- 你的目的是来预测我们生成图像的提示词
1.比赛目标
这个竞赛的目标不是从文本提示生成图像,而是创建一个模型,可以在给定生成图像的情况下预测文本提示(你有一堆提示词,你预测是否该提示词参与了图像的生成)?您将在包含由Stable Diffusion 2.0生成的各种(提示,图像)对的数据集上进行预测,以了解潜在关系的可逆程度。
2.内容
文本到图像模型的流行已经摒弃了提示工程的一个全新领域。一部分是艺术,一部分是悬而未决的科学,ML从业者和研究人员正在迅速努力理解提示和它们生成的图像之间的关系。在提示符上添加“4k”是使其更逼真的最佳方法吗?提示中的小扰动会导致高度发散的图像吗?提示关键字的顺序如何影响生成的场景?这个竞赛的任务是创建一个模型,可以可靠地反转生成给定图像的扩散过程。
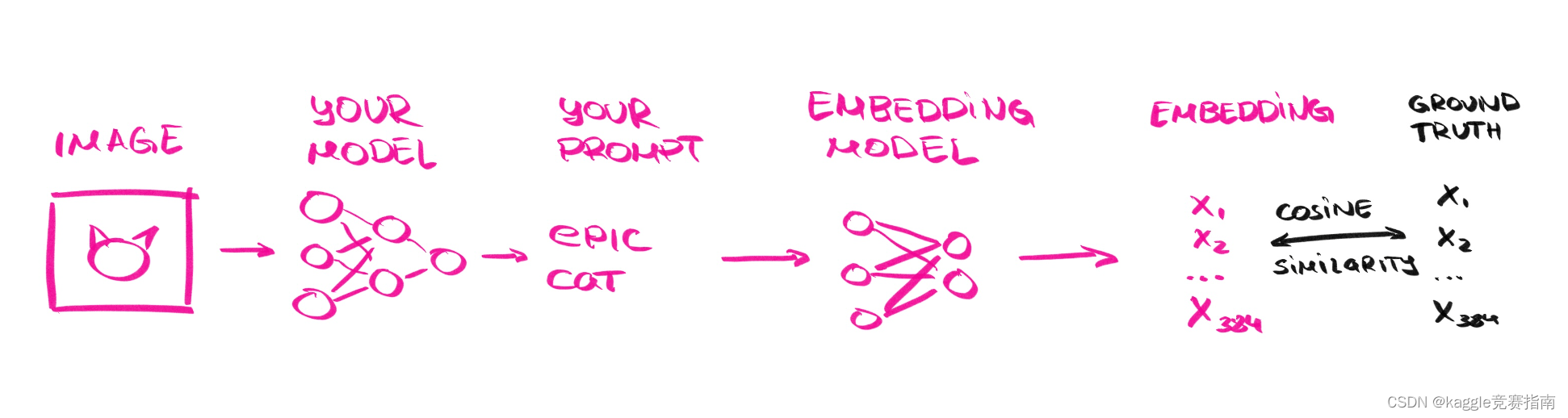
为了以一种稳健的方式计算提示的相似性——这意味着“史诗猫”的得分与“威严的小猫”相似(meaning that “epic cat” is scored as similar to “majestic kitten” in spite of character-level differences),尽管它们在字符级别上存在差异——你将提交你预测的提示的嵌入。是直接建模嵌入,还是先预测提示,然后转换为嵌入,都取决于您!祝你好运,并愿你在此创建“高质量、锐利焦点、复杂、详细、不真实的健壮交叉验证风格”的模型。
3评价指标
使用预测和实际提示嵌入向量之间的平均余弦相似度评分来评估提交。如何为groundtruth提示计算嵌入的精确细节见
数据
- images/ - 是一些从提示词中产生的图像;你的任务是预测是哪些提示词用来产生这个图像.隐藏的测试数据集包含大约16000张图片。
- prompts.csv - 用来产生图像的提示词。These are provided as illustrative examples only. It is up to each competitor to develop their own strategy of creating a training set of images, using pre-trained models, etc. Note that this file is not contained in the re-run test set, and thus referencing it in a Notebook submission will result in a failure.
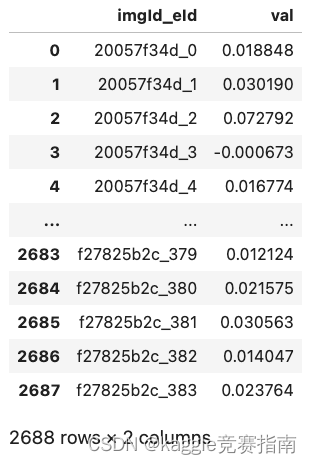
- sample_submission.csv - 一个正确的示范 The values found in this file are embeddings of the prompts in the prompts.csv file and thus can be used validate your embedding pipeline. This notebook demonstrates how to calculate embeddings.
探索性数据分析(Exploratory Data Analysis,EDA)
import os
import glob
import math
import random
import numpy as np
import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity
import cv2
import matplotlib.pyplot as plt
df_prompts = pd.read_csv("../input/stable-diffusion-image-to-prompts/prompts.csv")
df_prompts

图像id转路径
def image_id2path(
img_id: str,
folder: str = "stable-diffusion-image-to-prompts"
) -> str:
return f"../input/{folder}/images/{img_id}.png"
图像展示
def show_images_and_prompts(
df: pd.DataFrame,
folder: str = "stable-diffusion-image-to-prompts",
n: int = 10,
) -> None:
if n == -1:
n = df.shape[0]
for ind, row in df[:n].iterrows():
img_id = row["imgId"]
prompt = row["prompt"]
path = image_id2path(img_id, folder)
image = cv2.imread(path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
if ind % 2 == 0:
plt.figure(figsize=(16, 8))
plt.subplot(1, 2, 1)
else:
plt.subplot(1, 2, 2)
plt.imshow(image)
list_prompt_words = prompt.split()
if len(prompt) > 100:
_len = len(list_prompt_words)
prompt = "{}\n{}\n{}".format(
" ".join(list_prompt_words[:_len // 3]),
" ".join(list_prompt_words[_len // 3 : 2 * _len // 3]),
" ".join(list_prompt_words[2 * _len // 3:]),
)
elif len(prompt) > 50:
_len = len(list_prompt_words)
prompt = "{}\n{}".format(
" ".join(list_prompt_words[:_len // 2]),
" ".join(list_prompt_words[_len // 2:])
)
plt.title(prompt, fontsize=14)
plt.axis("off")
if df_prompts is not None:
show_images_and_prompts(df_prompts, n=7)

- 左上到右下分别意思为
- 超级逼真的照片,非常友好和反乌托邦的陨石坑
- 拉面用分形的玫瑰乌木雕刻而成,以哈德逊河学派的风格
- 超龙在树林里拿着一个黑豆卷,旁边是一只一模一样的角龙。
- 一个轰鸣的复古机器人起重机与一只无精打采的法国斗牛犬在羊皮纸上作画

import sys
sys.path.append('../input/sentence-transformers-222/sentence-transformers')
from sentence_transformers import SentenceTransformer, models
EMB_SIZE = 384
df_sample_submission = pd.read_csv("../input/stable-diffusion-image-to-prompts/sample_submission.csv")
df_sample_submission
ids = list(
map(
lambda x: x.split(".")[0],
os.listdir("../input/stable-diffusion-image-to-prompts/images/")
)
)
st_model = SentenceTransformer('/kaggle/input/sentence-transformers-222/all-MiniLM-L6-v2')
# Wait for the model in the future :)
prompts_to_test = [
"Moment of pure joy",
"Ride a bicycle in the snow",
"Cook a meal using only five ingredients",
"Write a short story in ten words or less",
"Take a photo of a stranger and ask them their life story",
"Sing a song in a language you don't speak",
"Learn a new dance style and perform it in public",
"Take a walk without using a map or GPS",
"Read a book in a genre you wouldn't normally choose",
"Visit a new restaurant and order a dish you've never tried",
"Draw a portrait of a friend without looking at the paper",
]
for prompt in prompts_to_test:
prompts = [prompt] * len(ids)
prompt_embeddings = st_model.encode(prompts).flatten()
imgId_eId = []
for _id in ids:
for i in range(EMB_SIZE):
imgId_eId.append(f"{_id}_{i}")
df_submission = pd.DataFrame(
index=imgId_eId,
data=prompt_embeddings,
columns=["val"]
).rename_axis("imgId_eId")
cosine_similarities = []
for i in range(len(ids)):
current = cosine_similarity(
df_submission.iloc[i * EMB_SIZE : (i + 1) * EMB_SIZE]["val"].values.reshape(1, -1),
df_sample_submission.iloc[i * EMB_SIZE : (i + 1) * EMB_SIZE]["val"].values.reshape(1, -1)
)
cosine_similarities.append(current)
print(prompt, f"{np.mean(cosine_similarities):.3f}")
df_submission.to_csv("submission.csv")
```
# Baseline Stable Diffusion ViT Baseline Train
### Library
```python
import os
import random
import numpy as np
import pandas as pd
from PIL import Image
from tqdm.notebook import tqdm
from scipy import spatial
from sklearn.model_selection import train_test_split
import torch
from torch import nn
from torch.utils.data import Dataset, DataLoader
from torch.optim.lr_scheduler import CosineAnnealingLR
from torchvision import transforms
import timm
from timm.utils import AverageMeter
import sys
sys.path.append('../input/sentence-transformers-222/sentence-transformers')
from sentence_transformers import SentenceTransformer
import warnings
warnings.filterwarnings('ignore')
Config
class CFG:
model_name = 'vit_base_patch16_224'
input_size = 224
batch_size = 64
num_epochs = 3
lr = 1e-4
seed = 42
seed
def seed_everything(seed):
os.environ['PYTHONHASHSEED'] = str(seed)
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
seed_everything(CFG.seed)
Dataset
class DiffusionDataset(Dataset):
def __init__(self, df, transform):
self.df = df
#图像增强
self.transform = transform
def __len__(self):
return len(self.df)
def __getitem__(self, idx):
row = self.df.iloc[idx]
#打开图片
image = Image.open(row['filepath'])
#图像增强
image = self.transform(image)
#标签
prompt = row['prompt']
return image, prompt
class DiffusionCollator:
def __init__(self):
self.st_model = SentenceTransformer(
'/kaggle/input/sentence-transformers-222/all-MiniLM-L6-v2',
device='cpu'
)
def __call__(self, batch):
images, prompts = zip(*batch)
images = torch.stack(images)
prompt_embeddings = self.st_model.encode(
prompts,
show_progress_bar=False,
convert_to_tensor=True
)
return images, prompt_embeddings
def get_dataloaders(trn_df,val_df,input_size,batch_size):
#图像增强设置
transform = transforms.Compose([
transforms.Resize(input_size),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),
])
#dataset
trn_dataset = DiffusionDataset(trn_df, transform)
val_dataset = DiffusionDataset(val_df, transform)
collator = DiffusionCollator()
#dataloader
dataloaders = {}
dataloaders['train'] = DataLoader(
dataset=trn_dataset,
shuffle=True,
batch_size=batch_size,
pin_memory=True,
num_workers=2,
drop_last=True,
collate_fn=collator
)
dataloaders['val'] = DataLoader(
dataset=val_dataset,
shuffle=False,
batch_size=batch_size,
pin_memory=True,
num_workers=2,
drop_last=False,
collate_fn=collator
)
return dataloaders
Train
#评价指标
def cosine_similarity(y_trues, y_preds):
return np.mean([
1 - spatial.distance.cosine(y_true, y_pred)
for y_true, y_pred in zip(y_trues, y_preds)
])
Train
def train(trn_df,val_df,model_name,input_size,batch_size,num_epochs,lr
):
#设置运行环境
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
#dataloader
dataloaders = get_dataloaders(trn_df,val_df,input_size,batch_size)
#创建模型
model = timm.create_model(
model_name,
pretrained=True,
num_classes=384#给定的词表长度为384
)
#梯度检查点,可以降低显存使用
model.set_grad_checkpointing()
#模型迁移到GPU上
model.to(device)
#优化器
optimizer = torch.optim.AdamW(model.parameters(), lr=lr)
#周期计算,用于CosineAnnealingLR
ttl_iters = num_epochs * len(dataloaders['train'])
#学习率调整策略
scheduler = CosineAnnealingLR(optimizer, T_max=ttl_iters, eta_min=1e-6)#eta_min.为最小的学习率
#评价指标
criterion = nn.CosineEmbeddingLoss()
best_score = -1.0
for epoch in range(num_epochs):
train_meters = {
'loss': AverageMeter(),
'cos': AverageMeter(),
}
#模型设置为训练模式
model.train()
for X, y in tqdm(dataloaders['train'], leave=False):
X, y = X.to(device), y.to(device)
#梯度清零
optimizer.zero_grad()
X_out = model(X)
target = torch.ones(X.size(0)).to(device)
#计算损失
loss = criterion(X_out, y, target)
#反向传播
loss.backward()
#更新
optimizer.step()
scheduler.step()
trn_loss = loss.item()
trn_cos = cosine_similarity(
X_out.detach().cpu().numpy(),
y.detach().cpu().numpy()
)
train_meters['loss'].update(trn_loss, n=X.size(0))
train_meters['cos'].update(trn_cos, n=X.size(0))
print('Epoch {:d} / trn/loss={:.4f}, trn/cos={:.4f}'.format(
epoch + 1,
train_meters['loss'].avg,
train_meters['cos'].avg))
val_meters = {
'loss': AverageMeter(),
'cos': AverageMeter(),
}
model.eval()
for X, y in tqdm(dataloaders['val'], leave=False):
X, y = X.to(device), y.to(device)
with torch.no_grad():
X_out = model(X)
target = torch.ones(X.size(0)).to(device)
loss = criterion(X_out, y, target)
val_loss = loss.item()
val_cos = cosine_similarity(
X_out.detach().cpu().numpy(),
y.detach().cpu().numpy()
)
val_meters['loss'].update(val_loss, n=X.size(0))
val_meters['cos'].update(val_cos, n=X.size(0))
print('Epoch {:d} / val/loss={:.4f}, val/cos={:.4f}'.format(
epoch + 1,
val_meters['loss'].avg,
val_meters['cos'].avg))
if val_meters['cos'].avg > best_score:
best_score = val_meters['cos'].avg
torch.save(model.state_dict(), f'{model_name}.pth')
准备训练数据
df = pd.read_csv('/kaggle/input/diffusiondb-data-cleansing/diffusiondb.csv')
trn_df, val_df = train_test_split(df, test_size=0.1, random_state=CFG.seed)
训练
train(trn_df, val_df, CFG.model_name, CFG.input_size, CFG.batch_size, CFG.num_epochs, CFG.lr)
模型推理
import numpy as np
import pandas as pd
from pathlib import Path
from PIL import Image
from tqdm.notebook import tqdm
import torch
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
import timm
class CFG:
model_path = '/kaggle/input/stable-diffusion-vit-baseline-train/vit_base_patch16_224.pth'
model_name = 'vit_base_patch16_224'
input_size = 224
batch_size = 64
dataset
class DiffusionTestDataset(Dataset):
def __init__(self, images, transform):
self.images = images
self.transform = transform
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
image = Image.open(self.images[idx])
image = self.transform(image)
return image
inference
def predict(
images,
model_path,
model_name,
input_size,
batch_size
):
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
transform = transforms.Compose([
transforms.Resize(input_size),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),
])
dataset = DiffusionTestDataset(images, transform)
dataloader = DataLoader(
dataset=dataset,
shuffle=False,
batch_size=batch_size,
pin_memory=True,
num_workers=2,
drop_last=False
)
model = timm.create_model(
model_name,
pretrained=False,
num_classes=384
)
state_dict = torch.load(model_path)
model.load_state_dict(state_dict)
model.to(device)
model.eval()
preds = []
for X in tqdm(dataloader, leave=False):
X = X.to(device)
with torch.no_grad():
X_out = model(X)
preds.append(X_out.cpu().numpy())
return np.vstack(preds).flatten()
images = list(Path('/kaggle/input/stable-diffusion-image-to-prompts/images').glob('*.png'))
imgIds = [i.stem for i in images]
EMBEDDING_LENGTH = 384
imgId_eId = [
'_'.join(map(str, i)) for i in zip(
np.repeat(imgIds, EMBEDDING_LENGTH),
np.tile(range(EMBEDDING_LENGTH), len(imgIds)))]
prompt_embeddings = predict(images, CFG.model_path, CFG.model_name, CFG.input_size, CFG.batch_size)
submission = pd.DataFrame(
index=imgId_eId,
data=prompt_embeddings,
columns=['val']
).rename_axis('imgId_eId')
submission.to_csv('submission.csv')