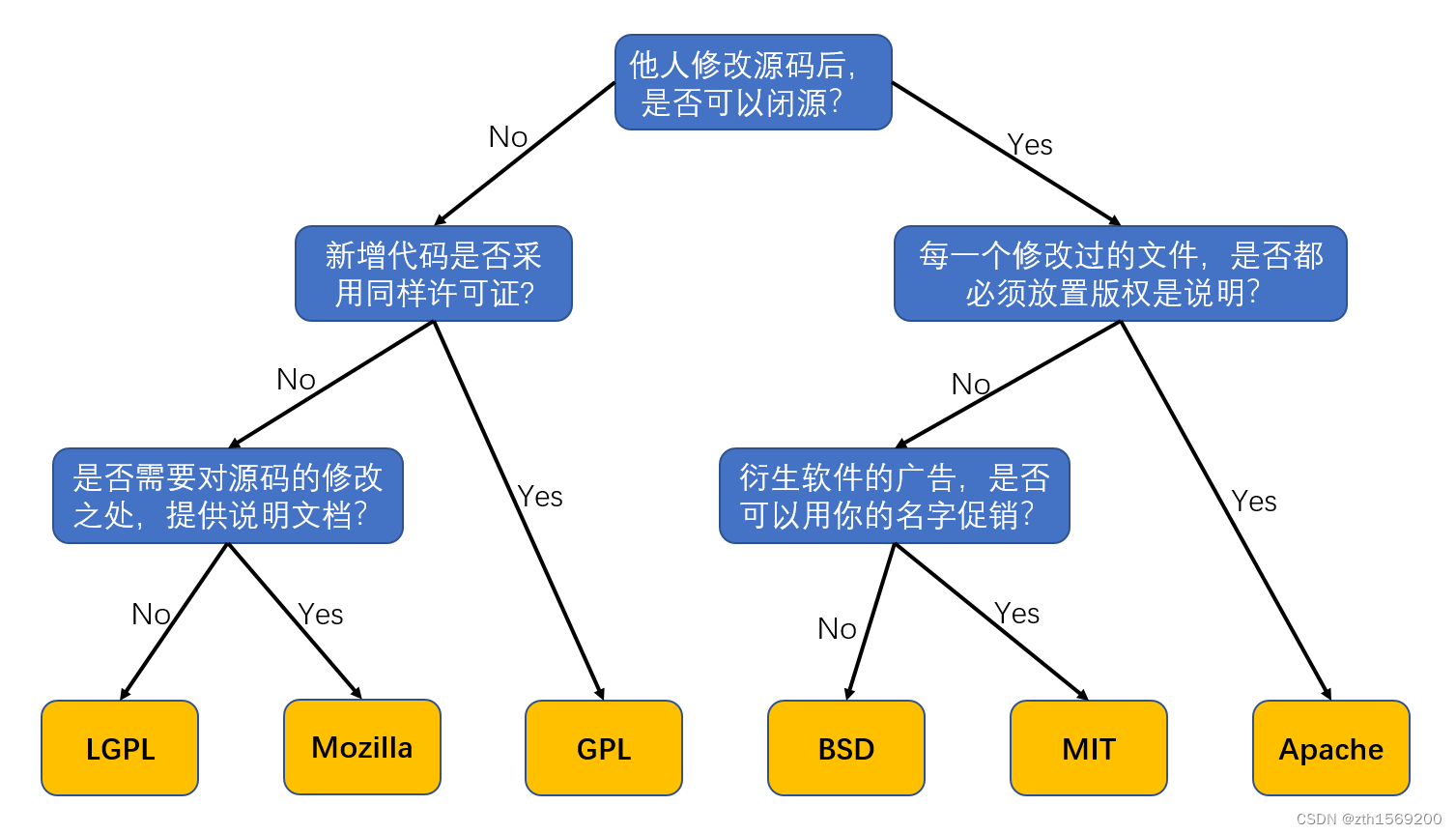
BBR算法
简述
bbr算法为google在2016年提出,用于改善tcp的性能,提升稳定性,降低延迟,更好地应对网络损伤。在整个算法调节周期中,bbr算法都在尽力维持最大bw和最小rtt。
对比传统的tcp算法
-
传统算法不能区分是拥塞导致的丢包还是错误丢包,降低一半速率,浪费网络带宽
-
传统算法会使得缓冲区膨胀,导致拥塞,进而导致rtt上升。
-
改进传统的慢启动算法,增加起始cwnd,以指数增加cwnd上升速度
数据计算
-
BW = delivered(应答了多少数据)/interval_us (应答 delivered 所用的时间)
-
pacing rate() = G(当前的增益系数) * BW
-
pacing rate 规定 cwnd 指示的窗口数据的数据包之间以多大的时间间隔发送出去
-
cwnd = BDP(当前最大管道容量)
-
BDP = max_bw * min_rtt * G
状态迁移
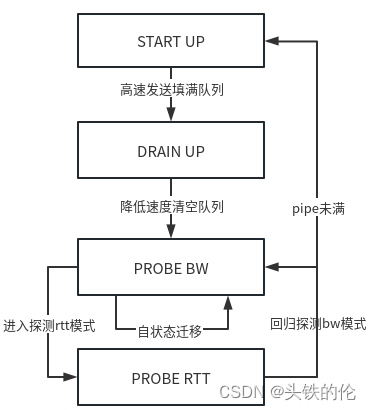
BBR初始状态为STARTUP,这一状态下迅速增加其发送速率以填满整个网络、网卡、缓存。当它估计管道已满时,它会进入DRAIN UP状态降低发送速度,快速的把缓存的数据发送完毕。drain up状态后,由于网络已经进行较大的数据收发,速率采样(rate sample)样本相对充足,BBR流进入ROBE_BW和PROBE_RTT。长声明周期的BBR流的绝大多数时间都在(重复)在PROBE_BW中,完全探测并利用管道的带宽以一种公平的方式,使用一个小的、有界的队列。如果流量持续发送整个min_rtt窗口,并且没有看到这一周期下的rtt数值<= min_rtt(近10s),然后它短暂地进入PROBE_RTT以便重新探测路径的双向传播延迟(min_rtt)。退出PROBE_RTT时,如果我们估计我们达到了管道的bw上限,然后我们进入PROBE_bw;否则,我们进入STARTUP以尝试填充管道。
状态介绍
(1)STARTUP: 当连接建立时,BBR初始状态为START UP,指数增加发送速率,目的也是尽可能快的占满管道,经过三次发现投递率不再增长,说明管道被填满,开始占用buffer它进入drain up阶段(事实上此时占的是三倍带宽*延迟)
(2)DRAIN UP:这一阶段会指数降低发送速率,(相当于是startup的逆过程)将多占的2倍buffer慢慢排空
(3)PROBE BW:在drain up后,进入probe bw状态,tcp针对速率的采样信息有了一定基础,BBR改变发送速率进行带宽探测:先在一个RTT时间内增加发送速率探测最大带宽,如果RTT没有变化,后减小发送速率排空前一个RTT多发出来地包,后面6个周期使用更新后的估计带宽发包.(gain系数为:1.25 0.75 1 1 1 1)
(4)PROBE RTT:还有一个阶段是延迟探测阶段:BBR每过10秒,如果估计延迟不变,就进入延迟探测阶段,为了探测最小延迟,BBR在这段时间内发送窗口固定为4个包,即几乎不发包,占整个过程2%的时间。
START UP阶段
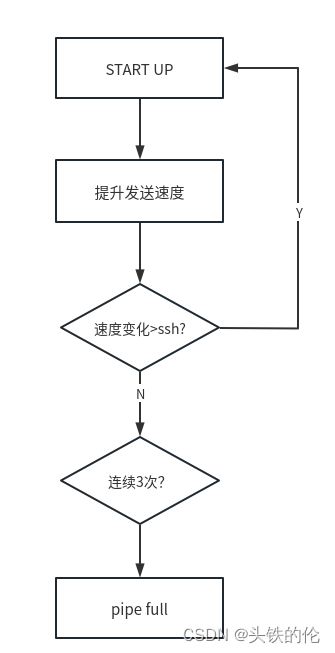
在startup阶段,发送速率会不断商上升,而后根据反馈回来的rate sample测算这一阶段速度是否相比上一次提升了25%,如果提升大于25%则认为pipe还未填满。如果小于25%,且连续三次,则认为当前pipe已满,可以进入drain up状态。
速率控制
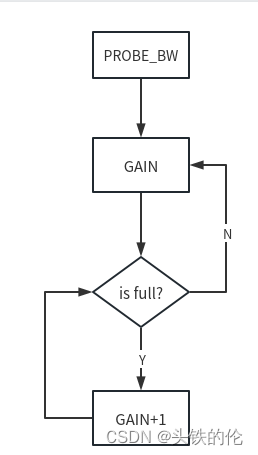
PROBE_BW状态下,速率gain系数为:1.25 0.75 1 1 1 1,在此状态下以尝试增加增加带宽开启,如果增加后发现rtt>min_rtt则判定当前发送速度超出网络承载能力了,进入下一个增益0.75下,降低速度如果rtt<=min_rtt,则判定速度降低达到预期,而后进入下一个增益1,维持4个周期。
PROBE_BW主要是为了解决两个问题:
网络环境波动
当BDP降低时,bbr会感知到rtt增加同时会降低发送速率增益直到rtt恢复预期。当BDP升高时,由于min_rtt持续稳定bbr会周期的增加发送速率尝试提升发送速度。
均衡调配
当多个网络请求共存时,由于网络整体发送的数据量上升导致拥塞,bbr会感知到rtt增加同时会降低发送速率直到rtt恢复预期。
BBR 2.0
Google也在持续优化BBR算法,在2018年 公布的BBR 2.0研究进展中就包含了:
-
提⾼与基于丢包的拥塞算法(Reno/Cubic)的共存能⼒。降低BBR算法的抢占性,提⾼不同算法之间的 公平性。
-
减⼩排队丢包和排队时延的情况。这⾥主要根据丢包率和标记ECN⽐例来设置inflight的两个⻔限值, inflight_hi和inflight_lo。
-
加快min_rtt的收敛性,增加是将进⼊Probe_RTT模式的频率由10s设置到2.5s。
-
减⼩Probe_RTT模式带来的带宽的波动。