(一) 文件的编码
1. 编码
编码是一种规则集合,记录了内容和二进制间进行相互转换的逻辑
编码有许多种,最常用的是utf-8
2. 使用编码的原因
计算机只能识别二进制数,因此要将文件的内容翻译为二进制数,才能保存进计算机内
同时也需要编码,将计算机保存的二进制数,反向编译回可识别的内容
(二) 文件的读取
1. 文件的基本操作步骤
打开文件
读写文件
关闭文件
! 可以只读,不写
2. 文件的基本操作函数
| 编号 | 关键字 | 使用方法 | 作用 |
| 1 | open | 文件对象 = open(file,mode,encoding) | 打开文件获得指定文件对象 |
| 2 | read | 文件对象.read(num) | 读取指定长度字节 不指定num读取文件全部 |
| 3 | readline | 文件对象.readline() | 读取一行 |
| 4 | readlines | 文件对象.readline() | 读取全部行,得到列表 |
| 5 | for | for line in 文件对象 | for循环文件行,一次循环得到一行数据 |
| 6 | close | 文件对象.close() | 关闭文件对象 |
| 7 | with open | with open() as f | 通过with open语法打开文件,可以自动关闭 |
! 读取文件后,要用进行关闭,否则文件一直被占用
完整的语法格式为:
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)参数说明:
- file: 必需,文件路径(相对或者绝对路径)。
- mode: 可选,文件打开模式
- buffering: 设置缓冲
- encoding: 一般使用utf8
- errors: 报错级别
- newline: 区分换行符
- closefd: 传入的file参数类型
- opener: 设置自定义开启器,开启器的返回值必须是一个打开的文件描述符。
****注意:mode 参数有:
| 模式 | 描述 |
|---|---|
| t | 文本模式 (默认)。 |
| x | 写模式,新建一个文件,如果该文件已存在则会报错。 |
| b | 二进制模式。 |
| + | 打开一个文件进行更新(可读可写)。 |
| U | 通用换行模式(Python 3 不支持)。 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
默认为文本模式,如果要以二进制模式打开,加上 b 。
file 对象
file 对象使用 open 函数来创建,下表列出了 file 对象常用的函数:
| 序号 | 方法及描述 |
|---|---|
| 1 | file.close() 关闭文件。关闭后文件不能再进行读写操作。 |
| 2 | file.flush() 刷新文件内部缓冲,直接把内部缓冲区的数据立刻写入文件, 而不是被动的等待输出缓冲区写入。 |
| 3 | file.fileno() 返回一个整型的文件描述符(file descriptor FD 整型), 可以用在如os模块的read方法等一些底层操作上。 |
| 4 | file.isatty() 如果文件连接到一个终端设备返回 True,否则返回 False。 |
| 5 | file.next() Python 3 中的 File 对象不支持 next() 方法。 返回文件下一行。 |
| 6 | file.read([size]) 从文件读取指定的字节数,如果未给定或为负则读取所有。 |
| 7 | file.readline([size]) 读取整行,包括 "\n" 字符。 |
| 8 | file.readlines([sizeint]) 读取所有行并返回列表,若给定sizeint>0,返回总和大约为sizeint字节的行, 实际读取值可能比 sizeint 较大, 因为需要填充缓冲区。 |
| 9 | file.seek(offset[, whence]) 移动文件读取指针到指定位置 |
| 10 | file.tell() 返回文件当前位置。 |
| 11 | file.truncate([size]) 从文件的首行首字符开始截断,截断文件为 size 个字符,无 size 表示从当前位置截断;截断之后后面的所有字符被删除,其中 windows 系统下的换行代表2个字符大小。 |
| 12 | file.write(str) 将字符串写入文件,返回的是写入的字符长度。 |
| 13 | file.writelines(sequence) 向文件写入一个序列字符串列表,如果需要换行则要自己加入每行的换行符。 |
练习:word.txt文本内容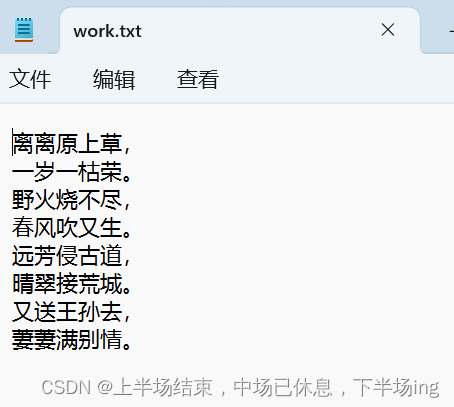
"""
演示对文件的读取
"""
# 打开文件
import time
f=open("C:/Users/cs/Desktop/work.txt","r",encoding="UTF-8") #这里我犯了一个错误,直接复制了文本的路径,发现不对,原因是斜杠的方向不一样
print(type(f))
# 读取文件 - read()
print(f"读取第3个字节的结果:{f.read(3)}")
print(f"read方法读取全部内容的结果是:{f.read()}") #当出现多个read语句时,会发现f.read()不会读取全部内容,只会读取没有被read使用过的内容,原因是文件操作会续接前的命令操作,读者不懂可以将这两个输出语句全部输出或者注释掉一个,只输出一个语句就能懂了
# 读取文件 - readLines()
lines=f.readlines() #读取文件的全部行,封装到列表里
print(f"lines对象的类型:{type(lines)}")
print(f"lines对象的内容是:{lines}") #输出为空,原因是文件前面的9 10行读取文件 ,就像指针一样,第9行指针在第3个字后面,执行第10行后,之后在最后了,所以对象内容为空的 
# 打开文件
import time
f=open("C:/Users/cs/Desktop/work.txt","r",encoding="YTF-8")
line1=f.readline()
line2=f.readline()
line3=f.readline()
print(f"第一行数据是:{line1}")
print(f"第二行数据是:{line2}")
print(f"第三行数据是:{line3}")
# for循环读取文件行
for line in f:
print(f"每一行数据是:{line}")
# 文件的关闭
f.close()
time.sleep(500000) #程序暂停执行50万秒 l 
"""
演示对文件的读取
"""
# 打开文件
import time
# with open 语法操作文件 自带关闭功能
with open("C:/Users/cs/Desktop/work.txt","r",encoding="UTF-8") as f:
for line in f:
print(f"每一行的数据是:{line}") #for 循环这两行代码运行完自动关闭了
time.sleep(500000)

对于同一个文件的操作,每一行的命令都会续接上面的代码 ,所以就出现了代码中注释的那几条解释
实例:读取文本内容的次数
文本内容为:
离离原上草,
一岁一枯荣。
野火烧不尽,
春风吹又生。
远芳侵古道,
晴翠接荒城。
又送王孙去,
萋萋满别情。
一二一
方法1:
"""
练习读取文件内容的次数
"""
# 打开文件
f=open("C:/Users/cs/Desktop/work.txt","r",encoding="UTF-8")
# 方法1:读取全部内容,同字符串count方法统计一这个字的数量
content=f.read()
count=content.count("一")
print(f"一 在文件中出现的次数为{count}")
#关闭文件
f.close()

方法2:
# 方法2:读取内容,一行一行读取
count=0 # 变量来增加次数
for line in f:
line =line.strip() #去除开头和结尾的空格以及\n换行符
words=line.split(" ")
for word in words:
if word == "一":
count+=1
print(f"一 出现的次数为:{count}")
#关闭文件
f.close()(三) 文件的写入
1. 写操作快速入门:
(1) 使用open的“w”模式进行写入
(2) 文件写入:f.write()
(3) 内容刷新:f.flush()
! 直接调用write,内容并未真正写入文件,而是积攒在程序的内存中,称为缓冲区
! 当调用flush时,文件才会真正写入文件
! 这样避免频繁的操作硬盘,导致效率下降
这里是写入不存在的文件
"""
演示文件的写入
"""
# 打开文件,不存在的文件
import time
f=open("C:/Users/cs/Desktop/text.txt","w",encoding="UTF-8")
# write写入
f.write("HelloWorld") #内容写到了内存中,需要调入flush写入硬盘
# flush刷新
f.flush()
time.sleep(60000)
#close关闭
f.close() # close方法,内置了flush的功能,也就是说 哪怕你没调用flush,但是调用了close,依旧可以写入内存这里演示写入已经存在的文件中,会自动清除原有文本中的内容,重新写入新值
"""
演示文件的写入
"""
# 打开一个存在的文件
f=open("C:/Users/cs/Desktop/text.txt","w",encoding="UTF-8")
#write写入,flush刷新
f.write("heima")
# f.flush()
time.sleep(60000)
# close关闭
f.close()2. 注意事项:
w模式,文件不存在,会创建新文件
w模式,文件存在,会清空原有内容
close方法,具有flush方法的作用
(四) 文件的追加
1. 追加写入操作的快速入门
(1) 使用open的“a”模式进行写入
(2) 文件写入:f.write()
(3) 内容刷新:f.flush()
2. 注意事项
- a模式,文件不存在,不会创建文件
- a模式,文件存在,会在最后追加写入文件
# 打开一个存在的文件 f=open("C:/Users/cs/Desktop/text.txt","a",encoding="UTF-8") #write写入,flush刷新 f.write("baima") # f.flush() time.sleep(60000) # close关闭 f.close()因为追加功能和写入功能是一样的,因此就写了一个文件存在,追加写入文件的例子