🎉🎉🎉点进来你就是我的人了
博主主页:🙈🙈🙈戳一戳,欢迎大佬指点!
人生格言:当你的才华撑不起你的野心的时候,你就应该静下心来学习!欢迎志同道合的朋友一起加油喔🦾🦾🦾
目标梦想:进大厂,立志成为一个牛掰的Java程序猿,虽然现在还是一个🐒嘿嘿
谢谢你这么帅气美丽还给我点赞!比个心

目录
1.启动MySQL,备份数据:
2.数据库表列类型
1.整数类型
2.浮点数类型
3.字符串类型
4.日期和时间类型
3.数据库术语及操作
3.1.DDL 操作数据库和表
3.1.1 操作数据库
3.1.2 操作数据表
3.1.3 操作数据列
3.2 DML对数据进行增删改(insert,delete,update)
3.3 DQL 查询数据(select)
3.3.1 基本语法语法:(顺序固定,不可以改变顺序)
查询限制条件总结
单行函数
聚合函数(多行函数):
(group by)分组查询
where和Having区别:
3.3.2 连接查询
内连接
外连接:
自连接
全外连接
3.3.3 子查询
3.3.4 多表查询
3.4 DCL 授权,权限和安全访问
3.5表的完整性约束
(二)唯一约束
(三)非空约束
(四)默认值约束
(五)字段值自增长约束
(七)级联操作(更新/删除):
1.启动MySQL,备份数据:
- cmd 命令行启动/关闭mysql服务:net start/stop mysql(以管理员身份运行)
-
命令行输入 :
mysql -u root -p
passward:root
1.2.2 远程登录别人的MySQL服务(需要设置配置文件)
- mysql -hip(ip地址,例本机127.0.0.1)-uroot -p(连接目标的密码)
- quit/exit
- 备份sql文件:mysqldump -uroot -p密码 备份数据库的名称 > 路径(例:mysqldump -u root -p用户密码 --databases dbname > mysql.dbname )
- 还原/执行sql文件:source sql文件路径
2.数据库表列类型
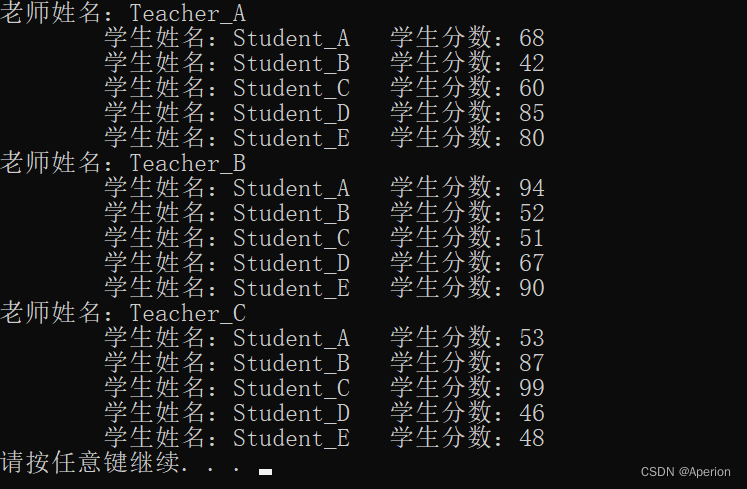
1.整数类型
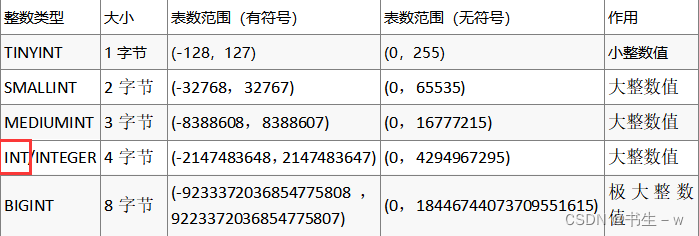
MySQL支持选择在该类型关键字后面的括号内指定整数值的显示宽度(例如,INT(4))。显示宽度并不限制可以在列内保存的值的范围,也不限制超过列的指定宽度的值的显示
主键自增:不使用序列,通过auto_increment,要求是整数类型
2.浮点数类型
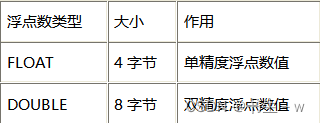
需要注意的是与整数类型不一样的是,浮点数类型的宽度不会自动扩充。 score double(4,1)
score double(4,1)--小数部分为1位,总宽度4位,并且不会自动扩充。
3.字符串类型
 CHAR和VARCHAR类型相似,均用于存于较短的字符串,主要的不同之处在于存储方式。CHAR类型长度固定,VARCHAR类型的长度可变。
CHAR和VARCHAR类型相似,均用于存于较短的字符串,主要的不同之处在于存储方式。CHAR类型长度固定,VARCHAR类型的长度可变。
因为VARCHAR类型能够根据字符串的实际长度来动态改变所占字节的大小,所以在不能明确该字段具体需要多少字符时推荐使用VARCHAR类型,这样可以大大地节约磁盘空间、提高存储效率。
CHAR和VARCHAR表示的是字符的个数,而不是字节的个数
4.日期和时间类型

TIMESTEMP类型的数据指定方式与DATETIME基本相同,两者的不同之处在于以下几点:
(1) 数据的取值范围不同,TIMESTEMP类型的取值范围更小。
(2) 如果我们对TIMESTAMP类型的字段没有明确赋值,或是被赋与了NULL值,MySQL会自动将该字段赋值为系统当前的日期与时间。
(3) TIMESTEMP类型还可以使用CURRENT_TIMESTAMP来获取系统当前时间。
(4) TIMESTEMP类型有一个很大的特点,那就是时间是根据时区来显示的。例如,在东八区插入的TIMESTEMP数据为2017-07-11 16:43:25,在东七区显示时,时间部分就变成了15:43:25,在东九区显示时,时间部分就变成了17:43:25。
3.数据库术语及操作
SQL语言分为五个部分:
数据查询语言(Data Query Language,DQL):DQL主要用于数据的查询,其基本结构是使用SELECT子句,FROM子句和WHERE子句的组合来查询一条或多条数据。
数据操作语言(Data Manipulation Language,DML):DML主要用于对数据库中的数据进行增加、修改和删除的操作,其主要包括:
(1) INSERT:增加数据
(2) UPDATE:修改数据
(3) DELETE:删除数据
数据定义语言(Data Definition Language,DDL):DDL主要用针对是数据库对象(数据库、表、索引、视图、触发器、存储过程、函数)进行创建、修改和删除操作。其主要包括:
(1) CREATE:创建数据库对象
(2) ALTER:修改数据库对象
(3) DROP:删除数据库对象
数据控制语言(Data Control Language,DCL):DCL用来授予或回收访问 数据库的权限,其主要包括:
(1) GRANT:授予用户某种权限
(2) REVOKE:回收授予的某种权限
事务控制语言(Transaction Control Language,TCL):TCL用于数据库的事务管理。其主要包括:
(1) START TRANSACTION:开启事务
(2) COMMIT:提交事务
(3) ROLLBACK:回滚事务
(4) SET TRANSACTION:设置事务的属性
3.1.DDL 操作数据库和表
(Create,Retrieve(查询),update,Delete)操作数据库和表
3.1.1 操作数据库
- 显示所有数据库:show databases;
- 显示创建的数据库:show create database 数据库名称;
- 创建一个数据库: create database 数据库名称;
- 创建数据库前先判断是否存在:create database if not exists 数据库名称;
- 创建数据库并设置字符编码格式:create database 数据库名 character set gbk;
- 修改数据库的字符集:alter database 数据库名称 character set 字符集名称(utf8);
- 删除一个数据库:drop database 数据库名;
- (drop database if exists 数据库名称; 先判断是否存在数据库,存在再删除删除库)
- 切换数据库:use 数据库名称;
- 查询现在正在使用的数据库:select database();
3.1.2 操作数据表
- 单行注释: #…
- 多行注释: /*…*/
- 查询某个数据库的所有表的名称: show tables;
- 查询表结构:desc 表名;
- 创建表:create table 表名(列名1 数据类型1 ,列名2,数据类型2…);
- 复制表:create table 表名1 like 表名2;
- 修改表名:alter table 表名 rename to 新的表名;
- 显示表的字符创建信息: show create table 表名;
- 修改表的字符集:alter table 表名 character set 字符集;
- 清空表的数据: delete from 表名;
- 删除表:drop table if exists 表名;(先判断表是否存在,存在再删除)
3.1.3 操作数据列
- 添加一列:alter table 表名 add 列名 数据类型;
- 删除一列:alter table 表名 drop 列名;
- 增加多列:alter table 表名 add(xh int(4),zc char(8),ads char(50),);
- 删除多列:alter table 表名 drop xh,zc,ads;
- 同时修改列名称和列数据类型:alter table 表名 change 旧列名 新列名 数据类型;
- 只修改列数据类型: alter table 表名 modify 列名 数据类型;
SQL演示
-- 查看数据:
select * from t_student;
-- 修改表的结构:
-- 增加一列:
alter table t_student add score double(5,2) ; -- 5:总位数 2:小数位数
update t_student set score = 123.5678 where sno = 1 ;
-- 增加一列(放在最前面)
alter table t_student add score double(5,2) first;
-- 增加一列(放在sex列的后面)
alter table t_student add score double(5,2) after sex;
-- 删除一列:
alter table t_student drop score;
-- 修改一列:
alter table t_student modify score float(4,1); -- modify修改是列的类型的定义,但是不会改变列的名字
alter table t_student change score score1 double(5,1); -- change修改列名和列的类型的定义
-- 删除表:
drop table t_student;3.2 DML对数据进行增删改(insert,delete,update)
- 添加数据:insert into 表名(列名1,列名2…) values(....),(.....).....;
- 删除数据:delete from 表名 where 条件;
- 删除全部记录:delete from 表名;
- 删除表并创建一个同名的空表(效率更高):truncate table 表名;
- 修改数据:update 表名 set 列名1=值1,列名2=值2 where 条件
注意事项
1.int 宽度是显示宽度,如果超过,可以自动增大宽度 int底层都是4个字节
2.时间的方式多样 '1256-12-23' "1256/12/23" "1256.12.23"
3.字符串不区分单引号和双引号
4.如何写入当前的时间 now() , sysdate() , CURRENT_DATE()
5.char varchar 是字符的个数,不是字节的个数,可以使用binary,varbinary表示定长和不定长的字节个数。
6.如果不是全字段插入数据的话,需要加入字段的名字
7.关键字,表名,字段名不区分大小写
8.默认情况下,内容不区分大小写
9.删除操作from关键字不可缺少10.修改,删除数据别忘记加限制条件
11.给表起别名时加不加as都可以,别名可以加引号也可以不加引号,但是别名中间有特殊字符必须加引号(比如中间有空格)
delete和truncate的区别:
从最终的结果来看,虽然使用TRUNCATE操作和使用DELETE操作都可以删除表中的全部记录,但是两者还是有很多区别的,其区别主要体现在以下几个方面:
(1)DELETE为数据操作语言DML;TRUNCATE为数据定义语言DDL。
(2) DELETE操作是将表中所有记录一条一条删除直到删除完;TRUNCATE操作则是保留了表的结构,重新创建了这个表,所有的状态都相当于新表。因此,TRUNCATE操作的效率更高。
(3)DELETE操作可以回滚;TRUNCATE操作会导致隐式提交,因此不能回滚
(4)DELETE操作执行成功后会返回已删除的行数(如删除4行记录,则会显示“Affected rows:4”);截断操作不会返回已删除的行量,结果通常是“Affected rows:0”。DELETE操作删除表中记录后,再次向表中添加新记录时,对于设置有自增约束字段的值会从删除前表中该字段的最大值加1开始自增;TRUNCATE操作则会重新从1开始自增。
SQL演示
-- 查看表记录:
select * from t_student;
-- 在t_student数据库表中插入数据:(添加数据)
insert into t_student values (1,'张三','男',18,'2022-5-8','软件1班','123@126.com');
insert into t_student values (10010010,'张三','男',18,'2022-5-8','软件1班','123@126.com');
insert into t_student values (2,'张三','男',18,'2022.5.8','软件1班','123@126.com');
insert into t_student values (2,"张三",'男',18,'2022.5.8','软件1班','123@126.com');
insert into t_student values (7,"张三",'男',18,now(),'软件1班','123@126.com');
insert into t_student values (9,"易烊千玺",'男',18,now(),'软件1班','123@126.com');
insert into t_student (sno,sname,enterdate) values (10,'李四','2023-7-5');
-- 修改表中数据
update t_student set sex = '女' ;
update t_student set sex = '男' where sno = 10 ;
UPDATE T_STUDENT SET AGE = 21 WHERE SNO = 10;
update t_student set CLASSNAME = 'java01' where sno = 10 ;
update t_student set CLASSNAME = 'JAVA01' where sno = 9 ;
update t_student set age = 29 where classname = 'java01';
-- 删除操作:
delete from t_student where sno = 2;3.3 DQL 查询数据(select)
3.3.1 基本语法语法:(顺序固定,不可以改变顺序)
select 字段1,字段2....(字段列表)
from 表一,表二....(表名列表)
where 条件1,条件2...(条件列表)
group by 分组字段
having 分组之后的条件
order by 按什么字段排序
limit 6 分页限定
-
查询所有信息:select * from 表名;
-
查询限制条件总结
- 逻辑运算符:and:同时满足(优先级大于or) or:满足任意条件即可
-
(distinct)去除相同的数据:如 :select distinct 列名 from student;
-
(between and)之间(闭区间):如 :select * from stu where age between 20 and 30;
-
(in/not in)集合之中:select * from stu where age in(18,19,20);
-
在查询中使用列的别名: select 列名 *AS 新列名 form 表名 where 查询条件;*
-
(null)查询: select * from stu where id is null /is not null;
-
(like)模糊查询: select * from 表名 where 字段名 like 对应值(子串)
-
'*'或者'_'代表单个任意字符, %代表多个任意字符
-
查询学好1开头的学生:select * from stu id like “1%”;
-
-
(order by)排序(可叠加):select * from stu order by math asc/desc,english asc;(desc降序)
单行函数
单行函数是指对每一条记录输入值进行计算,并得到相应的计算结果,然后返回给用户,也就是说,每条记录作为一个输入参数,经过函数计算得到每条记录的计算结果。
-- 1.字符串函数
select ename,length(ename),substring(ename,2,3) from emp;
-- substring字符串截取,2:从字符下标为2开始,3:截取长度3 (下标从1开始)
-- 2.数值函数
select abs(-5),ceil(5.3),floor(5.9),round(3.14) from dual; -- dual实际就是一个伪表
select abs(-5) 绝对值,ceil(5.3) 向上取整,floor(5.9) 向下取整,round(3.14) 四舍五入; -- 如果没有where条件的话,from dual可以省略不写
select ceil(sal) from emp;
select 10/3,10%3,mod(10,3) ;
-- 3.日期与时间函数
select * from emp;
select curdate(),curtime() ; -- curdate()年月日 curtime()时分秒
select now(),sysdate(),sleep(3),now(),sysdate() from dual; -- now(),sysdate() 年月日时分秒
insert into emp values (9999,'lili','SALASMAN',7698,now(),1000,null,30);
-- now()可以表示年月日时分秒,但是插入数据的时候还是要参照表的结构的
聚合函数(多行函数):
对一组数据进行运算,针对一组数据(多行记录)只返回一个结果,也称分组函数
COUNT() 统计表中记录的数目
SUM() 计算指定字段值的总和
AVG() 计算指定字段值的平均值
MAX() 统计指定字段值的最大值
MIN() 统计指定字段值的最小值
-- 多行函数自动忽略null值
count函数 : select count(ifnull(name,0)) from stu;(自动排除null)
count(*)代表表中有多少行数据,ifnull代表如果是null就是括号里第一个,否则第二个
-- max(),min(),count()针对所有类型 sum(),avg() 只针对数值型类型有效
select max(ename),min(ename),count(ename),sum(ename),avg(ename) from emp;
注意:
-- 字段和多行函数不可以同时使用
select deptno,avg(sal) from emp;
-- 字段和多行函数不可以同时使用,除非这个字段属于分组
select deptno,avg(sal) from emp group by deptno;
(group by)分组查询
-
GROUP BY 子句用于将结果集中的行按一个或多个列进行分组。分组后,可以对每个分组应用聚合函数,例如计算每个分组的 COUNT()、SUM()、AVG()、MIN() 或 MAX()。
-
基本语法:select 字段名列表 form 表名 where 约束条件 group by分组的字段名
如:select sex avg(math) from stu group by sex; 查询男女的平均分
-
limit 分页查询:select * from stu limit 3;(3条数据)
-
where和Having区别:
- where在分组之前过滤数据,having在分组之后过滤数据)
- where后不可以跟聚合函数,having后可以跟聚合函数
1.select sex,avg(math) from stu where math>70 group by sex;(分数>70分(分组之前))
2.select sex,avg(math),count(id) from stu where math>70 group by sex having count(id);(分数>70分 人数>2(分组之后))
3.3.2 连接查询
内连接
- 隐式内联:select * from emp,dept where dept.id=emp.id;
- 显式内联:select * from emp inner join dept on emp.id=dept.id; (inner可省略)
外连接:
外连接查询中参与连接的表有主从之分,已主表的每行数据匹配从表的数据列,将符合连接条件的数据直接返回到结果集中,对不符合连接条件的列,将被填上null值再返回到结果集中。
-
左外连接(查询的是左表的所有记录或交集),右边没有的会填充null;
如 : select ....... from emp as t1 left join dept as t2 on t1.id=t2.id;
-
右外连接(右外连接包含右表中所有的匹配行,右表中有的项在左表中没有对应的项将以null值填充)。
如: select ....... from emp as t1 right join dept as t2 on t1.id=t2.id;
自连接
select ... from 表1 join 表1 on 条件
例:select ....... from emp as t1 join emp as t2 on t1.id=t2.id;全外连接
mysql中不支持全外连接,但是可以使用union实现
-- 解决mysql中不支持全外连接的问题:
select * from emp eleft outer join dept don e.deptno = d.deptno
union -- 并集 去重 效率低
select * from emp eright outer join dept don e.deptno = d.deptno;
select * from emp eleft outer join dept don e.deptno = d.deptno
union all-- 并集 不去重 效率高
select * from emp eright outer join dept don e.deptno = d.deptno;
-- mysql中对集合操作支持比较弱,只支持并集操作,交集,差集不支持(oracle中支持)
-- outer可以省略不写
3.3.3 子查询
什么是子查询?
一条SQL语句含有多个select,不相关的子查询:子查询可以独立运行,先运行子查询,再运行外查询. (容易理解)
相关子查询:子查询不可以独立运行,并且先运行外查询,再运行子查询. (难理解)一些使用不相关子查询不能实现或者实现繁琐的子查询,可以使用相关子查询实现
select ... from 表1 where 字段1 = (select ... from ...);SQL演示
-- 【1】查询最高工资的员工 (不相关子查询)
select * from emp where sal = (select max(sal) from emp)
-- 【2】查询本部门最高工资的员工 (相关子查询)
-- 方法1:通过不相关子查询实现:
select * from emp where deptno = 10 and sal = (select max(sal) from emp where deptno = 10)
union
select * from emp where deptno = 20 and sal = (select max(sal) from emp where deptno = 20)
union
select * from emp where deptno = 30 and sal = (select max(sal) from emp where deptno = 30)
-- 缺点:语句比较多,具体到底有多少个部分未知
-- 方法2: 相关子查询
select * from emp e where sal = (select max(sal) from emp where deptno = e.deptno) order by deptno
-- 【3】查询工资高于其所在岗位的平均工资的那些员工 (相关子查询)
-- 不相关子查询:
select * from emp where job = 'CLERK' and sal >= (select avg(sal) from emp where job = 'CLERK')
union ......
-- 相关子查询:
select * from emp e where sal >= (select avg(sal) from emp e2 where e2.job = e.job)3.3.4 多表查询
-- 查询员工的编号、姓名、薪水、部门编号、部门名称、薪水等级
select * from emp;
select * from dept;
select * from salgrade;
select e.ename,e.sal,e.empno,e.deptno,d.dname,s.*
from emp e
right outer join dept d
on e.deptno = d.deptno //外连接关联两张表查询
inner join salgrade s //内连接关联第三张表查询
on e.sal between s.losal and s.hisal先实现两表查询,再三表查询,套娃即可
3.4 DCL 授权,权限和安全访问
-
创建用户:create user ‘用户名’@‘主机名(%未任意主机)’ identified by ‘密码’;
-
删除用户:drop user ‘用户名’@‘主机名’;
-
修改用户密码:update user set password = password(‘新密码’) where user = ‘用户名’;
set password for ‘用户名’@‘主机名’ where user=‘用户名’;
-
查用户的权限:show Grants for ‘用户名’@‘主机名’;
-
授予权限:grant 权限列表 to ‘用户名’@‘主机名’;
权限列表:delete,update,select on stu -
授予所有权限在任意数据库和表,grant all on . to ‘用户名’@‘主机名’;
-
撤销权限:revoke 权限列表 on 数据库名.表名 from ‘用户名’@‘主机名’;
3.5表的完整性约束
为防止不符合规范的数据存入数据库,在用户对数据进行插入、修改、删除等操作时,MySQL提供了一种机制来检查数据库中的数据是否满足规定的条件,以保证数据库中数据的准确性和一致性,这种机制就是完整性约束。
MySQL中主要支持以下几种种完整性约束,如表所示。 其中Check约束是MySQL8中提供的支持。

(一)主键约束
create table 数据表名 (字段名1 数据类型 primary key,......);
2、在已存在的表中添加主键约束
alter table 数据表名 add primary key (字段名1, 字段名2,....);
3、删除主键约束
alter table 数据表名 drop primary key;
(二)唯一约束
create table 数据表名 (字段名1 数据类型 unique, );
2、在已存在的表中添加唯一约束
alter table 数据表名 add unique (字段名1, 字段名2,....);
3、删除唯一约束
alter table 数据表名 drop index 字段名;
(三)非空约束
create table 数据表名 (字段名 字段类型 not null,...);
2、在已存在的表中添加非空约束
alter table 数据表名 modify 字段名 数据类型 not null;
3、删除非空约束
alter table 数据表名 modify 字段名 数据类型 (null); //null可写可不写
(四)默认值约束
create table 数据表名 (字段名 数据类型 default value,....);
2、在已存在的表中添加默认值约束
alter table 数据表名 modify 字段名 数据类型 default value;
3、删除默认值约束
alter table 数据表名 modify 字段名 数据类型;
(五)字段值自增长约束
create table 数据表名 (字段名 数据类型 auto_increment);
2、在已存在表中添加自增长约束
alter table 数据表名 modify 字段名 数据类型 auto_increment;
alter table 数据表名 modify 字段名 数据类型;
(六)外键约束
- “child_数据表名”为新建表的名称(从表),fk_name为外键约束名,“parent_字段名”为主表中被参照的字段,"child_字段名"为被设置的外键,[constraint fk_name] 是给外键设置外键约束名,可写可不写,方便报错快速定位是哪个外键报错.
create table child_数据表名 (字段名1 数据类型,字段名2 数据类型,...
[constraint fk_name] foreign key (child_字段名) references 数据表名 (parent_字段名) );
alter table child_数据表名 add foreign key (child_字段名)
references 数据表 parent_数据表名(parent_字段名) );
3、删除外键约束
- “child_数据表名”为要删除外键约束的从表名,fk_name为外键约束名
alter table child_数据表名 drop foreign key fk_name;
(七)级联操作(更新/删除):
cascade 级联操作:操作主表的时候影响从表的外键信息:
alter table 表名 add constraint 外键名称 foreign key(外键列名称) references 主表名称(主表列名称)on update cascade on delete cascade;
SQL演示:
-- 先创建父表:班级表:
create table t_class(
cno int(4) primary key auto_increment,
cname varchar(10) not null,
room char(4)
)
-- 可以一次性添加多条记录:
insert into t_class values (null,'java001','r803'),(null,'java002','r416'),(null,'大数据001','r103');
-- 添加学生表,添加外键约束:
create table t_student(
sno int(6) primary key auto_increment,
sname varchar(5) not null,
classno int(4),-- 取值参考t_class表中的cno字段,不要求字段名字完全重复,但是类型长度定义 尽量要求相同。
constraint fk_stu_classno foreign key (classno) references t_class (cno)
);
-- 可以一次性添加多条记录:
insert into t_student values (null,'张三',1),(null,'李四',1),(null,'王五',2),(null,'朱六',3);
-- 查看班级表和学生表:
select * from t_class;
select * from t_student;
-- 删除班级2:如果直接删除的话肯定不行因为有外键约束:
-- 加入外键策略:
-- 策略1:no action 不允许操作
-- 通过操作sql来完成:
-- 先把班级2的学生对应的班级 改为null
update t_student set classno = null where classno = 2;
-- 然后再删除班级2:
delete from t_class where cno = 2;
-- 策略2:cascade 级联操作:操作主表的时候影响从表的外键信息:
-- 先删除之前的外键约束:
alter table t_student drop foreign key fk_stu_classno;
-- 重新添加外键约束:
alter table t_student add constraint fk_stu_classno foreign key (classno) references t_class (cno) on update cascade on delete cascade;
-- 试试更新:
update t_class set cno = 5 where cno = 3;
-- 试试删除:
delete from t_class where cno = 5;
-- 策略3:set null 置空操作:
-- 先删除之前的外键约束:
alter table t_student drop foreign key fk_stu_classno;
-- 重新添加外键约束:
alter table t_student add constraint fk_stu_classno foreign key (classno) references t_class (cno) on update set null on delete set null;
-- 试试更新:
update t_class set cno = 8 where cno = 1;
-- 注意:
-- 1. 策略2 级联操作 和 策略2 的 删除操作 可以混着使用:
alter table t_student add constraint fk_stu_classno foreign key (classno) references t_class (cno) on update cascade on delete set null ;
-- 2.应用场合:
-- (1)朋友圈删除,点赞。留言都删除 -- 级联操作
-- (2)解散班级,对应的学生 置为班级为null就可以了,-- set null