Transformer
Transformer实际上就是变形金刚,其与Bert实际类似。其实际上就是一个Sequence-to-Sequence的模型,其输出的长度并不是由人为指定,而是由机器自行确定。
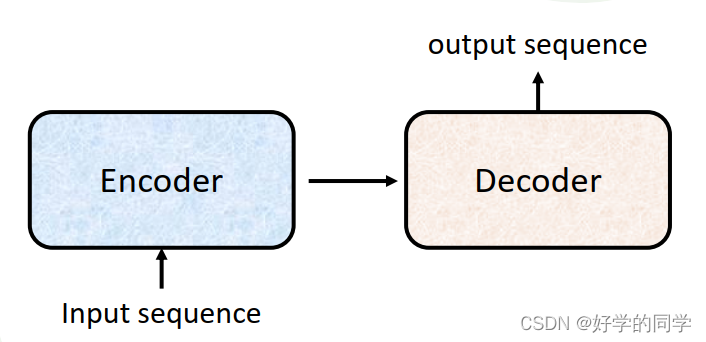
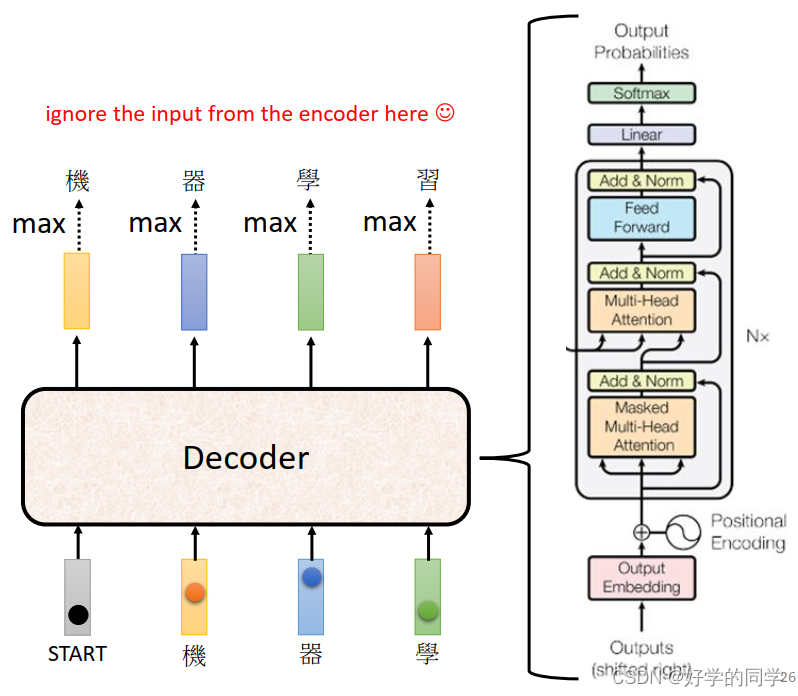
Transformer的基本结构,如上图所示,主要由一个Encoder和一个Decoder组成,一般将输入序列通过Encoder进行处理,处理完成后给到Decoder,由Decoder来确定输出向量。
1.Encoder
Encoder的基本结构:
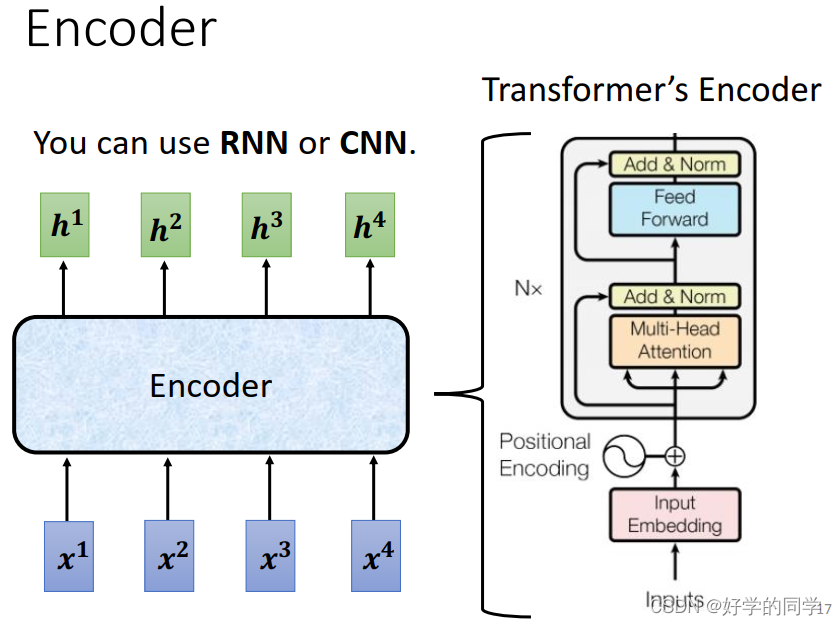
模型的编码器可以有多个Block进行编码处理。
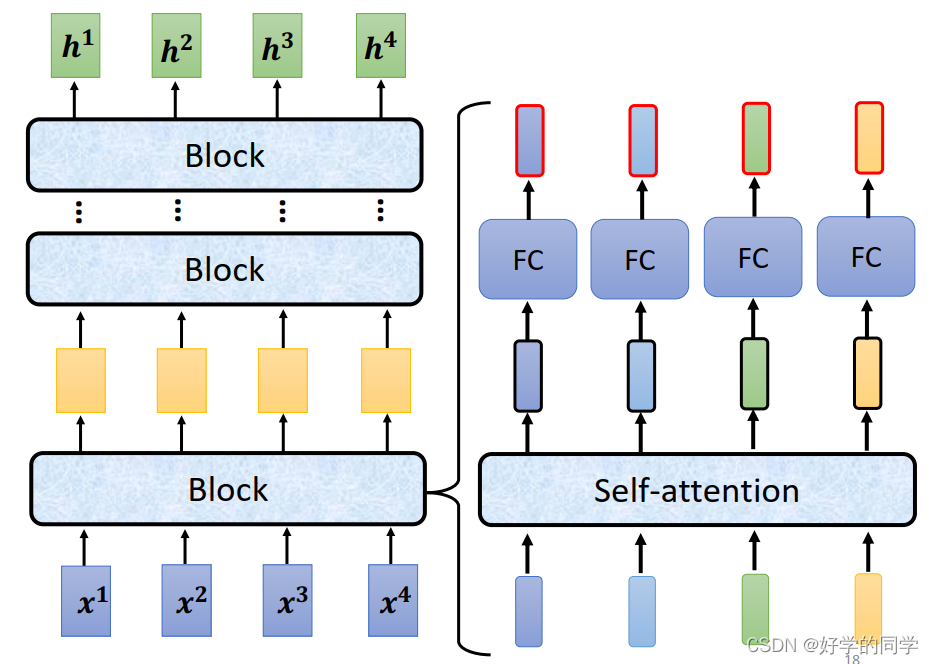
Block的具体结构:
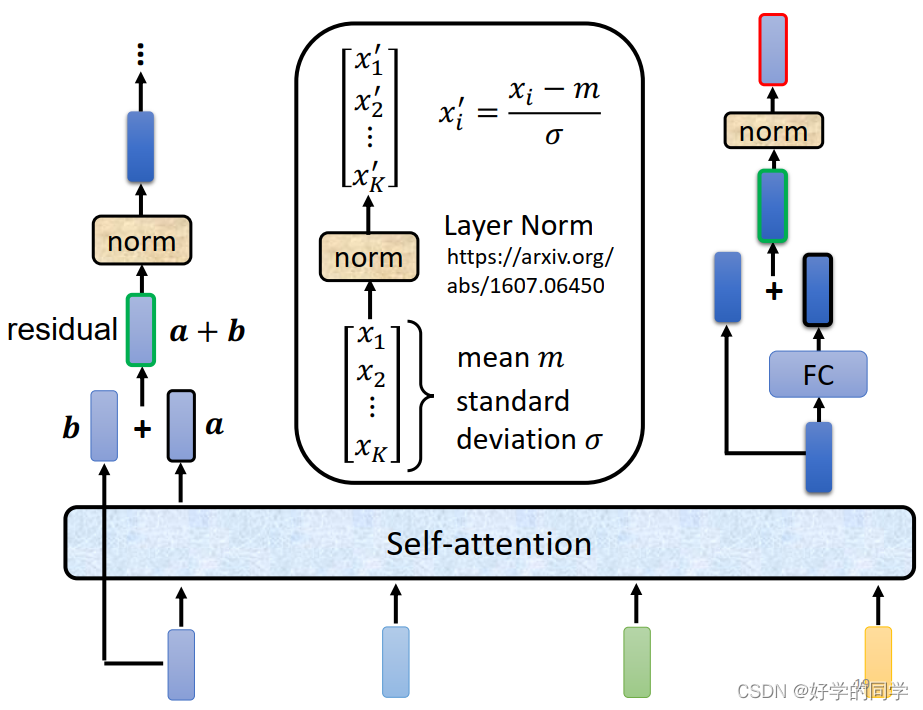
根据李老师课程中的讲解,仅以拆解内部的Block结构输入向量b讲过Self-Attention得到向量a,同时由相应的输入向量b进行残差连接,经过一次Layer Norm就可以得到向量c.接着将c作为FC网络的输入得到d,接着再次进行残差连接,得到向量e,最后再做一次Layer Norm操作得到向量f。
2.Decoder-Autoregressive (AT)
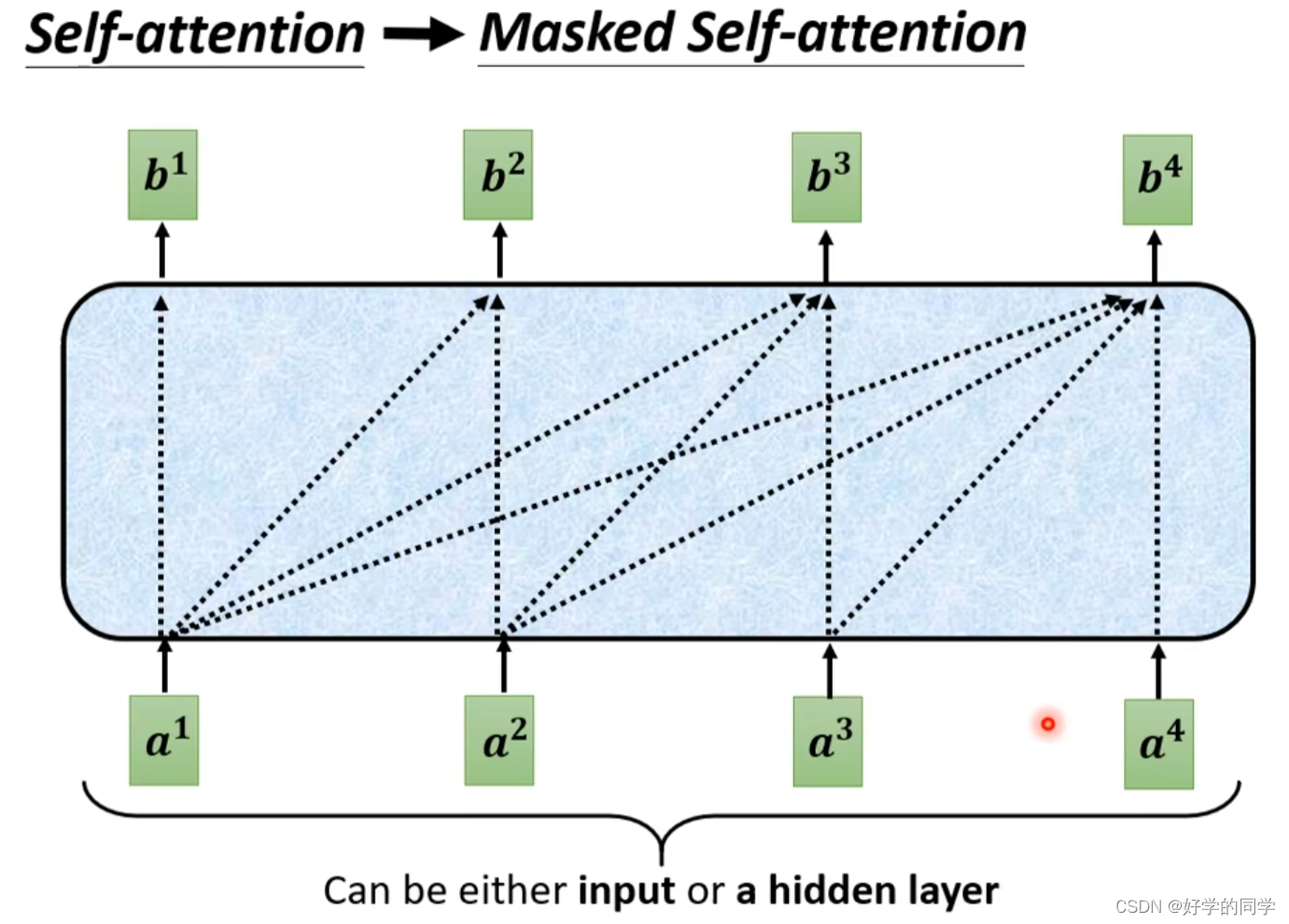
Decoder中使用的Masked Self-Attention结构如下图所示,只考虑之前的输入信息,并不考虑在当前点后的输入。
Decoder在进行处理的过程中会将自己上一个时刻的输出作为自己当前的输入,可能会出现一步错步步错的这样的问题,但是在训练过程中可以故意给模型喂入一些这样的数据,让模型在数据存在问题的情况下任然可以有比较不错的输出,防止出现一步错步步错的情况。
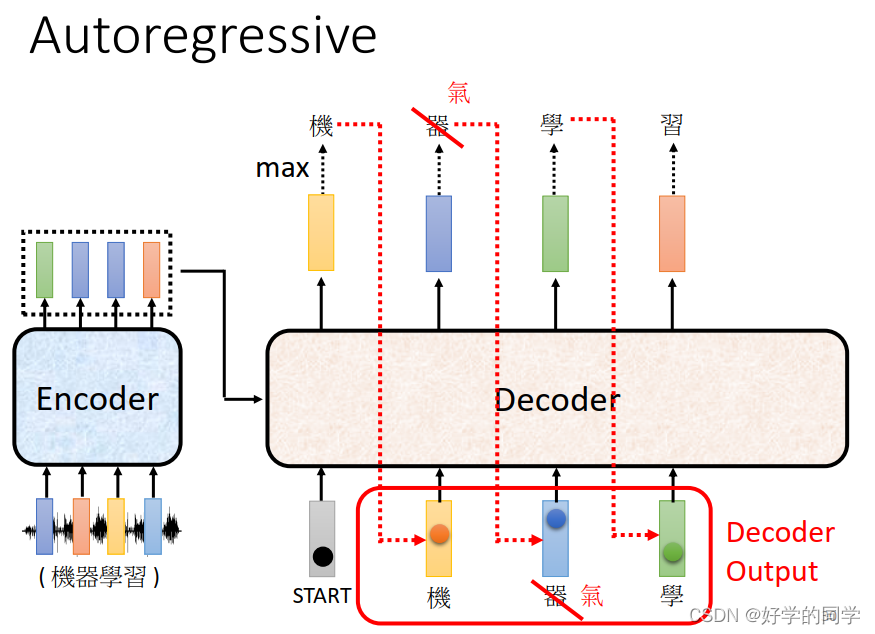
在做语音转换的时候需要有文字的结尾,防止出现Nerver Stop的问题。
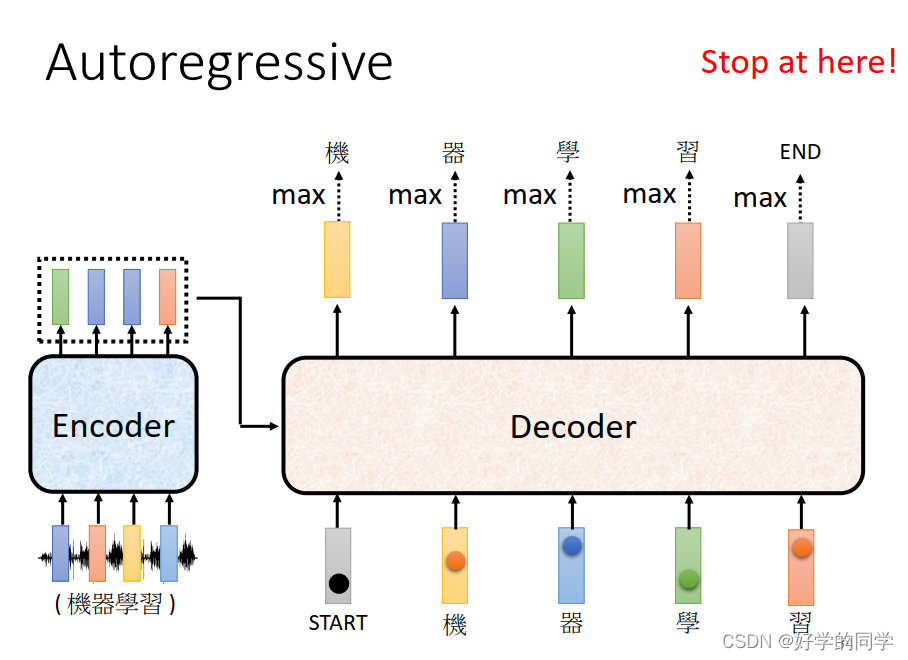
当模型输出END时候,模型就结束。
3.Decoder Non-autoregressive (NAT)
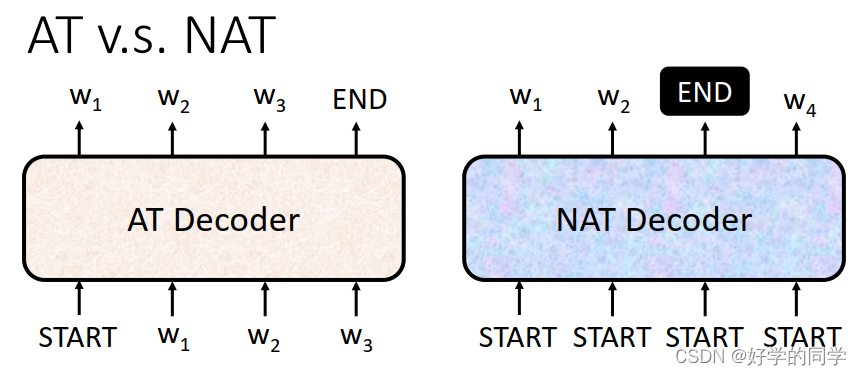
AT需要一步一步的去学习,并将上一次的学习的结果作为下一次学习的输入进行后续的操作,NAT直接一次性输入所有的vector,然后一次性输出整个句子,实现输出。输出的长度可以再设一个单独的模型来进行预测。另外一种方法,直接给一个足够长的start来让模型输出,我们只需要将开始到第一个END出现的位置视作为模型的实际输出即可。
NAT:可以实现并行运算,同时模型的输出长度也是可控的。
NAT的结果通常比AT的结果比较糟糕。由于Multi-modality的原因。
4. Encoder-Decoder
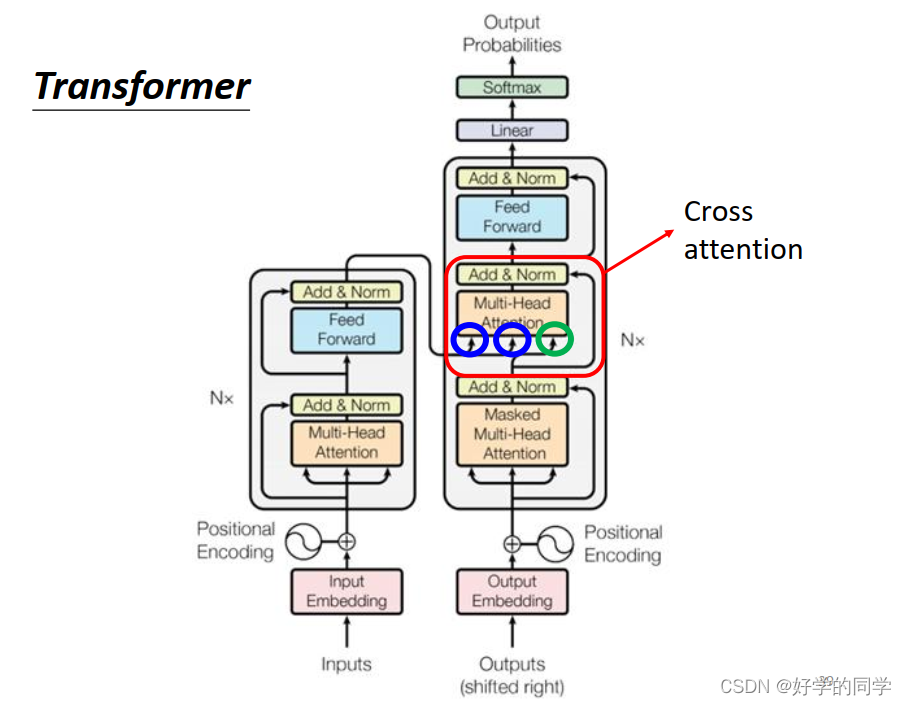
Decoder部分不仅有自身的输入向量,还有Encoder部分的输出作为输入向量。而Encoder部分的输出与Decoder中Masked Multi-Head Attention的输出一起被送到Multi-Head Attetion进行处理,这部分就叫Cross Attention,如上图。
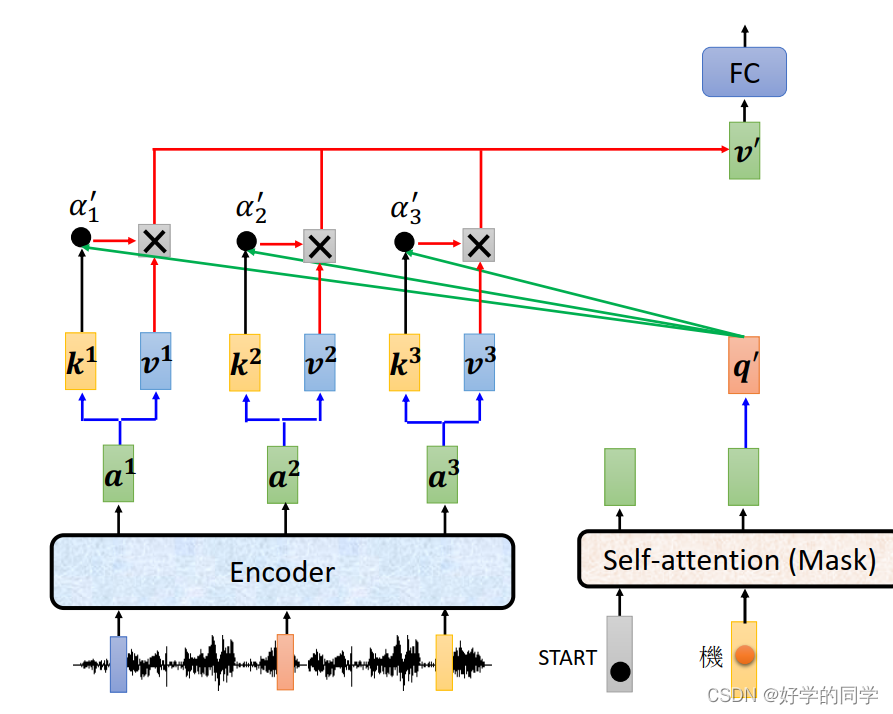
Cross-Attention的具体实现流程:
- Encoder的输出分别与各自对应的矩阵
,得到相应的key值,Decoder经过Masked Multi-Head Attention的输出与矩阵
相乘得到Query值,两者做点积得到相关性分数
;
- Encoder的输出分别与各自对应的矩阵
相乘得到相应的value值,然后与关联性分数
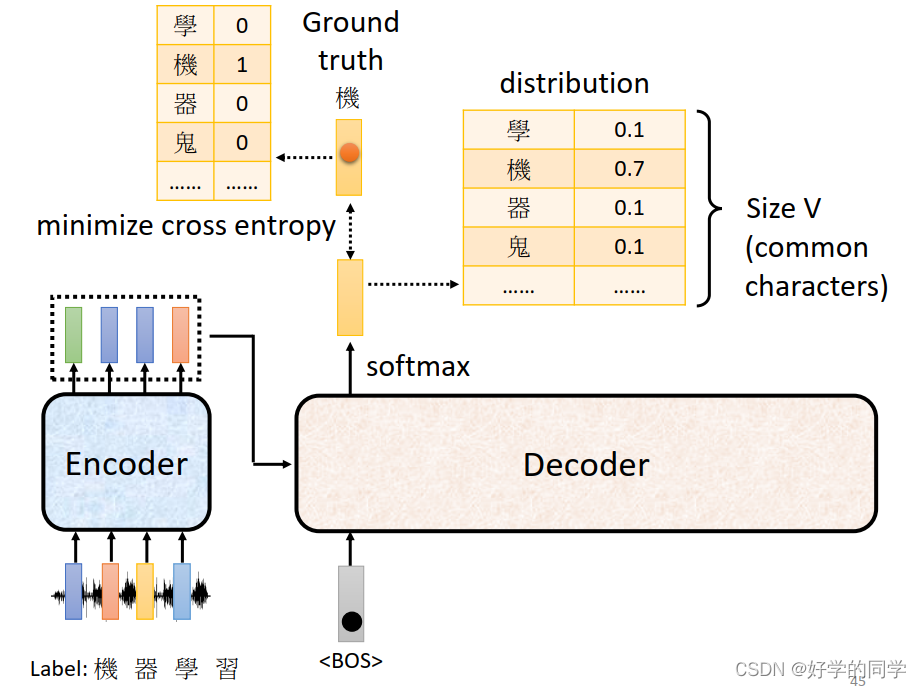
最后的输出实际上就是一个Softmax分类器,依次得到每一个字。