目录
1.何为RDD
2.RDD的五大特性
3.RDD常用算子
3.1.Transformation算子
1.map()
2.flatMap()
3.reduceByKey()
4 . mapValues()
5. groupBy()
6.filter()
7.distinct()
8.union()
9.join()
10.intersection()
11.glom()
12.gruopBykey()
13.sortBy()
14.sortByKey
3.2 Action算子
1.countByKey()
2.countByValue()
3.collect()
4.reduce()
5.fold()
6.first()
7.take()
8.top()
9.count()
10.takeSample()
11.takeOdered()
12.foreach()
13.saveAsTextFile()
3.3 分区操作算子
1.mapPartitions()
2.foreachPartition()
3.partitionBy()
4.repartition()
5.groupByKey() 与 reduceByKey() 的区别
4.一些练习提示
1.何为RDD
RDD,全称Resilient Distributed Datasets,意为弹性分布式数据集。它是Spark中的一个基本概念,是对数据的抽象表示,是一种可分区、可并行计算的数据结构。其RDD来源于这篇论文(论文链接:Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing)

RDD可以从外部存储系统中读取数据,也可以通过Spark中的转换操作进行创建和变换。RDD的特点是不可变性、可缓存性和容错性。同时,RDD提供了一种多种类型的操作,比如转换操作和行动操作,可以对RDD进行处理和计算。RDD的定义包含以下几个要素:
- 数据集:RDD是一个分布式的数据集合,数据可以来自于HDFS、HBase、本地文件系统等。
- 分区:数据集可以被分成多个分区,每个分区可以在集群中的不同节点上进行处理。
- 弹性:RDD的分区可以在集群中的不同节点上进行重建和恢复,从而保证了RDD的容错性。
- 不可变性:RDD中的数据不可被修改,只能通过转换操作生成新的RDD。
- 缓存性:RDD可以被缓存到内存中,以提高计算性能。
- 操作:RDD提供了多种类型的操作,包括转换操作和行动操作,可以对RDD进行处理和计算。
2.RDD的五大特性
(1)A list of partitions--RDD是分区的,由许多partition构成,有多少partition就对应有多少task
(2)A function for computing each split--计算方法(函数)是作用于每个RDD的
(3)A list of dependencies on other RDDs--RDD之间有相互依赖
(4)Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)--KV型RDD可以有分区型
(5)Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file)--RDD分区数据读取时尽量靠近数据所在地
具体RDD的五大特性可看这篇文章http://t.csdn.cn/gzjb7
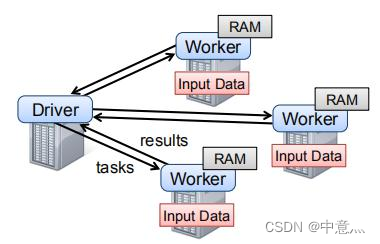
3.RDD常用算子
算子就是分布式集合对象上的API,类似于本地的函数或方法,只不过后者是本地的API,为了区分就叫其算子。

RDD算子主要分为Transformation算子和Action算子
Transformation算子其返回值仍然是一个RDD,而且该算子为lazy的,即如果没有Action算子,它是不会工作的,就类似与Transformation算子相当于一道流水线,而Action算子是这个流水线的开关。
Action算子其返回值则不是RDD,是其他的对象,如一个数,一个迭代器等。
接下来会介绍常用算子
3.1.Transformation算子
1.map()
map(func) 将RDD一条条处理,返回新的RDD
func:f:(T)->U
rdd=sc.parallelize([1,2,3,4,5,6],3)
def func(data):
return data*10
rdd=rdd.map(func)
print(rdd.collect())
#[10, 20, 30, 40, 50, 60]2.flatMap()
flatMap(func) 对RDD执行map操作,然后进行解除嵌套(即类似拉直数组)操作
rdd1=sc.parallelize(['hadoop spark hadoop','spark hadoop hadoop','hadoop flink spakr'])
rdd2=rdd1.map(lambda x:x.split(' '))
#flatMap()将多维数组拉直
rdd3=rdd1.flatMap(lambda x:x.split(' '))
print(rdd2.collect())
print(rdd3.collect())
#map:[['hadoop', 'spark', 'hadoop'], ['spark', 'hadoop', 'hadoop'], ['hadoop', 'flink', 'spakr']]
#flaMap:['hadoop', 'spark', 'hadoop', 'spark', 'hadoop', 'hadoop', 'hadoop', 'flink', 'spakr']3.reduceByKey()
reduceByKey(func) 针对于kv型数据,流程为按照k分组,然后对v进行处理(聚合) func(V,V)->V
rdd=sc.parallelize([('a',1),('a',1),('b',1),('a',1)])
def func(a,b):
return a+b
rdd=rdd.reduceByKey(func)
print(rdd.collect())
#[('a', 3), ('b', 1)]4 . mapValues()
mapValues(func)针对于二元元组RDD,只针对其中的value进行map操作 func(V)->U
rdd=sc.parallelize([('a',1),('a',1),('b',1),('a',1)])
def func(a):
return a*10
rdd=rdd.mapValues(func)
print(rdd.collect())
#[('a', 10), ('a', 10), ('b', 10), ('a', 10)]5. groupBy()
groupBy(func) 将rdd的数据进行分组 func(T)->K 通过这个函数,确定按照谁来分组(返回谁即可) 分组规则(hash分组),该函数是,拿到你的返回值,将所有相同返回值的放入一个组内,最后分组完成后,每一个组是一个二元组,key就是返回值,所有同组的数据放入一个迭代器对象中作为value
rdd=sc.parallelize([('a',1),('a',1),('b',1),('b',1),('b',1),('b',1)])
def func(a):
return a[0]
rdd=rdd.groupBy(func)
print(rdd.map(lambda x:(x[0],list(x[1]))).collect())
#[('a', [('a', 1), ('a', 1)]), ('b', [('b', 1), ('b', 1), ('b', 1), ('b', 1)])]6.filter()
filter(func) 过滤想要的数据进行保留 func(T)->bool 即返回值为True的数据保留
rdd=sc.parallelize([1,2,3,4,5,6])
def func(a):
if a%2==0:
return 1
else:
return 0
rdd=rdd.filter(func)#rdd.filte(lambda x:x%2==1)
print(rdd.collect())
#[2, 4, 6]7.distinct()
distinct(参数1) 对rdd数据进行去重 参数1-去重分区,一般不用传
rdd=sc.parallelize([1,1,2,3,1,2,2,3,4,4])
rdd=rdd.distinct()
print(rdd.collect())
#[1, 2, 3, 4]8.union()
union() 2个rdd合并成1个rdd返回 rdd.union(other_rdd) 只合并不去重,不同类型的RDD依旧可以混合
rdd1=sc.parallelize([1,2,4,5,1])
rdd2=sc.parallelize(['a','b','c','a'])
rdd=rdd1.union(rdd2)
print(rdd.collect())
#[1, 2, 4, 5, 1, 'a', 'b', 'c', 'a']9.join()
join() 对两个rdd执行join操作(可实现sql的内|外连接) 只能用于二元元组,根据二元元组的key来连接 内连接 rdd.join(other_rdd) 左外连接 rdd.leftOuterJoin(other_rdd) 右外连接 rrdd.ightOuterJoin(other_rdd) 对于缺失的,用None填充
rdd1=sc.parallelize([(1001,'a'),(1002,'b'),(1003,'c')])
rdd2=sc.parallelize([(1001,'dudu'),(1002,'huahua')])
#内连接
rdd=rdd1.join(rdd2)
print(rdd.collect())
#[(1001, ('a', 'dudu')), (1002, ('b', 'huahua'))]
#左外连接
rdd=rdd1.leftOuterJoin(rdd2)
print(rdd.collect())
#[(1001, ('a', 'dudu')), (1002, ('b', 'huahua')), (1003, ('c', None))]
#右外连接
rdd=rdd1.rightOuterJoin(rdd2)
print(rdd.collect())
#[(1001, ('a', 'dudu')), (1002, ('b', 'huahua'))]10.intersection()
intersection() 求2个rdd的交集,返回一个新的rdd rdd.intersection(other_rdd)
rdd1=sc.parallelize([('a',1),('b',3)])
rdd2=sc.parallelize([('a',1),('a',3)])
rdd=rdd1.intersection(rdd2)
print(rdd.collect())
#[('a', 1)]11.glom()
glom() 将rdd的数据,加上嵌套,按分区显示 rdd->[1,2,3,4,5]有两个分区 glom后->[[1,2,3],[4,5]]
rdd=sc.parallelize([1,2,3,4,5,6],2)
rdd=rdd.glom()
print(rdd.collect())
#[[1, 2, 3], [4, 5, 6]]12.gruopBykey()
groupByKey() 针对kv型rdd,自动按照key分组
rdd=sc.parallelize([('a',1),('a',2),('b',1),('b',2)])
rdd=rdd.groupByKey().map(lambda x:(x[0],list(x[1])))
print(rdd.collect())
#[('a', [1, 2]), ('b', [1, 2])]13.sortBy()
sortBy(func,ascending=False,numPartitions=1) 对rdd数据进行排序,基于指定的排序依据 func(T)->V ascending True 升序 Flases 降序 numPartitions 用多少分区排序 如果要全局有序,排序分区数要设置为1
def func(a):
return a[1]
rdd=sc.parallelize([('a',1),('b',3),('c',1),('c',2),('d',4),('a',6)],9)
rdd=rdd.sortBy(func,ascending=True, numPartitions=1)
print(rdd.collect())
#[('a', 1), ('c', 1), ('c', 2), ('b', 3), ('d', 4), ('a', 6)]14.sortByKey
sortByKey(ascending=True,numPartitions=None,keyfunc=<function RDD,<lambda>>) 针对kv型RDD,按照key进行排序
ascending true升序,false降序
numPartition 按照几个分区进行排序,如果全局有序,设置1
keyfunc 在排序前对key进行处理,语法是(k)->U,一个参数传入,返回一个值
rdd=sc.parallelize([('a',1),('E',1),('C',1),('D',1),('b',1),('g',1),('f',1)])
rdd=rdd.sortByKey(ascending=True,numPartitions=1,keyfunc=lambda x:x.lower())
print(rdd.collect())
#[('a', 1), ('b', 1), ('C', 1), ('D', 1), ('E', 1), ('f', 1), ('g', 1)]3.2 Action算子
1.countByKey()
countByKey() 统计key出现的次数(一般适用于kv型RDD)
rdd=sc.textFile('words.txt')
rdd=rdd.flatMap(lambda x:x.split(' ')).map(lambda x:(x,1))
result=rdd.countByKey()
print(result)
#defaultdict(<class 'int'>, {'hadoop': 6, 'spark': 3, 'flink': 1})2.countByValue()
countByValue() 根据rdd中的元素值相同的个数 返回的类型为Map[K,V], K : 元素的值,V :元素对应的的个数,与kv型数据中的v没有关系
rdd=sc.parallelize(['a','a','b','c','c','c','d'])
result=rdd.countByValue()
print(result)
#defaultdict(<class 'int'>, {'a': 2, 'b': 1, 'c': 3, 'd': 1})3.collect()
collect() 将RDD各个分区内的数据,统一收集到Driver中,形成一个list对象 用之前数据集别太大,否则会把Driver内存溢出而报错,很常用这里就不举例了
4.reduce()
reduce(func) 队RDD数据集按照你传入的逻辑进行聚合 func:(T,T)->T 2个参数传入,1个返回值,返回值和参数要求类型一致
rdd=sc.parallelize([1,2,3,4,5,6])
result=rdd.reduce(lambda a,b:a+b)
print(result)
#215.fold()
fold() 和reducce一样,接受传入逻辑进行聚合 但聚合是带有初始值的 多个分区时 这个初始值聚合会作用在 分区内和分区间

rdd=sc.parallelize([1,2,3,4,5,6,7,8,9],3)
result=rdd.fold(10,lambda a,b:a+b)
print(result)
#856.first()
first() 取出RDD的第一个元素
rdd=sc.parallelize([1,2,3,4,5])
result=rdd.first()
print(result)
#17.take()
take() 取RDD的前N个元素,组合成list返回
rdd=sc.parallelize([1,2,3,4,5])
result=rdd.take(5)
print(result)
#[1, 2, 3]8.top()
top() 对RDD数据集进行降序(从大到小)排序,取前N个,组成list返回
rdd=sc.parallelize([1,2,3,4,5])
result=rdd.top(3)
print(result)
#[5, 4, 3]9.count()
count() 计算RDD有多少条数据,返回一个数字
rdd=sc.parallelize([1,2,3,4,5])
result=rdd.count()
print(result)
#510.takeSample()
takeSample(参数1:True or False,参数2:采样数,参数3:随机数种子) 随机抽样RDD的数据 参数1:True表示允许取同一个数据 False表示不允许取同一个数据 和数据内容无关,是否重复表示的是同一个位置的数据 参数2:抽样要几个 参数3:随机数种子(一般不传,Spark会自动给)
rdd=sc.parallelize([1,2,3,1,2,3,4,5,6,2,3,1],2)
result=rdd.takeSample(False,3)
print(result)
#[3, 1, 5] 这是随机的,每次运行结果不一样11.takeOdered()
takeOrdered(参数1,参数2) 对RDD进行排序取前N个 参数1:要几个数据 参数2:对排序的数据进行更改(不会更改数据本身,只是在排序的时候换个样子) 这个方法使用按照元素自然顺序升序排序,如果想按照其他规则排序,需要用参数2进行编写
rdd=sc.parallelize([3,4,5,2,2,4,5,22,9],3)
result=rdd.takeOrdered(4,lambda x:-x)
print(result)
#[22, 9, 5, 5]12.foreach()
foreach(func) 对RDD的每一个元素,执行你提供的逻辑的操作(类似于map),但这个方法方法没有返回值 func:(T)->None 操作是在容器内进行,不需要上传至Dirver再运行,效率较高
rdd=sc.parallelize([1,2,3,4,5,6,7],2)
result=rdd.foreach(lambda x:print(x*10))
print(result)
#10
#20
#30
#40
#50
#60
#70
#None13.saveAsTextFile()
saveAsTextFile() 将RDD的数据写入文本文件中 支持本地写出,hdfs rdd有几个分区,就有几个文件
rdd=sc.parallelize([1,2,3,4,55,5,6],3)
rdd.saveAsTextFile('output/out1')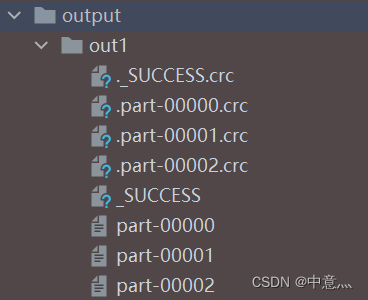
3.3 分区操作算子
1.mapPartitions()
mapPartitions()--Transformation mapPartitions 一次杯传递的是一整个分区的数据作为一个迭代器(list)对象传入过来,与map不同的是,map是每次传入一个值,在网络io层面,效率和性能有很大提升
rdd=sc.parallelize([1,2,3,4,5,6,7],3)
def func(x):
result=list()
for i in x:
result.append(i*10)
return result
rdd=rdd.mapPartitions(func)
print(rdd.collect())
#[10, 20, 30, 40, 50, 60, 70]2.foreachPartition()
foreachPartition()--Action 和普通的foreach一致,一次传入了的是一个分区数据
rdd=sc.parallelize([1,2,3,4,5,6,7],3)
def func(x):
result=list()
for i in x:
result.append(i*10)
print(result)
rdd.foreachPartition(func)
#[10, 20]
#[30, 40]
#[50, 60, 70]3.partitionBy()
partitionBy(参数1,参数2)--Transformation 对RDD进行自定义分区操作 参数1:重新分区后有几个分区 参数2:自定义分区规则,函数传入 (K)->int
rdd=sc.parallelize([('a',1),('a',1),('b',1),('a',1),('c',1),('d',1)],3)
print('自定义分区前:',rdd.glom().collect())
def func(key):
if key=='a' or key=='b':
return 0
elif key=='c':
return 1
else:
return 2
rdd=rdd.partitionBy(3,func)
print('自定义分区后:',rdd.glom().collect())
#自定义分区前: [[('a', 1), ('a', 1)], [('b', 1), ('a', 1)], [('c', 1), ('d', 1)]]
#自定义分区后: [[('a', 1), ('a', 1), ('b', 1), ('a', 1)], [('c', 1)], [('d', 1)]]4.repartition()
repartition(N)--Transfromation 对RDD的分区执行重新分区(仅数量) 其底层函数为 coalesce(N,shuffle=True) 但该函数有个安全机制,即若想增加分区得shuffle=True 而减少分区则不需要 传入N 决定新的分区数 (少用,尽量减少,不要增加)
rdd=sc.parallelize([1,2,3,4,5,6],3)
print('原分区:',rdd.glom().collect())
rdd1=rdd.repartition(1)
print('重新分区后:',rdd1.glom().collect())
rdd=sc.parallelize([1,2,3,4,5,6],3)
#原分区: [[1, 2], [3, 4], [5, 6]]
#重新分区后: [[1, 2, 3, 4, 5, 6]]5.groupByKey() 与 reduceByKey() 的区别
groupBykey()--仅仅分组 reduceByKey()--分组+聚合 redeceByKey-->先分区内聚合再分组最后再聚合 的性能远远大于 groupByKey+聚合逻辑-->先分组再聚合 网络io大
4.一些练习提示
对于两个输入文件a.txt和b.txt,编写Spark独立应用程序,对两个文件进行合并,并剔除其中重复的内容,得到一个新文件
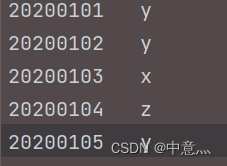
数据基本为这样,想将数据转化为二元元组,然后利用union拼接,再利用distinct去重,再利字符串拼接,最后再利用coalesce转换为一个分区,然后saveAstextFile就可以得到一个文件了。