储存
GridFS机制
- GridFS:将大文件分隔成多个小文档存放,这样我们能够有效的保存大文档,而且解决了BSON对象有限制的问题;
- 通过两个集合实现:两个集合分别存储存储实际数据和存储文件的元数据:
- 元数据文件:记录包括文档的id、长度、分块大小(每块默认大小为256k)、数据文件的md5值等;
- 数据文件:每一块作为一个单独的文档来存储;
实现介绍
- GridFS会将两个集合放在一个普通的buket中,并且这两个集合使用buket的名字作为前缀。默认使用fs命名的buket存放两个文件集合。元数据集合fs.files ,数据文件fs.chunks;
-
- MongoDB为了提高检索速度 MongoDB为GridFS的两个集合建立了索引。fs.files集合使用是filename与uploadDate字段作为唯一、复合索引。fs.chunk集合使用的是files_id与n字段作为唯一、复合索引。
- 实现方式:先保存数据文件,再构建元数据文件;
- 上传文件过程中是先把文件数据保存到fs.chunks,最后再把文件信息保存到fs.files中,所以如果在上传文件过程中失败,有可能在fs.chunks中出现垃圾数据。这些垃圾数据可以定期清理掉。
- 如果文件大于chunksize,则把文件分割成多个chunk,再把这些chunk保存到fs.chunks中,最后再把文件信息存入到fs.files中。
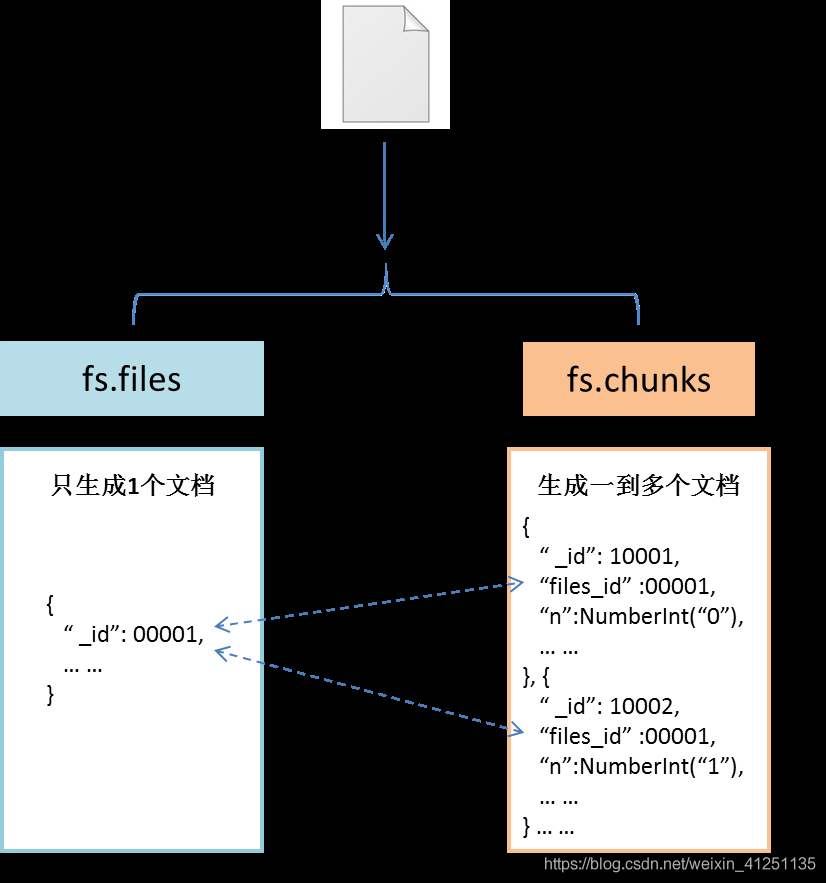
fs.file
-

- _id:当前文档id(即chuck集合的files_id)
fs.chuck
-

- n:为片位移(初始为0)
- id:当前文档Object_id
- file_id:父fs文档的id
- data:数据域
文件保存
组织形式
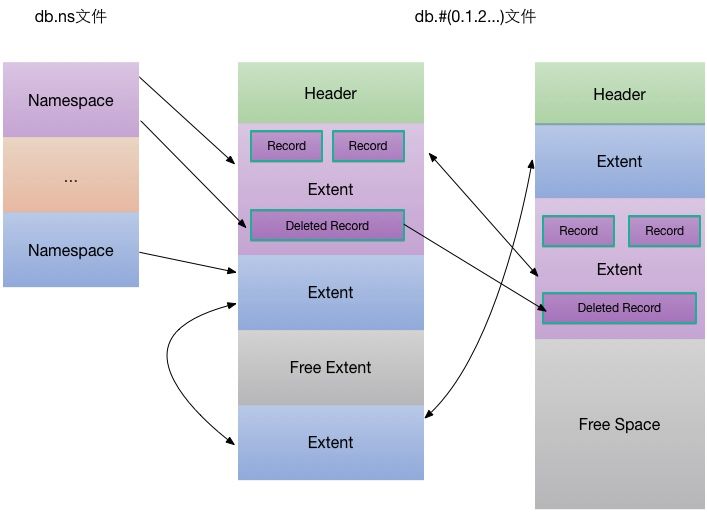
文档数据库最重要的是快速定位文档,包括:找到集合中文档的初始位置、找到集合中对应的文档,为此MongoDB通过命名空间的概念快速定位集合
- namespace(命名空间):数据库名.集合名;
- MongoDB的命名空间可以快速定位集合中的文档可能的位置;保存在mydb.ns;
- ns文件通过hash表保存、通过线性探测解决冲突;
- 每个节点大小为628Bytes,节点有三部分组成:hashcode、key(命名空间)和value(节点元数据)
- **节点元数据:记录了头尾文档位置(DiskLoc:数据文件编号和位偏移);**数据文件使用mmap映射到内存空间进行管理;
- 数据文件:
- 每个数据文件包含一个固定长度头部DataFileHeader;
- 记录数据文件版本、文件大小、未使用空间位置及长度、空闲extent链表起始及结束位置。extent被回收时,就会放到数据文件对应的空闲extent链表里。
- event:
- 每个数据文件被划分成多个extent,同一个namespace的所有extent之间以双向链表形式组织。
- 每个extent包含多个Record(对应mongodb的document),同一个extent下的所有record以双向链表形式组织。
总结
- 数据文件的分配:类似操作系统的分页系统的分配方式:
- 数据文件就像是应用的内存,extent就是块(操作系统是物理分块、逻辑分页实现分页存储的)
- 为了避免数据文件碎片化,MongoDB使用激进的预分配策略;
- 每个extent大小固定,可以保存一系列的文档数据;
- 操作系统中:也大小一致,页内分配数据;
- 通过位偏移计算event位置;
- 操作系统:通过页表的地址变换计算位置
- 通过空闲分区表记录空闲分区
- 数据文件就像是应用的内存,extent就是块(操作系统是物理分块、逻辑分页实现分页存储的)
- extent内部:是动态分区分配(即文档/记录大小不一致)
- 有足够的内存直接在event内分配;否则将申请新的固定分区分配的的新event;
- 通过空闲分区表记录可用的分区,通过最佳分配进行分配。(所以会有很大可能产生碎片)
- 当删除很多时,可能产生很多不能重复利用的"存储碎片",从而导致存储空间大量浪费;
- 操作系统通过紧凑的方式进行内存压缩回收,
- MongoDB通过对集合进行compact来整理存储碎片。
- 当进行更新时:
- 更新的文档比原来小,可以直接复用现有的空间(原地更新);多余的空间如果足够多,会将剩余空间插入到DeletedRecord链表;
- 更新的文档比原来大,更新相当于删除 + 新写入;
- namespace:快速定位集合的文档,加上索引将快速查找集合指定文档;如果没有索引将需要遍历集合所有记录;