欢迎访问我的GitHub
这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos
本篇概览
- 本文是《Golang流媒体实战》系列的第七篇,继续学习一个重要且通用的知识点:hls拉流
- 在《体验开源项目lal》一文中,咱们先是用rtmp协议推流,然后就行了拉流操作,尽管只用rtmp推流,然而拉流的时候却可以使用多种协议:rtmp、flv、hls,这就有意思了,想必lal在处理推流数据时有特殊处理吧,所以才能用各种协议来拉流
- 为了弄明白其中原因,本篇咱们就来阅读hls相关源码,看看rtmp推流时为hls做了什么,以及hls拉流时lal的详细逻辑
- 关于hls和m3u8的细节,就在本篇展开了,这个仅给出一些关键信息作为参考
- 参考资料:https://developer.ridgerun.com/wiki/index.php/HLS
- m3u8格式

《Golang流媒体实战》系列的链接
- 体验开源项目lal
- 回源
- 转推和录制
- lalserver的启动源码阅读
- Golang流媒体实战之五:lal推流服务源码阅读
- Golang流媒体实战之六:lal拉流服务源码阅读
- Golang流媒体实战之七:hls拉流服务源码阅读](https://xinchen.blog.csdn.net/article/details/130165581)
推流,初始阶段
- 首先看推流处理,关于rtmp推流的源码,其实已在 《Golang流媒体实战之五:lal推流服务源码阅读》有详细分析,所以这里就不从头说起了,只挑出hls有关代码来看
- 处理推流时,publish命令由server_session.go#doPublish方法负责处理,调用栈如下
server_session.go#doCommandMessage
->
doPublish
->
server.go#OnNewRtmpPubSession
->
server_manager__.go#OnNewRtmpPubSession
->
group__in.go#AddRtmpPubSession
->
addIn
- 注意这个addIn方法中有下面这么一段代码
group.rtmp2MpegtsRemuxer = remux.NewRtmp2MpegtsRemuxer(group)
- 也就是说,推流阶段,该流对应的group对象,其成员变量rtmp2MpegtsRemuxer是有值的,看名字,这个rtmp2MpegtsRemuxer变量负责的是将rtmp协议内的数据转为mpeg格式的时间分片文件
- 记住这个group.rtmp2MpegtsRemuxer,稍后马上就会用到
推流,处理媒体数据阶段
- 在《Golang流媒体实战之五:lal推流服务源码阅读》一文中咱们已经看过,lal收到媒体数据后,具体的处理逻辑是group__core_streaming.go#broadcastByRtmpMsg方法,里面有这么一段
// # mpegts remuxer
if group.rtmp2MpegtsRemuxer != nil {
group.rtmp2MpegtsRemuxer.FeedRtmpMessage(msg)
}
- 展开上述FeedRtmpMessage方法的堆栈有点深,这里简化一下
rtmp2mpegts.go#FeedRtmpMessage
->
rtmp2mpegts_filter_.go#Push
->
rtmp2mpegts.go#onPop
->
feedVideo (这段代码比较复杂,值得细看)
->
onFrame
->
muxer.go#OnTsPackets
->
FeedMpegts
->
fragment.go#WriteFile
- 上面这复杂的调用栈,重点是rtmp2mpegts_filter_.go的逻辑,先从入口Push方法看起,此方法的功能是从消息中取得音频和视频的codecID,用于确定ts文件所需的pat表和pmt表的内容
func (q *rtmp2MpegtsFilter) Push(msg base.RtmpMsg) {
// q.done是个标志,一旦等于true,今后收到的消息都直接给观察者,
// 但是等于true之前,收到的消息都放在切片中缓存起来,
// 如果从消息中成功取得音频和视频的codecID,就在drain方法中把标准设置为true
if q.done {
q.observer.onPop(msg)
return
}
// 将数据缓存到q.data
q.data = append(q.data, msg.Clone())
// 如果是音频消息或者视频消息,就可以得到对应的codecID
switch msg.Header.MsgTypeId {
case base.RtmpTypeIdAudio:
q.audioCodecId = int(msg.Payload[0] >> 4)
case base.RtmpTypeIdVideo:
q.videoCodecId = int(msg.Payload[0] & 0xF)
}
// 一旦音频和视频的codecID都搜集到了,就执行drain,
if q.videoCodecId != -1 && q.audioCodecId != -1 {
q.drain()
return
}
// 缓存存不下的时候也会执行drain
if len(q.data) >= q.maxMsgSize {
q.drain()
return
}
}
func (q *rtmp2MpegtsFilter) drain() {
// 根据当前视频的codecId,确定ts文件的PAT,PMT格式
switch q.videoCodecId {
case int(base.RtmpCodecIdAvc):
q.observer.onPatPmt(mpegts.FixedFragmentHeader)
case int(base.RtmpCodecIdHevc):
q.observer.onPatPmt(mpegts.FixedFragmentHeaderHevc)
default:
// TODO(chef) 正确处理只有音频或只有视频的情况 #56
q.observer.onPatPmt(mpegts.FixedFragmentHeader)
}
// 将缓存的所有消息输出给观察者
for i := range q.data {
q.observer.onPop(q.data[i])
}
q.data = nil
q.done = true
}
-
从上述代码可见,随着根据CodecId的不同,pat、pmt包也有差别,具体定义在mpegts.go中,
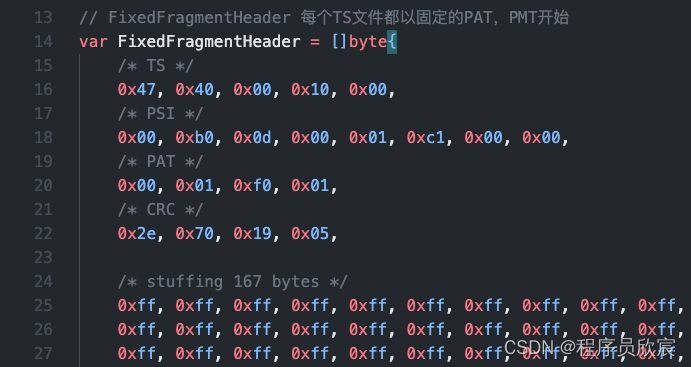
-
上面的onPatPmt方法,对应的是lal/pkg/logic/group__core_streaming.go#OnPatPmt,展开看看,主要是group.hlsMuxer.FeedPatPmt方法被执行了,也就是PAT和PMT被存入group.hlsMuxer对象,至于后面的group.recordMpegts.Write,那个和录制有关,这里暂不关注
func (group *Group) OnPatPmt(b []byte) {
group.patpmt = b
if group.hlsMuxer != nil {
group.hlsMuxer.FeedPatPmt(b)
}
if group.recordMpegts != nil {
if err := group.recordMpegts.Write(b); err != nil {
Log.Errorf("[%s] record mpegts write fragment header error. err=%+v", group.UniqueKey, err)
}
}
}
- 回到主线,一旦PAT和PMT确定后,rtmp2MpegtsFilter的作用就非常单纯了:每当新消息到来,只调用观察者的onPop方法
func (s *Rtmp2MpegtsRemuxer) onPop(msg base.RtmpMsg) {
switch msg.Header.MsgTypeId {
case base.RtmpTypeIdAudio:
s.feedAudio(msg)
case base.RtmpTypeIdVideo:
s.feedVideo(msg)
}
}
- 上述代码中的feedVideo方法,代码太长就不贴出了,主要功能是:先做合法性检查,再从一个消息中取出多个nalu逐个处理,主要是在关键帧前面放入SPS(Sequence Parameter Set)、PPS(Picture Parameter Sets),待这些都准备好之后就能组装好frame对象,然后调用rtmp2mpegts.go#onFrame
- onFrame的作用:先调用frame.Pack方法做格式转换,得到ts格式的数据,再调用观察者的OnTsPackets方法
func (s *Rtmp2MpegtsRemuxer) onFrame(frame *mpegts.Frame) {
s.adjustDtsPts(frame)
//Log.Debugf("Rtmp2MpegtsRemuxer::onFrame, frame=%s", frame.DebugString())
var boundary bool
if frame.Sid == mpegts.StreamIdAudio {
// 为了考虑没有视频的情况也能切片,所以这里判断spspps为空时,也建议生成fragment
boundary = !s.videoSeqHeaderCached()
} else {
// 收到视频,可能触发建立fragment的条件是:
// 关键帧数据 &&
// (
// (没有收到过音频seq header) || 说明 只有视频
// (收到过音频seq header && fragment没有打开) || 说明 音视频都有,且都已ready
// (收到过音频seq header && fragment已经打开 && 音频缓存数据不为空) 说明 为什么音频缓存需不为空?
// )
boundary = frame.Key && (!s.audioSeqHeaderCached() || !s.opened || !s.audioCacheEmpty())
}
if boundary {
s.opened = true
}
packets := frame.Pack()
s.observer.OnTsPackets(packets, frame, boundary)
}
更新切片文件,将音视频数据写入切片文件
- 接下来进入本篇的核心代码:生成新切片文件,关闭旧切片文件,将音视频数据写入新切片文件
- OnTsPackets对应的是muxer.go#FeedMpegts:先用updateFragment方法执行关闭旧切片开启新切片的操作,再调用WriteFile把数据写入当前切片
func (m *Muxer) FeedMpegts(tsPackets []byte, frame *mpegts.Frame, boundary bool) {
//Log.Debugf("> FeedMpegts. boundary=%v, frame=%p, sid=%d", boundary, frame, frame.Sid)
if frame.Sid == mpegts.StreamIdAudio {
// TODO(chef): 为什么音频用pts,视频用dts
if err := m.updateFragment(frame.Pts, boundary, frame); err != nil {
Log.Errorf("[%s] update fragment error. err=%+v", m.UniqueKey, err)
return
}
if !m.opened {
Log.Warnf("[%s] FeedMpegts A not opened. boundary=%t", m.UniqueKey, boundary)
return
}
//Log.Debugf("[%s] WriteFrame A. dts=%d, len=%d", m.UniqueKey, frame.DTS, len(frame.Raw))
} else {
if err := m.updateFragment(frame.Dts, boundary, frame); err != nil {
Log.Errorf("[%s] update fragment error. err=%+v", m.UniqueKey, err)
return
}
if !m.opened {
// 走到这,可能是第一个包并且boundary为false
Log.Warnf("[%s] FeedMpegts V not opened. boundary=%t, key=%t", m.UniqueKey, boundary, frame.Key)
return
}
//Log.Debugf("[%s] WriteFrame V. dts=%d, len=%d", m.UniqueKey, frame.Dts, len(frame.Raw))
}
if err := m.fragment.WriteFile(tsPackets); err != nil {
Log.Errorf("[%s] fragment write error. err=%+v", m.UniqueKey, err)
return
}
}
- 展开updateFragment去探寻核心代码,如下可见,一旦判定有必要启用新文件,就先调用closeFragment将当前TS文件关闭掉,再调用openFragment新建一个TS文件,判定条件有两个:当前TS文件存储内容是否超过一定长度,以及是否到达边界(boundary入参,如果是新的关键帧,此标志可能为true)
func (m *Muxer) updateFragment(ts uint64, boundary bool, frame *mpegts.Frame) error {
discont := true
// 如果已经有TS切片,检查是否需要强制开启新的切片,以及切片是否发生跳跃
// 注意,音频和视频是在一起检查的
if m.opened {
f := m.getCurrFrag()
// 以下情况,强制开启新的分片:
// 1. 当前时间戳 - 当前分片的初始时间戳 > 配置中单个ts分片时长的10倍
// 原因可能是:
// 1. 当前包的时间戳发生了大的跳跃
// 2. 一直没有I帧导致没有合适的时间重新切片,堆积的包达到阈值
// 2. 往回跳跃超过了阈值
//
maxfraglen := uint64(m.config.FragmentDurationMs * 90 * 10)
if (ts > m.fragTs && ts-m.fragTs > maxfraglen) || (m.fragTs > ts && m.fragTs-ts > negMaxfraglen) {
Log.Warnf("[%s] force fragment split. fragTs=%d, ts=%d, frame=%s", m.UniqueKey, m.fragTs, ts, frame.DebugString())
if err := m.closeFragment(false); err != nil {
return err
}
if err := m.openFragment(ts, true); err != nil {
return err
}
}
// 更新当前分片的时间长度
//
// TODO chef:
// f.duration(也即写入m3u8中记录分片时间长度)的做法我觉得有问题
// 此处用最新收到的数据更新f.duration
// 但是假设fragment翻滚,数据可能是写入下一个分片中
// 是否就导致了f.duration和实际分片时间长度不一致
if ts > m.fragTs {
duration := float64(ts-m.fragTs) / 90000
if duration > f.duration {
f.duration = duration
}
}
discont = false
// 已经有TS切片,切片时长没有达到设置的阈值,则不开启新的切片
if f.duration < float64(m.config.FragmentDurationMs)/1000 {
return nil
}
}
// 开启新的fragment
// 此时的情况是,上层认为是合适的开启分片的时机(比如是I帧),并且
// 1. 当前是第一个分片
// 2. 当前不是第一个分片,但是上一个分片已经达到配置时长
if boundary {
if err := m.closeFragment(false); err != nil {
return err
}
if err := m.openFragment(ts, discont); err != nil {
return err
}
}
return nil
}
- 在closeFragment的代码中,还有个重要操作:调用writePlaylist方法生成m3u8文件
func (m *Muxer) writePlaylist(isLast bool) {
// 找出时长最长的fragment
maxFrag := float64(m.config.FragmentDurationMs) / 1000
m.iterateFragsInPlaylist(func(frag *fragmentInfo) {
if frag.duration > maxFrag {
maxFrag = frag.duration + 0.5
}
})
// TODO chef 优化这块buffer的构造
var buf bytes.Buffer
buf.WriteString("#EXTM3U\n")
buf.WriteString("#EXT-X-VERSION:3\n")
buf.WriteString("#EXT-X-ALLOW-CACHE:NO\n")
buf.WriteString(fmt.Sprintf("#EXT-X-TARGETDURATION:%d\n", int(maxFrag)))
buf.WriteString(fmt.Sprintf("#EXT-X-MEDIA-SEQUENCE:%d\n\n", m.extXMediaSeq()))
m.iterateFragsInPlaylist(func(frag *fragmentInfo) {
if frag.discont {
buf.WriteString("#EXT-X-DISCONTINUITY\n")
}
buf.WriteString(fmt.Sprintf("#EXTINF:%.3f,\n%s\n", frag.duration, frag.filename))
})
if isLast {
buf.WriteString("#EXT-X-ENDLIST\n")
}
if err := writeM3u8File(buf.Bytes(), m.playlistFilename, m.playlistFilenameBak); err != nil {
Log.Errorf("[%s] write live m3u8 file error. err=%+v", m.UniqueKey, err)
}
}
- 还有个比较重要的地方,就是openFragment方法,里面是打开一个新的TS文件的操作:生成TS文件名,将准备好的PAT和PMT信息写入文件,调用观察者的回调接口
func (m *Muxer) openFragment(ts uint64, discont bool) error {
if m.opened {
return nazaerrors.Wrap(base.ErrHls)
}
id := m.getFragmentId()
filename := PathStrategy.GetTsFileName(m.streamName, id, int(Clock.Now().UnixNano()/1e6))
filenameWithPath := PathStrategy.GetTsFileNameWithPath(m.outPath, filename)
if err := m.fragment.OpenFile(filenameWithPath); err != nil {
return err
}
if err := m.fragment.WriteFile(m.patpmt); err != nil {
return err
}
m.opened = true
frag := m.getCurrFrag()
frag.discont = discont
frag.id = id
frag.filename = filename
frag.duration = 0
m.fragTs = ts
// nrm said: start fragment with audio to make iPhone happy
m.observer.OnFragmentOpen()
m.observer.OnHlsMakeTs(base.HlsMakeTsInfo{
Event: "open",
StreamName: m.streamName,
Cwd: base.GetWd(),
TsFile: filenameWithPath,
LiveM3u8File: m.playlistFilename,
RecordM3u8File: m.recordPlayListFilename,
Id: id,
Duration: frag.duration,
})
return nil
}
- TS文件名的生成逻辑很简单,用流名+时间戳+TS序号拼接
func (*DefaultPathStrategy) GetTsFileName(streamName string, index int, timestamp int) string {
return fmt.Sprintf("%s-%d-%d.ts", streamName, timestamp, index)
}
- 至此,生成逻辑的代码算是看过了,接下来要看播放逻辑
拉流播放
- 要响应客户端的拉流请求,首先要准备好server服务,咱们就从server初始化看起
- hls的server对象,是main方法中创建的,调用栈如下:
main()
->
logic.go#NewLalServer
->
server_manager__.go#NewServerManager
->
hls/server_handler.go#NewServerHandler
- 上述代码创建了hlsServerHandler对象,存入sm.hlsServerHandler,接下来就是server_manager__.go#RunLoop启动hls服务,代码如下
if err := addMux(sm.config.HlsConfig.CommonHttpServerConfig, sm.serveHls, "hls"); err != nil {
return err
}
- 也就是说,下面这个方法负责响应hls请求
func (sm *ServerManager) serveHls(writer http.ResponseWriter, req *http.Request) {
urlCtx, err := base.ParseUrl(base.ParseHttpRequest(req), 80)
if err != nil {
Log.Errorf("parse url. err=%+v", err)
return
}
if urlCtx.GetFileType() == "m3u8" {
// TODO(chef): [refactor] 需要整理,这里使用 hls.PathStrategy 不太好 202207
streamName := hls.PathStrategy.GetRequestInfo(urlCtx, sm.config.HlsConfig.OutPath).StreamName
if err = sm.option.Authentication.OnHls(streamName, urlCtx.RawQuery); err != nil {
Log.Errorf("simple auth failed. err=%+v", err)
return
}
}
sm.hlsServerHandler.ServeHTTP(writer, req)
}
- 对于hls的请求,处理逻辑的调用链
server_handler.go#ServeHTTP
->
ServeHTTPWithUrlCtx
- 响应hls请求的关键是ServeHTTPWithUrlCtx,来看它的关键代码,其实很简单,就是根据请求到达文件名找到文件,读取内容并返回,注意代码注解中有详细说明
// 根据请求信息生成读取TS或者M3U8文件的关键参数,例如流名和文件路径
ri := PathStrategy.GetRequestInfo(urlCtx, s.outPath)
//Log.Debugf("%+v", ri)
// 合法性检查
if filename == "" || (filetype != "m3u8" && filetype != "ts") || ri.StreamName == "" || ri.FileNameWithPath == "" {
err = errors.New(fmt.Sprintf("invalid hls request. url=%+v, request=%+v", urlCtx, ri))
Log.Warnf(err.Error())
resp.WriteHeader(http.StatusFound)
return
}
// 抽象过的读取文件操作,放入二进制切片,
// 具体的读取操作有两种:从磁盘读取或者从内存读取,这取决于配置的是写入磁盘还是内存
content, _err := ReadFile(ri.FileNameWithPath)
if _err != nil {
err = errors.New(fmt.Sprintf("read hls file failed. request=%+v, err=%+v", ri, _err))
Log.Warnf(err.Error())
resp.WriteHeader(http.StatusNotFound)
return
}
// 根据文件类型不同,设置不同的响应header
switch filetype {
case "m3u8":
resp.Header().Add("Content-Type", "application/x-mpegurl")
resp.Header().Add("Server", base.LalHlsM3u8Server)
// 给ts文件都携带上session_id字段
if sessionIdHash != "" {
content = bytes.ReplaceAll(content, []byte(".ts"), []byte(".ts?session_id="+sessionIdHash))
}
case "ts":
resp.Header().Add("Content-Type", "video/mp2t")
resp.Header().Add("Server", base.LalHlsTsServer)
}
resp.Header().Add("Cache-Control", "no-cache")
resp.Header().Add("Access-Control-Allow-Origin", "*")
if sessionIdHash != "" {
session := s.getSubSession(sessionIdHash)
if session != nil {
session.AddWroteBytesSum(uint64(len(content)))
}
}
// 响应
_, _ = resp.Write(content)
return
- 至此,hls拉流服务的源码阅读已经完成,简单来说,就是一路RTMP的推流会在处理每个音视频消息的时候,实时生成m3u8文件,以及多个TS文件,这样每当hls拉流请求到达时,就可以根据指定的文件名返回已经生成的内容了
- 简单清晰的逻辑,满满的知识点Get,再一次感谢lal的作者先生
你不孤单,欣宸原创一路相伴
- Java系列
- Spring系列
- Docker系列
- kubernetes系列
- 数据库+中间件系列
- DevOps系列