CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.HC
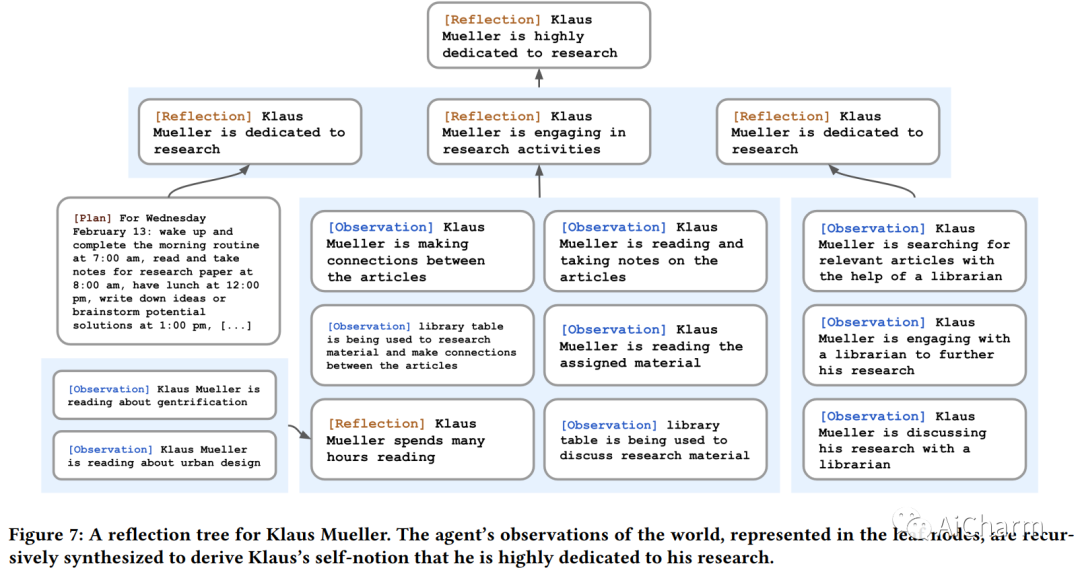
随着新的“生成代理”论文的发布,LLM刚刚达到了一个重要的里程碑——通过使用 LLM,生成代理能够在受《模拟人生》启发的交互式沙箱中模拟类人行为。代理架构扩展了语言模型,以存储代理使用自然语言的完整体验记录,随着时间的推移将这些记忆合成为更高级别的反射,并动态检索它们以规划行为。
它有三个组成部分:
1.记忆流,它记录了代理人经验的全面清单
2.反馈,随着时间的推移,将记忆综合为更高层次的推断
3.规划,将这些结论和当前环境转化为高层次的行动计划。
1.Generative Agents: Interactive Simulacra of Human Behavior

标题:生成代理:人类行为的交互式模拟
作者:Joon Sung Park, Joseph C. O'Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, Michael S. Bernstein
文章链接:https://arxiv.org/abs/2304.03442
项目代码:https://reverie.herokuapp.com/arXiv_Demo/



摘要:
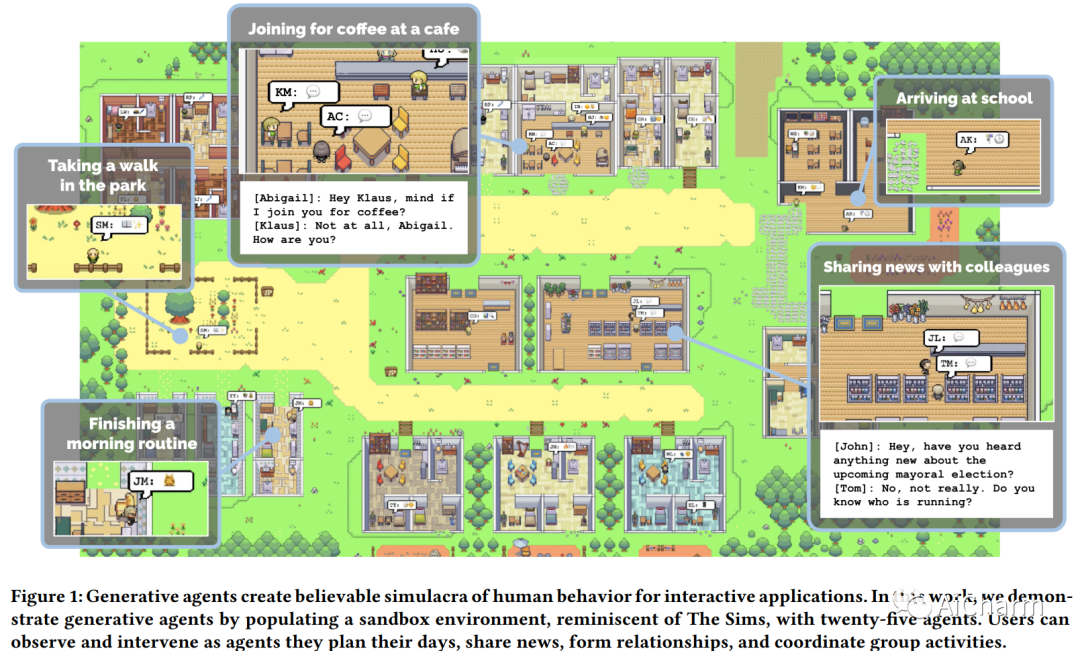
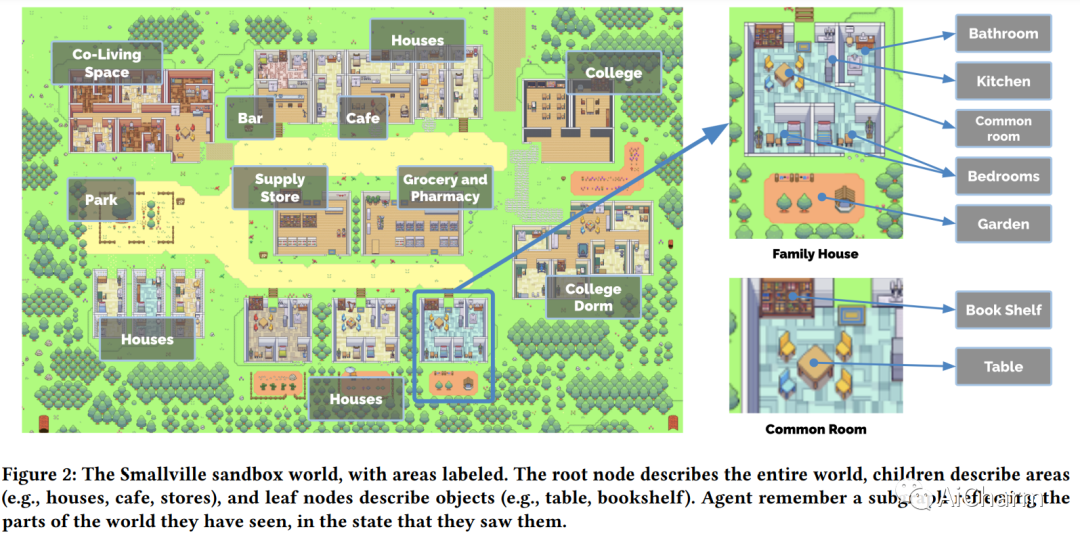
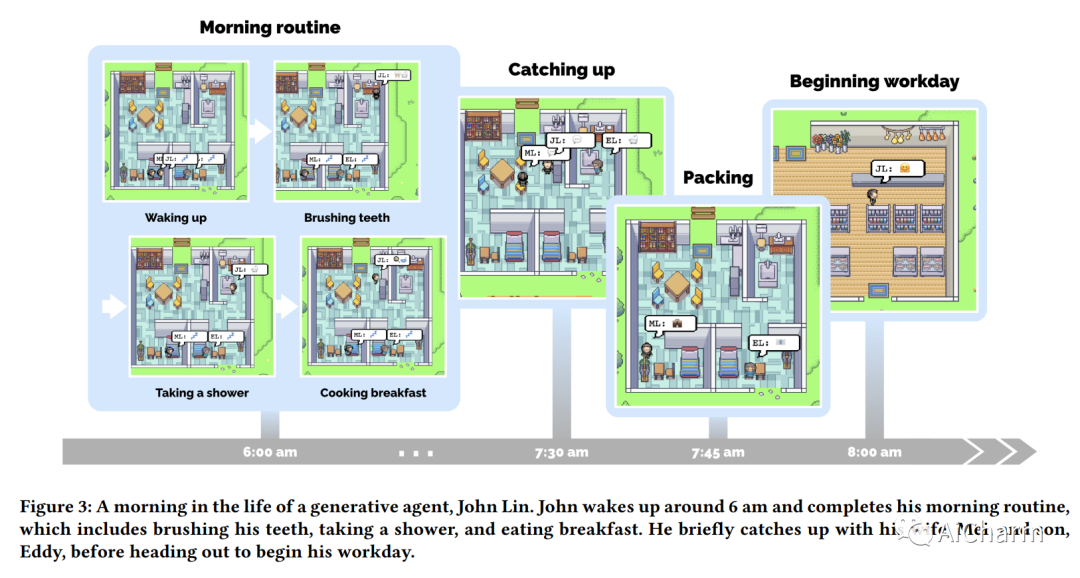
人类行为的可信代理可以增强交互式应用程序的能力,从沉浸式环境到用于人际交流的排练空间再到原型制作工具。在本文中,我们介绍了生成代理——模拟可信人类行为的计算软件代理。生成代理起床,做早餐,然后去上班;艺术家作画,作家写作;他们形成意见,互相注意,并发起对话;他们在计划第二天时会记住并反思过去的日子。为了启用生成代理,我们描述了一种架构,它扩展了一个大型语言模型,以存储代理使用自然语言的体验的完整记录,随着时间的推移将这些记忆合成为更高级别的反射,并动态检索它们以规划行为。我们实例化生成代理以填充受模拟人生启发的交互式沙箱环境,最终用户可以在其中使用自然语言与 25 个代理的小镇进行交互。在评估中,这些生成代理会产生可信的个人和紧急社会行为:例如,从只有一个用户指定的想法开始,即一个代理想要举办情人节派对,代理在接下来的两个时间里自动向派对发出邀请几天,结识新朋友,互相邀请参加聚会的日期,并协调在合适的时间一起出现在聚会上。我们通过消融证明了我们代理架构的组件——观察、规划和反思——每个组件都对代理行为的可信度做出了重要贡献。通过将大型语言模型与计算交互代理相融合,这项工作引入了架构和交互模式,以实现对人类行为的可信模拟。
2.OpenAGI: When LLM Meets Domain Experts

标题:OpenAGI:当 LLM 遇到领域专家
作者:Yingqiang Ge, Wenyue Hua, Jianchao Ji, Juntao Tan, Shuyuan Xu, Yongfeng Zhang
文章链接:https://arxiv.org/abs/2304.04370
项目代码:https://github.com/agiresearch/OpenAGI
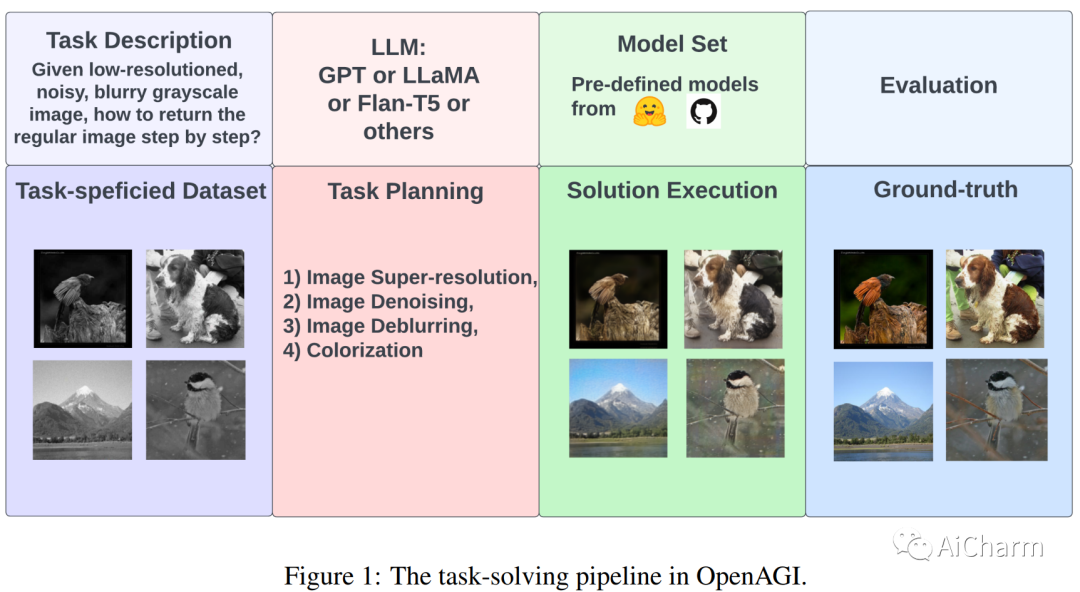
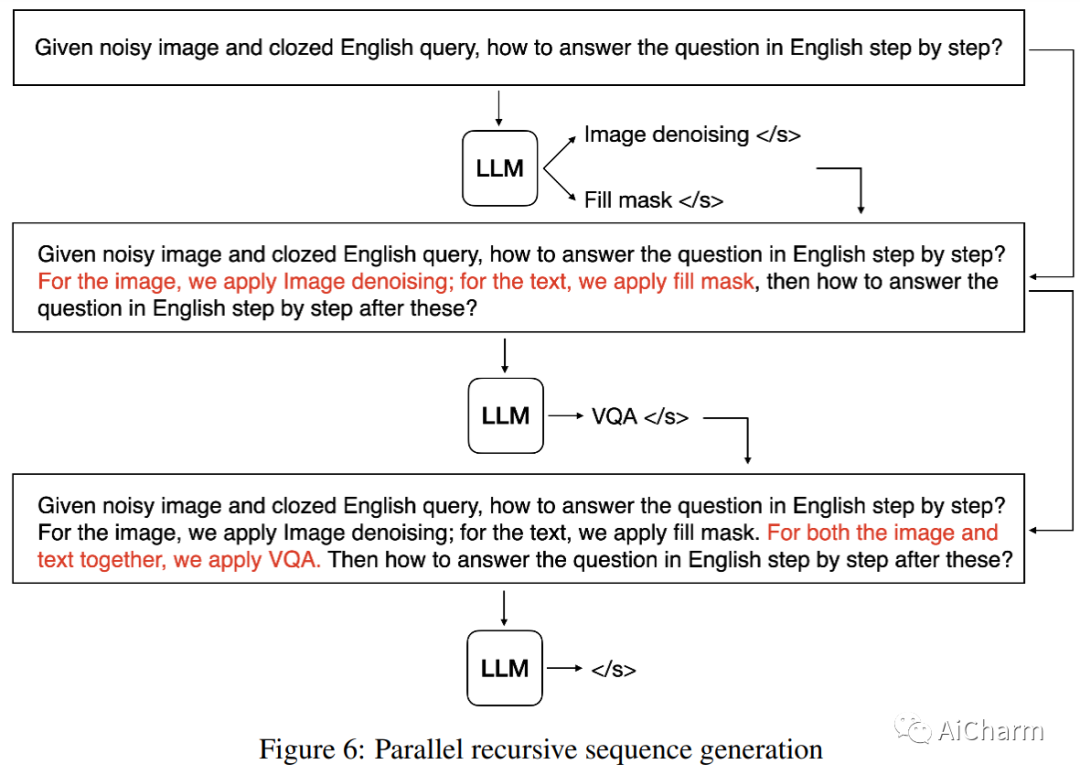
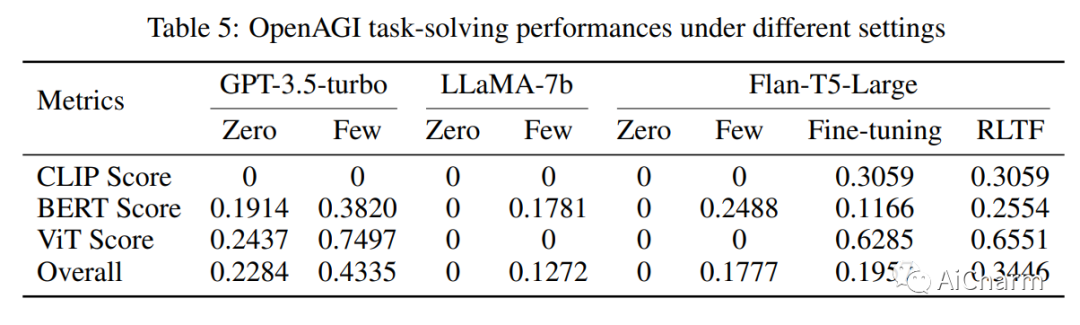
摘要:
人类智能具有将基本技能组合成复杂技能以解决复杂任务的非凡能力。这种能力对于人工智能 (AI) 同样重要,因此,我们断言,除了开发大型综合智能模型之外,让这些模型具备利用各种特定领域专家模型的能力同样重要在追求通用人工智能 (AGI) 过程中解决复杂的任务。大型语言模型 (LLM) 的最新发展展示了卓越的学习和推理能力,使其有望成为选择、综合和执行外部模型以解决复杂任务的控制器。在这个项目中,我们开发了 OpenAGI,这是一个开源 AGI 研究平台,专门设计用于提供复杂的多步骤任务,并附带特定于任务的数据集、评估指标和各种可扩展模型。OpenAGI 将复杂任务制定为自然语言查询,作为 LLM 的输入。LLM 随后选择、综合和执行 OpenAGI 提供的模型来解决任务。此外,我们提出了一种任务反馈强化学习(RLTF)机制,该机制使用任务解决结果作为反馈来提高 LLM 的任务解决能力。因此,LLM 负责综合各种外部模型来解决复杂的任务,而 RLTF 提供反馈以提高其任务解决能力,从而实现自我改进 AI 的反馈循环。我们认为,LLM 运行各种专家模型来解决复杂任务的范例是一种很有前途的 AGI 方法。为了便于社区对AGI能力的长期提升和评估,我们将OpenAGI项目的代码、基准测试和评估方法开源在这个https地址。
3.Inference with Reference: Lossless Acceleration of Large Language Models

标题:参考推理:大型语言模型的无损加速
作者:Nan Yang, Tao Ge, Liang Wang, Binxing Jiao, Daxin Jiang, Linjun Yang, Rangan Majumder, Furu Wei
文章链接:https://arxiv.org/abs/2304.04487

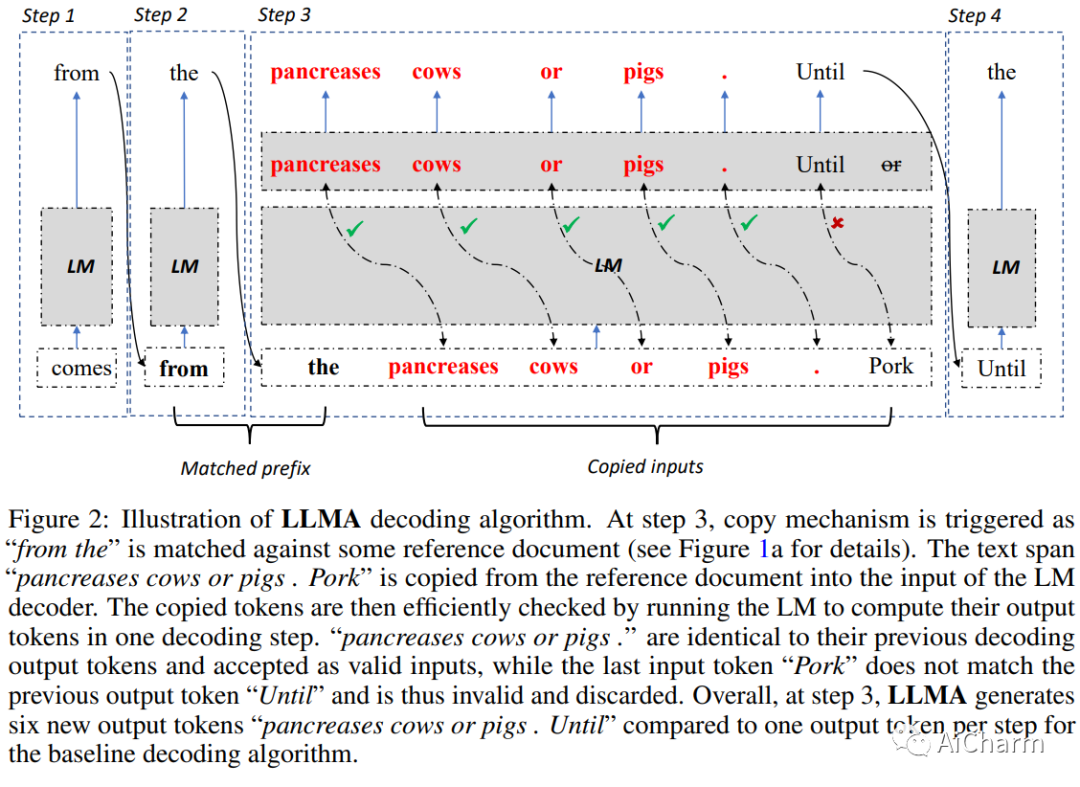


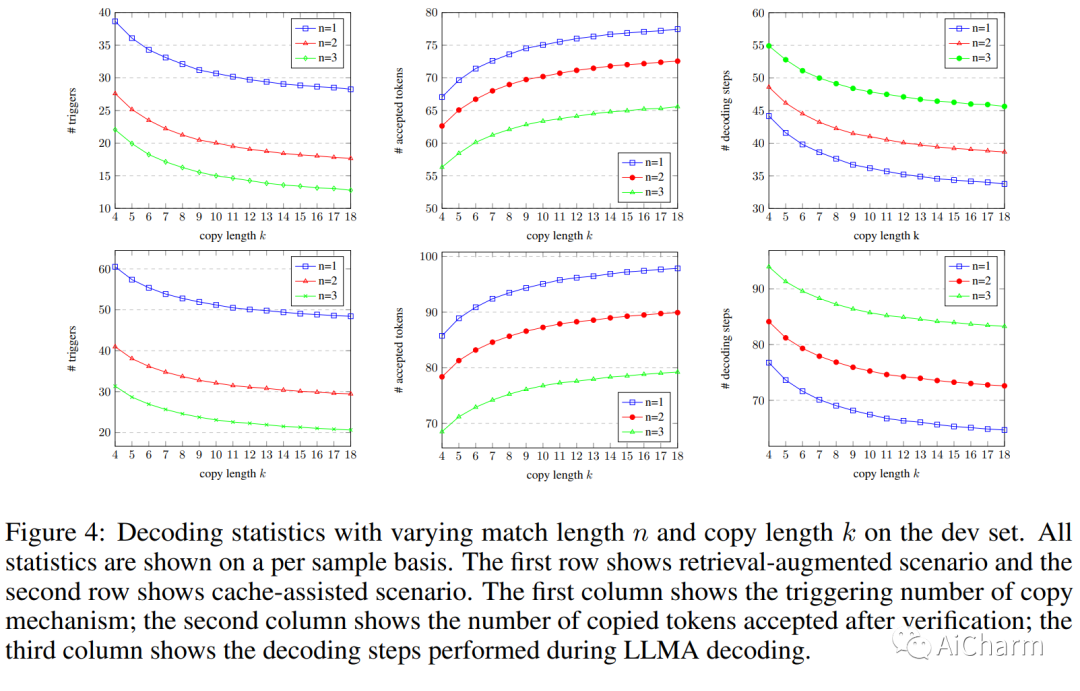
摘要:
我们提出了 LLMA,这是一种 LLM 加速器,可以无损地加速带有引用的大型语言模型 (LLM) 推理。LLMA 的动机是观察到在 LLM 的解码结果和许多现实世界场景(例如,检索到的文档)中可用的参考之间存在大量相同的文本跨度。LLMA 首先从参考中选择一个文本跨度并将其标记复制到解码器,然后在一个解码步骤中并行有效地检查标记作为解码结果的适当性。改进的计算并行性允许 LLMA 实现超过 2 倍的 LLM 加速,并且在许多实际生成场景中具有与贪婪解码相同的生成结果,在这些场景中上下文参考和输出之间存在显着重叠(例如,搜索引擎和多轮对话)。
更多Ai资讯:公主号AiCharm