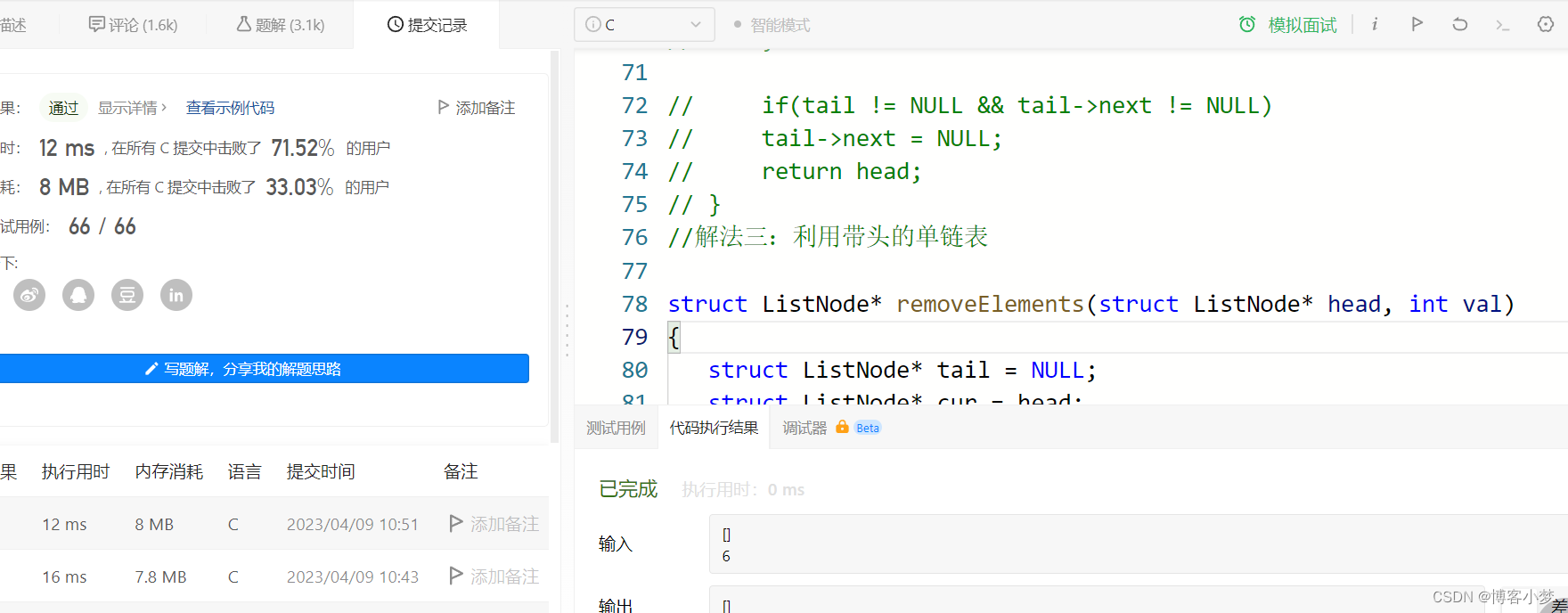
然后我们看如何把mysql中的数据,实时的同步到hdfs中去

准备工作首先,创建一个mysql表,然后启动hadoop集群
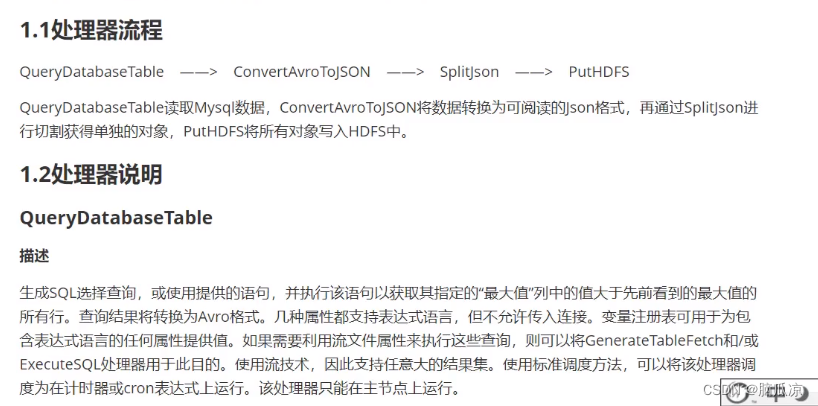
处理器我们需要这些处理器,首先通过querydatabasetable处理器,查询mysql中的数据,然后,把mysql中的数据,导入到
convertavrotojson处理器,注意querydatabasetable处理器,导出来的数据是avro格式的数据,然后再用
convertavrotojson把avro格式转换成json格式,然后再用splitjson,切割json数据,提取json中的数据,到splitjson的自定义属性中,然后再
用puthdfs处理器,提取splitjson切割好的,提取好的数据,拼接到puthdfs的命令中,就可以提交数据到hdfs中了
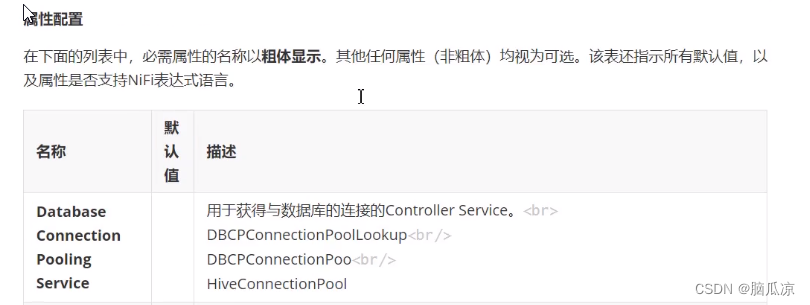
先看一下这个querydatabasetable处理器的熟悉,可以看到
首先需要一个database connection pooling service 需要一个数据库连接池
这里提供