主要用来记录学习,如果能帮助到你那最好了。
数据流重导向
- 概念
cat /etc/crontab /etc/vbirdsay
标准输出:将cat的文件输出到屏幕上
标准错误输出:无法找到文件报错
*系统会将标准输出和标注错误输出都输出到屏幕上,看着比较乱,此时可以通过数据流重导向将这两种数据分开
标准输入 stdin 代码为0, 使用<或<<
标准输出:stdout 代码为1,使用>或>>
标准错误输出:(stderr)代码为2,使用2>或2>>
或1>:以覆盖的方式将标准输出写入某个文件
或1>:以追加的方式将标准输出写入某个文件
2>:以覆盖的方式将标准错误写入某个文件
2>>:以追加的方式将标准错误写入某个文件
- 用法
/dev/null 垃圾桶黑洞装置
find /home -name .bashrc 2> /dev/null. //将标准错误丢弃
Cat > catfile < ~/test.log. //test.log 写入到catfile
Cat > catfile << “eof”. //将接下来的输入写到catfile中,输入eof时结束
- 为什么要数据流重定向?
- 屏幕输出的信息很重要,而且我们需要将他存下来的时候;
- 背景执行中的程序,不希望他干扰屏幕正常的输出结果时;
- 一些系统的例行命令(例如写在/etc/crontab 中的文件)的执行结果,希望他可以存下来时;一些执行命令的可能已知错误讯息时,想以『2>/dev/null」将他丢掉时;
- 错误讯息与正确讯息需要分别输出时。
命令执行的判断依据:;,&&,||
命令技巧:sync; sync; shutdown -h now. //关机前执行两次同步化磁盘
$?(指令回传值)
cat file1 && cat file2 若file1查看成功,继续查看file2;若file1失败,那么不执行file2
cat file1 || cat file2 与上面相反
管线命令 (pipe)
-
背景
某个命令输出后的数据并不是我们想要的数据格式时,可以通过管线命令去更改 -
例子
ls -al /etc | less
用less查看/etc下所有文件,可以支持翻页,不会把屏幕塞满
管线后的命令必须是“管线命令”才可以,如 less,more,head;
但Ls,cp,mv等就不是“管线命令”了,因为他们不会接收stdin的数据
拮取命令Cut和grep
cut
cut -d’分隔字符’ -f fields <==用于有特定分隔字符
cut -c 字符区间 <==用于排列整齐的讯息
选项与参数:
-d :后面接分隔字符。与 -f 一起使用;
-f :依据 -d 的分隔字符将一段讯息分区成为数段,用 -f 取出第几段的意思; -c :以字符 (characters) 的单位取出固定字符区间;
echo ${PATH} | cut -d ‘:’ -f 3,5 //用:分割,取第3、5段
export | cut -c 12- //将export 输出的讯息,取得第 12 字符以后的所有字符串
grep
筛选出想要看的字符串所在那一行
排序命令sort, wc, uniq
-
sort
cat /etc/passwd | sort //查看密码,并用第一列数据排序(默认以文字形态排序)
cat /etc/passwd | sort -t ‘:’ -k 3 -n //以:分割,数字形态第三列进行排序 -
uniq(将重复的只展示一行)
last | cut -d ’ ’ -f1 | sort | uniq -c //使用 last 将账号列出,仅取出账号栏,进行排序后仅取出一位,统计出现次数 -
wc
参数
-l :仅列出行;
-w :仅列出多少字(英文单字);
-m :多少字符; -
双重导向tee (可以将处理后的数据存储到文件中)
last | tee last.list | cut -d " " -f1 //列出账号,数据先存储到last.list,再取第一列展示
vi和vim
-
为什么学?
所有的 Unix Like 系统都会内建 vi 文书编辑器。 -
三种模式
一般指令模式 (刚打开一个文件就是这种模式)
编辑模式 (按下a、i、o等后的模式)
指令列命令模式 (输入:/?后进入的模式) -
一般指令模式可用的按钮说明
30j 向下30行
ctrl+f 向下翻一页
ctrl+b 向上翻一页
20光标向右移动20个字符(数字+空格)
n 光标向下移动n行 -
搜索
/abc 向下寻找abc这个字符串
?abc 向前寻找abc这个字符串
p粘贴到光标所在行的下一行
P粘贴到光标所在行的上一行
u撤销
ctrl+r重复上一次操作
.重复上一次操作(小数点)
Vim意外退出,会将本次的改动写到.filename.swp中,如果想恢复的话,按R即可恢复
[O]pen Read-Only, (E)dit anyway, ®ecover, (D)elete it, (Q)uit, (A)bort:
- 区块选择(Visual Block) 处于一般指令模式时
v 字符选择,光标经过的地方反白选择
V 列选择,光标经过的列反白选择
ctrl+v 区块选择,可以选择多行(长方形)
选择后支持 y复制,d删除,p粘贴到游标处
多文件编辑
vim file1 file2 file3
:n 编辑下一个文件 :N 编辑下一个文件 :files 列出目前这个vim的开启的所有文件
支持两个文件之间拷贝粘贴操作
多窗口功能
:sp{filename}
切换文件 ctrl+w,松开所有按键,然后在按⬆️
挑字补全功能
常用ide中,可以使用tab来补全关键字、变量名,vim也可以
ctrl+x ctrl+o 以扩展名作为语法补充,以 vim 内建的关键词,予以补齐
ctrl+x ctrl+n 透过目前正在编辑的这个『文件的内容文字』作为关键词,予以补齐
Grep的进阶选项
-
参数
-A n after,将后面的n行列出来
-B n befer 将前面的n行列出来
-n 显示行号
-v 反向查找 -
查找特定范围的字符
grep -n ‘t[ae]st’ regular_express.txt //可以匹配到tast test
grep -n ‘[^g]oo’ regular_express.txt //查找带oo的行,并且oo前不能是g
grep -n ‘[^a-z]oo’ regular_express.txt //查找带oo的行,并且oo前不能是a-z
行首^ 行尾 $
grep -n ‘^the’ regular_express.txt //查找以the开头的行
grep -n ‘1’ regular_express.txt //查找以a-z开头的行
特殊用法
grep -n ‘^KaTeX parse error: Expected group after '^' at position 40: …查找空白行 grep -v '^̲’ /etc/rsyslog.conf | grep -v ‘^#’ //筛选出不要空白行,且不以#开头
通配符
. (小数点):代表『一定有一个任意字符』的意思;
* (星星号):代表『重复前一个字符, 0 到无穷多次』的意思,为组合形态
grep -n ‘g…d’ regular_express.txt //在文件中查找以g开头以d结尾长度为4的字符串所在行
grep -n ‘g*g’ regular_express.txt //只要该行中有一个g即可匹配
grep -n ‘g.*g’ regular_express.txt //该行中有两个g即可匹配
限定连续 RE 字符范围 {}
grep -n ‘go{2,5}g’ regular_express.txt //匹配gg之间有2-5个o的字符串
sed
Sed -nefr “执行动作”。//命令格式
参数
-n 只展示sed处理后的那写行
-e :直接在指令列模式上进行 sed 的动作编辑;
-f :直接将 sed 的动作写在一个文件内
-r :sed 的动作支持的是延伸型正规表示法的语法。(预设是基础正规表示法语法)
-i :直接修改读取的文件内容,而不是由屏幕输出。 (慎用!!!)
动作说明: [n1[,n2]]function //一般用于选择动作的行数
a :新增, a 的后面可以接字符串,而这些字符串会在新的一行出现(目前的下一行)~
c :取代, c 的后面可以接字符串,这些字符串可以取代 n1,n2 之间的行!
d :删除,因为是删除啊,所以 d 后面通常不接任何咚咚;
i :插入, i 的后面可以接字符串,而这些字符串会在新的一行出现(目前的上一行);
p :打印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运作~
s :取代,可以直接进行取代的工作哩!通常这个 s 的动作可以搭配正规表示法!
(nl:为每一个文件添加行号。)
nl /etc/passwd | sed ‘2,5d’ //删除passwd的2-5行
nl /etc/passwd | sed '2a Drink tea or …\
drink beer ?’ //加多行需要再行尾增加\
sed ‘s/要被取代的字符串/新的字符串/g’
- 示例
cat /etc/man_db.conf | grep ‘MAN’
MANDATORY_MANPATH
MANPATH_MAP
cat /etc/man_db.conf | grep ‘MAN’| sed ‘s/#.*$//g’ //删除掉批注之后的数据! 但是删除后会有很多空行
cat /etc/man_db.conf | grep ‘MAN’| sed ‘s/#.*KaTeX parse error: Expected group after '^' at position 14: //g' | sed '/^̲/d’ //删除批注后的数据,并删除空行
sed -i ‘s/.$/!/g’ regular_express.txt。//利用 sed 将 regular_express.txt 内每一行结尾若为 . 则换成 !
awk
使用示例 awk ‘条件类型 1{动作 1} 条件类型 2{动作 2} …’ filename
可以接文件,也可以接前一个指令的stdout
last:列出目前与过去登入系统的用户相关信息
last -n 5 | awk ‘{print $1 “\t” $3}’ //显示前五行,取出第一列和第三列的数据
NF 该行字段的数目
NR 当前处理的行数
FS 分隔符(默认空格)
运算符与go中一致 >,<,==,>=,<=,!=
cat /etc/passwd | awk ‘{FS=“:”} $3 < 10 {print $1 "\t " $3}’ //设置:为分隔符,筛选第三列小于10的行,输出第一列和第三列
[root@10 ~]# cat /etc/passwd | awk ‘{FS=“:”} $3 < 10 {print $1 "\t " $3}’
root❌0:0:root:/root:/bin/bash
bin 1
daemon 2
adm 3
lp 4
sync 5
但是第一行不会正确显示,因此需要添加参数,指定从第一行开始就以:作为分隔符
cat /etc/passwd | awk ‘BEGIN {FS=“:”} $3 < 10 {print $1 "\t " $3}’
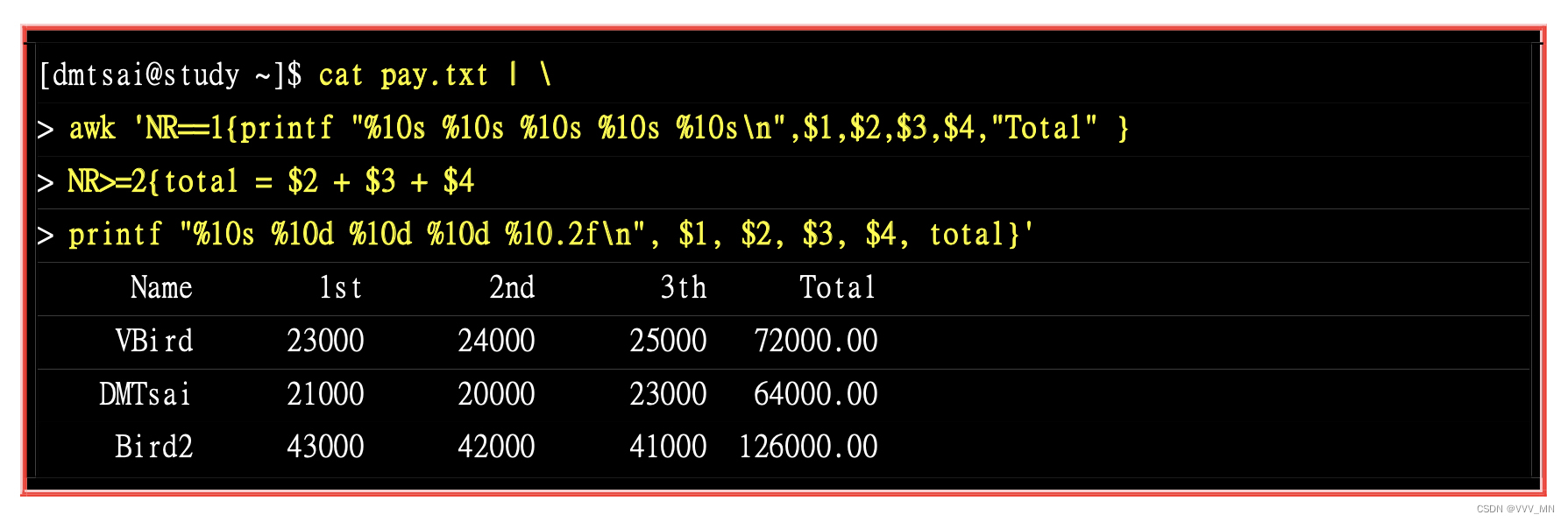
Awk可以计算,例如将下面的表换个格式展示,并对每行求和
pay.txt
Name 1st 2nd 3th
VBird 23000 24000 25000
DMTsai 21000 20000 23000
Bird2 43000 42000 41000
diff命令
命令使用样式 diff [-bBi] from-file to-file
from-file/to-file 可以使用-代替(-意思为使用标准输入代替)
-b :忽略一行当中,仅有多个空白的差异(例如 “about me” 与 “about me” 视为相同
-B :忽略空白行的差异。
-i :忽略大小写的不同。

感觉不是很直观,文本文件个人更推荐使用vimdiff
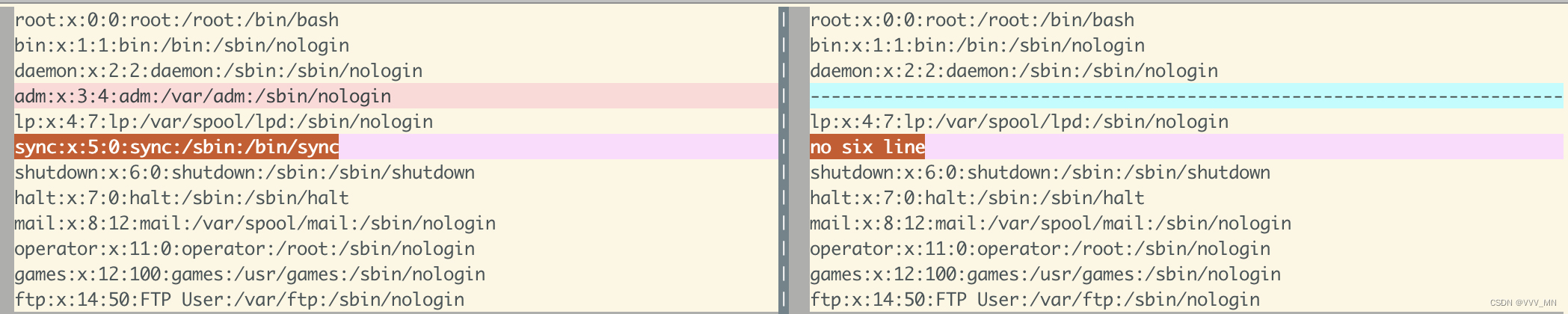
Cmp(以字节为单位去对比)
使用格式 cmp [-l] file1 file2
参数
-l :将所有的不同点的字节处都列出来。因为 cmp 预设仅会输出第一个发现的不同点。
cmp passwd.old passwd.new
passwd.old passwd.new differ: char 106, line 4
Shell
Linux操作系统预设的shell就是bash
Bash功能
History:记录历史命令,暂时存在内存中,等注销系统后,会存于家目录的.bash_history中
Tab 命令、文件补全
alias 命令别名设定 例:alias lm=‘ls -al’
type 查询指令是否为 Bash shell 的内建命令
变量的取用 echo
例如 echo ${PATH}
变量定义和规则
例如:myname=VBird 【回车】echo
m
y
n
a
m
e
/
/
即可输出
m
y
n
a
m
e
的内容
−
[
]
⚠
®
等号两边不能有空格
−
[
]
“”和’’有区别,””内可以包含特殊字符如
myname //即可输出myname的内容 - [ ] ⚠️等号两边不能有空格 - [ ] “”和’’有区别,””内可以包含特殊字符如
myname//即可输出myname的内容−[]⚠R◯等号两边不能有空格−[]“”和’’有区别,””内可以包含特殊字符如myname,‘’会按照纯文本处理
- [ ] unset 取消变量定义 unset myname
- 例子
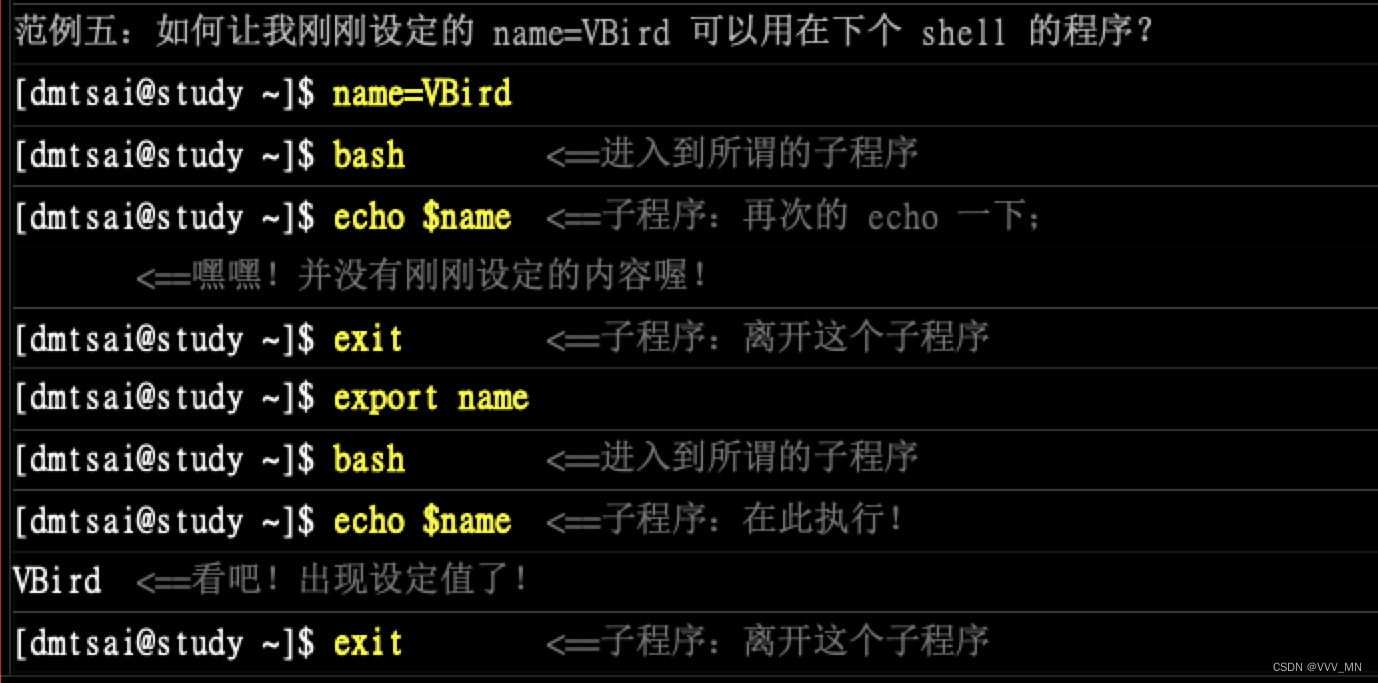
name=VBird
name=${name}yes //在name后添加yes字符串
环境变量
env 即可查看当前shell环境下的所有环境变量
Set 用 set 观察所有变量 (含环境变量与自定义变量)

PS1提示字符设定
- \u :目前使用者的账号名称,如『dmtsai』;
- \h :仅取主机名在第一个小数点之前的名字,如鸟哥主机则为『study』后面省略
- \w :完整的工作目录名称,由根目录写起的目录名称。但家目录会以 ~ 取代;
- $ :提示字符,如果是 root 时,提示字符为 # ,否则就是 $ 啰~
- \t :显示时间,为 24 小时格式的『HH:MM:SS』
- \v :BASH 的版本信息,如鸟哥的测试主机版本为 4.2.46(1)-release,仅取『4.2』显示
例:PS1='[\u@\h \w \A ##]$ ’
$(本shell的PID)
?(关于上个执行指令的回传值)
export 自定义变量转环境变量(简单理解自定义变量局势局部变量,环境变量是全局变量(可以在其他bash中读取到))
export 不加变量试,会把所有环境变量展示出来
declare 可以将环境变量改为自定义变量
Linux系统乱码、语系问题
- locale -a 可以查看当前系统支持的所有语系
如:
zh_TW.big5 <==大五码的中文编码
zu_ZA.iso88591
zu_ZA.utf8 <==万国码的中文编码
默认语系定义在/etc/locale.conf 中(如果想要长期生效,那么该这个配置文件即可)
如果只需要短期生效,那么LANG=en_US.utf8; locale export LC_ALL=en_US.utf8; locale 即可
通常说明仅设定 LANG 或 LC_ALL 这两个变量即可

变量键盘读取、数组与宣告: read, array, declare
键盘读取 read
- 使用格式 read [-pt] variable
- 选项与参数:
-p :后面可以接提示字符!
-t :后面可以接等待的『秒数!』这个比较有趣~不会一直等待使用者啦!
变量键盘宣告 declare
- 使用格式 declare [-aixr] variable
- 选项与参数:
-a :将后面名为 variable 的变量定义成为数组 (array) 类型
-i :将后面名为 variable 的变量定义成为整数数字 (integer) 类型
-x :用法与 export 一样,就是将后面的 variable 变成环境变量;
-r :将变量设定成为 readonly 类型,该变量不可被更改内容,也不能 unset
数组类型array
- 数组类型定义格式var[index]=content
例:var[1]=“small min” - 数组变量的读取
例:echo “ v a r [ 1 ] ”可以。 e c h o " {var[1]}”可以。 echo " var[1]”可以。echo"{var}”无法读取
ulimit 与文件系统及程序的限制关系
- 使用格式ulimit [-SHacdfltu] [配额]
-H :hard limit ,严格的设定,必定不能超过这个设定的数值;
-S :soft limit ,警告的设定,可以超过这个设定值,但是若超过则有警告讯息。
在设定上,通常 soft 会比 hard 小,举例来说,soft 可设定为 80 而 hard 设定为 100,那么你可以使用到 90 (因为没有超过 100),但介于 80~100 之间时, 系统会有警告讯息通知你!
-a :后面不接任何选项与参数,可列出所有的限制额度;
-c :当某些程序发生错误时,系统可能会将该程序在内存中的信息写成文件(除错用),
这种文件就被称为核心文件(core file)。此为限制每个核心文件的最大容量。
-d :程序可使用的最大断裂内存(segment)容量; -l :可用于锁定 (lock) 的内存量
-t :可使用的最大 CPU 时间 (单位为秒)
-u :单一用户可以使用的最大程序(process)数量。
a-z ↩︎