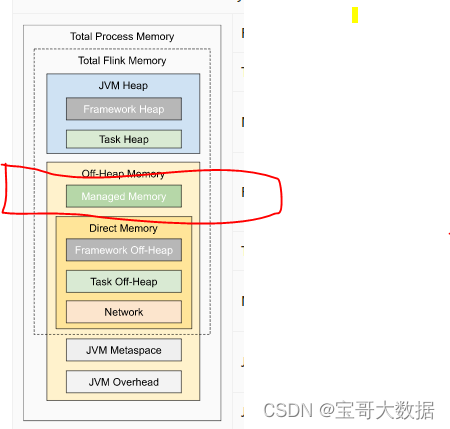 |
2.1、buck_insert 案例
2.2.1、mysql jdbc
参考: https://chbxw.blog.csdn.net/article/details/119479967
Flink SQL>
create table person (
id int not null,
name string,
age int not null,
primary key (id) not enforced
) with (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://chb1:3306/flinktest',
'username' = 'root',
'password' = '123456',
'table-name' = 'person'
);
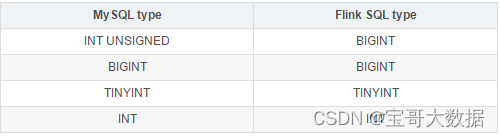
报错 java.lang.Integer cannot be cast to java.lang.Long, 由于 mysql 中 person的id 是 int 类型, 转为 flink 对应的是 int, 但是在flink建表时 字段为 bigint.所以报错。
2.2.2、hudi buck_insert
Flink SQL>
create table person_binlog_sink_hudi_buck (
id int not null,
name string,
age int not null,
primary key (id) not enforced -- 主键
) with (
'connector' = 'hudi',
'path' = 'hdfs://chb3:8020/hudi_db/person_binlog_sink_hudi_buck',
'table.type' = 'MERGE_ON_READ',
'write.option' = 'bulk_insert' -- 配置 buck_insert 模式
);
2.2.3、buck insert 写入hudi 表
Flink SQL>
insert into person_binlog_sink_hudi_buck
select * from person;
一次性的。

三、Index Bootstrap (全量接增量)
在上面使用 buck_insert 已经完成全量数据导入,接下来, 用户可以通过Index Bootstrap 功能实时插入增量数据,保证数据不重复。
WITH 参数
| 参数名 | 是否必选 | 默认值 | 备注 |
|---|---|---|---|
index.bootstrap.enabled | true | false | 此功能开启,Hudi 表中剩余的记录将一次性加载到Flink状态 |
index.partition.regex | false | * | 优化选择。设置正则表达式以过滤分区。默认情况下,所有分区都加载到flink状态 |
使用方法
CREATE TABLE创建一条与Hudi表对应的语句。 注意这个table.type配置必须正确。- 设置
index.bootstrap.enabled = true来启用index bootstrap功能 - 在
flink-conf.yaml文件中设置Flink checkpoint的容错机制,设置配置项execution.checkpointing.tolerable-failed-checkpoints = n(取决于Flink checkpoint执行时间) - 等待直到第一个
checkpoint成功,表明index bootstrap完成。 - 在
index bootstrap完成后,用户可以退出并保存savepoint(或直接使用外部 checkpoint`)。 - 重启任务,并且设置
index.bootstrap.enable为false。
注意:
- 索引引导是一个阻塞过程,因此在索引引导期间无法完成checkpoint。
- index bootstrap由输入数据触发。 用户需要确保每个分区中至少有一条记录。
- index bootstrap是并发执行的。用户可以在日志文件中通过
finish loading the index under partition以及Load record form file观察index bootstrap的进度。 - 第一个成功的checkpoint表明
index bootstrap已完成。 从checkpoint恢复时,不需要再次加载索引。
3.1、Index Bootstrap 案例
Flink SQL>
create table person_binlog_sink_hudi_boot (
id bigint not null,
name string,
age int not null,
primary key (id) not enforced -- 主键
) with (
'connector' = 'hudi',
'path' = 'hdfs://chb3:8020/hudi_db/person_binlog_sink_hudi_buck',
'table.type' = 'MERGE_ON_READ',
'index.bootstrap.enabled'='true'
);
index bootstrap表接cdc表
Flink SQL>
insert into person_binlog_sink_hudi_boot
select * from person_binlog;
四、Changelog Mode
4.1、基本特性
Hudi可以保留消息的所有中间变化(I / -U / U / D),然后通过flink的状态计算消费,从而拥有一个接近实时的数据仓库ETL管道(增量计算)。 Hudi MOR表以行的形式存储消息,支持保留所有更改日志(格式级集成)。 所有的更新日志记录可以使用Flink流阅读器。
4.2、可选配置参数
| 参数名 | 是否必选 | 默认值 | 备注 |
|---|---|---|---|
changelog.enabled | false | false | 默认是关闭的,即upsert语义,只有合并的消息被确保保留,中间的更改可以被合并。 设置为true以支持消费所有的更改 |
注意
-
不管格式是否存储了中间更改日志消息,批(快照)读取仍然合并所有中间更改。
-
在设置
changelog.enable为true时,中间的变更也是 best effort: 异步压缩任务将更新日志记录合并到一条记录中,因此如果流源不及时消费,则压缩后只能读取每个key的合并记录。- 解决方案是通过调整压缩策略,比如压缩选项:
compress.delta_commits和compression.delta_seconds,为读取器保留一些缓冲时间。
- 解决方案是通过调整压缩策略,比如压缩选项:
4.3、案例
Flink SQL> SET 'sql-client.execution.result-mode' = 'tableau'; -- table tableau changelog
[INFO] Session property has been set.
Flink SQL> SET 'execution.runtime-mode' = 'streaming';
[INFO] Session property has been set.
Flink SQL>
create table person2(
id bigint not null,
name string,
age int not null,
primary key (id) not enforced -- 主键
) with (
'connector' = 'hudi',
'path' = 'hdfs://chb3:8020/hudi_db/person2',
'table.type' = 'MERGE_ON_READ',
'read.streaming.enabled' = 'true',
'read.streaming.check-interval' = '4',
'changelog.enabled' = 'true'
);
-- 插入数据
insert into person2 values (1, 'chb', 23);
insert into person2 values (1, 'chb', 24);
select * from person2;

创建非changelog表, url 指向person2同一路径
Flink SQL>
create table person3(
id bigint not null,
name string,
age int not null,
primary key (id) not enforced -- 主键
) with (
'connector' = 'hudi',
'path' = 'hdfs://chb3:8020/hudi_db/person2',
'table.type' = 'MERGE_ON_READ',
'read.streaming.enabled' = 'true',
'read.streaming.check-interval' = '4'
);
结果只有最新数据

报错 Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.mapred.FileInputFormat
拷贝 hadoop-mapreduce-client-core.jar 到 flink lib.
五、Append Mode
从 0.10 开始支持
对于 INSERT 模式:
MOR默认会 apply 小文件策略: 会追加写 avro log 文件COW每次直接写新的 parquet 文件,没有小文件策略
Hudi 支持丰富的 Clustering 策略,优化 INSERT 模式下的小文件问题。
5.1、Inline Clustering (只支持 Copy_On_Write 表)
| 参数名 | 是否必选 | 默认值 | 备注 |
|---|---|---|---|
write.insert.cluster | false | false | 是否在写入时合并小文件,COW 表默认 insert 写不合并小文件,开启该参数后,每次写入会优先合并之前的小文件(不会去重),吞吐会受影响 (用的比较少,建议使用 Async Clustering) |
5.2、Async Clustering
从 0.12 开始支持
WITH 参数
| 名称 | Required | 默认值 | 说明 |
|---|---|---|---|
| clustering.schedule.enabled | false | false | 是否在写入时定时异步调度 clustering plan,默认关闭 |
| clustering.delta_commits | false | 4 | 调度 clsutering plan 的间隔 commits,clustering.schedule.enabled 为 true 时生效 |
| clustering.async.enabled | false | false | 是否异步执行 clustering plan,默认关闭 |
| clustering.tasks | false | 4 | Clustering task 执行并发 |
| clustering.plan.strategy.target.file.max.bytes | false | 1024 * 1024 * 1024 | Clustering 单文件目标大小,默认 1GB |
| clustering.plan.strategy.small.file.limit | false | 600 | 小于该大小的文件才会参与 clustering,默认600MB |
| false | N/A | 支持指定特殊的排序字段 | |
| false | NONE | 支持NONE:不做限制RECENT_DAYS:按时间(天)回溯SELECTED_PARTITIONS:指定固定的 partition | |
| false | 2 | RECENT_DAYS 生效,默认 2 天 |
5.3、Clustering Plan Strategy
支持定制化的 clustering 策略。
| 名称 | Required | 默认值 | 说明 |
|---|---|---|---|
| clustering.plan.partition.filter.mode | FALSE | NONE | 支持· NONE:不做限制· RECENT_DAYS:按时间(天)回溯· SELECTED_PARTITIONS:指定固定的 partition |
| clustering.plan.strategy.daybased.lookback.partitions | FALSE | 2 | RECENT_DAYS 生效,默认 2 天 |
| clustering.plan.strategy.cluster.begin.partition | FALSE | N/A | SELECTED_PARTITIONS 生效,指定开始 partition(inclusive) |
| clustering.plan.strategy.cluster.end.partition | FALSE | N/A | SELECTED_PARTITIONS 生效,指定结束 partition(incluseve) |
| clustering.plan.strategy.partition.regex.pattern | FALSE | N/A | 正则表达式过滤 partitions |
| clustering.plan.strategy.partition.selected | FALSE | N/A | 显示指定目标 partitions,支持逗号 , 分割多个 partition |
六、Bucket Index
默认的 flink 流式写入使用 state 存储索引信息:primary key 到 fileId 的映射关系。当数据量比较大的时候,state的存储开销可能成为瓶颈,bucket 索引通过固定的 hash 策略,将相同 key 的数据分配到同一个 fileGroup 中,避免了索引的存储和查询开销。
6.1、WITH 参数
| 名称 | Required | 默认值 | 说明 |
|---|---|---|---|
| index.type | false | FLINK_STATE | 设置 BUCKET 开启 Bucket 索引功能 |
| hoodie.bucket.index.hash.field | false | 主键 | 可以设置成主键的子集 |
| hoodie.bucket.index.num.buckets | false | 4 | 默认每个 partition 的 bucket 数,当前设置后则不可再变更。 |
6.2、与 state index 对比
- (1)bucket index 没有 state 的存储计算开销,性能较好
- (2)bucket index 无法扩容 buckets,state index 则可以依据文件的大小动态扩容
- (3)bucket index 不支持跨 partition 的变更(如果输入是 cdc 流则没有这个限制),state index 没有限制
七、Rate Limit (限流)
有许多用户将完整的历史数据集与实时增量数据一起放到消息队列中的用例。然后使用 flink 将队列中的数据从最早的偏移量消费到hudi中。
消费历史数据集具有以下特点:
- 1)瞬时吞吐量巨大
- 2)严重无序(随机写分区)。
这将导致写入性能下降和吞吐量故障。对于这种情况,可以打开速度限制参数以确保流的平滑写入。
| 名称 | Required | 默认值 | 说明 |
|---|---|---|---|
| write.rate.limit | false | 0 | 默认禁止限流 |
参考:
https://hudi.apache.org/cn/docs/hoodie_deltastreamer/#flink-ingestion