目录
1. modules() 和 named_modules()
2. children() 和 named_children()
3. parameters() 和 named_parameters()
4. buffers() 和 named_buffers()
Module类内置了很多函数,其中本文主要介绍常用的属性访问函数,包括: modules(), named_modules(), buffers(), named_buffers(), children(), named_children(), parameters(), named_parameters()。官方文档 Module — PyTorch 1.7.0 documentation
示例代码均使用如下:
class Net(nn.Module):
def __init__(self, num_class=10):
super().__init__()
self.features = nn.Sequential(
nn.Conv2d(in_channels=6, out_channels=9, kernel_size=3),
nn.BatchNorm2d(9),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.classifier = nn.Sequential(
nn.Linear(9 * 8 * 8, 128),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(128, num_class)
)
def forward(self, x):
output = self.features(x)
output = output.view(output.size()[0], -1)
output = self.classifier(output)
return output
model = Net()1. modules() 和 named_modules()
【相同点】均返回Module类中的所有子层(子类),返回类型为生成器(可以遍历访问)
【不同点】modules()仅返回子类,named_modules()返回子类和对应的名字

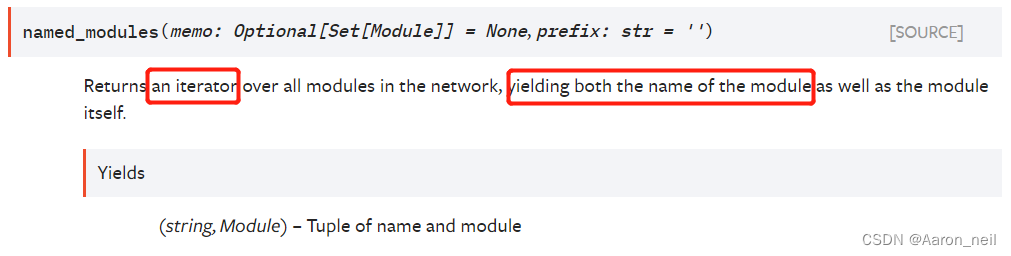
示例1:model.modules() 会遍历并返回模型中所有的nn.Module子类对象,包括model自身(因为model也是继承Module), self.features, self.classifier(Sequential继承Module类),以及Conv,MaxPool,ReLU, Linear, BN, Dropout等都是nn.Module子类。
for item in model.modules():
print(item)
#Net(
# (features): Sequential(
# (0): Conv2d(6, 9, kernel_size=(3, 3), stride=(1, 1))
# (1): BatchNorm2d(9, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (2): ReLU(inplace=True)
# (3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
# )
# (classifier): Sequential(
# (0): Linear(in_features=576, out_features=128, bias=True)
# (1): ReLU(inplace=True)
# (2): Dropout(p=0.5, inplace=False)
# (3): Linear(in_features=128, out_features=10, bias=True)
# )
# )
# Sequential(
# (0): Conv2d(6, 9, kernel_size=(3, 3), stride=(1, 1))
# (1): BatchNorm2d(9, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (2): ReLU(inplace=True)
# (3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
# )
# Conv2d(6, 9, kernel_size=(3, 3), stride=(1, 1))
# BatchNorm2d(9, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# ReLU(inplace=True)
# MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
# Sequential(
# (0): Linear(in_features=576, out_features=128, bias=True)
# (1): ReLU(inplace=True)
# (2): Dropout(p=0.5, inplace=False)
# (3): Linear(in_features=128, out_features=10, bias=True)
# )
# Linear(in_features=576, out_features=128, bias=True)
# ReLU(inplace=True)
# Dropout(p=0.5, inplace=False)
# Linear(in_features=128, out_features=10, bias=True)示例2:model.named_modules() 会遍历并返回所有的nn.Module子类对象和名字。除了自定义的一些名字外,如features, classifier等,其他层都采用PyTorch的默认命名方式
for item in model.named_modules():
print(item)
#('', Net(
# (features): Sequential(
# (0): Conv2d(6, 9, kernel_size=(3, 3), stride=(1, 1))
# (1): BatchNorm2d(9, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (2): ReLU(inplace=True)
# (3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
# )
# (classifier): Sequential(
# (0): Linear(in_features=576, out_features=128, bias=True)
# (1): ReLU(inplace=True)
# (2): Dropout(p=0.5, inplace=False)
# (3): Linear(in_features=128, out_features=10, bias=True)
# )
# ))
# ('features', Sequential(
# (0): Conv2d(6, 9, kernel_size=(3, 3), stride=(1, 1))
# (1): BatchNorm2d(9, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (2): ReLU(inplace=True)
# (3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
# ))
# ('features.0', Conv2d(6, 9, kernel_size=(3, 3), stride=(1, 1)))
# ('features.1', BatchNorm2d(9, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))
# ('features.2', ReLU(inplace=True))
# ('features.3', MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False))
# ('classifier', Sequential(
# (0): Linear(in_features=576, out_features=128, bias=True)
# (1): ReLU(inplace=True)
# (2): Dropout(p=0.5, inplace=False)
# (3): Linear(in_features=128, out_features=10, bias=True)
# ))
# ('classifier.0', Linear(in_features=576, out_features=128, bias=True))
# ('classifier.1', ReLU(inplace=True))
# ('classifier.2', Dropout(p=0.5, inplace=False))
# ('classifier.3', Linear(in_features=128, out_features=10, bias=True))2. children() 和 named_children()
【相同点】均返回Module类中的当前的子层(子类),不会递归遍历所有,返回类型同样为生成器
【不同点】children() 仅返回当前子类, named_children() 返回子类和对应的名字
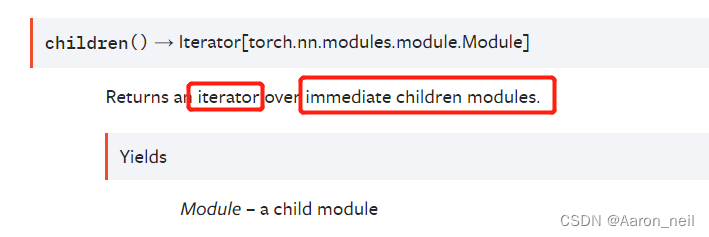
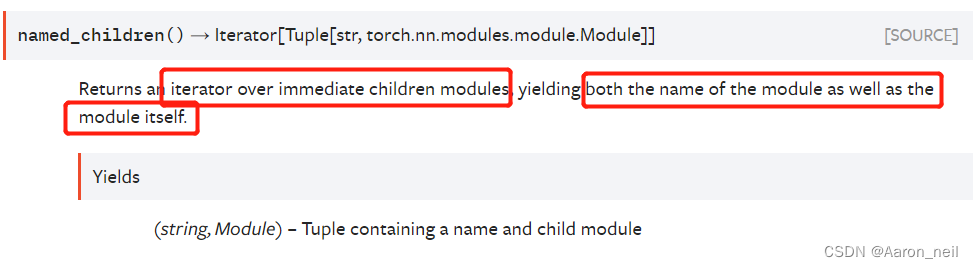
示例1:如果把model按层次从外到内进行划分的话,features和classifier是model的子层,而conv2d, BatchNorm, ReLU, Maxpool2d 是features的子层, Linear, ReLU,Dropout, Linear等是classifier的子层,因此当前model的子层只有两个Squential,即 features 和 classifier
for item in model.children():
print(item)
#Sequential(
# (0): Conv2d(6, 9, kernel_size=(3, 3), stride=(1, 1))
# (1): BatchNorm2d(9, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (2): ReLU(inplace=True)
# (3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
# )
# Sequential(
# (0): Linear(in_features=576, out_features=128, bias=True)
# (1): ReLU(inplace=True)
# (2): Dropout(p=0.5, inplace=False)
# (3): Linear(in_features=128, out_features=10, bias=True)
)示例2:同理,named_children()会返回子层和名字
for item in model.named_children():
print(item)
# ('features', Sequential(
# (0): Conv2d(6, 9, kernel_size=(3, 3), stride=(1, 1))
# (1): BatchNorm2d(9, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (2): ReLU(inplace=True)
# (3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
# ))
# ('classifier', Sequential(
# (0): Linear(in_features=576, out_features=128, bias=True)
# (1): ReLU(inplace=True)
# (2): Dropout(p=0.5, inplace=False)
# (3): Linear(in_features=128, out_features=10, bias=True)
# ))3. parameters() 和 named_parameters()
【相同点】均返回模型中的所有可学习参数,返回类型为生成器(可以遍历访问)
【不同点】named_parameters()返回参数和对应的可学习层的名字

示例1:以named_parameters()为例,每个参数都会带有 .weight或 .bias以区分权重和偏置。
其中 features.0对应 self.features中的 nn.Conv2d,features.1 对应 self.features中的 nn.BatchNorm2d,classifier.0对应self.classifier中的nn.Linear(9 * 8 * 8, 128), classifier.3对应self.classifier中的nn.Linear(128, num_class)。
for item in model.named_parameters():
print(item[0], item[1].shape)
# features.0.weight torch.Size([9, 6, 3, 3])
# features.0.bias torch.Size([9])
# features.1.weight torch.Size([9])
# features.1.bias torch.Size([9])
# classifier.0.weight torch.Size([128, 576])
# classifier.0.bias torch.Size([128])
# classifier.3.weight torch.Size([10, 128])
# classifier.3.bias torch.Size([10])示例2:parameters()
for item in model.parameters():
print(item.shape)
# torch.Size([9, 6, 3, 3])
# torch.Size([9])
# torch.Size([9])
# torch.Size([9])
# torch.Size([128, 576])
# torch.Size([128])
# torch.Size([10, 128])
# torch.Size([10])
示例3:常将 parameters() 其放到优化器内
torch.optim.SGD(params_list.parameters(),
lr=args.lr,
momentum=args.momentum,
weight_decay=args.weight_decay)4. buffers() 和 named_buffers()
【相同点】均保存在模型参数中的不可学习参数,如BN中的均值和方差(running_mean 和 running_var),返回类型为生成器
【不同点】named_buffers() 除返回参数外,还返回名字
示例1:named_buffers()
for item in model.named_buffers():
print(item[0], item[1].shape)
# features.1.running_mean torch.Size([9])
# features.1.running_var torch.Size([9])
# features.1.num_batches_tracked torch.Size([])示例2:buffers()
for item in model.buffers():
print(item.shape)
# torch.Size([9])
# torch.Size([9])
# torch.Size([])
本文部分代码和内容参考的博客:https://www.jianshu.com/p/a4c745b6ea9b