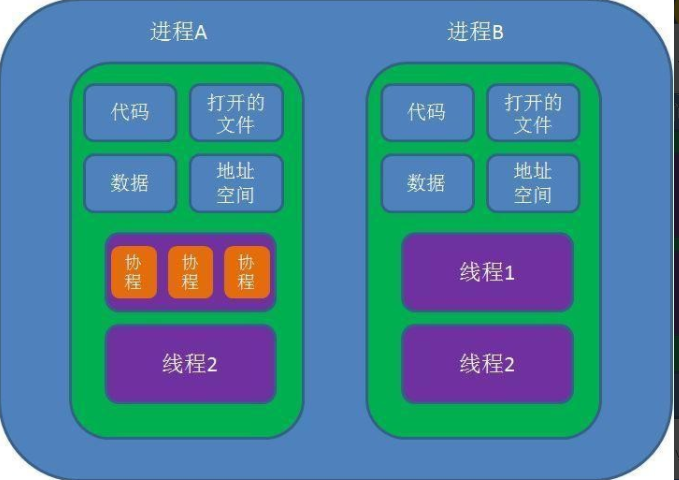
总结:
(1)生成摘要等模型,虽然有评估方法,但是人类总结的质量依旧难以相比


总结:
(1)在各种NLP任务中,大规模语言模型的预训练以及取得了很高的性能
(2) 当把大模型用于下游任务的时候,通常需要监督数据进行微调,数据一般来源于人类总结的证据,来最大化似然函数
(3)这些方法提高了性能,但是呢存在无法对其的问题,微调最大化似然的结果,和人类作出的高质量回答是不一致的
(4)导致问题的主要是:1、未区分重要错误和非重要错误 2、模型选取的数据有低质量的,且shuffle后导致低性能

总结:
(1) 我们的目标就是让最终结果接近我们所希望的,然后现阶段集中在英文文本摘要上面,现存ROUGE等评估手段,一直遭受不准确的批评
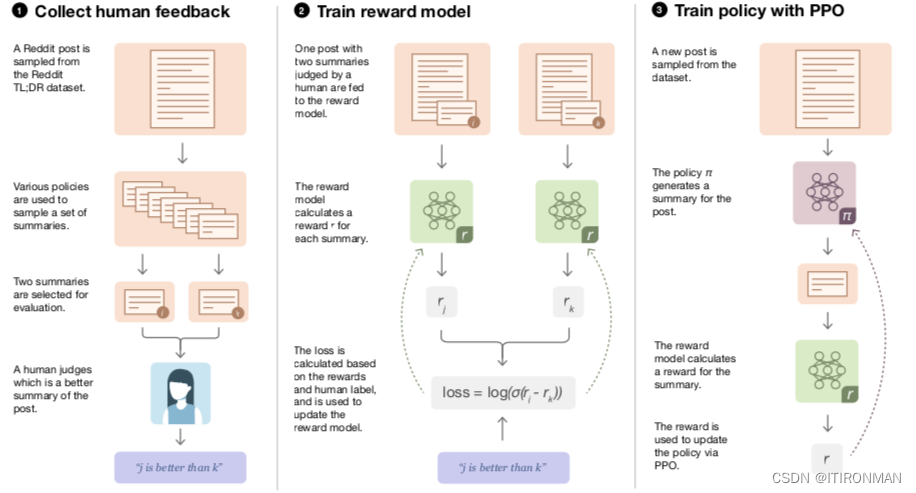
(2)我们首先收集成对摘要之间的人类偏好数据集,然后通过监督学习训练奖励模型(RM)来预测人类偏好的摘要。最后,我们通过强化学习(RL)来训练策略,以最大化RM给出的分数;该策略在每个“时间步骤”生成一个文本令牌,并使用基于RM“奖励”的PPO算法[58]更新整个生成的摘要


总结(四个贡献):
(1) 我们发现,在英语总结方面,有人类反馈的训练显著优于非常强的基线
(2)我们发现人类反馈模型比监督模型更好地推广到新领域
(3)我们对我们的政策和奖励模式进行了广泛的实证分析,优于ROUGE评价
(4)我们公开发布我们的人类反馈数据集,以供进一步研究

总结:
(1)高级方法
(2)从现有的政策中收集样本,并将比较结果发送给人类
(3)从人类的比较中学习奖励模式
(4)针对奖励模式优化策略