- 消息队列 场景
- 模式
- 基础架构
- 发送原理
- 异步发送
- 同步发送
- 分区
- 生产者提高吞吐量:
- 数据可靠性
- ack应答
- 数据重复
- 幂等性
- 事务
- 数据有序
- 数据乱序
- broker工作流程
- follower故障
- leader故障
- 数据查找
- 文件清除
- 高效读写
- 消费者流程
- 消费者组初始化
- 分区分配策略
- 自动提交offset
- 手动提交
- 指定位置消费
- 数据积压(消费者提高吞吐量)
Kafka:数据管道、流分析、数据集成和关键任务应用。存储、计算、分析、集成
消息队列 场景
缓存/消峰:数据量过大时,消息队列缓存数据,服务端缓慢读取
解耦:数据源、目的地不同,符合接口约束即可
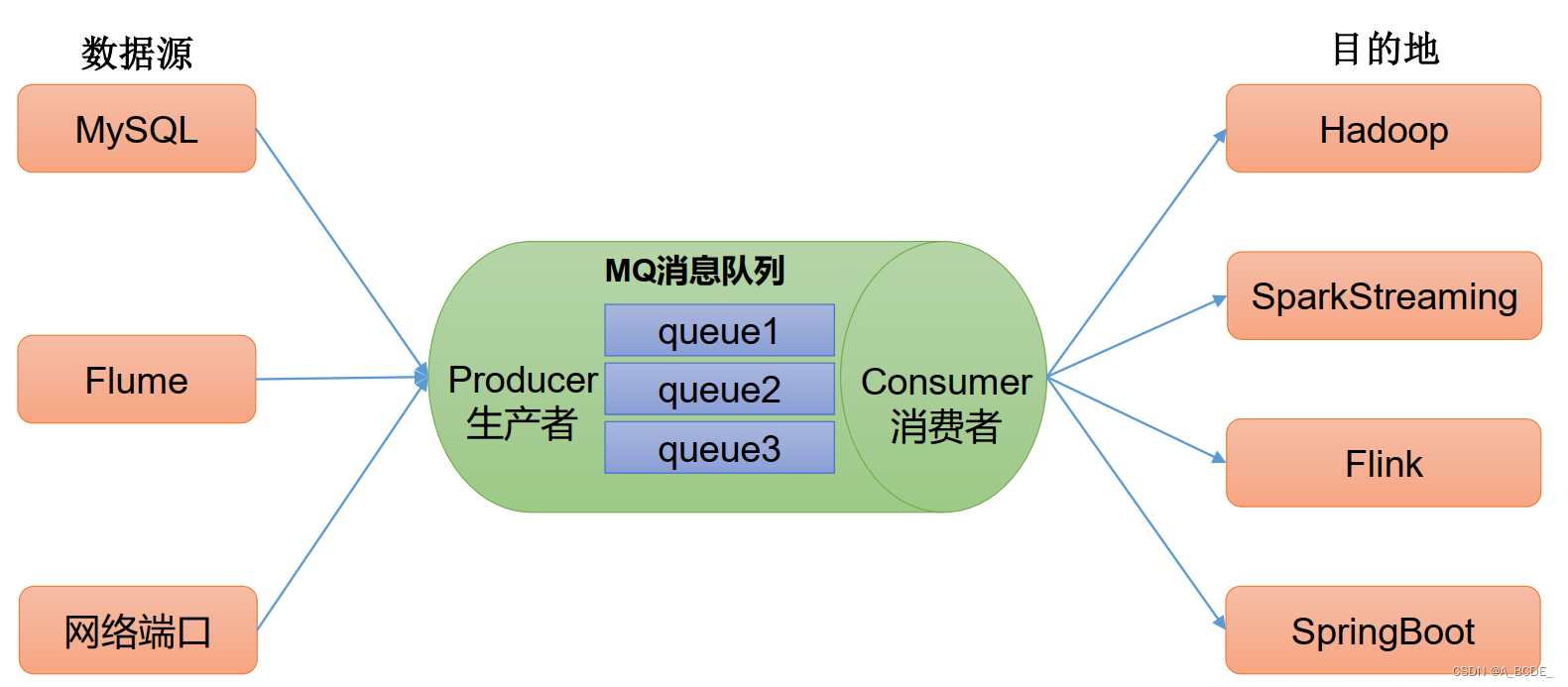
异步通信:无所谓的工作,由其他从kafka中读取完成
模式
- 点对点:一对一,消费者读取后删除
- 发布订阅模式(设计模式):多对多,消费者相互独立,消费后不删除,其他消费者可以读到数据。多个topic主题
基础架构
- 海量数据,为提高吞吐量分区,一个topic分为多个partition。一个分区的数据只能由一个消费者来消费
- 为提高可用性,为每个partition增加若干副本,partition为leader,副本为follower,生产和消费只针对leader,leader挂掉后follower推举产生新的leader
- 分区信息, leader和follower信息由zk存储,新版本可以不使用zk存储
- Consumer Group(CG):消费者组,由多个consumer组成。消费者组内每个消
费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
发送原理
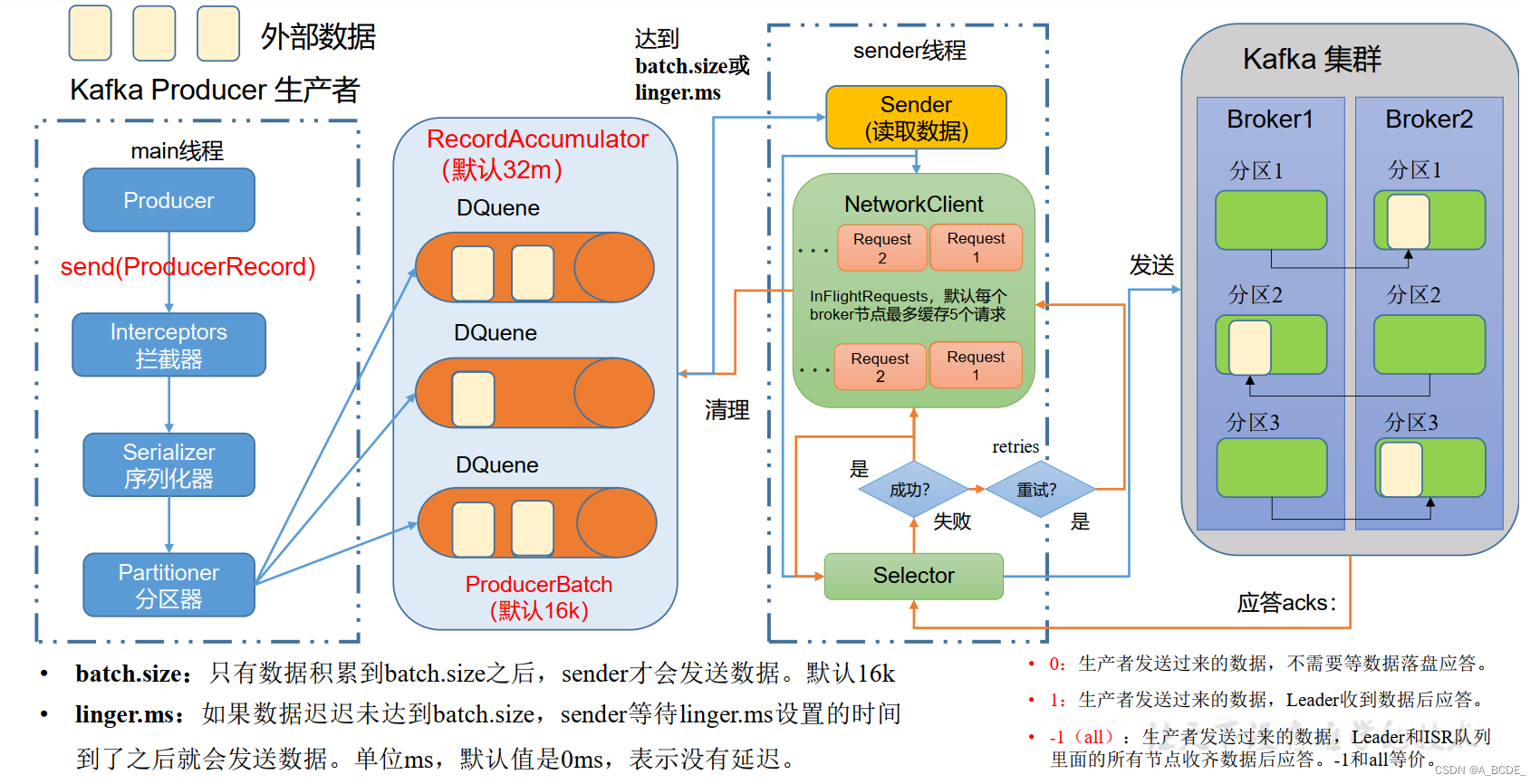
序列化器:客户指定,java自带的过重
分区器:分区器在内存中,大小32m,实际上为一个缓存队列,包含多个双端队列。一个分区一个队列,将数据发送到对应的队列中(一个数据发往多个队列)。分区器中还包含一个内存池,每一批次数据从内存池取内存插入队列,发送成功后删除数据,内存释放回内存池
sender:从分区器中读取数据发到kafka,队列中累积16k数据为一组读取发送。如果未达到16k,在达到linger.ms时间也读取发送。每个分区一个队列,读取对应分区队列的数据发送到对应分区(leader和follower)。如果分区未应答,可继续发送,最多可发送五组数据,如果仍未应答则不再发送。分区应答,回复成功,则清除sender发送的数据以及分区器队列中的数据,失败则重试(次数不限)。
异步发送:将外部数据发送到分区器中(同步发送,等上一批数据已发送到kafka集群中再继续发送)
异步发送
// 1.创建kafka生产者的配置对象
Properties properties = new Properties();
// 2.给kafka配置对象添加配置信息
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092");
// key,value序列化(必须):key.serializer,value.serializerproperties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
// 3.创建kafka生产者对象
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties);
// 4.调用send方法,发送消息
for (int i = 0; i <5; i++) {
//添加回调
kafkaProducer.send(new ProducerRecord<>("first", "atguigu" + i),new Callback(){
//该方法在Producer收到ack时调用,为异步调用
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception == null) {
//没有异常,输出信息到控制台
System.out.println("主题:" +
metadata.topic()+ "->" + "分区:" +metadata.partition());
} else {
//出现异常打印
exception.printStackTrace();
}
}
});
//延迟一会会看到数据发往不同分区
Thread.sleep(2);
}
// 5.关闭资源
kafkaProducer.close();
同步发送
// 1.创建kafka生产者的配置对象
Properties properties = new Properties();
// 2.给kafka配置对象添加配置信息
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092");
// key,value序列化(必须):key.serializer,value.serializerproperties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
// 3.创建kafka生产者对象
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties);
// 4.调用send方法,发送消息
for (int i = 0; i <5; i++) {
//异步发送默认
// kafkaProducer.send(newProducerRecord<>("first","kafka" + i));
//同步发送
kafkaProducer.send(new ProducerRecord<>("first","kafka" + i)).get();
}
// 5.关闭资源
kafkaProducer.close();
分区
- 便于合理使用存储资源,数据存储在多台Broker上。合理控制分区的任务,可以实现负载均衡的效果。
- 提高并行度,生产者可以以分区为单位发送数据;消费者可以以分区为单位进行消费数据。
有指定分区,按指定分区,没有制定分区按key,没有制定分区没有key,随机一个一直使用直到已满或已完成,再随机一个(必须和上一个随机的不同)
可自定义分区器:实现Partitioner接口
生产者提高吞吐量:
batch.size:批次大小,默认16k
linger.ms:等待时间,修改为5-100ms
compression.type:压缩snappy
RecordAccumulator:缓冲区大小,修改为64m
数据可靠性
ack应答
- 0:生产者发送过来的数据,不需要等数据落盘应答。效率最高。如果服务端挂掉则数据丢失(此时数据在内存中,或未收到),不安全
- 1:生产者发送过来的数据,Leader收到数据后应答。应答后,leader数据还未与follower同步就挂掉,则数据丢失
- -1(all):生产者发送过来的数据,Leader+follower(ISR队列)收齐数据后应答。数据可靠,若一个follower挂掉则无法收齐。
ISR队列:和Leader保持同步的Leader+follower,follower一段时间内未与leader同步数据或通信则认为follower挂掉,踢出ISR队列。
若分区副本数为1,或ISR应答最小副本数量=1,当follower挂了,则与ack=1情况相同
数据完全可靠条件:ack=-1+分区副本数>=2+ISR应答最小副本数量>=2
数据重复(ack=-1)
leader+部分follower获得数据,未收齐时leader挂掉,没有回复ack,则重新选举leader,重发数据,follower可能获得一个已获得的数据。
数据重复
最多收一次:ack=0
最少收一次:ack=-1
精确一次:
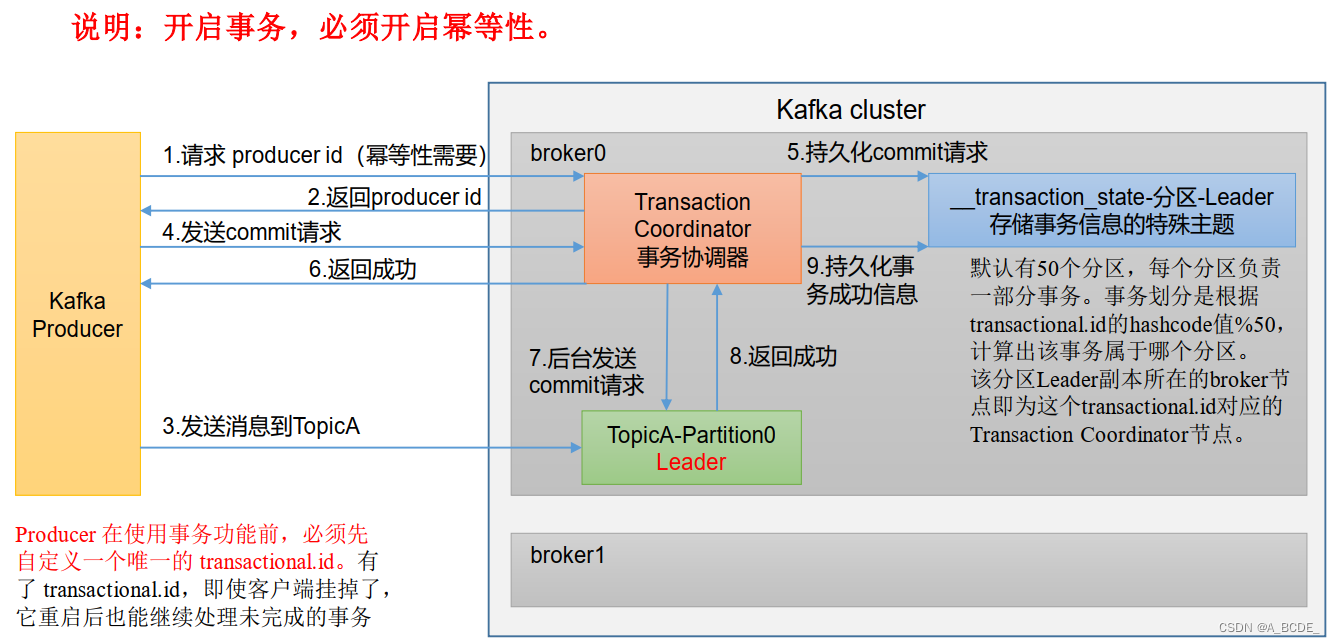
幂等性
幂等性就是指Producer不论向Broker发送多少次重复数据,Broker端都只会持久化一条,保证了不重复。
精确一次(ExactlyOnce)=幂等性+至少一次(ack=-1+分区副本数>=2+ISR最小副本数量>=2)。
重复数据的判断标准:具有<PID,Partition,SeqNumber>相同主键的消息提交时,Broker只会持久化一条。
其中PID是生产者id,kafka每重启一次,产生一个新的id;Partition表示分区号;SequenceNumber是单调自增的。
所以幂等性只能保证的是在单分区单会话内不重复。
如果重复,不会在磁盘中落盘,在内存中删掉
事务
数据有序
保证单分区内有序
可以完成多分区内有序:多个分区统一读取,排序,效率低。不如只用一个topic
数据乱序
生产者最多可接受kafka五个数据包没有应答
eg:①②正常发送,③失败,④正常,③重发
方案:
(1)未开启幂等性
max.in.flight.requests.per.connection需要设置为1。
(2)开启幂等性
max.in.flight.requests.per.connection需要设置小于等于5。
原因说明:因为在kafka1.x以后,启用幂等后,kafka服务端会缓存producer发来的最近5个request的元数据,故无论如何,都可以保证最近5个request的数据都是有序的。
①②有序,正常落盘,应到③,实际收到④,则内存中缓存④,直到收到③
broker工作流程
offset存于kafka 的topic中
broker启动向zk注册,zk存储broker、leader相关信息
zk选举leader 按照AR中的顺序,要求ISR中存活的
follower主动拉取数据,与leader同步
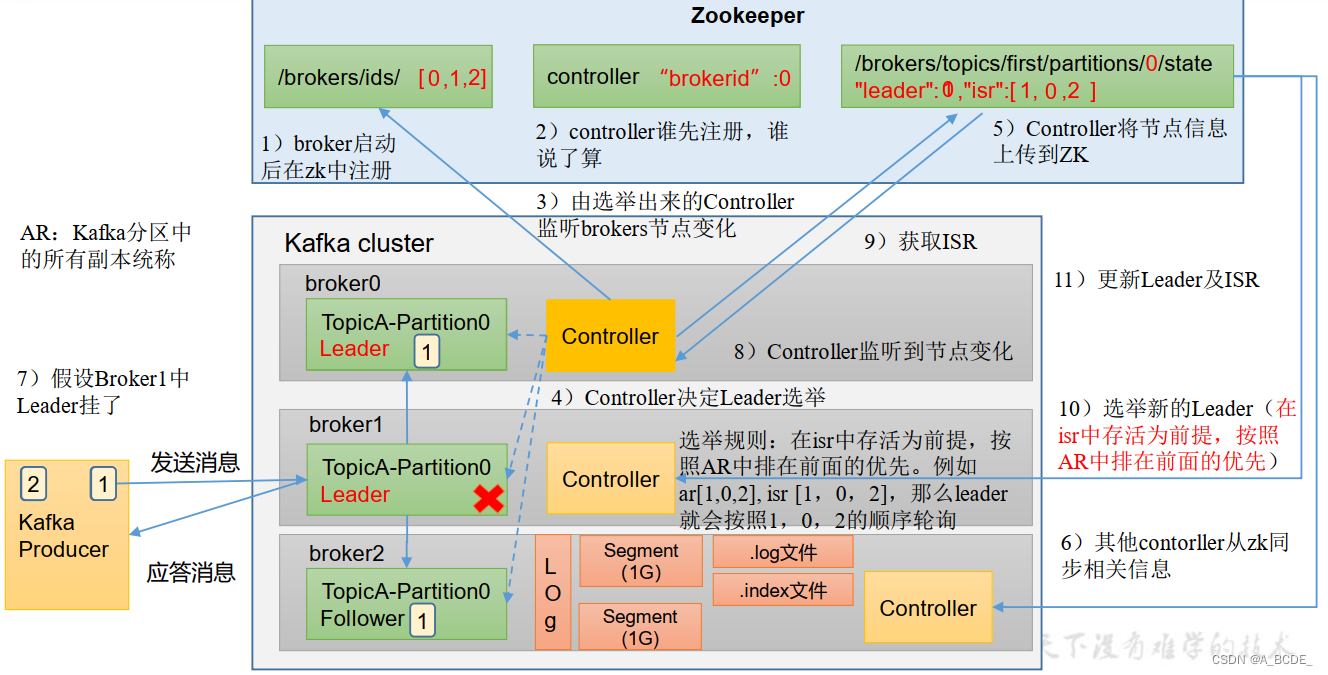
数据以log形式存放,实际分为多个segment,为segment建立索引,便于查找
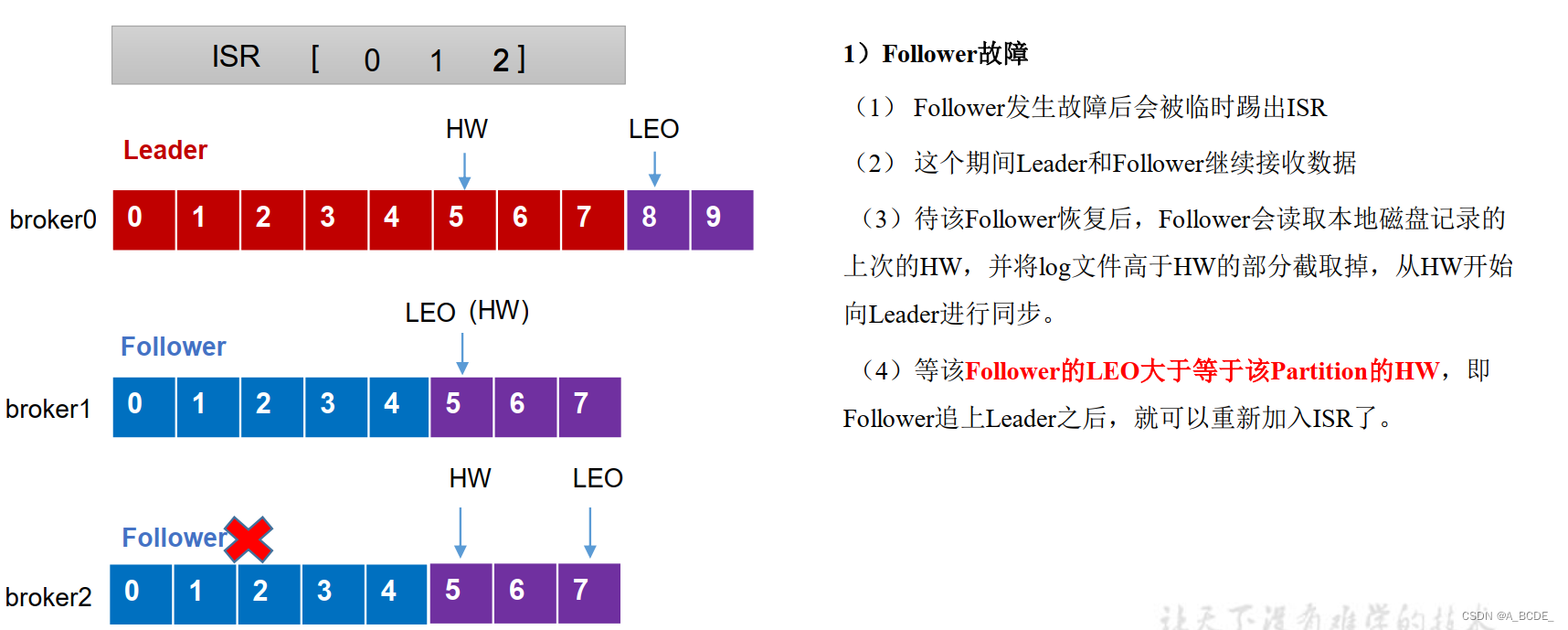
follower故障
LEO(Log End Offset):每个副本的最后一个offset,LEO其实就是最新的offset + 1。
HW(High Watermark):所有副本中最小的LEO。
消费者能见到的最大的offset = HW-1
leader故障
从ISR中选出一个新的Leader
为保证多个副本之间的数据一致性,其余的Follower会先将各自的log文件高于HW的部分截掉,然后从新的Leader同步数据。
只保证副本之间的数据一致性,并不能保证数据不丢失或者不重复。
数据查找
分区数据以log形式存储,log分片为segment,对segment建索引
数据在末尾插入到log中
index为稀疏索引,4kb数据一条索引
index文件名中有offset
根据文件名,判断使用哪个index文件
index文件名中的offset+index存储的相对offset 选择适当的log文件
根据log文件查找位置
文件清除
delete:以segment中最后文件的时间为时间戳,计算过期时间
数据过大,超出最大范围,则删除最早的segment
compact压缩:
同一个key只留最新的value,其余删掉
高效读写
- 分布式
- 稀疏索引,快速定位
- 顺序写磁盘
- 页缓存+零拷贝:不对数据进行处理,不走应用层,所以零拷贝(linux提供),效率更高。数据到kafka存储于页缓存,然后存于内存/落盘
- 16kb一个包,传输次数减少
消费者流程
消费者消费的offset,存于kafka集群,topic相关位置。如果存在zk,会导致客户端和zk频繁通信
一个消费者可以消费多个分区
一份分区只能由消费者组内的一个消费者消费
组内每个消费者负责消费不同分区
消费者组初始化
根据groupid 选择分区,所有消费者与分区的coordinator通信,coordinator选择一个消费者做leader,将相关信息反馈给消费者leader,leader制定合适的消费计划把方案发给coordinator,coordinator发给所有消费者。如果消费者挂掉或者消费时间过长,则将其消费工作Rebalance,分配给其他消费者
消费一次,1k-50m数据/一定时间内的数据为一条,一次五百条
分区分配策略
range:一个topic的全部分区按分区号排序,平均分给所有消费者,除不尽的给最前面的几个消费者。
数据倾斜:最前面的几个消费者获取更多数据,如果多个topic,则前面几个消费者总能获得更多数据,压力大
RoundRobin:所有Topic所有的partition按照hashcode排序,轮询分配partition给到各个消费者。
Sticky:全部分区乱序,其他约等于range
自动提交offset
每隔五秒,自动提交
重复消费:已消费,未提交,消费者挂了,则重启后,从旧offset处消费
手动提交
同步/异步提交:消费数据&提交offset
漏消费:已消费,offset已提交,数据未落盘,消费者挂了,则数据丢失。重启后从offset位置向后消费
避免数据重复/丢失:生产端,消费者应支持事务
指定位置消费
指定offset:消费者中设置offset
指定时间:时间转为offset
数据积压(消费者提高吞吐量)
增加分区和消费者
消费者拉取数据50m,500条,修改参数