文章目录
- 1.语言模型 Language Model
- 1.1 语言模型是什么
- 1.2 语言模型计算什么
- 1.3 n-gram Language Model
- 2.神经网络语言模型NNLM
- 2.1 N-gram模型的问题
- 3. 词向量
- 3.1 词向量(word Embedding)
- word2vec 词向量训练算法
- 3.2 如何把词转换为词向量?
- 3.3如何让向量具有语义信息?
- 3.4 词向量算法CBOW和Skip-gram
- 3.5 用神经网络实现CBOW
- 4. 使用PaddleNLP加载词向量
- 5.使用VisualDL进行词向量可视化
- 6.系统环境
====================================
课程链接:零基础学习深度学习(第2版)
====================================
1.语言模型 Language Model
1.1 语言模型是什么
从前面的文字中推断出后续会出现的文字
eg. 今天欢迎大家来到飞桨学习课程---->今天欢迎大家来到飞桨学习___
通过语言模型推断出“课程’’
1.2 语言模型计算什么
计算这句话产生的文字的概率 词语同时出现的概率 条件概率等
1.3 n-gram Language Model
和前面n个词的关系
eg.
- 飞桨\学习 two-gram 与前面两个词有关
- 来到\飞桨\学习 tree-gram 与前面三个词有关
2.神经网络语言模型NNLM
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hMOACs4j-1681110145461)(C:\Users\朱振宇\AppData\Roaming\Typora\typora-user-images\image-20230409181006049.png)]](https://img-blog.csdnimg.cn/fc7e3ee3c47743d0ad85ad5d0087e908.png)
2.1 N-gram模型的问题
- 无法建模出更远距离的依赖关系
- 无法建模出词之间的相似度
- 泛化能力不够,对于训练集中没有出现过的n元组条件概率为0的情况,只能用平滑法赋予他们概率
2.2 平滑法
3. 词向量
3.1 词向量(word Embedding)
word2vec 词向量训练算法
Mikolov提出的经典word2vec算法就是通过上下文来学习语义信息。包括两个经典算法CBOW,Skip-gram。
-
高维空间的降维操作
-
是一种表示自然语言中单词的方法,即把每个词都表示为一个N维空间的一个点,即一个高维空间内的向量,通过这种方式,将自然语言计算转化为向量计算。
在自然语言处理任务中,词向量(Word Embedding)是表示自然语言里单词的一种方法,即把每个词都表示为一个N维空间内的点,即一个高维空间内的向量。通过这种方法,实现把自然语言计算转换为向量计算。
如图所示的词向量计算任务中,先把每个词(如queen,king等)转换成一个高维空间的向量,这些向量在一定意义上可以代表这个词的语义信息。再通过计算这些向量之间的距离,就可以计算出词语之间的关联关系,从而达到让计算机像计算数值一样去计算自然语言的目的。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4nNt0vCu-1681110145462)(C:\Users\朱振宇\AppData\Roaming\Typora\typora-user-images\image-20230409191301669.png)]
3.2 如何把词转换为词向量?
3.3如何让向量具有语义信息?
3.4 词向量算法CBOW和Skip-gram
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cqEuRBiZ-1681110145463)(C:\Users\朱振宇\AppData\Roaming\Typora\typora-user-images\image-20230409191943887.png)]](https://img-blog.csdnimg.cn/0a78f4cf2f58467d96fa661264692491.png)
CBOW
给定一句话:Pineapples are spiked and yellow
- 使用上下文的词向量来预测中心词
- 中心词:“spiked"
- 上上文:“Pineapples are and yellow”
- 中心词的所限定的语义就被传递到上下文的词向量中,如“spiked->pineapple”,从而达到学习语义信息的目的
- 其他带刺的植物的向量表示就会靠近pineapple
Wvxn 是词向量

Skip-gram
给定一句话:Pineapples are spiked and yellow
- 使用中心词的词向量来预测上下文
- 中心词:“spiked"
- 上上文:“Pineapples are and yellow”
- 上下文定义的语义被传入到中心词的表示中,如“pineapple->spiked”
- spiked,prickly等词的向量表示就会逐渐的越来越相似
cbow比skip-gram训练快且更加稳定一些,然而,skip-gram比cbow更好地处理生僻字或者是一些评率低的字
3.5 用神经网络实现CBOW
给定一句话:Pineapples are spiked and yellow
C=4, V=5000, N=128
- 输入层:一个形状为C*V的one-hot的张量,其中C表示上下文中词的个数,对于eg中的句子C的值为4,V表示词表的大小
- 该张量的每一行都是一个上下文词的one-hot向量表示,比如[Pineapples,are,and,yellow]
- 隐藏层:一个形状为V*N的参数张量W1,一般称为word-embedding,N表示每个词的向量表示长度
- 输入张量的word embedding W1进行矩阵乘法,就会得到一个形状为C*N的张量
- 最后通过softamx函数,得到中心词的预测概率
实现Skip-gram的pycharm代码
preparedata.pyy
import sys
import requests
from collections import OrderedDict
import math
import random
import numpy as np
import paddle
from paddle.nn import Embedding
import paddle.nn.functional as F
import paddle.nn as nn
# 读取text8数据
def load_text8():
with open("./text8.txt", "r") as f:
corpus = f.read().strip("\n")
f.close()
return corpus
# 对语料进行预处理(分词)
def data_preprocess(corpus):
# 由于英文单词出现在句首的时候经常要大写,所以我们把所有英文字符都转换为小写,
# 以便对语料进行归一化处理(Apple vs apple等)
corpus = corpus.strip().lower()
corpus = corpus.split(" ")
return corpus
# 构造词典,统计每个词的频率,并根据频率将每个词转换为一个整数id
def build_dict(corpus):
# 首先统计每个不同词的频率(出现的次数),使用一个词典记录
word_freq_dict = dict()
for word in corpus:
if word not in word_freq_dict:
word_freq_dict[word] = 0
word_freq_dict[word] += 1
# 将这个词典中的词,按照出现次数排序,出现次数越高,排序越靠前
# 一般来说,出现频率高的高频词往往是:I,the,you这种代词,而出现频率低的词,往往是一些名词,如:nlp
word_freq_dict = sorted(word_freq_dict.items(), key=lambda x: x[1], reverse=True)
# 构造3个不同的词典,分别存储,
# 每个词到id的映射关系:word2id_dict
# 每个id出现的频率:word2id_freq
# 每个id到词的映射关系:id2word_dict
word2id_dict = dict()
word2id_freq = dict()
id2word_dict = dict()
# 按照频率,从高到低,开始遍历每个单词,并为这个单词构造一个独一无二的id
for word, freq in word_freq_dict:
curr_id = len(word2id_dict)
word2id_dict[word] = curr_id
word2id_freq[word2id_dict[word]] = freq
id2word_dict[curr_id] = word
return word2id_freq, word2id_dict, id2word_dict
# 把语料转换为id序列
def convert_corpus_to_id(corpus, word2id_dict):
# 使用一个循环,将语料中的每个词替换成对应的id,以便于神经网络进行处理
corpus = [word2id_dict[word] for word in corpus]
return corpus
# 使用二次采样算法(subsampling)处理语料,强化训练效果
def subsampling(corpus, word2id_freq):
# 这个discard函数决定了一个词会不会被替换,这个函数是具有随机性的,每次调用结果不同
# 如果一个词的频率很大,那么它被遗弃的概率就很大
def discard(word_id):
return random.uniform(0, 1) < 1 - math.sqrt(
1e-4 / word2id_freq[word_id] * len(corpus))
corpus = [word for word in corpus if not discard(word)]
return corpus
# 构造数据,准备模型训练
# max_window_size代表了最大的window_size的大小,程序会根据max_window_size从左到右扫描整个语料
# negative_sample_num代表了对于每个正样本,我们需要随机采样多少负样本用于训练,
# 一般来说,negative_sample_num的值越大,训练效果越稳定,但是训练速度越慢。
def build_data(corpus, word2id_dict, word2id_freq, max_window_size=3, negative_sample_num=4):
# 使用一个list存储处理好的数据
dataset = []
# 从左到右,开始枚举每个中心点的位置
for center_word_idx in range(len(corpus)):
# 以max_window_size为上限,随机采样一个window_size,这样会使得训练更加稳定
window_size = random.randint(1, max_window_size)
# 当前的中心词就是center_word_idx所指向的词
center_word = corpus[center_word_idx]
# 以当前中心词为中心,左右两侧在window_size内的词都可以看成是正样本
positive_word_range = (
max(0, center_word_idx - window_size), min(len(corpus) - 1, center_word_idx + window_size))
positive_word_candidates = [corpus[idx] for idx in range(positive_word_range[0], positive_word_range[1] + 1) if
idx != center_word_idx]
vocab_size = len(word2id_freq)
# 对于每个正样本来说,随机采样negative_sample_num个负样本,用于训练
for positive_word in positive_word_candidates:
# 首先把(中心词,正样本,label=1)的三元组数据放入dataset中,
# 这里label=1表示这个样本是个正样本
dataset.append((center_word, positive_word, 1))
# 开始负采样
i = 0
while i < negative_sample_num:
negative_word_candidate = random.randint(0, vocab_size - 1)
if negative_word_candidate not in positive_word_candidates:
# 把(中心词,正样本,label=0)的三元组数据放入dataset中,
# 这里label=0表示这个样本是个负样本
dataset.append((center_word, negative_word_candidate, 0))
i += 1
return dataset
# 构造mini-batch,准备对模型进行训练
# 我们将不同类型的数据放到不同的tensor里,便于神经网络进行处理
# 并通过numpy的array函数,构造出不同的tensor来,并把这些tensor送入神经网络中进行训练
def build_batch(dataset, batch_size, epoch_num):
# center_word_batch缓存batch_size个中心词
center_word_batch = []
# target_word_batch缓存batch_size个目标词(可以是正样本或者负样本)
target_word_batch = []
# label_batch缓存了batch_size个0或1的标签,用于模型训练
label_batch = []
for epoch in range(epoch_num):
# 每次开启一个新epoch之前,都对数据进行一次随机打乱,提高训练效果
random.shuffle(dataset)
for center_word, target_word, label in dataset:
# 遍历dataset中的每个样本,并将这些数据送到不同的tensor里
center_word_batch.append([center_word])
target_word_batch.append([target_word])
label_batch.append(label)
# 当样本积攒到一个batch_size后,我们把数据都返回回来
# 在这里我们使用numpy的array函数把list封装成tensor
# 并使用python的迭代器机制,将数据yield出来
# 使用迭代器的好处是可以节省内存
if len(center_word_batch) == batch_size:
yield np.array(center_word_batch).astype("int64"), \
np.array(target_word_batch).astype("int64"), \
np.array(label_batch).astype("float32")
center_word_batch = []
target_word_batch = []
label_batch = []
if len(center_word_batch) > 0:
yield np.array(center_word_batch).astype("int64"), \
np.array(target_word_batch).astype("int64"), \
np.array(label_batch).astype("float32")
if __name__ == '__main__':
corpus = load_text8()
corpus = data_preprocess(corpus)
word2id_freq, word2id_dict, id2word_dict = build_dict(corpus)
vocab_size = len(word2id_freq)
corpus = convert_corpus_to_id(corpus, word2id_dict)
corpus = subsampling(corpus, word2id_freq)
corpus_light = corpus[:int(len(corpus) * 0.2)]
dataset = build_data(corpus_light, word2id_dict, word2id_freq)
for _, batch in zip(range(10), build_batch(dataset, 128, 3)):
print(batch)
break
SkipGram.py
from prepare_data import *
# 定义skip-gram训练网络结构
# 使用paddlepaddle的2.0.0版本
# 一般来说,在使用paddle训练的时候,我们需要通过一个类来定义网络结构,这个类继承了paddle.nn.layer
class SkipGram(nn.Layer):
def __init__(self, vocab_size, embedding_size, init_scale=0.1):
# vocab_size定义了这个skipgram这个模型的词表大小
# embedding_size定义了词向量的维度是多少
# init_scale定义了词向量初始化的范围,一般来说,比较小的初始化范围有助于模型训练
super(SkipGram, self).__init__()
self.vocab_size = vocab_size
self.embedding_size = embedding_size
# 使用Embedding函数构造一个词向量参数
# 这个参数的大小为:[self.vocab_size, self.embedding_size]
# 数据类型为:float32
# 这个参数的初始化方式为在[-init_scale, init_scale]区间进行均匀采样
self.embedding = Embedding(
num_embeddings=self.vocab_size,
embedding_dim=self.embedding_size,
weight_attr=paddle.ParamAttr(
initializer=paddle.nn.initializer.Uniform(
low=-init_scale, high=init_scale)))
# 使用Embedding函数构造另外一个词向量参数
# 这个参数的大小为:[self.vocab_size, self.embedding_size]
# 这个参数的初始化方式为在[-init_scale, init_scale]区间进行均匀采样
self.embedding_out = Embedding(
num_embeddings=self.vocab_size,
embedding_dim=self.embedding_size,
weight_attr=paddle.ParamAttr(
initializer=paddle.nn.initializer.Uniform(
low=-init_scale, high=init_scale)))
# 定义网络的前向计算逻辑
# center_words是一个tensor(mini-batch),表示中心词
# target_words是一个tensor(mini-batch),表示目标词
# label是一个tensor(mini-batch),表示这个词是正样本还是负样本(用0或1表示)
# 用于在训练中计算这个tensor中对应词的同义词,用于观察模型的训练效果
def forward(self, center_words, target_words, label):
# 首先,通过self.embedding参数,将mini-batch中的词转换为词向量
# 这里center_words和eval_words_emb查询的是一个相同的参数
# 而target_words_emb查询的是另一个参数
center_words_emb = self.embedding(center_words)
target_words_emb = self.embedding_out(target_words)
# 我们通过点乘的方式计算中心词到目标词的输出概率,并通过sigmoid函数估计这个词是正样本还是负样本的概率。
word_sim = paddle.multiply(center_words_emb, target_words_emb)
word_sim = paddle.sum(word_sim, axis=-1)
word_sim = paddle.reshape(word_sim, shape=[-1])
pred = F.sigmoid(word_sim)
# 通过估计的输出概率定义损失函数,注意我们使用的是binary_cross_entropy_with_logits函数
# 将sigmoid计算和cross entropy合并成一步计算可以更好的优化,所以输入的是word_sim,而不是pred
loss = F.binary_cross_entropy_with_logits(word_sim, label)
loss = paddle.mean(loss)
# 返回前向计算的结果,飞桨会通过backward函数自动计算出反向结果。
return pred, loss
corpus = load_text8()
corpus = data_preprocess(corpus)
word2id_freq, word2id_dict, id2word_dict = build_dict(corpus)
vocab_size = len(word2id_freq)
corpus = convert_corpus_to_id(corpus, word2id_dict)
corpus = subsampling(corpus, word2id_freq)
corpus_light = corpus[:int(len(corpus) * 0.2)]
dataset = build_data(corpus_light, word2id_dict, word2id_freq)
# 开始训练,定义一些训练过程中需要使用的超参数
batch_size = 512
epoch_num = 3
embedding_size = 200
step = 0
learning_rate = 0.001
# 定义一个使用word-embedding查询同义词的函数
# 这个函数query_token是要查询的词,k表示要返回多少个最相似的词,embed是我们学习到的word-embedding参数
# 我们通过计算不同词之间的cosine距离,来衡量词和词的相似度
# 具体实现如下,x代表要查询词的Embedding,Embedding参数矩阵W代表所有词的Embedding
# 两者计算Cos得出所有词对查询词的相似度得分向量,排序取top_k放入indices列表
def get_similar_tokens(query_token, k, embed):
W = embed.numpy()
x = W[word2id_dict[query_token]]
cos = np.dot(W, x) / np.sqrt(np.sum(W * W, axis=1) * np.sum(x * x) + 1e-9)
flat = cos.flatten()
indices = np.argpartition(flat, -k)[-k:]
indices = indices[np.argsort(-flat[indices])]
for i in indices:
print('for word %s, the similar word is %s' % (query_token, str(id2word_dict[i])))
# 通过我们定义的SkipGram类,来构造一个Skip-gram模型网络
skip_gram_model = SkipGram(vocab_size, embedding_size)
# 构造训练这个网络的优化器
adam = paddle.optimizer.Adam(learning_rate=learning_rate, parameters=skip_gram_model.parameters())
# 使用build_batch函数,以mini-batch为单位,遍历训练数据,并训练网络
for center_words, target_words, label in build_batch(
dataset, batch_size, epoch_num):
# 使用paddle.to_tensor,将一个numpy的tensor,转换为飞桨可计算的tensor
center_words_var = paddle.to_tensor(center_words)
target_words_var = paddle.to_tensor(target_words)
label_var = paddle.to_tensor(label)
# 将转换后的tensor送入飞桨中,进行一次前向计算,并得到计算结果
pred, loss = skip_gram_model(
center_words_var, target_words_var, label_var)
# 程序自动完成反向计算
loss.backward()
# 程序根据loss,完成一步对参数的优化更新
adam.step()
# 清空模型中的梯度,以便于下一个mini-batch进行更新
adam.clear_grad()
# 每经过100个mini-batch,打印一次当前的loss,看看loss是否在稳定下降
step += 1
if step % 1000 == 0:
print("step %d, loss %.3f" % (step, loss.numpy()[0]))
# 每隔10000步,打印一次模型对以下查询词的相似词,这里我们使用词和词之间的向量点积作为衡量相似度的方法,只打印了5个最相似的词
if step % 10000 == 0:
get_similar_tokens('movie', 5, skip_gram_model.embedding.weight)
get_similar_tokens('one', 5, skip_gram_model.embedding.weight)
get_similar_tokens('chip', 5, skip_gram_model.embedding.weight)
具体实现的讲解可以去看百度飞桨团队的讲解
4. 使用PaddleNLP加载词向量
import paddle
from paddlenlp.embeddings import TokenEmbedding, list_embedding_name
paddle.set_device("cpu")
# 查看预训练embedding名称:
print(list_embedding_name()) # ['w2v.baidu_encyclopedia.target.word-word.dim300']
# 初始化TokenEmbedding, 预训练embedding没下载时会自动下载并加载数据
token_embedding = TokenEmbedding(embedding_name="w2v.baidu_encyclopedia.target.word-word.dim300")
# 查看token_embedding详情
# print(token_embedding)
# 使用token_embedding.cosine_sim API 可以轻松地计算两个词汇之间的cosine相似度
if __name__ == '__main__':
score = token_embedding.cosine_sim("中国", "美国")
print(score)
使用PaddleNLP可以大大简化操作的步骤,运行结果如下

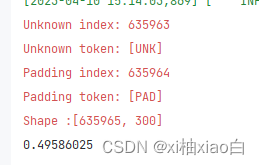
5.使用VisualDL进行词向量可视化
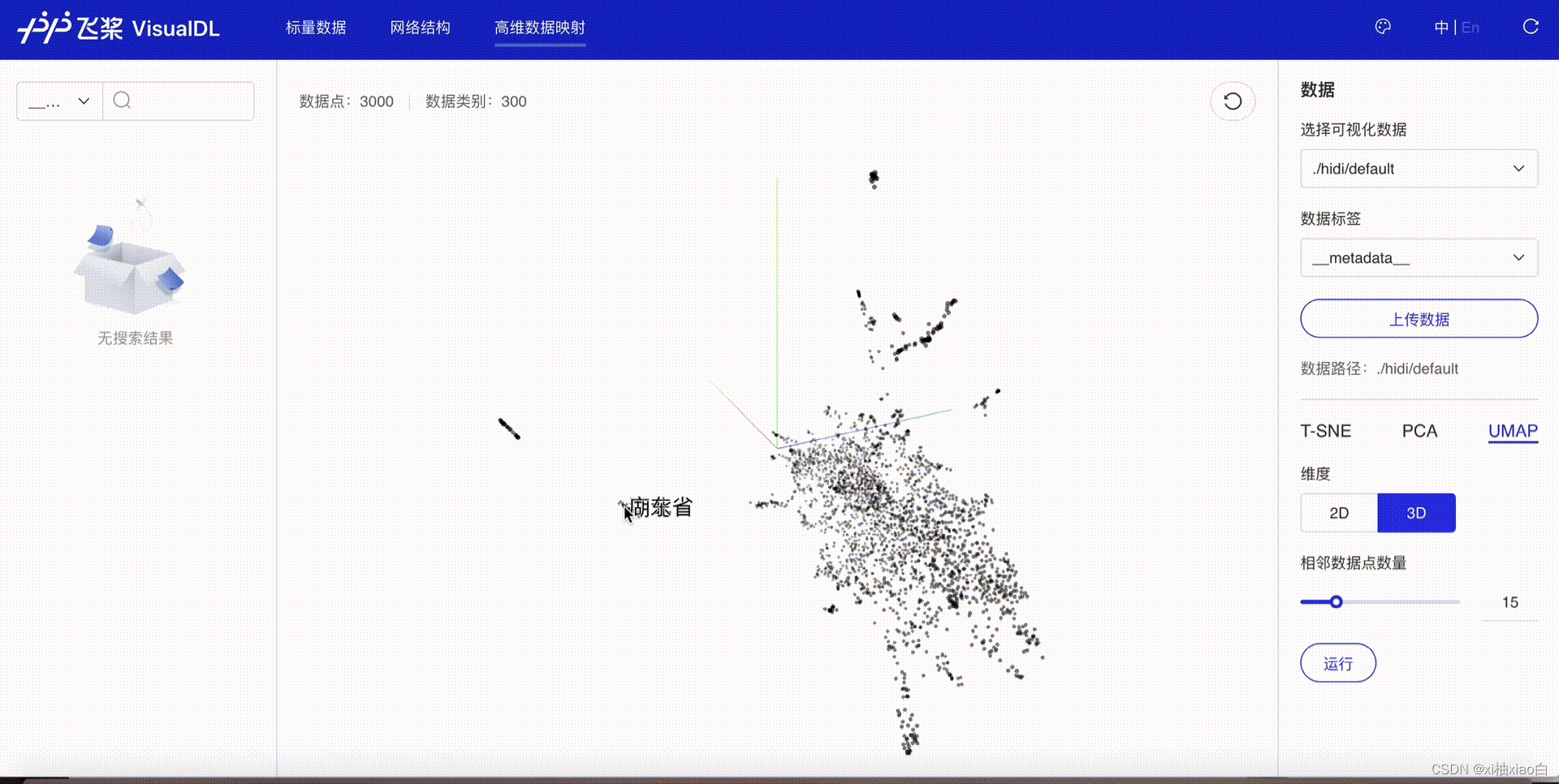
运行代码如下
# 引入VisualDL的LogWriter记录日志
from visualdl import LogWriter
import paddle
from paddlenlp.embeddings import TokenEmbedding, list_embedding_name
from visualdl.server import app
paddle.set_device("cpu")
# 查看预训练embedding名称:
print(list_embedding_name()) # ['w2v.baidu_encyclopedia.target.word-word.dim300']
# 初始化TokenEmbedding, 预训练embedding没下载时会自动下载并加载数据
token_embedding = TokenEmbedding(embedding_name="w2v.baidu_encyclopedia.target.word-word.dim300")
# 获取词表中前1000个单词
labels = token_embedding.vocab.to_tokens(list(range(0,1000)))
test_token_embedding = token_embedding.search(labels)
with LogWriter(logdir='./visualize') as writer:
writer.add_embeddings(tag='test', mat=test_token_embedding, metadata=labels)
if __name__ == '__main__':
app.run(logdir="./visualize")
运行结果如下

按照提示,浏览器进入给出的网址就可以进入查看开头的效果。
6.系统环境
乱下的 不知道为什么就这么多依赖包了 主要是那几个Paddle的包要正确
Windows11 miniconda
(paddle_learn) D:\python_project\paddle_learn\NLP\NLPtest1>pip list
Package Version
aiofiles 23.1.0
aiohttp 3.8.4
aiosignal 1.3.1
altair 4.2.2
anyio 3.6.2
astor 0.8.1
async-timeout 4.0.2
attrdict 2.0.1
attrs 22.2.0
Babel 2.12.1
bce-python-sdk 0.8.79
Brotli 1.0.9
certifi 2022.12.7
cffi 1.15.1
charset-normalizer 3.1.0
click 8.1.3
colorama 0.4.6
colorlog 6.7.0
contourpy 1.0.7
cycler 0.11.0
datasets 2.10.1
decorator 5.1.1
dill 0.3.4
easydict 1.10
entrypoints 0.4
fastapi 0.95.0
ffmpy 0.3.0
filelock 3.11.0
Flask 2.2.3
Flask-Babel 2.0.0
fonttools 4.39.3
frozenlist 1.3.3
fsspec 2023.3.0
future 0.18.3
gevent 22.10.2
geventhttpclient 2.0.2
gradio 3.24.1
gradio_client 0.0.8
greenlet 2.0.2
grpcio 1.52.0
h11 0.14.0
httpcore 0.16.3
httpx 0.23.3
huggingface-hub 0.13.4
idna 3.4
importlib-metadata 6.1.0
importlib-resources 5.12.0
itsdangerous 2.1.2
jieba 0.42.1
Jinja2 3.1.2
joblib 1.2.0
jsonschema 4.17.3
kiwisolver 1.4.4
linkify-it-py 2.0.0
lxml 4.9.2
markdown-it-py 2.2.0
MarkupSafe 2.1.2
matplotlib 3.7.1
mdit-py-plugins 0.3.3
mdurl 0.1.1
mpmath 1.3.0
multidict 6.0.4
multiprocess 0.70.12.2
numpy 1.24.2
onnx 1.13.1
opencv-contrib-python 4.7.0.72
opencv-python 4.7.0.72
opt-einsum 3.3.0
orjson 3.8.7
packaging 23.0
paddle-bfloat 0.1.7
paddle2onnx 1.0.6
paddlefsl 1.1.0
paddlehub 2.3.1
paddlenlp 2.5.2
paddlepaddle-gpu 2.4.2
pandas 1.5.3
Pillow 9.5.0
pip 23.0.1
pkgutil_resolve_name 1.3.10
protobuf 3.20.0
psutil 5.9.4
pyarrow 11.0.0
pycparser 2.21
pycryptodome 3.17
pydantic 1.10.6
pydub 0.25.1
Pygments 2.14.0
pyparsing 3.0.9
pyrsistent 0.19.3
python-dateutil 2.8.2
python-multipart 0.0.6
python-rapidjson 1.10
pytils 0.4.1
pytz 2022.7.1
PyYAML 6.0
pyzmq 25.0.1
rarfile 4.0
requests 2.28.2
responses 0.18.0
rfc3986 1.5.0
rich 13.3.2
scikit-learn 1.2.2
scipy 1.10.1
semantic-version 2.10.0
sentencepiece 0.1.96
seqeval 1.2.2
setuptools 65.6.3
six 1.16.0
sniffio 1.3.0
starlette 0.26.1
sympy 1.11.1
threadpoolctl 3.1.0
tools 0.1.9
toolz 0.12.0
tqdm 4.65.0
tritonclient 2.31.0
typer 0.7.0
typing_extensions 4.5.0
uc-micro-py 1.0.1
urllib3 1.26.15
uvicorn 0.21.1
visualdl 2.4.2
websockets 10.4
Werkzeug 2.2.3
wheel 0.38.4
wincertstore 0.2
x2paddle 1.4.0
xxhash 3.2.0
yarl 1.8.2
zipp 3.15.0
zope.event 4.6
zope.interface 6.0