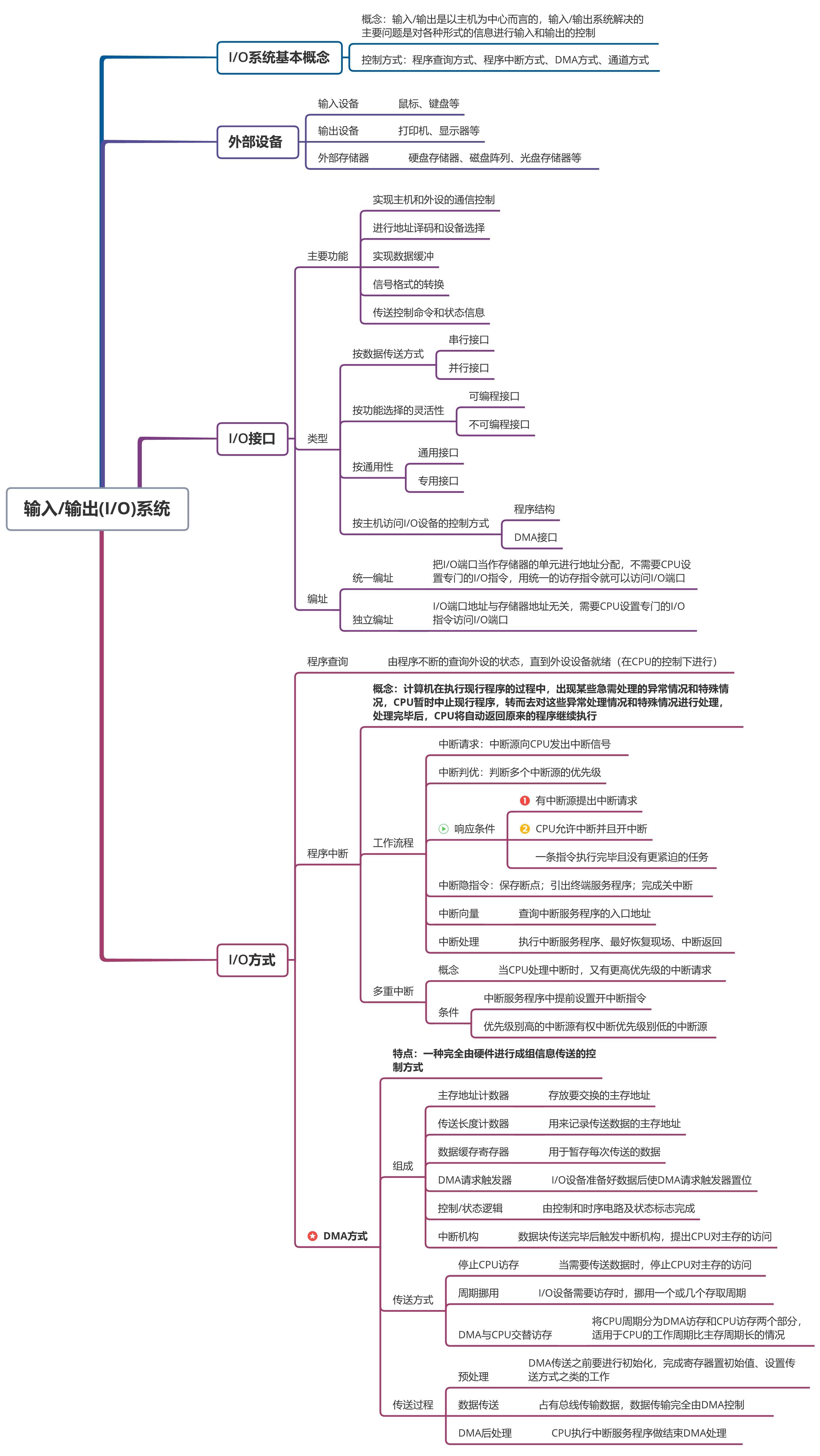
目录:导读
- 前言
- 一、Python编程入门到精通
- 二、接口自动化项目实战
- 三、Web自动化项目实战
- 四、App自动化项目实战
- 五、一线大厂简历
- 六、测试开发DevOps体系
- 七、常用自动化测试工具
- 八、JMeter性能测试
- 九、总结(尾部小惊喜)
前言
本节或者后面都可能需要用到jmeter的插件,因此需要先引入插件管理工具:plugin-manageI.x…x.jar ,把jar包放入jmeter的lib\ext目录下(由于这里不方便放文件,可以看最底下助理)
放入jar包后,重启jmeter,然后在选项卡的最下面就会有Plugins Manager
进入之后,选择Available Plugins,搜索需要的插件然后点右下角的Apply Changes and Restart JMeter即可安装插件
DDT数据驱动
性能测试因为是使用多用户并发,请求的时间也要几分钟到几十分钟不等,所以总请求量很大,因此经常需要准备测试数据。最典型的场景,就是使用一批账号不停的进行登录接口的压测,此时就需要用到DDT的概念。
1、CSV数据文件
通过在csv文件中提前写入测试数据,循环读取csv文件并提取其中数据以达到数据驱动。
(在用csv准备数据时,能用csv数据文件设置时,坚决不同${__CSVRead(,)}函数,这是个鸡肋)
添加配置元件->CSV数据文件设置
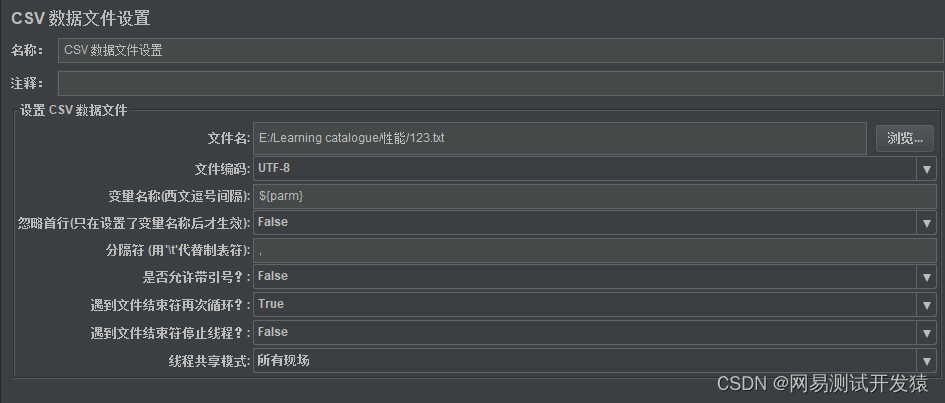
参数的含义大家可以去网上查查,这里列举几个重要的。
变量名称:
- 就是csv的列,每一列都是一个参数。
- 多个参数时,固定用逗号分隔
- 如果中间有一列空列或者有一列的数据不想接受时,中间的可以用空格站位。例如:
user, ,pwd
线程共享模式:
- 所有现场(所有线程):当配置原件在线程组外部时,所有线程组共用这些数据。
- 当前线程组:每个线程组的数据是独立的,每个线程组各自循环自己的数据。
- 当前线程:每个线程(并发用户数)的数据是独立的,各自循环自己的数据。
2、使用sqllite实现数据驱动
使用sqlite数据库要注意,sqlite不只支持多线程的,所以使用多线程写入数据偶尔会出现错误。因此写数据时需要加上临界控制器,让所有用户串行。
操作步骤
准备测试数据,这个步骤可以有很多方法,使用Python、csv或其他方式生成测试数据都可以。这里是使用JMeter通过查询数据库。 为了方便查看结果,可以使用保存到响应文件配置元件,将结果保存到txt文件中查看。
首先编写查询sqlselect id,username,password,mobile from cb_account where password=“e10adc3949ba59abbe56e057f20f883e” and LENGTH(mobile)=11 limit 100 OFFSET 500;
配置数据库信息和jdbc请求,具体配置方式请看到多协议脚本中的JDBC脚本,记得填写Variable names,因为要去返回结果里面取值。
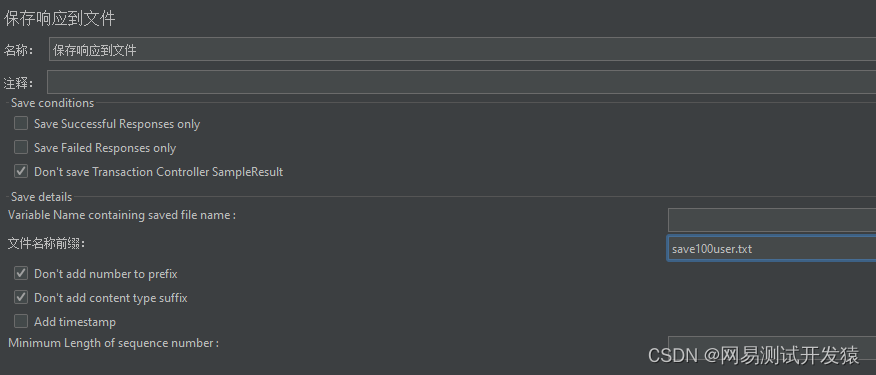
添加监听器->保存响应到文件(注意顺序),一般只需要勾选/填写下图中的内容,其他都不动。保存成功之后在bin目录可以找到保存的文件(这一步非必须,这里主要是为了看保存的结果,顺便介绍这个配置元件的使用)
至此,测试数据已经生成出来了,但要思考一下,这一次生成的数据只有100条,如果要继续生成,要200、300、400条以上的数据,那要怎么操作?
总不可能生成N个txt文件,然后循环去读取吧,因此就会引出下一步操作,往数据库中存入测试数据。。
这里引入一个叫sqlite的数据库,它是一个关系型数据库但同时也是一个内存数据库,它没有复杂的安装,也不需要登录账号,只要你的操作系统是图形界面且带有浏览器,那你的电脑就一定安装了sqlite。
把sqlite的jar包sqlite-jdbc-3.31.1.jar放到jmeter的lib目录里
再添加一个JDBC Connection Configuration配置元件并填写Variable Name for created pool
在地下的数据库配置信息里,Database URL填写jdbc:sqlite:sqltest.db, 后面的这个sqltest.db其实就是文件名称,这里写路径也可以。同样的,如果不写路径,它会根据文件名自动生成一个db文件并存放在bin目录下
JDBC Driver class选择org.sqlite.JDBC,剩下的就不用填写了,没有账号密码。
创建表,创建表可以通过jmeter完成,也可以通过Navicat等工具完成。我是使用jmeter去创建表的
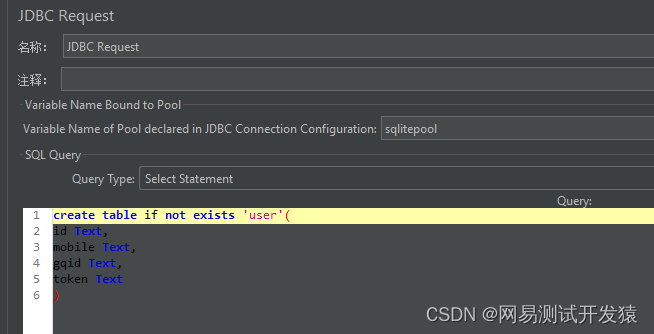
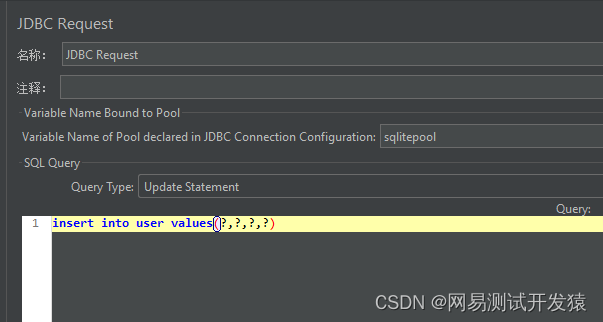
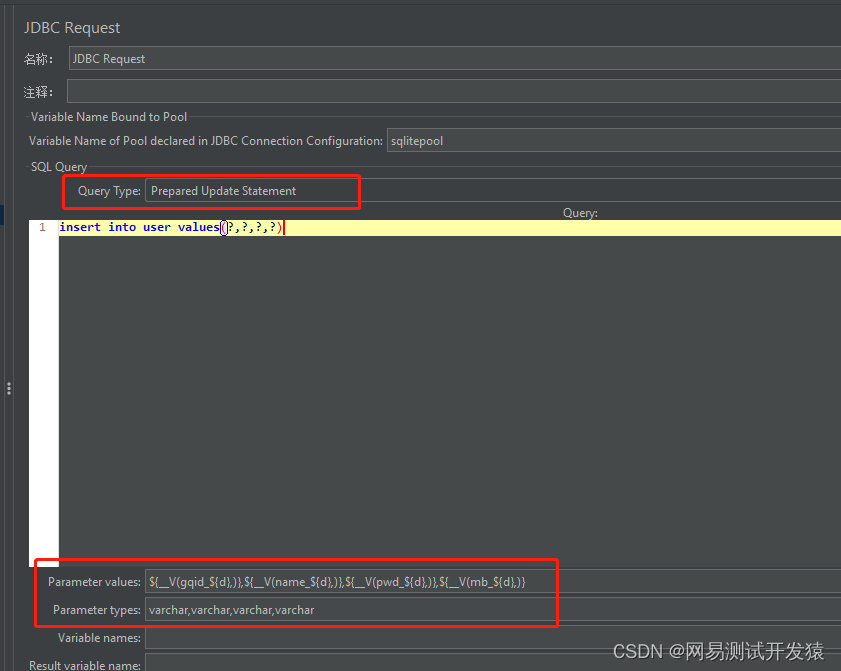
数据库也创建完了,接下来就可以将数据写入到数据库中。再创建一个jdbc request取样器,编写写入数据的sql脚本
然后在这个取样器上再添加一个循环控制器,因为从mysql查询数据出来后后,它的数据格式是这样的,所以需要进行循环,循环的次数就是mb_#的值
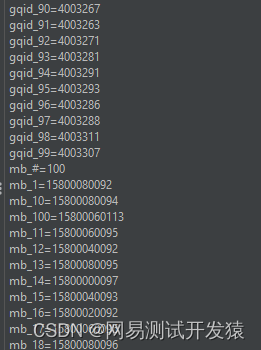
然后再添加一个计数器。提一句,如果懂Python的话,现在的循环控制器+计数器≈for i in len(obj)
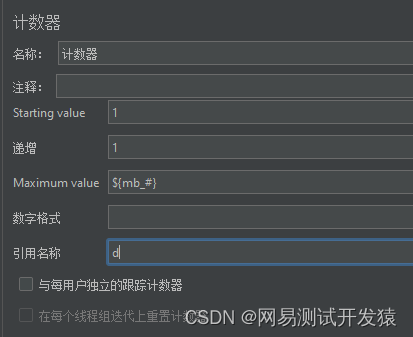
然后结合V函数,把变量名传进写入数据的脚本里,注意query type的选项
运行之后,去数据库就能看到插入的数据了。至此,测试数据已经有了。
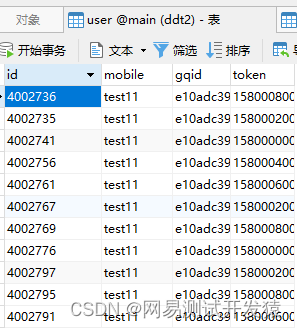
将产生的数据融入到性能测试中
这里可能会有人有疑问,为什么要那么麻烦,还要再搞一个数据库,再去存数据。从MySQL上读到数据之后直接用不就好了吗?
这个问题,其实是可以,但仅能用在功能或自动化测试中!因为性能测试中,去请求MySQL,这无疑是额外增加了MySQL的压力,这会影响到性能测试结果。
那为什么会用sqlite?再单独拉一个MySQL出来不行吗?
答案是可以,但不推荐。因为sqlite是一个内存数据库,它的读取速度是肯定比MySQL快的,而且它比MySQL更轻便,数据文件可以跟着脚本走。
然后要使用sqlite的数据做性能测试需要考虑一个问题,每个线程使用的数据是独立的还是共用的?
下面这种场景就是每个线程使用的数据都是独立的,可以使用仅一次控制器去控制读取次数。
先查询sqlite,得到全部用户的手机号
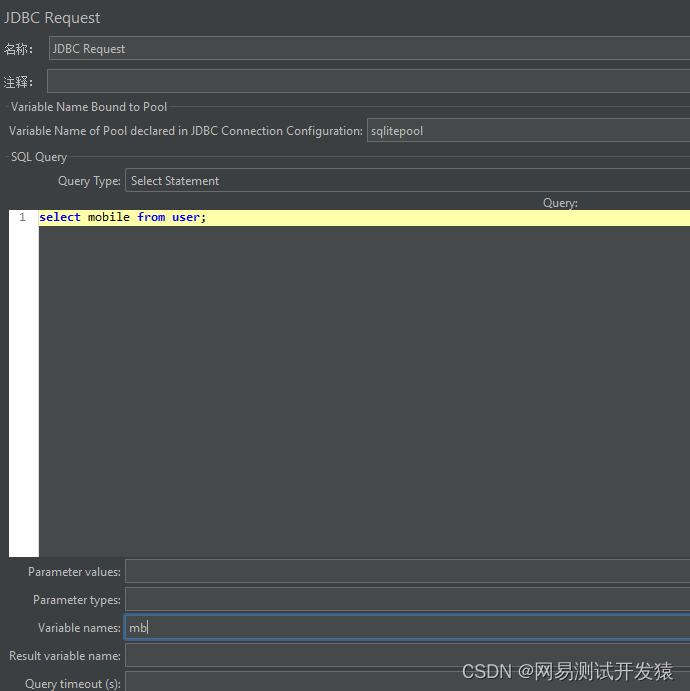
把这个取样器放入到仅一次控制器中
在登录时候,引用变量
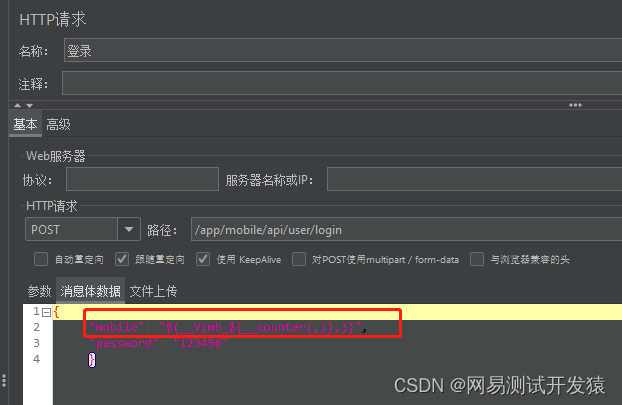
最终得到的结果就是,每个线程都会去查询一次sqlite数据库,然后得到数据后,单独去循环。
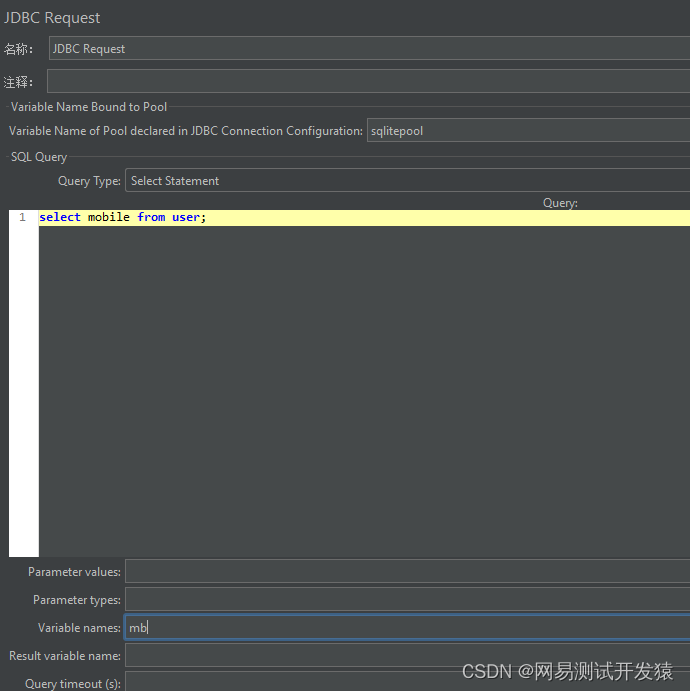
另一种场景就是所有数据都是共用的,此时就不能用仅一次控制器了。
第一步也是查询手机号,但是要放入setup线程组中
添加循环控制器,循环次数是${mb_#}
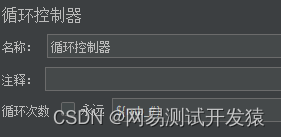
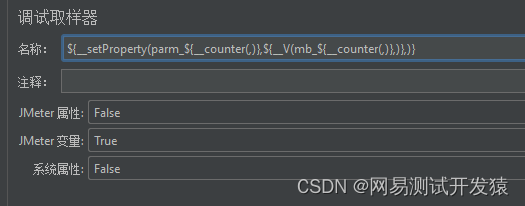
然后在循环控制内部添加一个调试取样器,并使用setProperty函数把参数写入到属性中。
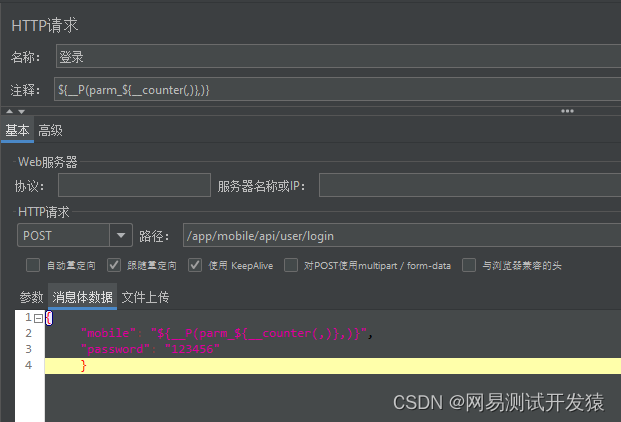
最后在登录脚本中,通过P函数引用属性即可
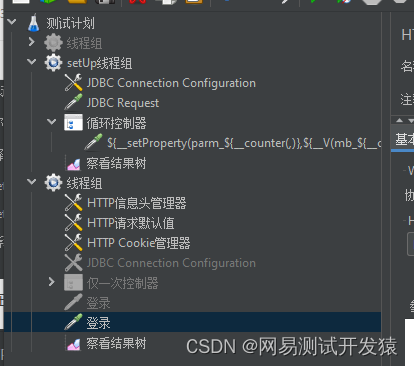
补充,上面用的是count函数去计数的,但如果运行次数比数据大时会出现取不到值的情况,因为下标越界了。要解决的其实只需要把count函数替换成计数器就好了。

| 下面是我整理的2023年最全的软件测试工程师学习知识架构体系图 |
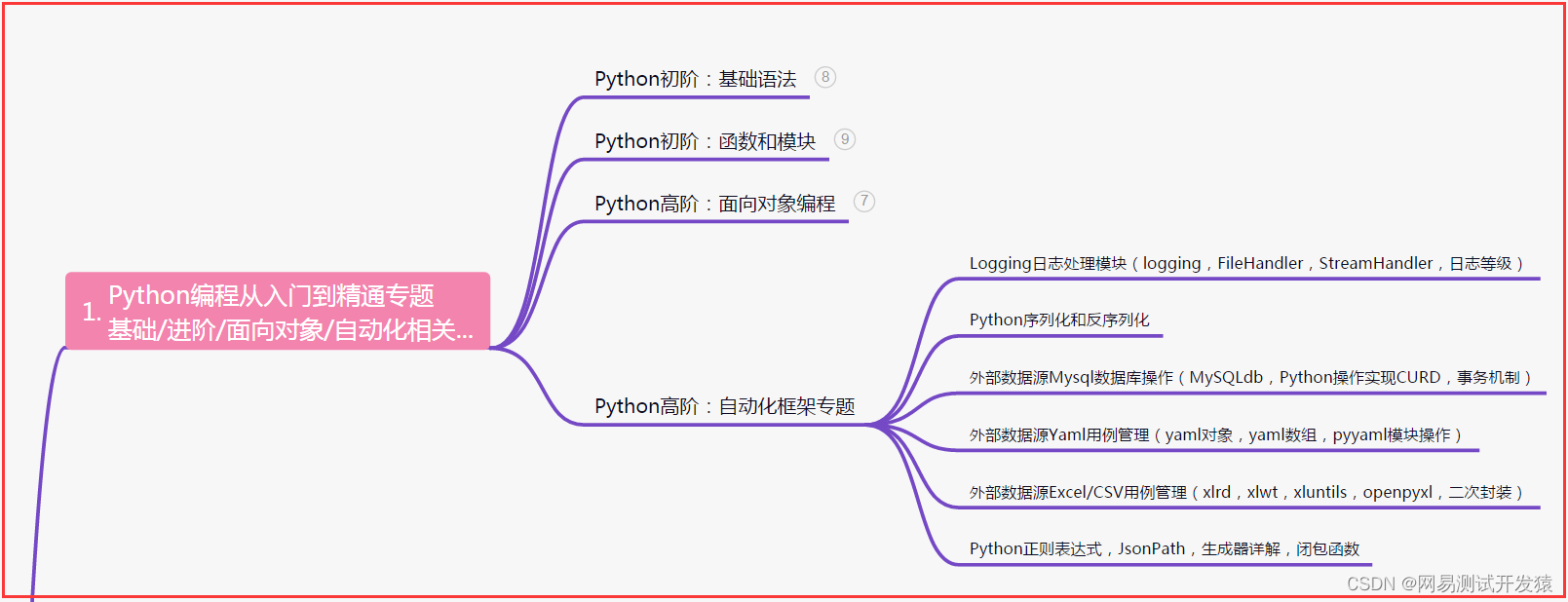
一、Python编程入门到精通
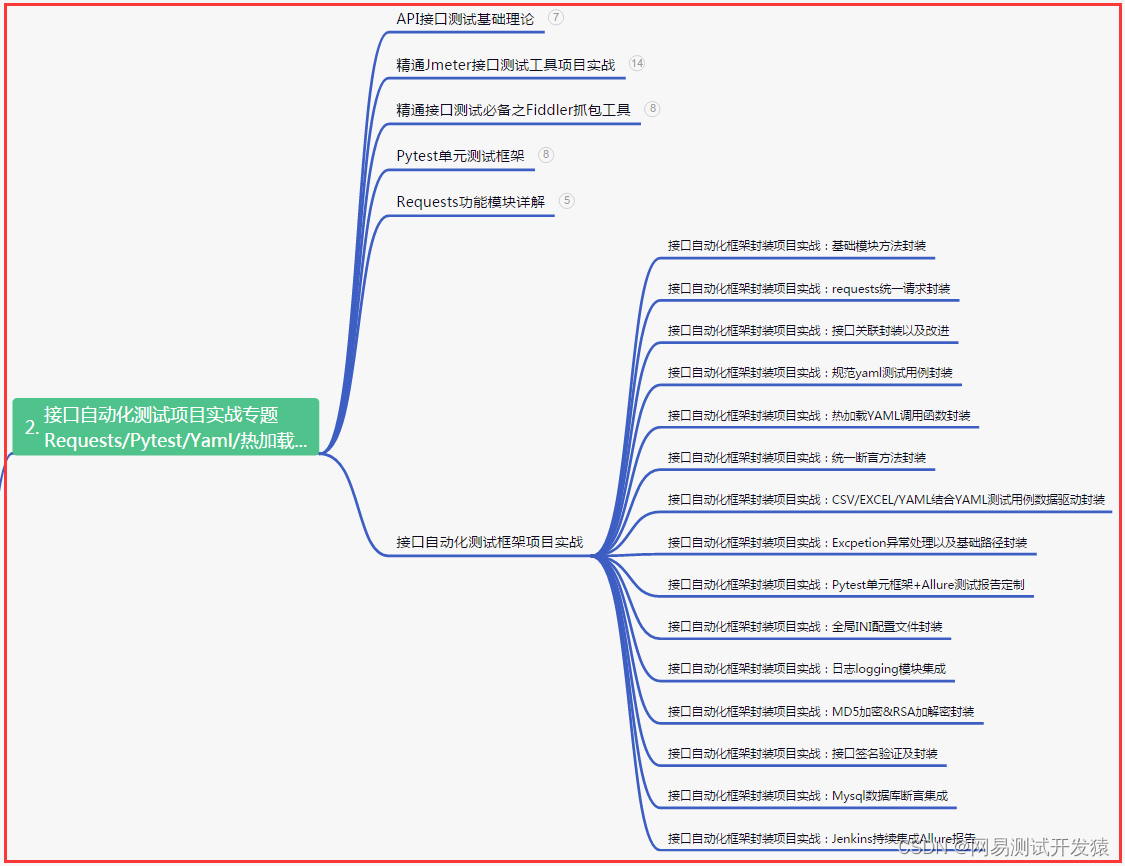
二、接口自动化项目实战
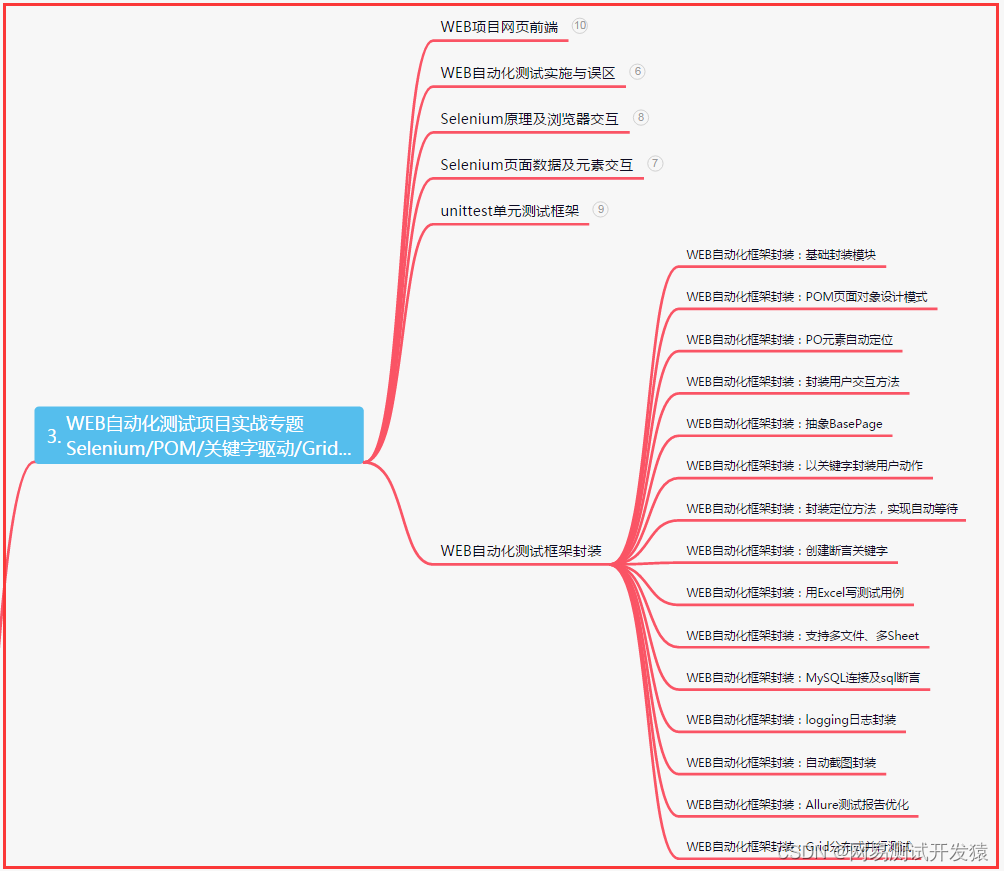
三、Web自动化项目实战
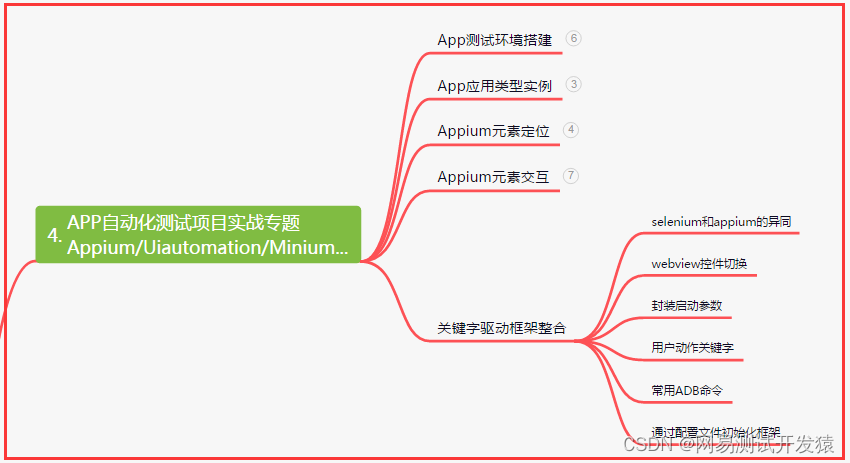
四、App自动化项目实战
五、一线大厂简历
六、测试开发DevOps体系
七、常用自动化测试工具

八、JMeter性能测试
九、总结(尾部小惊喜)
只要你肯努力,就没有什么是无法实现的。每一次奋斗和拼搏,都是为了成就更好的自己。所以,请勇敢向前,迎接挑战,不断超越自己!
相信自己,拼尽全力去追求梦想。道路不会一帆风顺,但只要坚持不懈、乐观向上,就一定能够战胜困难,实现自己的目标。
生命不息,奋斗不止。无论遇到什么挑战和困难,我们都要坚持、坚韧不拔地前行,用勇气和毅力去迎接未来的每一个日出和日落。