动动发财的小手,点个赞吧!
NLP 中结合结构化和非结构化知识的研究概况
自 2012 年谷歌推出知识图谱 (KG) 以来,知识图谱 (KGs) 在学术界和工业界都引起了广泛关注 (Singhal, 2012)。作为实体之间语义关系的表示,知识图谱已被证明与自然语言处理(NLP)特别相关,并且在最近几年迅速流行起来,这一趋势似乎正在加速。鉴于该领域的研究工作越来越多,NLP 研究界已经对几种与 KG 相关的方法进行了调查。然而,迄今为止,仍缺乏对既定主题进行分类并审查各个研究流的成熟度的综合研究。为了缩小这一差距,我们系统地分析了 NLP 中关于知识图谱的文献中的 507 篇论文。因此,本文[1]对研究前景进行了结构化概述,提供了任务分类,总结了发现,并强调了未来工作的方向。
什么是自然语言处理?
自然语言处理 (NLP) 是语言学、计算机科学和人工智能的一个子领域,关注计算机与人类语言之间的交互,特别是如何对计算机进行编程以处理和分析大量自然语言数据。
什么是知识图?
KGs 已经成为一种以机器可读格式语义表示真实世界实体知识的方法。大多数作品隐含地采用了知识图谱的广义定义,将它们理解为“旨在积累和传达现实世界知识的数据图,其节点代表感兴趣的实体,其边代表这些实体之间的关系”。
为什么我们在 NLP 中使用知识图谱?
底层范式是结构化和非结构化知识的结合可以使各种 NLP 任务受益。例如,可以将知识图谱中的结构化知识注入语言模型中发现的上下文知识中,从而提高下游任务的性能(Colon-Hernandez 等人,2021)。此外,鉴于当前关于大型语言模型(例如 ChatGPT)的公开讨论,我们可能会使用 KG 来验证并在必要时纠正生成模型的幻觉和错误陈述。此外,随着 KG 的重要性日益增加,从非结构化文本构建新的 KG 的努力也在不断扩大。
NLP 中如何使用知识图谱?
研究格局的特点
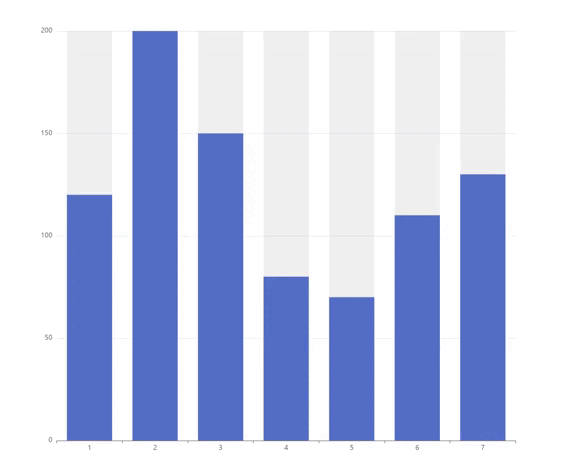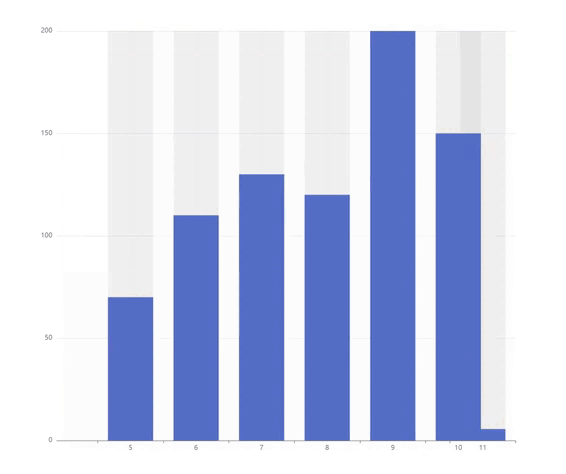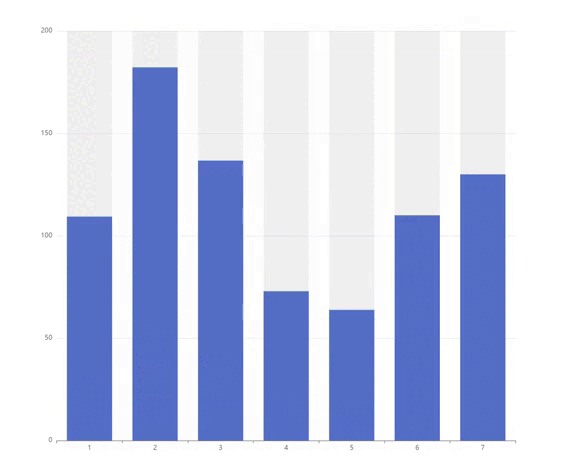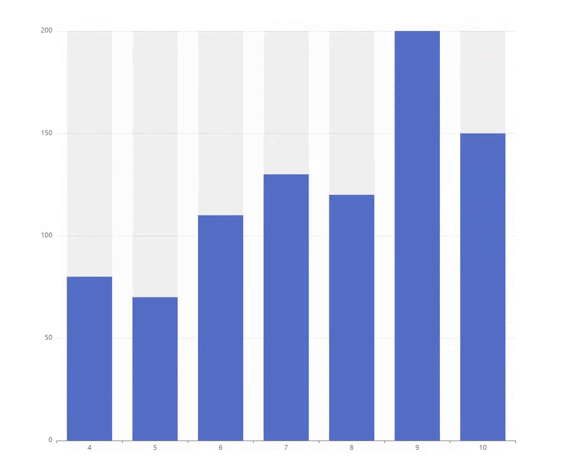
下图显示了十年观察期内的出版物分布情况。
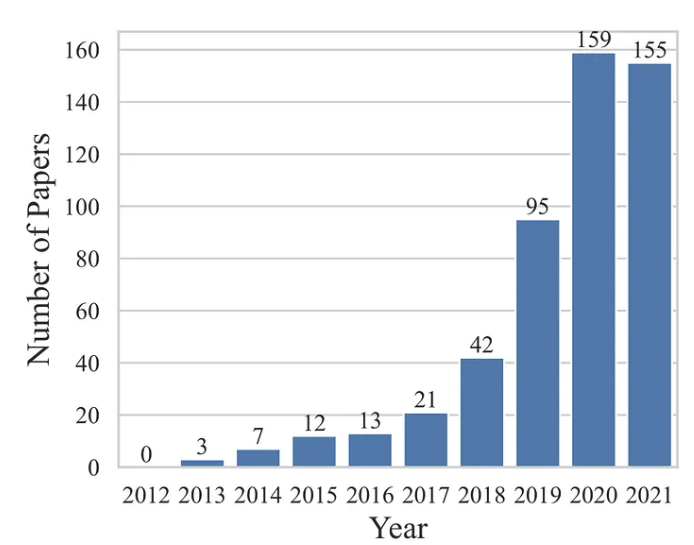
虽然第一批出版物出现在 2013 年,但年度出版物在 2013 年至 2016 年间增长缓慢。从 2017 年开始,出版物数量几乎每年翻一番。由于这些年研究兴趣的显着增加,超过 90% 的出版物都来自这五年。尽管增长趋势似乎在 2021 年停止,但这很可能是由于数据导出发生在 2022 年的第一周,遗漏了许多 2021 年的研究,这些研究在 2022 年晚些时候被纳入数据库。尽管如此,趋势清楚地表明KG 越来越受到 NLP 研究界的关注。
此外,我们观察到研究文献中探索的领域数量与年度论文数量同步快速增长。在下图中,显示了十个最常用的域。
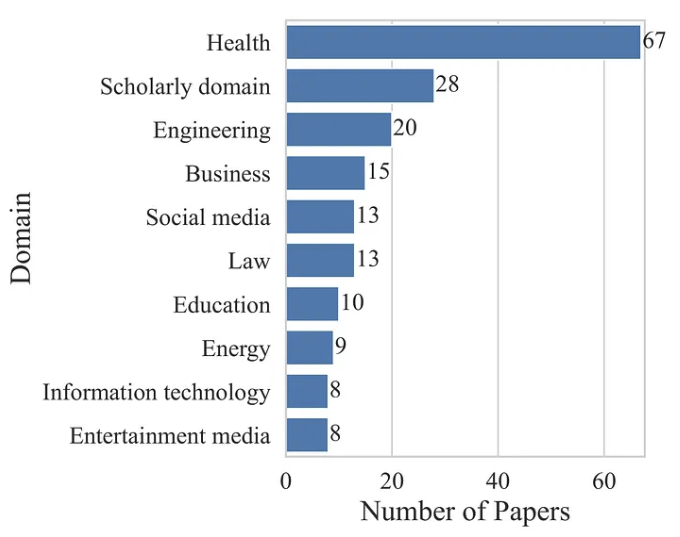
令人惊讶的是,健康是迄今为止最突出的领域。后者出现的频率是排名第二的学术领域的两倍多。其他受欢迎的领域是工程、商业、社交媒体或法律。鉴于领域的多样性,很明显 KGs 自然适用于许多不同的环境。
研究文献中的任务
基于 NLP 知识图谱文献中确定的任务,我们开发了如下所示的实证分类法。
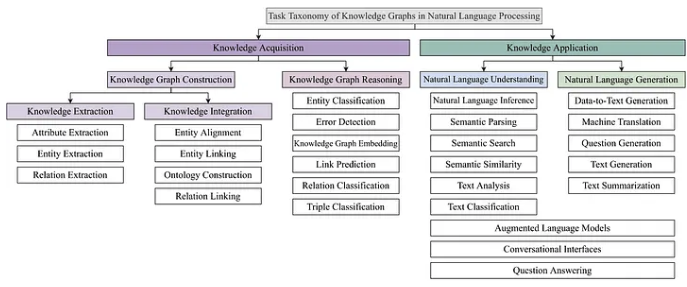
两个顶级类别包括知识获取和知识应用。知识获取包含 NLP 任务,从非结构化文本构建知识图谱(知识图谱构建)或对已构建的知识图谱进行推理(知识图谱推理)。 KG 构建任务进一步分为两个子类:知识提取,用于用实体、关系或属性填充 KG,以及知识集成,用于更新 KG。知识应用是第二个顶级概念,包含常见的 NLP 任务,这些任务通过 KG 的结构化知识得到增强。
知识图谱构建
实体提取任务是构建知识图谱的起点,用于从非结构化文本中提取真实世界的实体。一旦相关实体被挑选出来,它们之间的关系和交互就会通过关系抽取的任务被发现。许多论文同时使用实体抽取和关系抽取来构建新的知识图谱,例如,用于新闻事件或学术研究。实体链接是将某些文本中识别的实体链接到知识图谱中已经存在的实体的任务。由于同义或相似的实体经常存在于不同的知识图谱或不同的语言中,因此可以执行实体对齐以减少未来任务中的冗余和重复。提出 KGs 的规则和方案,即它们在其中呈现的知识的结构和格式,是通过本体构建的任务完成的。
知识图谱推理
一旦构建,知识图谱就包含结构化的世界知识,可用于通过对它们进行推理来推断新知识。因此,对实体进行分类的任务称为实体分类,而链接预测是推断现有知识图谱中实体之间缺失链接的任务,通常通过对实体进行排序作为查询的可能答案来执行。知识图嵌入技术用于创建图的密集向量表示,以便它们随后可用于下游机器学习任务。
知识应用
现有的知识图谱可用于多种流行的 NLP 任务。在这里,我们概述了最受欢迎的。问答 (QA) 被发现是使用知识图谱最常见的 NLP 任务。此任务通常分为文本 QA 和知识库问答 (KBQA)。文本 QA 从非结构化文档中获取答案,而 KBQA 从预定义的知识库中获取答案。 KBQA 自然地与 KGs 联系在一起,而文本 QA 也可以通过使用 KGs 作为回答问题时的常识性知识来源来实现。这种方法之所以受欢迎,不仅因为它有助于生成答案,还因为它使答案更易于解释。语义搜索是指“有意义的搜索”,其目标不仅仅是搜索字面匹配,还包括了解搜索意图和查询上下文。此标签表示使用知识图谱进行搜索、推荐和分析的研究。示例是称为 ConceptNet 的日常概念的大型语义网络和学术交流和关系的 KG,其中包括 Microsoft Academic Graph。对话界面构成了另一个 NLP 领域,可以从知识图谱中包含的世界知识中获益。我们可以利用知识图谱中的知识来生成会话代理的响应,这些响应在给定的上下文中提供的信息更丰富、更合适。
自然语言生成 (NLG) 是 NLP 和计算语言学的一个子领域,它与从头开始生成自然语言输出的模型有关。 KG 在此子领域中用于从 KG 生成自然语言文本、生成问答对、图像字幕的多模式任务或低资源设置中的数据增强。文本分析结合了各种用于处理和理解文本数据的分析 NLP 技术和方法。示例性任务是情绪检测、主题建模或词义消歧。增强语言模型是大型预训练语言模型 (PLM) 的组合,例如 BERT(Devlin 等人,2019 年)和 GPT(Radford 等人,2018 年)与知识图谱中包含的知识。由于 PLM 从大量非结构化训练数据中获取知识,因此将它们与结构化知识相结合的研究趋势正在兴起。来自知识图谱的知识可以通过输入、架构、输出或它们的某种组合被注入语言模型。
在 NLP 中使用知识图的热门任务
下图显示了 NLP 中使用知识图谱最流行的任务。
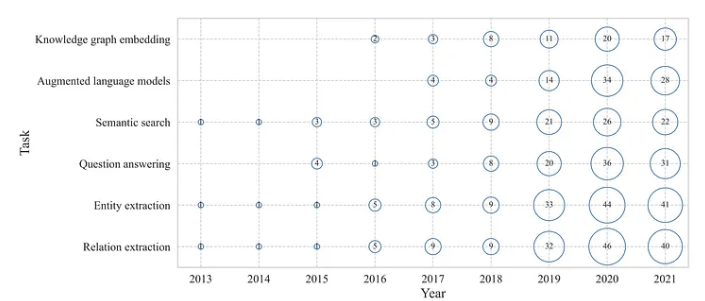
我们可以观察到,诸如关系抽取或语义搜索之类的任务已经存在了一段时间,并继续稳步增长。在我们的研究中,我们使用这个作为一个指标来得出关系提取或语义搜索等任务已经相当成熟的结论。相比之下,增强语言模型和知识图嵌入任务仍然可以被认为是相对不成熟的。这可能是因为这些任务还相对年轻且研究较少。上图显示,这两项任务从 2018 年开始研究量急剧增加,并引起了广泛关注。
总结
近年来,KGs 在 NLP 研究中的地位日益突出。自 2013 年首次发表以来,全世界的研究人员越来越关注从 NLP 的角度研究知识图谱,尤其是在过去的五年中。为了概述这个成熟的研究领域,我们对 KGs 在 NLP 中的使用进行了多方面的调查。我们的研究结果表明,NLP 中有关知识图谱的大量任务已在各个领域进行了研究。关于使用实体抽取和关系抽取构建 KG 的论文占所有作品的大部分。 QA 和语义搜索等应用 NLP 任务也有强大的研究社区。近年来最新兴的主题是增强语言模型、QA 和 KG 嵌入。
一些概述的任务仍然局限于研究界,而其他任务已经在许多现实生活中找到了实际应用。我们观察到 KG 构建任务和对 KG 的语义搜索是应用最广泛的任务。在 NLP 任务中,QA 和对话界面已被许多现实生活领域采用,通常以数字助理的形式出现。 KG 嵌入和增强语言模型等任务仍处于研究阶段,在现实场景中缺乏广泛的实际应用。我们预计,随着增强语言模型和 KG 嵌入的研究领域的成熟,将针对这些任务研究更多的方法和工具。
Reference
Source: https://towardsdatascience.com/a-decade-of-knowledge-graphs-in-natural-language-processing-5fdb15abc2b3
本文由 mdnice 多平台发布