链路追踪
在大型系统的微服务化构建中,一个系统被拆分成了许多微服务。这些模块负责不同的功能,组合成系统,最终可以提供丰富的功能。在这种架构中,一次请求往往需要涉及到多个服务。互联网应用构建在不同的软件模块集上,这些软件模块,有可能是由不同的团队开发、可能使用不同的编程语言来实现、有可能布在了几千台服务器,横跨多个不同的数据中心【区域】,也就意味着这种架构形式也会存在一些问题:
l 如何快速发现问题?
l 如何判断故障影响范围?
l 如何梳理服务依赖以及依赖的合理性?
l 如何分析链路性能问题以及实时容量规划?
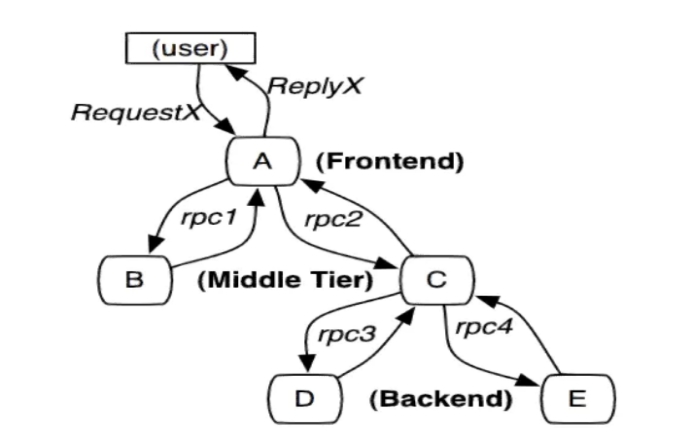
定位该请求的故障:发生在哪个微服务上。
理念: 在每个微服务节点上----》安装一个GPS. ----程序中----日志。我们在通过查看日志 就可以定位响应的错误。
收集-----展示到一个统一的界面。
第一个就是在每个微服务上 帮你产生日志记录。
第二个技术就是收集这些日志,并能展示到一个图形化界面上。
1. Sleuth
它的作用就是为微服务产生日志记录。
-
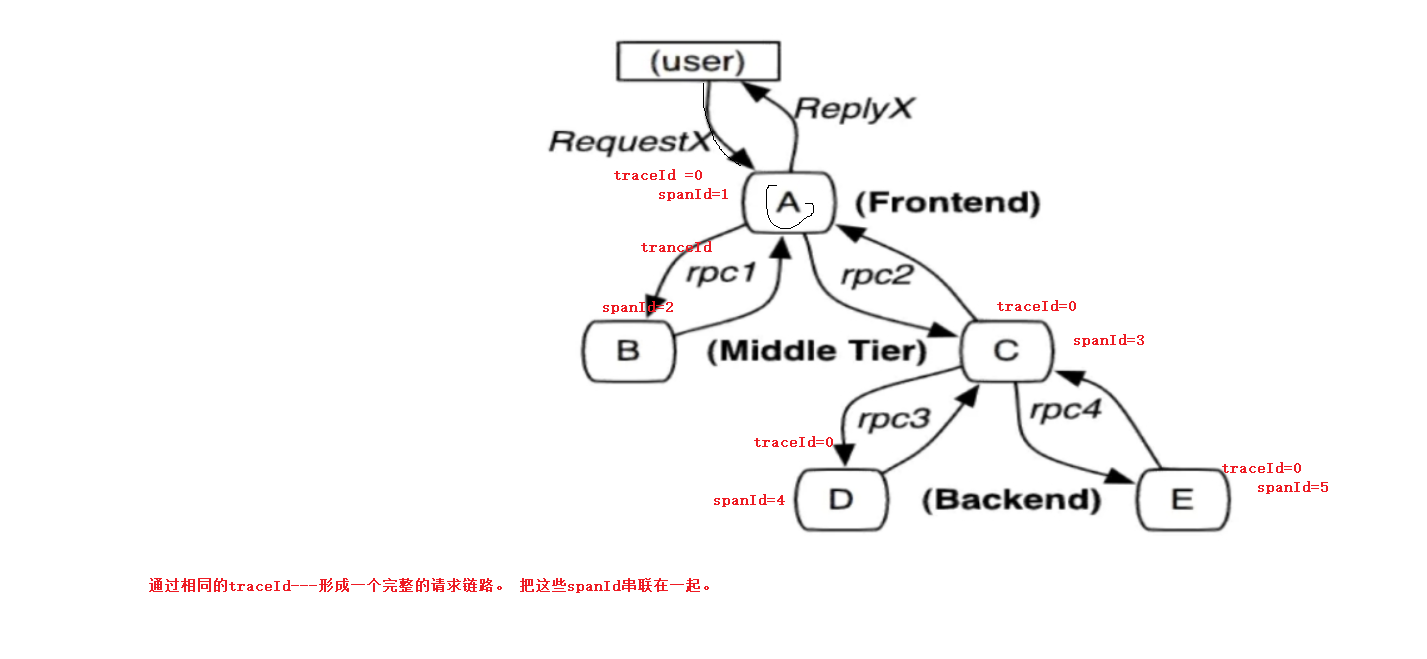
Trace (一次请求的完整链路–包含很多span(微服务接口))
- 由一组Trace Id(贯穿整个链路)相同的Span串联形成一个树状结构。为了实现请求跟踪,当请求到达分布式系统的入口端点时,只需要服务跟踪框架为该请求创建一个唯一的标识(即TraceId),同时在分布式系统内部流转的时候,框架始终保持传递该唯一值,直到整个请求的返回。那么我们就可以使用该唯一标识将所有的请求串联起来,形成一条完整的请求链路。 Span
- 代表了一组基本的工作单元。为了统计各处理单元的延迟,当请求到达各个服务组件的时候,也通过一个唯一标识(SpanId)来标记它的开始、具体过程和结束。通过SpanId的开始和结束时间戳,就能统计该span的调用时间,除此之外,我们还可以获取如事件的名称。请求信息等元数据。 Annotation
-
用它记录一段时间内的事件,内部使用的重要注释:
l cs(Client Send)客户端发出请求,开始一个请求的命令
l sr(Server Received)服务端接受到请求开始进行处理,sr-cs = 网络延迟(服务调用的时间)
l ss(Server Send)服务端处理完毕准备发送到客户端,ss - sr = 服务器上的请求处理时间
l cr(Client Reveived)客户端接受到服务端的响应,请求结束。cr - cs = 请求的总时间
1.1 如何使用sleuth
在微服务中引入sleuth依赖—整个父工程中
这样所有微服务都会拥有sleuth包
<!--引入sleuth依赖-->
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
</dependencies>
浏览器
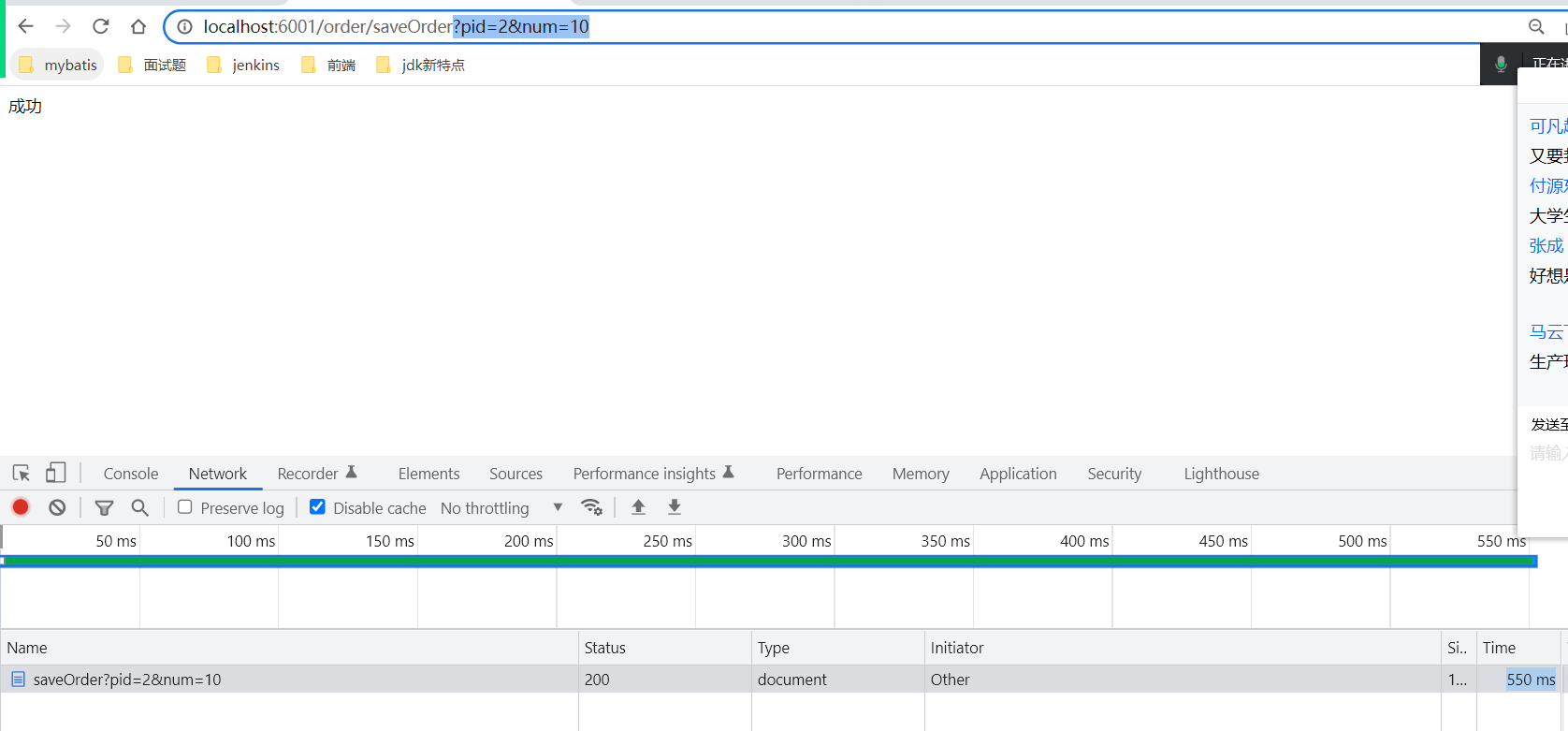
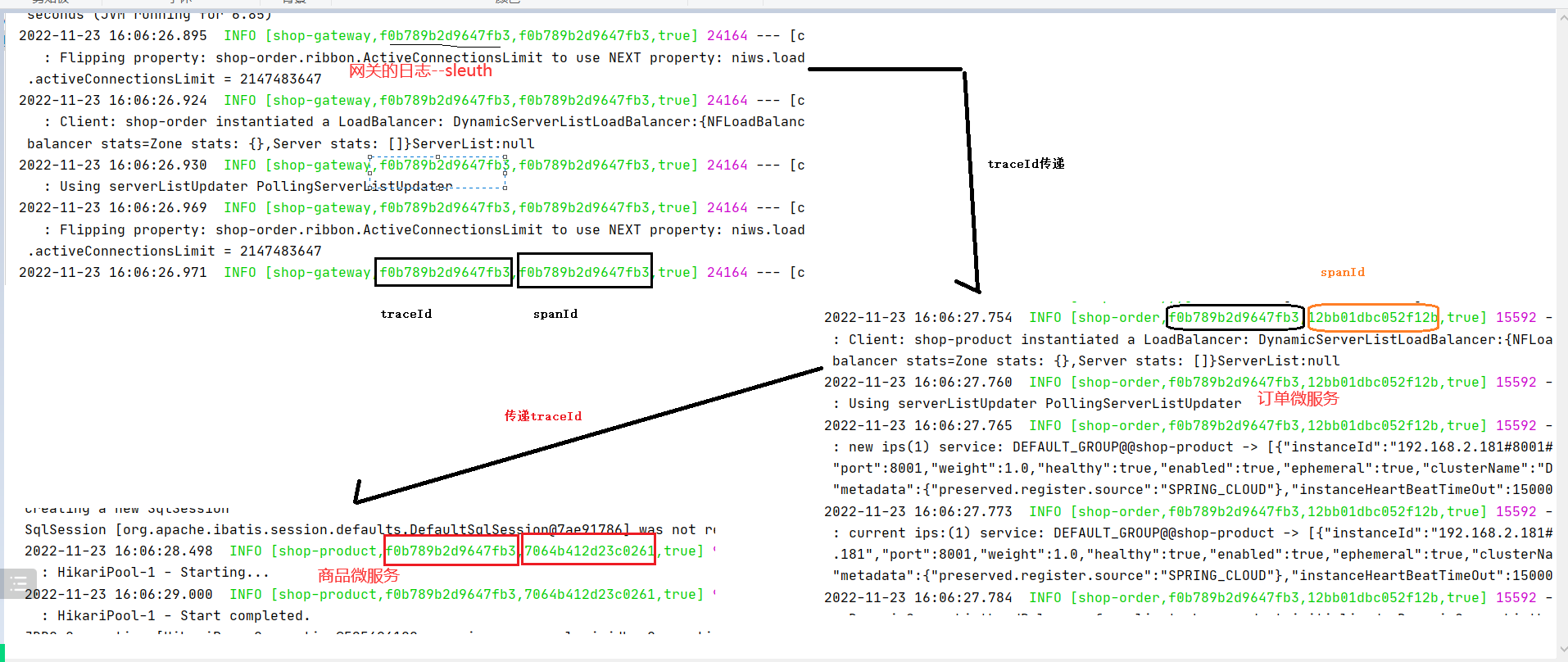
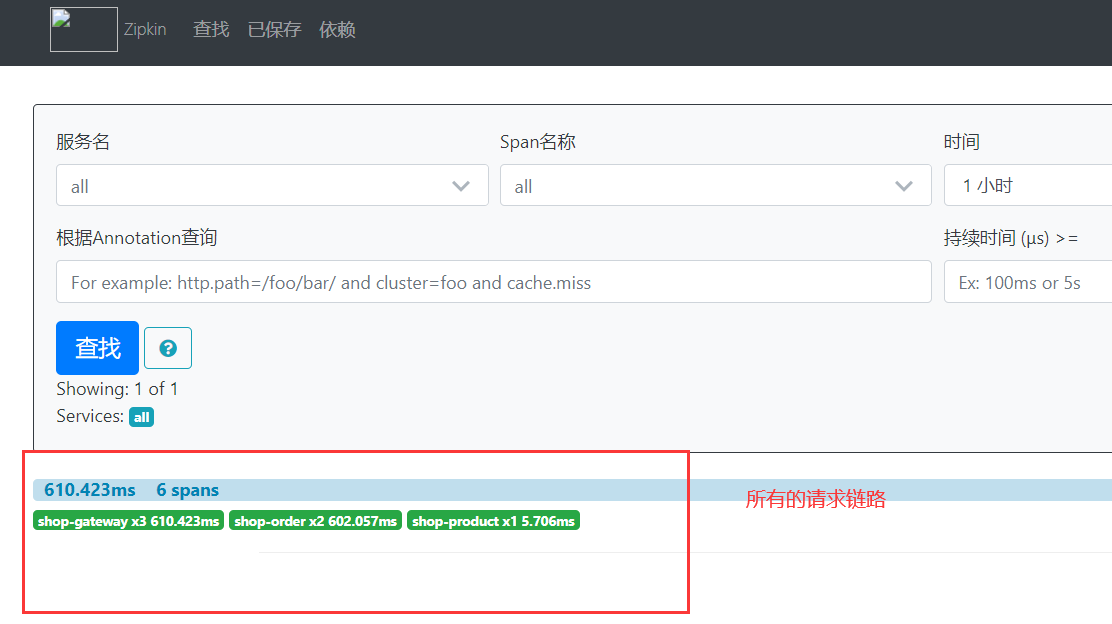
整个请求链路,响应的时间是500多毫秒。 是哪台服务器出现故障。 可以通过sleuth产生的日志进行查看,自己计算时间戳来查看。 这种方案十分麻烦。
我们通过zipkin收集sleuth产生的日志 并以图形化展示。
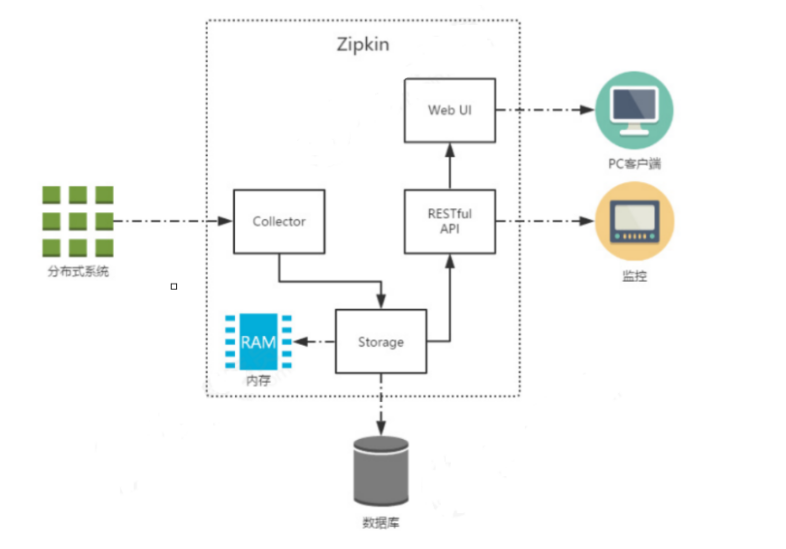
2. zipkin
作用: 收集微服务上sleuth产生的日志 并以图形化的模式来展示给客户。
zipkin有服务端【服务器】和客户端【微服务】
2.1 运行zipkin服务端
java -jar zipkin-server-2.12.9-exec.jar

微服务接入zipkin
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
在相应微服务上接入zipkin
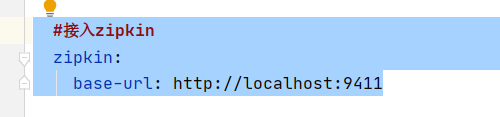
使用配置—做微服务的配置管理
sleuth+zipkin 完成链路追踪—定位错误







![面向OLAP的列式存储DBMS-12-[ClickHouse]的管理与运维](https://img-blog.csdnimg.cn/3ef2a3e2094d42bbb946dd8863f70768.png)