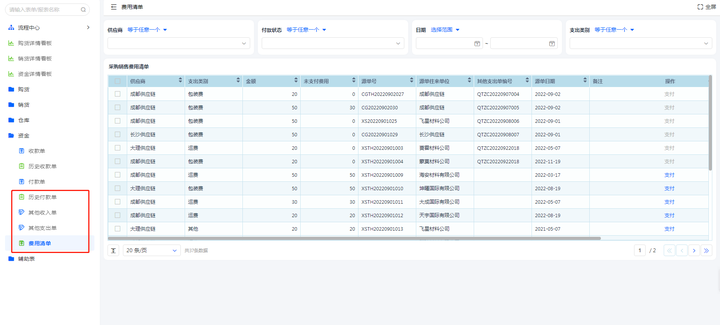
目录
9.1.1 理解字符串
9.1.2 字符串的类型名
9.1.3 字符的数字编码
9.1.4 常用的字符编码
9.1.5 字符串的默认编码
9.1.6 字符串的编码与解码
9.1.7 转义字符详解
9.1.8 对字符串进行遍历
9.1.9 知识要点
9.1.10 系统学习python
9.1.1 理解字符串
理解字符串,不仅要知道它是什么,还要知道它底层的数据结构。
那么,什么是字符串?
在Python中使用英文引号括住的都是字符串,以下的都为字符串:
Python
# 英文中的引号为单引号,双引号,三引号
chinese = "我爱你"
english = 'I Love You'
japanese = '''君のことを愛している'''
russian = """я люблю тебя"""
字符串是一种线性的序列结构。理解这种数据结构,先直接看图:

上图表示的是字符串"我一直深爱着你",从图中可以看出,字符与字符之间是直线的关系,字符是按序进行排列的,所有的字符空间对应着一块连续的内存,这种结构就叫做线性的序列结构。图中的每一个格子表示一个内存块,内存块里存储了字符的数字编码。
对于这种线性的序列结构,可以通过索引访问数据集合中的每一个元素。在Python中,索引从0开始编号。例如编号0对应的是字符'我',编号1对应的是字符'一',以此类推。
感兴趣的同学可以系统地学习数据结构这门课程。成为一名卓越的程序员,必须掌握数据结构这门知识。薯条老师在后面的教程中会推出数据结构的系列课。
9.1.2 字符串的类型名
在交互模式中通过type来输出字符串的类型名:
>>> chinese = "我爱你" >>> english = 'I Love You' >>> japanese = '''君のことを愛している''' >>> russian = """я люблю тебя""" >>> type(chinese) <class 'str'> >>> type(english) <class 'str'> >>> type(japanese) <class 'str'> >>> type(russian) <class 'str'>
从输出可知,字符串的类型名为str。
9.1.3 字符的数字编码
在第三章中已经介绍过,计算机只能处理二进制,为了让计算机能对字符进行处理,需要对字符进行编码。所谓的编码,是指用数字来对字符进行表示。不同的表示方法,对应不同的字符编码。
通过Python中的内置函数ord,可以获取字符的十进制数字码。使用ord函数的基本语法:
ord(character)
参数character表示特定的字符,返回值为字符的十进制数字编码。进入交互模式中进行验证:
>>> ord('爱')
29233
通过Python中的内置函数chr,可以获取数字编码所对应的字符。使用chr函数的基本语法:
chr(code)
参数code表示字符的数字编码,返回值为数字编码所对的字符。 进入交互模式中进行验证:
>>> chr(29233) '爱'
9.1.4 常用的字符编码
最早的字符编码为ASCII编码,这种编码使用一个字节来表示一个字符。一个字节能表示的范围是0-255,也就是说,这种编码最多只能表示256个字符。ASCII编码无法表示汉字等其它字符,为了满足其它地区的需要,又出现了多字节编码。
我们中国一开始制定的是GBK编码,使用两个字节来表示常用的汉字,其它地区也纷纷制定了不同的编码,用来表示本国的字符集。 为了对各地区的编码进行规范统一,出现了UNICODE编码,UNICODE编码在制定之初统一使用两个字节来表示一个字符。
(1) ASCII
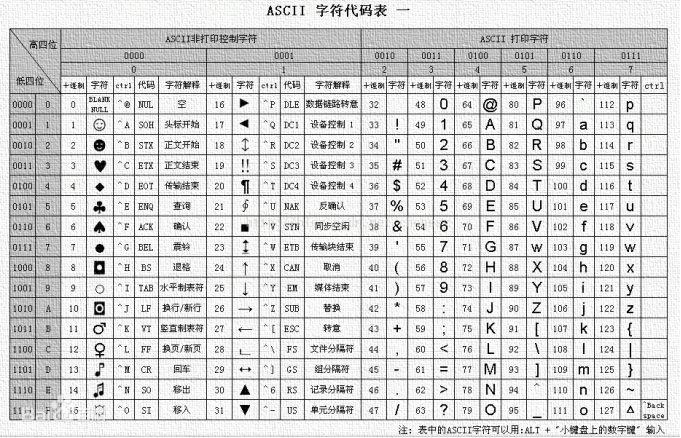
ASCII码,全称为美国信息交换标准码,一种使用7个或8个二进制位进行字符编码的方案,最多可以包含256个字符。基本的 ASCII 字符集一共有 128 个字符,其中有 96 个可打印字符,包括常用的字母、数字、标点符号等,另外还有 32 个控制字符。下图为ASCII字符的码表:
(2)UNICODE
在UNICODE编码中,为每种语言中的每个字符设定了统一并且唯一的二进制编码, 这个编号范围从 0x000000 到 0x10FFFF,每个字符对应一个唯一的UNICODE数字码,UNICODE编码的形式为:在数字码(十六进制)前面加上U+。例如:"爱"的UNICODE是U+7231。
(3) UTF-8
UTF-8,是一种针对UNICODE的可变长度字符编码, 不同于UNICODE编码采用固定长度的字节数来表示字符, UTF-8使用的字节数是可变的,比如ASCII字符,在UTF-8编码中仍使用一个字节来进行编码,对于汉字等字符使用的是3个字节来进行编码。
(4) GBK
GBK编码是汉字编码字符集,采用的是单双字节变长编码,英文字符使用单字节编码,完全兼容ASCII码,中文部分采用双字节编码。
9.1.5 字符串的默认编码
Python中的字符串默认采用UNICODE进行编码,也就是说,Python中的字符串是UNICODE字符串。
9.1.6 字符串的编码与解码
通过字符串类型的encode方法,可以获取字符串以特定编码方式编码后的字节码类型。
使用encode方法的基本语法:
str.encode(encoding)
参数encoding表示字符的编码方法, 返回值为bytes类型。通过字节码类型的decode方法,可以将字节码类型转换为UNICODE字符串。
使用decode函数的基本语法:
bytes.decode(encoding)
参数encoding表示字符的编码方法,返回值为str类型。
代码实例-对字符串进行编码与解码
Python
# 1.对汉字字符进行编码与解码
chinese = "我爱你"
gbk_code = chinese.encode('gbk')
chinese = gbk_code.decode('gbk')
# 2.对英文字符进行编码与解码
english = 'I Love You'
ascii_code = english.encode('ascii')
english = ascii_code.decode('ascii')
# 3.对日本字符进行编码与解码
japanese = '''君のことを愛している'''
unicode = japanese.encode('unicode-escape')
japanese = unicode.decode('unicode-escape')
# 4.对俄文字符进行编码与解码
russian = """я люблю тебя"""
utf8_code = russian.encode('utf-8')
russian = utf8_code.decode('utf-8')代码讲解:
(1)传递参数'gbk',获取gbk编码的字节码类型 (2)传递参数'ascii',获取ascii编码的字节码类型 (3)传递参数'unicode-escape',获取unicode编码的字节码类型 (4)传递参数'utf-8',获取utf-8编码的字节码类型
使用bytes类型的decode进行解码时,编码方式必须兼容,否则会抛出编码错误的异常信息。
可以在交互模式中进行验证:
>>> gbk_code = chinese.encode('gbk')
>>> gbk_code.decode('ascii')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeDecodeError: 'ascii' codec can't decode byte 0xce in position 0:
ordinal not in range(128)
在交互模式中,传递gbk获取gbk编码的字节码类型,但在解码时传递的参数是ascii。ascii编码与gbk编码不兼容,故抛出了异常信息。
9.1.7 转义字符详解
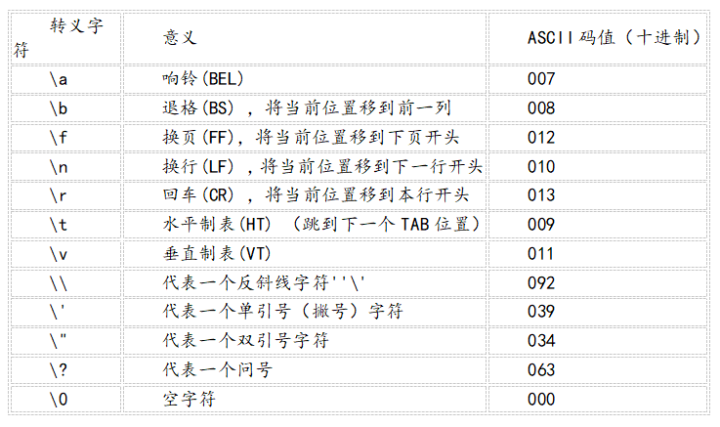
编程语言中的转义字符是反斜杠符号'\'+字符构成的特殊字符,通常使用转义字符来表示字符集中定义的字符,如ASCll字符集里面的换行符。
下表是常用的转义字符:
使用转义字符可以避免产生歧义,比如通过转义字符\"来表示一个包含引号的字符串:
"\""
如果没有转义字符,那么系统无法识别用户究竟定义的是一个包含引号的字符串,还是一个三引号。
也可以通过引号括住其它形式的引号来表示包含引号的字符串,例如在单引号中包含双引号:'"',在双引号中包含单引号:"''"。
使用转义字符,还可以实现一些有用的特性。
(1) 使用换行符输出多行
>>>chinese = "我\n爱\n你\n" >>>print(chinese) 我 爱 你
(2) 输出水平制表符
>>> chinese = "我\t爱\t你\t" >>> print(chinese) 我 爱 你
在特定的应用场景下,需要禁止字对符进行转义,通过在字符串前加上r前缀,可以实现这样的功能。
>>> chinese = r"我\t爱\t你\t" >>> print(chinese) 我\t爱\t你
字符串中包含路径时,禁止Python对其进行转义会非常有用:
>>> file_path = "D:\nosql\data" >>> print(file_path) D: osql\data
输出明显是有问题的,Python将字符串中的\n字符解释成了转义字符,此时可以在字符串中加上r前缀,来禁止Python对字符进行转义。
>>> file_path = r"D:\nosql\data" >>> print(file_path) D:\nosql\data
9.1.8 对字符串进行遍历
字符串是一种线性的序列结构,可以通过for循环对字符串中的所有字符进行遍历。
代码实例-逐一遍历字符串中的字符:
Python
japanese = '''君のことを愛している'''
for _ in japanese:
print(_)代码讲解:
(1) 对字符串进行遍历,是按字符的先后排列顺序进行遍历的 (2) 通过分析程序的输出,可以更好地理解字符串这种线性的序列结构。
9.1.9 知识要点
(1) 在Python中用英文引号括住的都为字符串 (2) 字符串是一种线性的序列结构 (3) 字符串的类型名是str (4) 所谓的编码,是指用数字来对字符进行表示。不同的表示方法,对应不同的字符集。 (5) 常用的字符集有ascii字符集,unicode字符集,utf-8字符集,gbk字符集 (6) Python中的字符串默认为UNICODE字符串
9.1.10 系统学习python
薯条老师简介:资深技术专家,技术作家,著有《Python零基础入门指南》,《Java零基础入门指南》等技术教程。薯条老师的博客:http://www.chipscoco.com, 系统学习后端,爬虫,数据分析,机器学习、量化投资。




![5 分钟带你小程序入门 [实战总结分享]](https://img-blog.csdnimg.cn/img_convert/49d2b221867c780b56d0d8c4a8231f2d.jpeg)