标准模板库STL
- string字符串
- 如何对string字符串的初始化(声明)?
- 如何遍历string对象进行访问?
- 如何对string类型的字符串进行增删改查?
- 对string字符串增加一些字符
- 对string字符串删除一些字符
- 对string字符串改动一些字符
- 在string字符串中查找一些字符
- string类的一些功能性API
- 对string字符串内的某一段子串进行替换
- 两个字符串进行比较,判断是否相等
- string字符串的大小size和容量capacity
- string 和 C-Style 字符串的转换
- 字符串和数字之间的转换
- vector向量
- 如何声明vector数组,vector数组可以存储哪些类型元素?
- 如何遍历vector对象?
- 如何访问vector内的元素
- vector容器的增删改查
- 向vector添加元素
- 删除vector中的元素
- 改动vector中的元素
- 查找vector中的元素(可以判断是否在vector中以及所在位置)
- 有关vector内存大小的一些操作
- 查询vector容器中元素的个数
- 判断vector容器是否为空
- 重新指定vector容器的长度
- 查看vector容器的容量
- 手动扩容
- 二维vector的一些碎碎念
- queue队列
- queue的基本概念
- 队列queue的初始化
- 向队列中添加元素
- 访问队尾元素
- 访问队头元素
- 删除队头元素(弹出队头)
- 查看队列的长度
- 判断队列是否为空
- 打印队列
- stack栈
- stack的基本概念
- 如何声明一个栈stack
- 向栈中添加元素
- 弹出栈顶元素(也叫从栈中删除栈顶元素)
- 访问栈顶元素(仅仅是访问,不删除)
- 判断栈是否为空
- 打印stack元素
- deque双向队列
- deque的基本概念
- deque的初始化(声明、定义)
- 队列的赋值操作
- 队列的内存大小API
- 遍历双向队列deque
- deque的双端插入与删除
- 访问双向队列的队头和队尾元素
- 在双向队列deque的任意位置插入元素
- deque的删除操作
- list链表
- list的初始化(定义&声明)
- 访问链表头元素和链表尾元素
- list元素的插入和删除操作
- 在链表list的头尾进行插入和删除
- 在链表list的任意位置插入或者删除
- 删除链表中所有等于elem的元素
- 清空list元素,并判断是否为空
- 翻转链表
- 排序链表
- set集合
- set 容器基本概念
- set的初始化操作
- set的遍历访问
- set的插入和删除操作
- set的查找操作(可以说是set最重要API)
- pair数据结构的使用
- multiset的使用(set的进化版,可以存在重复元素)
- map映射(类似于python中的字典)
- map基本概念
- map的声明初始化操作
- 遍历map里的元素
- map插入数据的操作
- map删除数据操作
- 修改map里的数据
- 查找map中的数据
- 交换两个map
- 返回当前map所能容纳的最大容量
- map不允许两个相同的key出现
- 不同容器的使用场景(容器的总结)
- vector<元素类型>
- list<元素类型>
- deque<元素类型>
- stack<元素类型>
- queue<元素类型>
- map<关键字类型,值类型>
- set<元素类型>
string字符串
提到字符串,我们会想起C语言中的char *,这是一个指针。而在STL中string也是用来声明字符串的,但是string是一个类,需要导入库#include<string>。 String封装了char *,管理这个字符串,是一个char*型的容器。
string本质上是一个动态的char数组。
如何对string字符串的初始化(声明)?
使用String字符串的第一步,那就是定义、初始化、声明字符串。不要把最简单的东西不当回事,ACM模式下,很容易写不出来。下面介绍声明String字符串的若干方法。
背景定义:封装了一下打印字符串的函数
void printStr(string & str) {
cout << str << endl;
}
- 初始化一个空的字符串,这不叫初始化了,这叫定义一个空字符串。(打印为空)
string s1;
printStr(s1); //
- 用
const char*类型的字符串赋值给string对象,本质上发生的是string类内的运算符重载操作:string& operator=(const char* s)
//直接初始化一个string类型的字符串,但其实是:string = const char *,发生的是运算符重载
string s2 = "hello world";
printStr(s2);//hello world
string类内部还有两个运算符重载操作string& operator=(const string& s)和string& operator=(const char c)也就是说,下面两个操作也可以发生:用char字符赋值string对象,用一个已经存在的string对象赋值新的string对象
string s2 = 'c';//string& operator=(const char c)
string s2_2 = s2;//string& operator=(const string& s)
- 使用
const char*类型的字符串调用string类内的有参构造函数string(const char* s),完成string的初始化
//使用const char *初始化string,发生的是调用有参构造函数
string s3("hello world");
printStr(s3);//hello world
- 跟上面所达到的目的一样,也是调用有参构造函数
string(const char* s),只不过把const char*类型的定义写在了外面,各有自己的应用场合
//用const char *类型的字符串初始化为string类型
const char *c_s = "hello world";
string s4(c_s);
printStr(s4);//hello world
- 使用
string类型的字符串调用string类内的有参构造函数string(const string& str),完成string对象的初始化
//使用string类型的字符串拷贝构造一个string字符串
string s2 = "hello world";
string s5(s2);
printStr(s5);//hello world
- 截取
const char*字符串,调用函数string (const char* s, size_t nn)截取s的前n个字符
//用字符串的前n个字符构造string类
const char* url = "http://www.cplusplus.com/reference/string/string/string/";
string s6(url, 8);
printStr(s6);//http://w
- 从指定位置开始截取,然后指定截取长度,调用
string (const string& str, size_t pos, size_t len)。可以看到printStr(s7)打印的是lo w说明空格也算字符,通过这种索引截取字符串,也能证明string对象本质就是一个char字符数组。
string s2 = "hello world";
//初始化s7为s2的部分字符,从s2的第3个字符开始,往后数4个字符,然后截取下来作为s6的初始值
string s7(s2, 3, 4);
printStr(s7);//lo w
//如果截取的字符超过了s2,那就在s2的最后一个字符停下
string s8(s2, 9, 4);
printStr(s8);//ld
- 用
n个char字符初始化string类字符串,本质调用的是构造函数string(int n, char c)。必须是单个字符,不能是字符串,多个字符组成的char字符,也只会取最后一个字符。
//用n个char字符构造,一定是字符,而不是字符串
string s9(10, 'x');
printStr(s9);//xxxxxxxxxx
//如果不是单个字符,就直接读取最后一个字符
string s10(10, 'xs');
printStr(s10);//ssssssssss
必须是单引号字符,不可以是双引号字符串。

可以看出,string类的对象本质上就是一个char字符数组,由一个一个字符组成的数组字符串。
如何遍历string对象进行访问?
我们了解到,string类的对象本质上就是一个char字符数组,由一个一个字符组成的数组字符串。所以,string是可以被遍历的,接下来介绍几种遍历string字符串并访问字符的方法:
- 普通for循环遍历,使用下标访问。
size()函数可以返回string字符串的有效长度。其实这个下标[]本质就是string类内部实现了运算符重载char& operator[](int n);
string s1 = "hello world";
//下标遍历访问法,
for (int i = 0; i < s1.size(); i++) {
cout << s1[i];
}
//hello world
- 普通for循环遍历,然后使用string类内部的成员函数
at()来访问对应索引的字符。
string s1 = "hello world";
//at()遍历访问法
for (int i = 0; i < s1.size(); i++) {
cout << s1.at(i);
}
//hello world
- 范围for循环遍历,直接拿到的就是string中的字符。通常用auto声明类型,省事。
string s1 = "hello world";
//范围for遍历
for (auto s_item : s1) {
s_item = 's';
cout << s_item;
}
//sssssssssss
printStr(s1);//hello world
还有一种情况是这样的:设置为引用类型s_item,这样的话就可以通过修改s_item 来修改外面的string了。不采用引用传递,就像上面一样,不会更改原本的s1的数据。
string s1 = "hello world";
//范围for遍历
for (auto &s_item : s1) {
s_item = 's';
cout << s_item;
}
//sssssssssss
printStr(s1);//sssssssssss
- 正向迭代器遍历。迭代器通过
string::iterator来定义,通过begin()和end()成员函数来声明。其中it_begin指向string字符串的首字符,it_end指向的不是尾字符,而是尾字符的下一位。因为迭代器也遵循左闭右开。迭代器的本质就是指针,所以取出对应的元素,只需要*it_begin即可。

string s1 = "hello world";
//迭代器遍历(正向),it_begin指向string的第一个字符,it_end指向的则是最后字符的下一个位置,因为迭代器遵循左闭右开原则
string::iterator it_begin = s1.begin();
string::iterator it_end = s1.end();
for (; it_begin != it_end; it_begin++) {
cout << *it_begin;
}
//hello world
- 反向迭代器遍历。反向迭代器跟正向迭代器不同,定义方式变为了
string::reverse_iterator,声明方式则变成了rbegin()和rend()。其中it_begin指向string字符串的尾字符,it_end指向的不是首字符,而是首字符的前一位。反向迭代器遵循左开右闭原则。最最重要的是:it_rbegin的索引仍然是从0开始,而不是从size-1开始。因此,it_rbegin遍历字符串仍要不断++,而不是--。

//迭代器遍历(反向),it_rbegin指向的是最后一个字符,it_rend指向的是第一个字符前面的位置,但是反向迭代器的索引位置是反着的,因此it_rbegin向前变量是++而不是--
string::reverse_iterator it_rbegin = s1.rbegin();
string::reverse_iterator it_rend = s1.rend();
for (; it_rbegin != it_rend; it_rbegin++) {
cout << *it_rbegin << endl;
}
//dlrow olleh
从结果可以看到,这种反向迭代器获取元素的方式会翻转字符串。
如何对string类型的字符串进行增删改查?
对string字符串增加一些字符
- 在尾部增加单个字符,用
string类的push_back()成员函数。连续添加,那就相当于添加字符串了。
string s1 = "hello ";
//在尾部插入字符.push_back只能插入单个字符
s1.push_back('w');
s1.push_back('o');
s1.push_back('r');
s1.push_back('l');
s1.push_back('d');
printStr(s1);//hello world
- 还可以使用
string类的成员函数append()直接在尾部添加字符串
string s1 = "hello ";
//在尾部追加字符串,可以是多个字符组成的字符串
s1.append("world");
printStr(s1);//hello world
- 也可以使用一种最简单暴力的手段,使用运算符重载之后的
'+='直接进行append操作。这也能起到在尾部添加字符串的目的。(这个是最常用的)
string s1 = "hello ";
//这种也是追加字符串,跟append效果一样
s1 += "world";
printStr(s1);//hello world
- 使用
string类内部的函数string& insert(int pos, const char* s),在pos位置插入const char*风格字符数组。想要实现在尾部插入,那pos就设置为s1.size()。(不推荐使用,因为这个函数本质跟数组插入元素一样,可能会复杂度变高)
string s1 = "hello ";
//insert是在任意位置插入元素,只不过我这里选择的是尾部,尽量少用,因为本质是数组插入
s1.insert(s1.size(), "world");
printStr(s1);//hello world
insert函数有三种重载形式:
string& insert(int pos, const char* s); // 在pos位置插入C风格字符数组
string& insert(int pos, const string& str); // 在pos位置插入字符串str
string& insert(int pos, int n, char c); // 在pos位置插入n个字符c
既可以接收const char*,也可以接收const string&,
//可以接受两种类型的字符串
const char *ss = "world";
//string ss = "world";
s1.insert(3, ss);
printStr(s1);//helworldlo
还可以传入两个参数,表示插入n个字符c。
string s1 = "hello ";
//表示在3位置插入4个'x'
s1.insert(3, 4,'x');
printStr(s1);//helxxxxlo
对string字符串删除一些字符
- 从某个位置一直删除到字符末尾:
string& erase(int pos, int n = npos); // 删除从pos位置开始的n个字符,如果第二个参数缺省,则默认删除到末尾。
string s1 = "hello ";
s1.erase(1);
printStr(s1);//h
- 删除某一段字符,那就不能缺省第二个参数
string s1 = "hello ";
s1.erase(0, 2);//从第0位开始,删除2个
printStr(s1);//llo
- 如果删除的个数大于剩余元素的个数,那么就直接删除到尾部。(明显100大于从1开始到末尾的元素个数,)
string s1 = "hello ";
s1.erase(1, 100);//从第1位开始,删除100个
printStr(s1);//h
对string字符串改动一些字符
string的修改比较简单,string类中对[ ]运算符进行了重载,我们可以像数组一样一样直接使用[ ]加下表的方式对string值进行修改。
string s1 = "hello ";
s1[2] = 'p';
printStr(s1);//heplo
在string字符串中查找一些字符
首先介绍一个取出string字符串子串的内置函数:string substr(int pos, int n),获取pos位置开始,n个字符的子串。跟使用构造函数string (const string& str, size_t pos, size_t len)时效果一样,都是截取子串。
string s1 = "hello ";
string sub_str = s1.substr(2, 3);//string substr(int pos, int n),获取pos位置开始,n个字符的子串
printStr(sub_str);//llo
查找字符串中的字符,有一个非常重要的内置成员函数:find()。
int find(const string& str, int pos = 0) const;
// 查找str在当前字符串中第一次出现的位置,从pos开始查找,pos默认为0
int find(const char* s, int pos = 0) const;
// 查找C风格字符串s在当前字符串中第一次出现的位置,从pos开始查找,pos默认为0
int find(const char* s, int pos, int n) const;
// 从pos位置查找s的前n个字符在当前字符串中第一次出现的位置
int find(const char c, int pos = 0) const;
// 查找字符c第一次出现的位置,从pos开始查找,pos默认为0
下面介绍其用法:
- 由string对象调用,必须手动传入的参数是需要在原字符串s1中查找的子串,即sub_str。find函数的功能就是查找子串在原字符串中的位置,返回第一次出现位置的索引。
string s1 = "hello world";
string sub_str = "llo";
cout << s1.find(sub_str) << endl;//2
当我查找"llo"时,就会首先确定字符串中有没有连续的子串"llo",如果有,再定位第一次出现时子串第一个字符在原字符串中的索引,并返回。
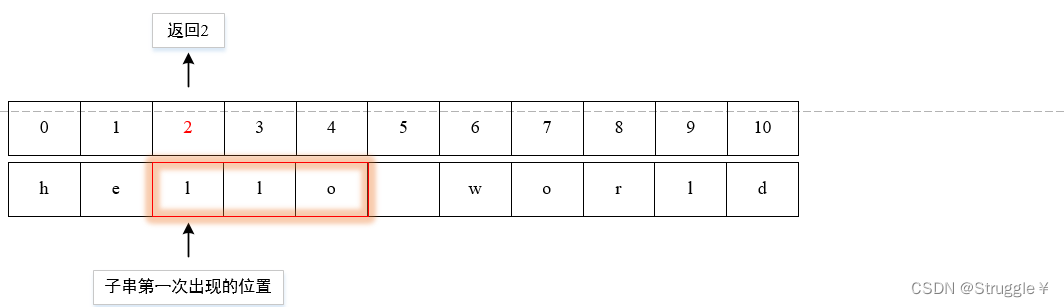
接下来我多多举例,更加清晰地了解find函数的作用。
- 设置:子串不仅可以是
string类型的,也可以是const char*类型的。原字符串中有两处子串,find函数只会找到首次出现的,不会理会第二次出现的
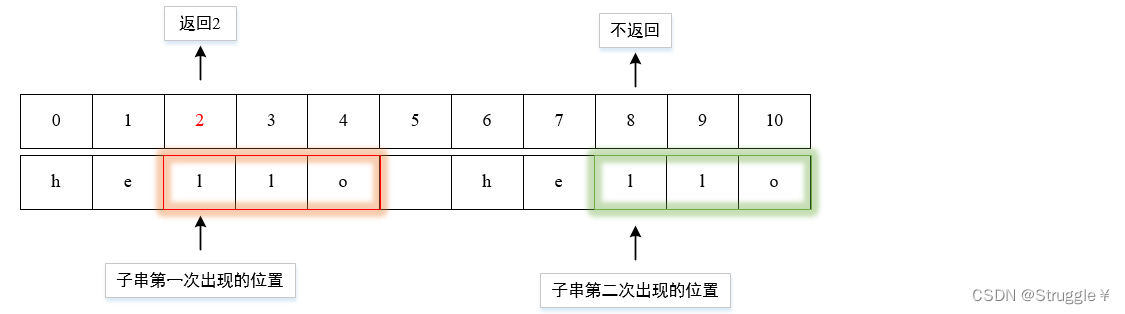
string s1 = "hello hello";
const char* sub_str = "llo";
cout << s1.find(sub_str, 0) << endl;//2
- 设置:如果从索引为3处开始找,那么就不会找到前面的子串了。在s1[3:]的范围内,索引8出现的子串才是第一次被发现的子串,因此返回8。(注意这里返回的8是看原字符串说的,而不是看查找区间)

string s1 = "hello hello";
const char* sub_str = "llo";
cout << s1.find(sub_str, 3) << endl;//8
- 设置:不仅可以查找子串,还可以查找单个字符(const char sub_str = ‘l’;)。也是根据查找范围,找到第一个出现的索引。
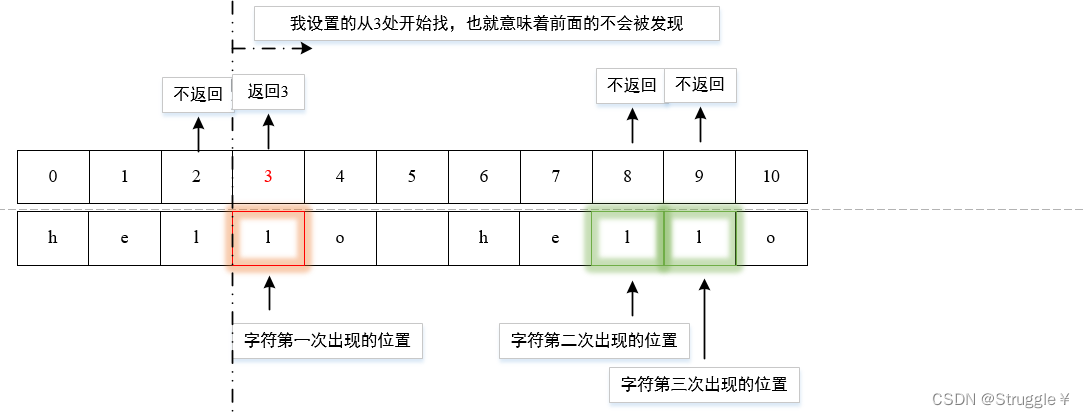
string s1 = "hello hello";
const char sub_str = 'l';
cout << s1.find(sub_str,3) << endl;//3
- 我们有一个应用场景,需要判断
find函数没找到的情况,string内置了一个成员变量string::npos,用来标志find函数的返回值没找到,要记住这个内置的成员变量,以后会有用的。为什么要记住这个变量呢,因为如果find没找到,就会返回4294967295这一串很乱的数字,不利于我们确认标志位。
string s1 = "hello hello";
const char* sub_str = "xxx";
if (s1.find(sub_str, 3) == string::npos) {
cout << "没找到" << endl;//没找到
}
else
{
cout << s1.find(sub_str, 3) << endl;//3
}
- 小练习:从网址中
https://github.com/XHB-ZMM/BTrans-with-LC-for-UnbiasedSGG/tree/master找出域名github.com。
string s1 = "https://github.com/XHB-ZMM/BTrans-with-LC-for-UnbiasedSGG/tree/master";
//首先定位://的位置
int pos = s1.find("://");
//然后向后移动三位
int start = pos + 3;
//从://后开始找,直到找到第一个'/'停下
int end = s1.find('/', start);
//start就是域名的开始索引,end-start就是域名所占字符的个数,调用substr函数即可截取域名
string sub_str = s1.substr(start, end-start);
printStr(sub_str);
- 上述都是从前往后查找,string其实还提供了从后往前查找的函数
int rfind(const string& str, int pos = npos) const;默认是从最后一位向前查找,因此第二个参数可以不写。功能就是从pos开始向前查找,找到首次出现的字符str,就返回索引。
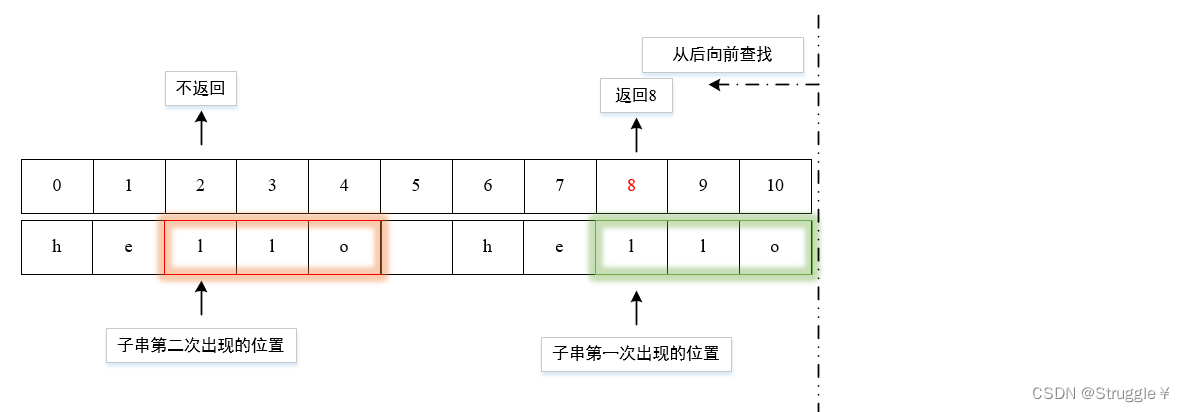
string s1 = "hello hello";
const char* sub_str = "llo";
cout << s1.rfind(sub_str) << endl;//8
string类的一些功能性API
对string字符串内的某一段子串进行替换
string& replace(int pos, int n, const string& str);
// 替换从pos开始n个字符为字符串s
string& replace(int pos, int n, const char* s);
// 替换从pos开始的n个字符为字符串s

string s1 = "hello hello";
printStr(s1.replace(0, 5, "world"));//world hello
- 假如我要替换的字符串,和前面的数量不吻合,会发生什么?
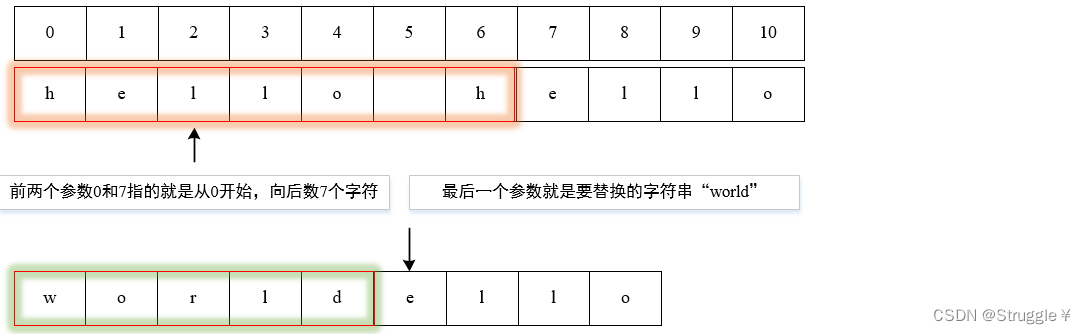
string s1 = "hello hello";
printStr(s1.replace(0, 7, "world"));//worldello
replace函数的原理是先通过前两个参数定位要被替换的字符串,然后把它们从内存中抹去,然后把第三个参数补在这块区域上,额外多出来的区域自动消失。
两个字符串进行比较,判断是否相等
int compare(const string& s) const; // 与字符串s比较
int compare(const char* s) const; // 与C风格字符数组比较
- compare函数用来比较两个字符串是否相等。如果相等则会返回0,如果不相等则会返回-1或1。至于是1还是-1,是根据字典序进行比较的,具体详情看这篇博客。
string s1 = "hello hello";
cout << s1.compare("hello hello") << endl;//0
或者使用重载后的’=='也可以判断是否相等。
string s1 = "hello hello";
const char * s2 = "hello hello";
cout << (s1 == s2) << endl;//1
string字符串的大小size和容量capacity
size指的是当前字符串的长度,而capacity指的是内存中存储这个字符串的内存容量。一般不相等,容量会稍微大一些。
string s1 = "hello hello";
cout << s1.size() << endl;//11
cout << s1.capacity() << endl;//15
为什么这么说呢?因为我清空字符串后,容量不变,size正常的清空了。
string s1 = "hello hello";
cout << s1.size() << endl;//11
cout << s1.capacity() << endl;//15
s1.clear();
cout << s1.size() << endl;//0
cout << s1.capacity() << endl;//15
string 和 C-Style 字符串的转换
string转const char*,用的是string内置的c_str()函数
string str = "demo";
const char* cstr = str.c_str();
const char*转string,直接string(const char* )就行,本质是string有参的构造函数,只不过可以接受const char*类型的参数
const char* cstr = "demo";
string str(cstr); // 本质上其实是一个有参构造
字符串和数字之间的转换
- 数字转化为字符串:调用
to_string函数。
#include <string>
using namespace std;
/** 带符号整数转换成字符串 */
string to_string(int val);
string to_string(long val);
string to_string(long long val);
/** 无符号整数转换成字符串 */
string to_string(unsigned val);
string to_string(unsigned long val);
string to_string(unsigned long long val);
/** 实数转换成字符串 */
string to_string(float val);
string to_string(double val);
string to_string(long double val);
只需要调用to_string函数即可,就可以将数字转换为字符串,然后就可以按照字符串的要求进行操作了。
int a = 10;
string s1 = to_string(a);
printStr(s1);//10
double a = 10;
string s1 = to_string(a);
printStr(s1);//10.00000
- 字符串变为数字。如果想要转换为
int类型,那就用stoi()函数;如果想要转换为float类型,那就用stof()函数;如果想要转换为double类型,那就用stod()函数。
string s1 = "10";
int a = stoi(s1);
cout << a + 1 << endl;
string s2 = "10.0";
float b = stof(s2);
cout << b + 1 << endl;
string s3 = "10.00000";
double c = stod(s3);
cout << c + 1 << endl;
vector向量
如何声明vector数组,vector数组可以存储哪些类型元素?
vector是STL的动态数组,可以在运行中根据需要改变数组的大小。也就是我们熟知的动态扩容技术。
因为它以数组的形式储存,所以它的内存空间是连续的。
vector的头文件为#include<vector>,由于vector仍是在std命名空间下,所以还要using namespace std;
背景知识:实现一个接口打印vector里的东西,这里要用泛型函数模板,因为vector<数据类型> 变量名,就是泛型。
template<typename T>
void printVec(vector<T>& v) {
for (T c : v) {
cout << c << ' ';
}
cout << endl;
}
下面介绍如何声明vector数组:
- 声明一个空的
vector<int>数组,里面啥也没有的那种。根据打印结果,可以看出来vector数组里是什么情况。声明一个空的vector里面什么也没有,所以size等于0,且打印出来的vector为空。
vector<int> v1;
cout << v1.size() << endl;//0
printVec(v1);//
- 声明一个已知内容的
vector<int>数组,里面初始化为10个4,
vector<int> v2 = {4,4,4,4,4,4,4,4,4,4};
cout << v2.size() << endl;//10
printVec(v2);//4 4 4 4 4 4 4 4 4 4
- 声明一个大小为10的
vector<int>数组,第二个参数没写,默认填充为0。
vector<int> v3(10);
cout << v3.size() << endl;//10
printVec(v3);//0 0 0 0 0 0 0 0 0 0
- 声明一个大小为10的
vector<int>数组,第二个参数写了4,那就把10个数全部填充为4
vector<int> v4(10,4);
cout << v4.size() << endl;//10
printVec(v4);//4 4 4 4 4 4 4 4 4 4
- 声明一个大小为10的
vector<float>数组,第二个参数写了4.1,那就把10个数全部填充为4.1
vector<float> v5(10, 4.1);
cout << v5.size() << endl;//10
printVec(v5);//4.1 4.1 4.1 4.1 4.1 4.1 4.1 4.1 4.1 4.1
- 声明一个大小为10的
vector<string>数组,第二个参数写了具体的字符串,那就把10个字符串部填充为 “null”
vector<string> v6(10, "null");
cout << v6.size() << endl;//10
printVec(v6);//null null null null null null null null null null
- 声明一个大小为10的
vector<string>数组,第二个参数写了具体的字符串,那就把10个字符串部填充为 “hello”
vector<string> v7(10, "hello");
cout << v7.size() << endl;//10
printVec(v7);//hello hello hello hello hello hello hello hello hello hello
- 声明一个大小为10的
vector<string>数组,并采用构造函数的方式初始化,本质是用v7从头到尾的内容初始化v8,也就是发生了拷贝构造的操作
vector<string> v8(v7.begin(),v7.end());
cout << v8.size() << endl;//10
printVec(v8);//hello hello hello hello hello hello hello hello hello hello
上述方法都是在声明时就初始化了,如果有这样的需求:声明时不初始化,用到的时候再分配数据给vector,这又该如何实现?好在vector提供了一个内置函数assign(),用来在任意位置分配数据给vector的。 有三种使用形式:
- 直接像构造函数一样,分配10个整型变量4到v1中
vector<int> v1;
v1.assign(10, 4);
printVec(v1);//4 4 4 4 4 4 4 4 4 4
- 利用已存在的v1分配v2,assign需要接收两个迭代器,一个是begin,一个是end
vector<int> v1;
v1.assign(10, 4);
printVec(v1);//4 4 4 4 4 4 4 4 4 4
vector<int> v2;
v2.assign(v1.begin(), v1.end());
printVec(v2);//4 4 4 4 4 4 4 4 4 4
当然,也可以使用反向迭代器,还能达到翻转vector的效果呢!
vector<int> v1 = { 1,2,3,4,5,6,7,8,9 };
printVec(v1);//1 2 3 4 5 6 7 8 9
vector<int> v2;
v2.assign(v1.rbegin(), v1.rend());
printVec(v2);//9 8 7 6 5 4 3 2 1
- 利用普通数组,分配数据给vector数组。此时的assign输入参数本质上还是指针,跟迭代器一样。
int arr[] = { 1,2,3,4,5,6,7,8,9 };
vector<int> v2;
v2.assign(arr, arr + sizeof(arr)/sizeof(int));
printVec(v2);//1 2 3 4 5 6 7 8 9
- vector还可以存储自定义类型。存结构体或者类 vector<结构体名或者类名> v;比如
vector<Person> v。
class Person
{
public:
int m_age;
string m_name;
Person(int age, string name) {
m_age = age;
m_name = name;
}
};
vector<Person> v0(5,Person(18,"zmm"));
cout << v0.size() << endl;//10
可以通过迭代器,遍历访问Person对象里的成员变量:
vector<Person>::iterator it_begin = v1.begin();
vector<Person>::iterator it_end = v1.end();
for (; it_begin != it_end; it_begin++) {
cout << "年龄:" << it_begin->m_age << " 姓名:" << it_begin->m_name << endl;
}
//年龄:18 姓名:zmm
//年龄:18 姓名:zmm
//年龄:18 姓名:zmm
//年龄:18 姓名:zmm
//年龄:18 姓名:zmm
如何遍历vector对象?
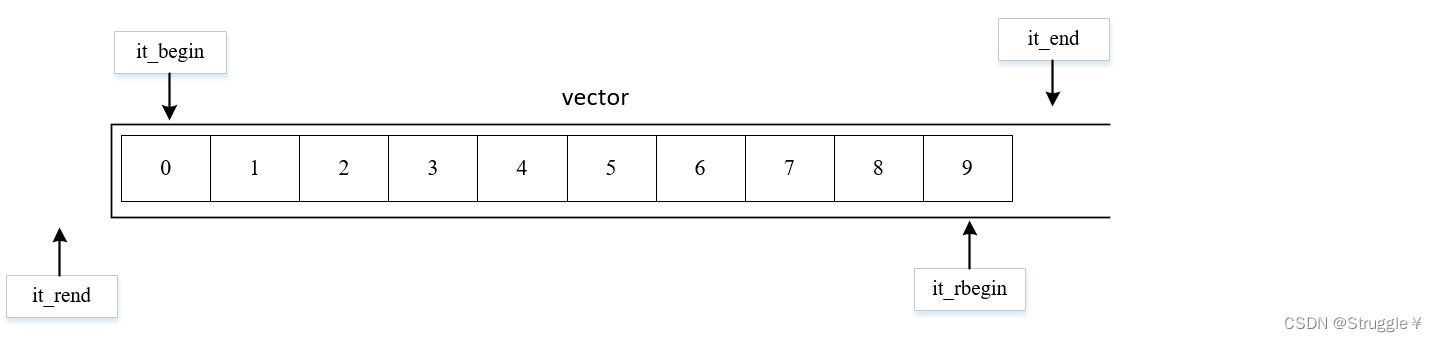
迭代器遍历是最专业的遍历方式,分为正向迭代器和反向迭代器。正向迭代器从前向后遍历,反向迭代器从后向前遍历。都遵循左闭右开,即[begin,end)。下面首先介绍这两种迭代器:
- 正向迭代器,正向迭代器的声明都是
容器类型::iterator,由begin()和end()方法生成。遍历的话就是从it_begin开始,一直到it_begin == it_end结束,每次it_begin++。
vector<int> v1 = {0,1,2,3,4,5,6,7,8,9};
vector<int>::iterator it_begin = v1.begin();
vector<int>::iterator it_end = v1.end();
for (; it_begin != it_end; it_begin++) {
cout << *it_begin <<' ';
}
//0,1,2,3,4,5,6,7,8,9
- 反向迭代器,正向迭代器的声明都是
容器类型::iterator,由rbegin()和rend()方法生成。使用while循环也是遍历的好方法。遍历的话就是从it_rbegin开始,一直到it_rbegin == it_rend结束,每次it_rbegin++。注意:反向迭代器的it_rbegin从末尾开始,但是it_rbegin++是向前走,而不是向后走。
vector<int> v1 = {0,1,2,3,4,5,6,7,8,9};
vector<int>::reverse_iterator it_rbegin = v1.rbegin();
vector<int>::reverse_iterator it_rend = v1.rend();
while (it_rbegin != it_rend)
{
cout << *it_rbegin << ' ';
it_rbegin++;
}
//9 8 7 6 5 4 3 2 1 0
如果给出一幅图可以看懂正向迭代器和反向迭代器,下面的图很合适:
- 除了使用专业的迭代器遍历,还有更简单的遍历方式,也就是for范围遍历:
vector<int> v1 = {0,1,2,3,4,5,6,7,8,9};
for (auto item : v1) {
cout << item << ' ';
}
//0,1,2,3,4,5,6,7,8,9
如何访问vector内的元素
at()方法访问
vector<int> v1 = {0,1,2,3,4,5,6,7,8,9};
for (int i = 0; i < 10; i++) {
cout << v1.at(i) << " ";
}
//9 8 7 6 5 4 3 2 1 0
- 下标
[]访问
vector<int> v1 = {0,1,2,3,4,5,6,7,8,9};
for (int i = 0; i < 10; i++) {
cout << v1[i] << " ";
}
//9 8 7 6 5 4 3 2 1 0
- 迭代器指针间接访问
vector<int> v1 = {0,1,2,3,4,5,6,7,8,9};
for (vector<int>::iterator it = v1.begin(); it != v1.end(); it++) {
cout << *it << " ";
}
//9 8 7 6 5 4 3 2 1 0
- 取出vector中的首元素或者尾元素
vector<int> v1 = {0,1,2,3,4,5,6,7,8,9};
cout << v1.front() << endl;//0
cout << v1.back() << endl;//9
vector容器的增删改查
向vector添加元素
push_back()是最经典的向vector尾部添加数据的方法,但是C++11引入了emplace_back()方法,跟push_back()的功能一样,也是向尾部添加。底层实现的机制不同。push_back()向容器尾部添加元素时,首先会创建这个元素,然后再将这个元素拷贝或者移动到容器中(如果是拷贝的话,事后会自行销毁先前创建的这个元素);而emplace_back()在实现时,则是直接在容器尾部创建这个元素,省去了拷贝或移动元素的过程。
vector<int> v1;
for (int i = 0; i < 10; i++) {
v1.emplace_back(i);
}
for (int i = 9; i >= 0; i--) {
v1.push_back(i);
}
printVec(v1);//0 1 2 3 4 5 6 7 8 9 9 8 7 6 5 4 3 2 1 0
无论是push_back还是emplace_back都是向vector的尾部插入元素。最灵活的添加元素方法,还是insert(),任意位置插入任意元素。vector内部重载了三种insert用法,下面一一介绍其用法:
insert(const_iterator pos, T elem); // 在pos位置处插入元素elem
insert(const_iterator pos, int n, T elem); // 在pos位置插入n个元素elem
insert(const_iterator pos, const_iterator beg, const_iterator end); // 将[beg, end)区间内的元素插到位置pos
注意:insert()的第一个参数必须是迭代器表示的位置,不能是普通的int变量。
- 在指定
pos位置,插入元素elem:insert(const_iterator pos, T elem)。本例是在pos=v1.begin()也就是第0位插入元素elem=0。
vector<int> v1 = {0,1,2,3,4,5,6,7,8,9};
v1.insert(v1.begin(),0);
printVec(v1);//0 0 1 2 3 4 5 6 7 8 9
- 在指定
pos位置,插入n个元素elem:insert(const_iterator pos, int n, T elem)。本例是在pos=v1.begin() + 3,也就是第3位插入n=3个元素elem=2。
vector<int> v1 = {0,1,2,3,4,5,6,7,8,9};
v1.insert(v1.begin() + 3, 3, 2);
printVec(v1);//0 1 2 [2 2 2] 3 4 5 6 7 8 9
- 在指定
pos位置,插入另一个vector的某一段区间(可能是从头到尾,也可能是截取一部分):insert(const_iterator pos, const_iterator beg, const_iterator end)。本例是在v1的pos=v1.end()也就是尾部插入v2的[begin, end)区间。
vector<int> v1 = {0,1,2,3,4,5,6,7,8,9};
vector<int> v2(5, 10);
v1.insert(v1.end(), v2.begin(),v2.end());
printVec(v1);//0 1 2 3 4 5 6 7 8 9 [10 10 10 10 10]
删除vector中的元素
- 最经典的弹出最后一个元素(也就是删除尾部元素,与
push_back对应),所用的方法是:pop_back(),不需要传参。
vector<int> v1 = {0,1,2,3,4,5,6,7,8,9};
v1.pop_back();//0 1 2 3 4 5 6 7 8
v1.pop_back();//0 1 2 3 4 5 6 7
v1.pop_back();//0 1 2 3 4 5 6
还是那个问题,pop_back()只能删除一个尾部元素,而我想要更加灵活的删除方式。vector内部提供了内置函数erase(),可以删除任意位置的任意元素(与insert对应)。
erase(const_iterator start, const_iterator end); // 删除区间[start, end)内的元素
erase(const_iterator pos); // 删除位置pos的元素
- 删除
vector某个区间的批量元素,本例删除的是[v1.begin() + 1, v1.end() - 1)的所有元素,也就只剩下首元素和尾元素了。
vector<int> v1 = {0,1,2,3,4,5,6,7,8,9};
v1.erase(v1.begin() + 1, v1.end() - 1);
printVec(v1);//0 9
- 删除
pos位置的某一个元素,这个pos也不能是普通的int变量,必须是迭代器指针。本例我删除的是pos=v1.begin(),也就是第0位元素。
vector<int> v1 = {0,1,2,3,4,5,6,7,8,9};
v1.erase(v1.begin());
printVec(v1);//1 2 3 4 5 6 7 8 9
- 终极删除法:清空,函数是
clear()
vector<int> v1 = {0,1,2,3,4,5,6,7,8,9};
v1.clear();
printVec(v1);//
改动vector中的元素
- 跟string类似,直接通过赋值操作,就能覆盖vector原来的值。以string类型的vector为例,可以更改某一处的字符串
vector<string> vs(10,"hello");
vs[1] = "world";
printVec(vs);//hello world hello hello hello hello hello hello hello hello
- 交换两个vector的内容,使用的是内置函数swap()。本质就是交换指向vector内存空间的指针。
vector<int> v1 = {0,1,2,3,4,5,6,7,8,9};
vector<int> v2(5, 0);
printVec(v1);//0 1 2 3 4 5 6 7 8 9
printVec(v2);//0 0 0 0 0
v1.swap(v2);
printVec(v1);//0 0 0 0 0
printVec(v2);//0 1 2 3 4 5 6 7 8 9
查找vector中的元素(可以判断是否在vector中以及所在位置)
依然是find()函数。find()函数不仅可以查找string类,还可以用在vector类上。string的find()函数会直接返回int类型,而用于vector类的find()函数返回的是对应的迭代器类型。然后我们可以通过it - v1.begin()获取索引,单独的it不行,会出错。
- 本例我们查找的范围是
[v1.begin(), v1.end()),也就是整个vector容器,查找的元素是4。返回的是迭代器指针,通过*it可以获取查找到的元素,通过it - v1.begin()可以获取该元素在vector中的索引。
vector<int> v1 = {0,1,2,3,4,5,6,7,8,9};
vector<int>::iterator it = find(v1.begin(), v1.end(), 4);
if (it != v1.end()) {
cout << "查到的元素是:" << *it << endl;
cout << "对应的首次出现的索引是:" << it - v1.begin() << endl;
}else
{
cout << "没找到" << endl;
}
- 查找
string类型的vector也一样。可以查找到是否有字符串在vector中,并定位其索引位置。
vector<string> vs = {"hello", "world" ,"hello" ,"world"};
vector<string>::iterator it = find(vs.begin(), vs.end(), "hello");
if (it != vs.end()) {
cout << "查到的元素是:" << *it << endl; //hello
cout << "对应的首次出现的索引是:" << it - vs.begin() << endl; //0
}else
{
cout << "没找到" << endl;
}
有关vector内存大小的一些操作
查询vector容器中元素的个数
size()函数可以返回当前vector里元素的个数
vector<string> vs = {"hello", "world" ,"hello" ,"world"};
printVec(vs);//hello world hello world
cout << vs.size() << endl;//4
判断vector容器是否为空
empty()可以返回当前vector是否为空,不为空就返回0,为空就返回1
vector<string> vs = {"hello", "world" ,"hello" ,"world"};
printVec(vs);//hello world hello world
cout << vs.empty() << endl;//0,也就是FALSE
重新指定vector容器的长度
vector提供了两个重载函数来实现这个事。总结就是:若容器变长,则填充指定的元素到新位置;若容器变短,则删除超出容器新长度的元素。
void resize(int num);
// 重新指定容器的长度为num,若容器变长,则以默认值填充新位置。
// 若容器变短,则末尾超出容器长度的元素被删除
void resize(int num, T elem);
// 重新指定容器的长度为num,若容器变长,则以elem填充新位置。
// 若容器变短,则末尾超出容器长度的元素被删除
void resize(int num); 如果扩大容器,默认填充空元素到尾部,容器的size会变化,但是打印容器看不出变化。之前是hello world hello world,resize之后就变成了hello world hello world - -,我向尾部push一个hello,就打印hello world hello world - - hello。如果此时我缩小,那么就会删除多出来的
vector<string> vs = {"hello", "world" ,"hello" ,"world"};
printVec(vs);//hello world hello world
vs.resize(6);
cout << vs.size() << endl;//6
printVec(vs);//hello world hello world
vs.push_back("hello");
printVec(vs);//hello world hello world hello
vs.resize(3);
printVec(vs);//hello world hello
void resize(int num, T elem); 扩大容器的话,可以向后面填充指定的元素。本例填充的是xxx。可以看到,resize之后,size会变,且多出来的部分被xxx填充。
vector<string> vs = {"hello", "world" ,"hello" ,"world"};
printVec(vs);//hello world hello world
cout << vs.size() << endl;//4
cout << vs.empty() << endl;//0,也就是FALSE
vs.resize(6,"xxx");
cout << vs.size() << endl;//6
cout << vs.capacity() << endl;//6
printVec(vs);//hello world hello world xxx xxx
vs.push_back("hello");
printVec(vs);//hello world hello world xxx xxx hello
vs.resize(3);
printVec(vs);//hello world hello
查看vector容器的容量
依然是capacity函数,多数情况下capacity会略大于size,这个就看内部设置了。
vector<string> vs = {"hello", "world" ,"hello" ,"world"};
cout << vs.size() << endl;//4
cout << vs.capacity() << endl;//4
手动扩容
vector本身是一个动态数组,在size大于等于capacity时会自动扩容。当我明知要添加很多数据时,如果任由动态数组自动扩容,那势必会扩容很多次,造成性能浪费。这时候我们可以手动扩容一个大的容量,避免多次扩容。vector给出了一个合理的方法,使用reserve()函数。
- 假设初始的vector设置为10个数,然后push100个数进去,看看扩容情况。
vector<int> v1(10, 5);
cout << v1.capacity() << endl;//10
auto current_cap = v1.capacity();
for (int i = 0; i < 100; i++) {
v1.push_back(i);
if (v1.capacity() != current_cap) {
//说明扩容了
cout << "由 " << current_cap << " 扩容为:" << v1.capacity() << endl;
}
current_cap = v1.capacity();
}
//由 10 扩容为:15
//由 15 扩容为:22
//由 22 扩容为:33
//由 33 扩容为:49
//由 49 扩容为:73
//由 73 扩容为:109
//由 109 扩容为:163
可以看到,扩容了很多次。这势必会造成资源的浪费。当我把reserve操作放在push大量数据之前,那就会减少扩容的次数,进而提升性能。
vector<int> v1(10, 5);
cout << v1.capacity() << endl;
v1.reserve(100);
auto current_cap = v1.capacity();
for (int i = 0; i < 100; i++) {
v1.push_back(i);
if (v1.capacity() != current_cap) {
//说明扩容了
cout << "由 " << current_cap << " 扩容为:" << v1.capacity() << endl;
}
current_cap = v1.capacity();
}
//由 100 扩容为:150
这种操作只有在需要给vector添加大量数据的时候才显得有意义,因为这将避免内存多次容量扩充操作(当vector的容量不足时会自动扩容,当然这必然降低性能)
二维vector的一些碎碎念
二维vector如何初始化呢?vector<vector<int> 空格>即两个vector,里面的vector必须后面跟一个空格,如果没有空格,比如:vector<vector<int>>这会报错。vv是二维向量的名字,row是二维向量的行数,col是二维向量的列数。意思就是初始化row个长度为col的vector,那相当于初始化了一个矩阵一样。
int row, col;
vector<vector<int> > vv(row, vector<int>(col));
比如初始化一个3行4列的二维vector,即矩阵。
vector<vector<int> > vv(3,vector<int>(4));
还可以初始化的时候,全部设置初始化值。比如下面:初始化时设置矩阵里面的值都为elem,例子中初始化一个全为1的3行4列矩阵。
int row, col;
int elem;
vector<vector<int> > vv(row, vector<int>(col,elem));
vector<vector<int> > vv(3,vector<int>(4,1));
当然还可以直接初始化一个自定义的矩阵:都要有大括号包围着。
vector<vector<int> > vv{ {1,2,3,4}, {2,3,4,5}, {3,4,5,6} };
如何遍历二维vector呢?
- 下标遍历法:二维
vector的size方法返回的是行数,每一行的vector的size方法返回的是该行中元素的个数。知道了这个原则,就可以使用下标遍历法,两个for循环即可遍历。注意一个细节:用vector初始化的二维数组,不要求每一行的vector长度一致,比如第三行只有三个数。
vector<vector<int> > vv{ {1,2,3,4}, {2,3,4,5}, {3,4,5} };
for (int i = 0; i < vv.size(); i++)
{
for (int j = 0; j < vv[i].size(); j++)
cout << vv[i][j] << " ";
cout << endl;
}
//1 2 3 4
//2 3 4 5
//3 4 5
- 迭代器遍历法:
vv.size返回的是行的个数,说明二维vector的属性都是为行服务的。因此vv.begin返回的其实是指向行的指针,也就是行迭代器。那么取出行的内容,就是所在行的vector。然后再.begin在是遍历当前行中的每一个元素。
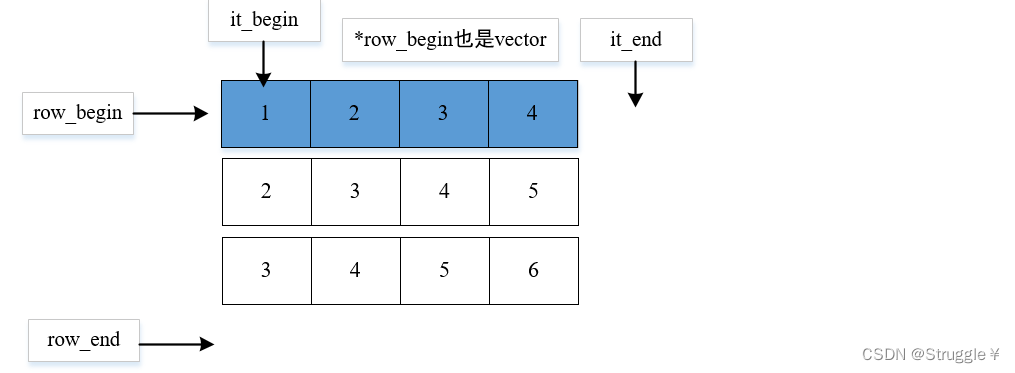
vector<vector<int> > vv{ {1,2,3,4}, {2,3,4,5}, {3,4,5} };
for (vector<vector<int>>::iterator row_begin = vv.begin(); row_begin != vv.end(); row_begin++)
{
for (vector<int>::iterator it = (*row_begin).begin(); it != (*row_begin).end(); it++)
{
cout << *it << " ";
}
cout << endl;
}
最最最最最重要的一点:二维vector的所有属性都是每一行说的。size返回的是行数,begin返回的是行指针等等。
queue队列
queue的基本概念
queue 是一种先进先出(First In First Out, FIFO)的数据结构,它有两个出口,queue容器允许从一端新增元素,从另一端移除元素只允许从尾部添加元素不允许从尾部弹出元素,只允许从头部弹出元素,不允许从头部添加元素。其示意图如下:

队列queue只有头元素才有可能被外界使用,因此queue不提供遍历功能,也不提供迭代器(不允许遍历,因为队列的目的就是让外界只能从队头访问元素)
队列queue的初始化
初始化有两种方式,要么直接初始化一个空的,要么利用已有的拷贝构造。
queue<int> plist;
queue<int> qlist(plist);
队列是不允许赋值初始化的:

向队列中添加元素
向队列中添加元素只能从队尾向队列里添加,采用的是push方法,不是push_back。
queue<int> plist;
for (int i = 0; i < 10; i++) {
plist.push(i);
}
访问队尾元素
队尾元素访问,使用的是back()函数。也只是访问,不能删除。
queue<int> plist;
for (int i = 0; i < 10; i++) {
plist.push(i);
}
cout << plist.back() << endl;//9
访问队头元素
看明白标题,这里说的是访问,仅仅是访问,不影响原队列。用front()函数。front()函数是有返回值的,不能单独书写。
queue<int> plist;
for (int i = 0; i < 10; i++) {
plist.push(i);
}
cout << plist.front() << endl;//0
删除队头元素(弹出队头)
弹出队头元素,意味着从队列中删除该元素,那么原来老二就变成了新的队头。用的是pop()函数,无返回值,可以单独执行。可以看到下面的例子,弹出前和弹出后的front变了。
queue<int> plist;
for (int i = 0; i < 10; i++) {
plist.push(i);
}
cout << plist.front() << endl;//0
plist.pop();
cout << plist.front() << endl;//1
查看队列的长度
还是用的size函数,可以看出弹出队头之后,size就减一了。
queue<int> plist;
for (int i = 0; i < 10; i++) {
plist.push(i);
}
cout << plist.size() << endl;//10
plist.pop();
cout << plist.size() << endl;//9
判断队列是否为空
用的是empty()函数,0表示不空,1表示空了。
queue<int> plist;
for (int i = 0; i < 10; i++) {
plist.push(i);
}
cout << plist.empty() << endl;//0
打印队列
我知道队列不能遍历,也就意味着,不能正常打印。那我就想知道队列中有什么元素怎么办?
queue<int> plist;
for (int i = 0; i < 10; i++) {
plist.push(i);
}
cout << plist.empty() << endl;//0
while (!plist.empty()) {
cout << plist.front() << " ";
plist.pop();
}
// 0 1 2 3 4 5 6 7 8 9
cout << plist.empty() << endl;//1
先获取当前队头元素,然后把队头弹出,继续获取下一个队头元素,然后继续弹出…知道队列为空,所有队头都被挨个打印出来了,那不就完成了打印队列的目的吗(虽然队列最终被清空了)
stack栈
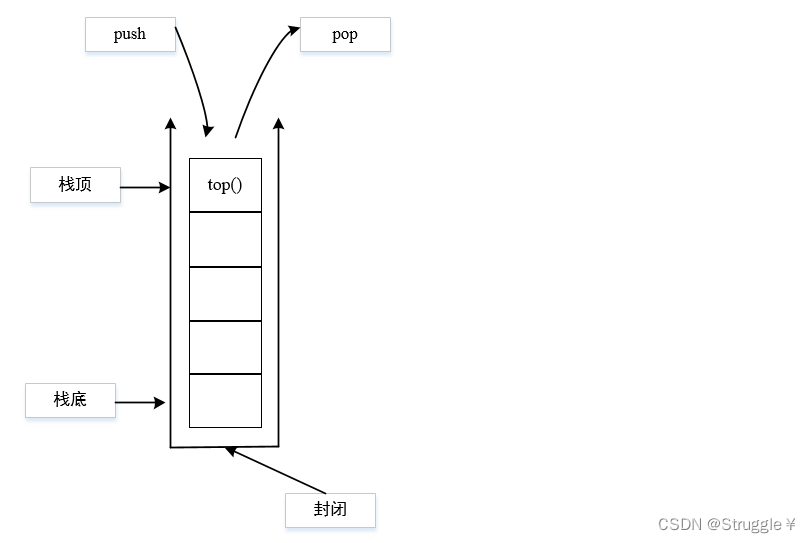
stack的基本概念
栈是一种先进后出(First In Last Out, FILO)的数据结构,它只有一个出口,那就是栈顶。栈底是不允许访问的,想要访问栈的元素,必须一个一个访问栈顶元素top。使用前需要包含stack库:#include<stack>
如何声明一个栈stack
- 直接声明
stack<string> stkS,或者利用已存在的初始化stack<string> stkS_(stkS)。不能赋值初始化stack<string> stkS = {“hello”,“world”}会报错。
stack<string> stkS;
cout << stkS.size() << endl;//0
for (int i = 0; i < 10; i++) {
stkS.push("zmm");
}
stack<string> stkS_(stkS);
cout << stkS_.size() << endl;//10
向栈中添加元素
跟queue一样,也是push方法,可以看到push之后,size变大了
stack<string> stkS;
cout << stkS.size() << endl;//0
for (int i = 0; i < 10; i++) {
stkS.push("zmm");
}
cout << stkS.size() << endl;//10
弹出栈顶元素(也叫从栈中删除栈顶元素)
用的是pop()函数,
stack<string> stkS;
cout << stkS.size() << endl;//0
for (int i = 0; i < 10; i++) {
stkS.push("zmm");
}
cout << stkS.size() << endl;//10
stkS.pop();
cout << stkS.size() << endl;//9
stkS.pop();
cout << stkS.size() << endl;//8
stkS.pop();
cout << stkS.size() << endl;//7
访问栈顶元素(仅仅是访问,不删除)
用的是top函数,有返回值,不可独立书写。本例,我一次将0~9入栈,然后返回栈顶元素9,弹出栈顶元素后再次访问新的栈顶元素,是8。
stack<int> stkI;
for (int i = 0; i < 10; i++) {
stkI.push(i);
}
cout << stkI.top() << endl;//9
stkI.pop();
cout << stkI.top() << endl;//8
判断栈是否为空
用的就是empty()函数
stack<int> stkI;
cout << stkI.empty() << endl;//1
for (int i = 0; i < 10; i++) {
stkI.push(i);
}
cout << stkI.empty() << endl;//0
打印stack元素
只能访问栈顶元素,那就访问一个,弹出一个,这就打印出来了。可以看出,打印的是9 8 7 6 5 4 3 2 1 0,这就叫后入先出。
stack<int> stkI;
for (int i = 0; i < 10; i++) {
stkI.push(i);
}
for (int i = 0; i < 10; i++) {
cout << stkI.top() << " ";
stkI.pop();
}
//9 8 7 6 5 4 3 2 1 0
我就想从栈底打印到栈顶,怎么办?也就是说打印出0 1 2 3 4 5 6 7 8 9,那就得准备两个栈,另一栈接收原来栈的元素。
stack<int> stkI;
stack<int> stkTemp;
for (int i = 0; i < 10; i++) {
stkI.push(i);
}
for (int i = 0; i < 10; i++) {
stkTemp.push(stkI.top());//另一个栈不断地入栈,栈顶元素,达到把原来的栈反序的目的。
stkI.pop();
}
for (int i = 0; i < 10; i++) {
cout << stkTemp.top() << " ";
stkTemp.pop();
}
//0 1 2 3 4 5 6 7 8 9
deque双向队列
deque的基本概念
普通队列queue只能在尾部插入和在头部删除。deque相对于queue来说,可以在两端进行添加和删除操作。具体如下图所示:
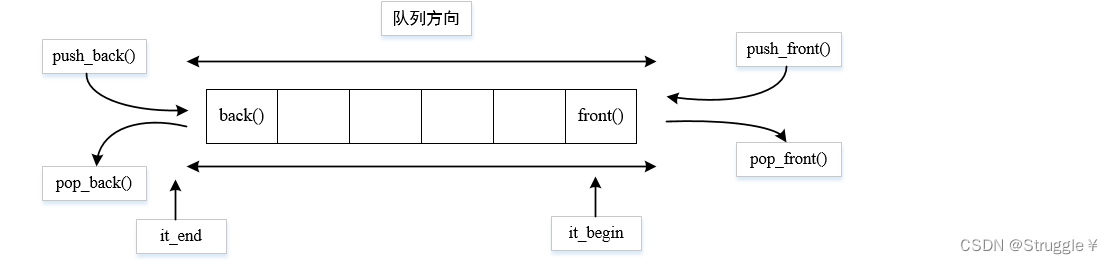
相对于vector来说,deque最大的优势就是在头部插入元素时,效率依然是O(1)。因为deque在空间中并不是连续内存,而是由一个中控器管理,貌似是连续存储元素,其实不是。
deque的初始化(声明、定义)
deque内部重载了多种构造函数,因此依然有很多种初始化方式
deque<T> deqT; // 默认构造函数
deque(beg, end); // 构造函数将[beg, end)区间中的元素拷贝给本身
deque(int n, T elem); // 构造函数将n个elem拷贝给本身
deque(const deque& deq); // 拷贝构造函数
这里就不一一介绍了,因为这种初始化方式跟vector几乎一样,自己看吧:
deque<int> deq1;
printDeq(deq1);//
deque<int> deq2(10, 0);
printDeq(deq2);//0 0 0 0 0 0 0 0 0
deque<int> deq3 = { 0,1,2,3,4,5,6,7,8,9 };
printDeq(deq3);//1 2 3 4 5 6 7 8 9
deque<int> deq4(deq3.begin(), deq3.end());
printDeq(deq4);//1 2 3 4 5 6 7 8 9
deque<int> deq5(deq4);
printDeq(deq5);//1 2 3 4 5 6 7 8 9
队列的赋值操作
deque也有assign()函数,用于分配现有的数据给新队列。
deque<int> deq1 = { 0,1,2,3,4,5,6,7,8,9 };
printDeq(deq1);//1 2 3 4 5 6 7 8 9
deque<int> deq2;
deq2.assign(deq1.begin()+1, deq1.end()-1);
printDeq(deq2);//1 2 3 4 5 6 7 8
deque也有交换函数,swap()函数,可以交换
deq1.swap(deq2);
printDeq(deq1);//1 2 3 4 5 6 7 8
printDeq(deq2);//1 2 3 4 5 6 7 8 9
队列的内存大小API
查看队列中的元素个数,依然用size()函数。
deque<int> deq1 = { 0,1,2,3,4,5,6,7,8,9 };
printDeq(deq1);//1 2 3 4 5 6 7 8 9
cout << deq1.size() << endl;//10
判断队列是否为空,依然用empty()函数
deque<int> deq1 = { 0,1,2,3,4,5,6,7,8,9 };
printDeq(deq1);//1 2 3 4 5 6 7 8 9
cout << deq1.empty() << endl;//0
重新指定队列的size,多的填充,少的去掉,用的是resize函数,跟vector一样。
void resize(int num);
// 重新指定容器的长度为num,若容器变长,则以默认值填充新位置,
// 如果容器变短,则末尾超出容器长度的元素被删除
void resize(int num, T elem);
// 重新指定容器的长度为num,若容器变长,则以elem填充新位置,
// 如果容器变短,则末尾超出容器长度的元素被删除
注意:deque没有容量的概念,deque都是动态的生成存储空间,没有容量的概念,因此不能使用capacity函数。
遍历双向队列deque
迭代器遍历是最经典的:
deque<int> deq1 = { 0,1,2,3,4,5,6,7,8,9 };
printDeq(deq1);//1 2 3 4 5 6 7 8 9
for (deque<int>::iterator it = deq1.begin(); it != deq1.end(); it++) {
cout << *it << " ";
}
//1 2 3 4 5 6 7 8 9
虽然deque容器也提供了Random Access Iterator,但是它的迭代器并不是普通的指针,其复杂度和vector不是一个量级,这当然影响各个运算的层面。因此,在需要遍历容器的时候,除非有必要,我们应该尽可能的使用vector,而不是 deque。
例如:对deque进行的排序操作,为了最高效率,可将deque先完整的复制到一个vector中,对vector容器进行排序,再复制回deque。
deque的双端插入与删除
这是deque最重要的特性,可以在双端进行删除与插入。这也是deque唯一的优点。
- 插入元素,
push操作,如果在尾部插入就是push_back(),如果在头部插入那就是push_front()。
deque<int> deq1 = { 0,1,2,3,4,5,6,7,8,9 };
printDeq(deq1);//1 2 3 4 5 6 7 8 9
deq1.push_back(-1);
deq1.push_front(10);
printDeq(deq1);//10 0 1 2 3 4 5 6 7 8 9 -1
可以看到,前面的才叫头部,后面的才叫尾部,顺序要搞懂。
- 删除(弹出)元素,用的是
pop操作,如果是弹出尾部元素就是pop_back(),如果是弹出队头元素那就是pop_front()。
deque<int> deq1 = { 0,1,2,3,4,5,6,7,8,9 };
printDeq(deq1);//0 1 2 3 4 5 6 7 8 9
deq1.push_back(-1);
deq1.push_front(10);
printDeq(deq1);//10 0 1 2 3 4 5 6 7 8 9 -1
deq1.pop_back();
deq1.pop_front();
printDeq(deq1);//0 1 2 3 4 5 6 7 8 9
弹出元素并不是返回元素,因此没有返回值,需要单独书写。
访问双向队列的队头和队尾元素
只是简单的访问:访问头元素用的是front()函数,访问尾元素用的是back()
deque<int> deq1 = { 0,1,2,3,4,5,6,7,8,9 };
printDeq(deq1);//0 1 2 3 4 5 6 7 8 9
cout << deq1.front() << endl;//0
cout << deq1.back() << endl;//9
别跟栈的弄混了,栈顶元素用的是top函数,队列的队头用的是front函数。
在双向队列deque的任意位置插入元素
用的也是insert函数,内置了三种重载函数。
const_iterator insert(const_iterator pos, T elem);
// 在pos位置处插入元素elem的拷贝,返回新数据的位置
void insert(const_iterator pos, int n, T elem);
// 在pos位置插入n个元素elem,无返回值
void insert(pos, beg, end);
// 将[beg, end)区间内的元素插到位置pos,无返回值
- 第一个,插入之后有返回值的,返回的是迭代器,想要打印出来迭代器的位置,需要
it - deq1.begin(),我们之前讲过。
deque<int> deq1 = { 0,1,2,3,4,5,6,7,8,9 };
printDeq(deq1);//0 1 2 3 4 5 6 7 8 9
deque<int>::iterator it = deq1.insert(deq1.begin()+1, 100);
cout << it - deq1.begin() << endl;//1
printDeq(deq1);//0 100 1 2 3 4 5 6 7 8 9
可以看到,把100插入到队列的pos=deq1.begin()+1,也就是第1位。
- 第二个,无返回值,直接插入
2个100在第1位
deque<int> deq1 = { 0,1,2,3,4,5,6,7,8,9 };
printDeq(deq1);//0 1 2 3 4 5 6 7 8 9
deq1.insert(deq1.begin()+1, 2, 100);
printDeq(deq1);//0 100 100 1 2 3 4 5 6 7 8 9
- 第三个,把另一个容器的某一块区间插入到
pos位置。本例是队列pos=deq1.begin()+1的位置插入vector的数据。
deque<int> deq1 = { 0,1,2,3,4,5,6,7,8,9 };
printDeq(deq1);//0 1 2 3 4 5 6 7 8 9
vector<int> v1 = { 2,3,2,3 };
deq1.insert(deq1.begin()+1, v1.begin(),v1.end());
printDeq(deq1);//0 2 3 2 3 1 2 3 4 5 6 7 8 9
deque的删除操作
清空的话,还是用clear函数
deque<int> deq1 = { 0,1,2,3,4,5,6,7,8,9 };
printDeq(deq1);//0 1 2 3 4 5 6 7 8 9
cout << deq1.empty() << endl;//0
deq1.clear();
cout << deq1.empty() << endl;//1
删除指定pos位置的元素,用的还是erase函数。提供了两个重载函数。
iterator erase(iterator beg, iterator end);
// 删除区间[beg, end)的数据,返回下一个数据的位置
iterator erase(iterator pos);
// 删除pos位置的数据,返回下一个数据的位置
- 删除队列某一个区间的所有元素,然后返回删除之后队列的下一个数据的位置(返回的是迭代器)。比如本例:删除的是
2 3 4 5 6 7,那么下一个数据就是8,然而在更新之后的队列中,8所在的索引位置是2,所以返回的是2,而不是原来队列8的索引。
deque<int> deq1 = { 0,1,2,3,4,5,6,7,8,9 };
printDeq(deq1);//0 1 2 3 4 5 6 7 8 9
deque<int>::iterator it = deq1.erase(deq1.begin()+2, deq1.end()-2);
cout << it - deq1.begin() << endl; // 2
printDeq(deq1);// 0 1 8 9
- 删除某一个元素,返回的就是下一个元素在新队列中的索引。
deque<int> deq1 = { 0,1,2,3,4,5,6,7,8,9 };
printDeq(deq1);//0 1 2 3 4 5 6 7 8 9
deque<int>::iterator it = deq1.erase(deq1.begin() + 1);
cout << it - deq1.begin() << endl; // 1
printDeq(deq1);// 0 2 3 4 5 6 7 8 9
list链表
STL的list是双向链表(要明白一个点啊:节点内部的prev和next我们是看不见的,也访问不了。STL中的list就是一个线性表。只不过在设计链表的时候,要用到prev和next。我们今后在使用链表的时候,只需要了解到链表的一些API即可。)需要包含头文件#inclined<list>
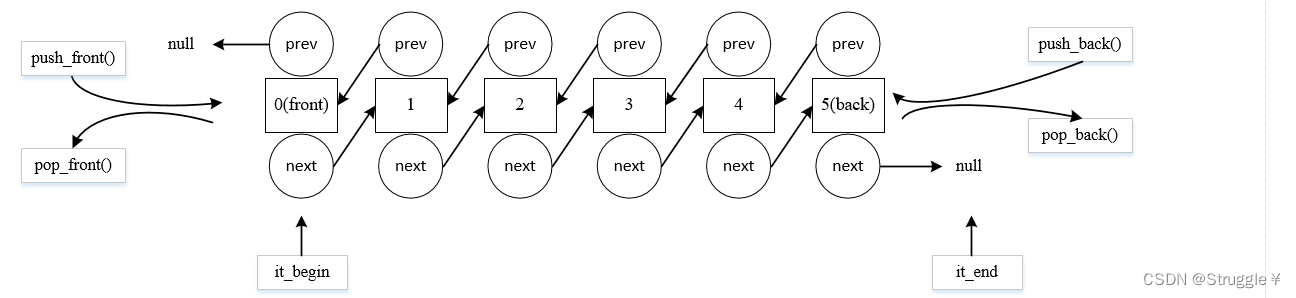
下面介绍一下,双向链表list的各种使用范式:
list的初始化(定义&声明)
背景知识,定义了一个打印list内容的函数:
template<class T>
void printList(list<T> &deq) {
for (T item : deq) {
cout << item << " ";
}
cout << endl;
}
list也是容器的一种,也支持泛型模板,本例我们存储string字符串,初始化方式有以下几种,跟vector差不多:
list<string> list0;
printList(list0);//0
cout << list0.size() << endl;//
list<string> list1 = {"hello","world","ZMM"};
printList(list1);//hello world ZMM
list<string> list2(list1.begin(), list1.end());
printList(list2);//hello world ZMM
list<string> list3(list1);
printList(list3);//hello world ZMM
list<string> list4(5, "hello");
printList(list4);//hello hello hello hello hello
访问链表头元素和链表尾元素
跟双向队列一样,还是front函数和back函数。
list<int> list1 = { 0,1,2,2,2,2,2,7,8,9 };
cout << list1.front() << endl;//0
cout << list1.back() << endl;//9
list元素的插入和删除操作
在链表list的头尾进行插入和删除
双向链表的头尾都可以操作,跟双向队列的API名字一样。往尾部添加元素用push_back,往头部添加元素用push_front,删除尾部元素用pop_back,删除头部元素用pop_front。通过本例的打印,可以看出每一个API的使用效果。
list<string> list1 = {"hello","world"};
printList(list1);//hello world
list1.push_back("ZMM");
printList(list1);//hello world ZMM
list1.push_back("XHB");
printList(list1);//hello world ZMM XHB
list1.push_front("C++");
printList(list1);//C++ hello world ZMM XHB
list1.pop_back();
printList(list1);//C++ hello world ZMM
list1.pop_back();
printList(list1);//C++ hello world
list1.pop_front();
printList(list1);//hello world
在链表list的任意位置插入或者删除
插入函数,提供了三种重载方法。
insert(iterator pos, elem); // 在pos位置插入elem元素的拷贝,返回新数据的位置
insert(iterator pos, n, elem); // 在pos位置插入n个elem元素的拷贝,无返回值
insert(iterator pos, beg, end); // 在pos位置插入[beg, end)区间内的数据,无返回值
- 插入仍是用的
insert函数,本例中我们先查到到2的位置,然后插入元素10。
list<int> list1 = { 0,1,2,3,4,5,6,7,8,9 };
list<int>::iterator pos = find(list1.begin(),list1.end(),2);
list1.insert(pos, 10);
printList(list1);//0 1 10 2 3 4 5 6 7 8 9
- 插入5个10
list<int> list1 = { 0,1,2,3,4,5,6,7,8,9 };
list<int>::iterator pos = find(list1.begin(),list1.end(),2);
list1.insert(pos, 5,10);
printList(list1);//0 1 10 10 10 10 10 2 3 4 5 6 7 8 9
- 插入另一个数据结构的若干元素
list<int> list1 = { 0,1,2,3,4,5,6,7,8,9 };
list<int> list2 = { 8,8,8,8 };
list<int>::iterator pos = find(list1.begin(),list1.end(),2);
list1.insert(pos, list2.begin(),list2.end());
printList(list1);//0 1 8 8 8 8 2 3 4 5 6 7 8 9
删除函数依然用的是erase函数,提供两个重载函数。
erase(beg, end); // 删除[beg, end)区间内的所有数据,返回下一个数据的位置
erase(pos); // 删除pos位置的数据,返回下一个数据的位置
链表的迭代器没有重载+运算符,因此不能手动移动任意位置了,只能删除链表中已知存在的元素。

- 从头删除到尾
list<int> list1 = { 0,1,2,3,4,5,6,7,8,9 };
list1.erase(list1.begin(), list1.end());
printList(list1);//
- 删除指定元素:先通过
find函数查找到pos,然后删除。
list<int> list1 = { 0,1,2,3,4,5,6,7,8,9 };
list<int>::iterator pos = find(list1.begin(),list1.end(), 2);
list1.erase(pos);
printList(list1);//0 1 3 4 5 6 7 8 9
删除链表中所有等于elem的元素
用的是一个新函数:remove(),可以删除链表中等于elem的所有元素。
list<int> list1 = { 0,1,2,2,2,2,2,7,8,9 };
list1.remove(2);
printList(list1);//0 1 7 8 9
清空list元素,并判断是否为空
通过这个例子了解到,链表是否为空还是用的empty函数,判断里面的元素个数还是用的size函数,清空还是用的clear函数。
list<int> list1 = { 0,1,2,3,4,5,6,7,8,9 };
cout << list1.empty() << endl;//0
list1.clear();
cout << list1.empty() << endl;//1
cout << list1.size() << endl;//0
printList(list1);//
翻转链表
用的是reverse函数,直接调用也行list1.reverse(),传参数进去也行reverse(list1.begin(),list1.end())。
list<int> list1 = { 0,1,2,3,4,5,6,7,8,9 };
list1.reverse();
//reverse(list1.begin(),list1.end());
printList(list1);//9 8 7 6 5 4 3 2 1 0
排序链表
用的是sort函数,直接调用也行list1.sort(),传参数进去也行sort(list1.begin(),list1.end())。
list<int> list1 = { 0,1,2,5,4,3,6,8,7,9 };
list1.sort();
//sort(list1.begin(),list1.end());
printList(list1);//0 1 2 3 4 5 6 7 8 9
set集合
set 容器基本概念
set翻译为集合,是一个内部自动有序且不含重复元素的容器。set这个容器最大的特点就是不允许有重复元素,且会自动排序,即使初始化的时候是一个乱序的。需要包含头文件#inclined<set>
set<int> set1 = { 0,1,2,3,4,5,6,9,8,7 };
printSet(set1);//0 1 2 3 4 5 6 7 8 9
本例中可以看到,我初始化的时候是乱序的,但是打印出来就是顺序的。
set<int> set1 = { 0,1,3,3,3,3,3,3,8,7 };
printSet(set1);//0 1 3 7 8
本例中可以看到,我初始化的时候有一一堆3,但是打印的时候被去重了。
这两个例子充分展现了集合set的特点!
set的初始化操作
跟其它容器差不多,也是下面的一些操作,这里就不赘述了
set<int> set0;
set<int> set1 = { 0,1,3,3,3,3,3,3,8,7 };
set<int> set2(set1);
set<int> set3(set1.begin(), set1.end());
printSet(set3);//0 1 3 7 8
set的遍历访问
set<int> set1 = { 0,1,3,3,3,3,3,3,8,7 };
for (set<int>::iterator it = set1.begin(); it != set1.end(); it++) {
cout << *it << " ";
}
//0 1 3 7 8
set只能通过迭代器访问!
set容器也不能迭代器+1,(能迭代器+1的只有vector,string,deque)

set的插入和删除操作
- 插入函数还是用的
insert
set<int> set1 = { 0,1,3,3,3,3,3,3,8,7 };
set1.insert(5);
for (set<int>::iterator it = set1.begin(); it != set1.end(); it++) {
cout << *it << " ";
}
//0 1 3 5 7 8
但是,这里还隐藏着一个新知识:insert是有返回值的,返回的是一个pair结构。其中第一个位置返回迭代器,第二个位置返回是否插入成功。pair这种数据结构,通过first方法和second方法访问不同位置的返回值。可以看到:取出迭代器的值就是我们插入的值,返回是否插入成功,输出的就是1。
set<int> set1 = { 0,1,3,3,3,3,3,3,8,7 };
pair<set<int>::iterator, bool> pair;
pair = set1.insert(5);
cout << *pair.first << endl;//5
cout << pair.second << endl;//1
for (set<int>::iterator it = set1.begin(); it != set1.end(); it++) {
cout << *it << " ";
}
//0 1 3 5 7 8
- 清空
set还是用的clear
set<int> set1 = { 0,1,3,3,3,3,3,3,8,7 };
set1.clear();
for (set<int>::iterator it = set1.begin(); it != set1.end(); it++) {
cout << *it << " ";
}
//
- 删除指定
pos的元素,由于set也不能迭代器+1,因此只能指定头尾的迭代器然后删除头尾元素,没法删除指定位置的中间元素
set<int> set1 = { 0,1,3,3,3,3,3,3,8,7 };
for (set<int>::iterator it = set1.begin(); it != set1.end(); it++) {
cout << *it << " ";
}
//0 1 3 7 8
set1.erase(set1.begin());
set1.erase(--set1.end());
printSet(set1);//1 3 7
- 删除
set容器中为elem的元素,这个是最常用的set删除操作。本例中从容器中删除的是3。
set<int> set1 = { 0,1,3,3,3,3,3,3,8,7 };
for (set<int>::iterator it = set1.begin(); it != set1.end(); it++) {
cout << *it << " ";
}
//0 1 3 7 8
set1.erase(3);
printSet(set1);//0 1 7 8
set的查找操作(可以说是set最重要API)
- 查找
elem是否在set中,如果在就返回对应的迭代器,如果不在就返回set.end()。依然用的是find方法
set<int> set1 = { 0,1,3,3,3,3,3,4,8,7 };
printSet(set1);//0 1 3 4 7 8
set<int>::iterator it = set1.find(3);
cout << *it << endl;//3
- 统计
set中elem的个数,因为set是去重集合,因此count函数不是返回1就是0,可以用来判断elem是否在set中
set<int> set1 = { 0,1,3,3,3,3,3,4,8,7 };
printSet(set1);//0 1 3 4 7 8
cout << set1.count(3) << endl;//1
- 查找
set中大于等于elem的第一次出现的迭代器。本例中查找的是4,因此返回大于等于4的第一次出现的迭代器
set<int> set1 = { 0,1,3,3,3,3,3,4,8,7 };
printSet(set1);//0 1 3 4 7 8
set<int>::iterator it_lower = set1.lower_bound(4);
cout << *it_lower << endl;//4
- 查找
set中大于elem的第一次出现的迭代器,本例中查找的是4,因此返回大于4的第一次出现的迭代器
set<int> set1 = { 0,1,3,3,3,3,3,4,8,7 };
printSet(set1);//0 1 3 4 7 8
set<int>::iterator it_upper = set1.upper_bound(4);
cout << *it_upper << endl;//7
pair数据结构的使用
set<int> set1 = { 0,1,3,3,3,3,3,3,8,7 };
set<int>::iterator k, bool v;
pair<set<int>::iterator, bool> p(k, v);
pair<set<int>::iterator, bool> p;
p.first, p.second;
multiset的使用(set的进化版,可以存在重复元素)
multiset也是集合,只不过允许集合中有重复的元素,仍然是会自动排序。
所以说,multiset的应用场景比set更广泛。跟set一样,只需要#inclined<set>,这两个共有一个头文件。
通过下面的例子可以看出:multiset不会去掉重复的元素,但是仍然会给元素进行排序,默认就是递增排序。当我们统计3的个数,也能准确地给出5个。
multiset<int> set1 = { 0,1,3,3,3,3,3,4,8,7 };
printSet(set1);//0 1 3 3 3 3 3 4 7 8
multiset<int>::iterator it = set1.find(3);
cout << *it << endl;//3
for (set<int>::iterator it = set1.begin(); it != set1.end(); it++) {
cout << *it << " ";
}
//0 1 3 3 3 3 3 4 7 8
cout << set1.count(3) << endl;//5
想要改变排序的规则,可以自定义仿函数,然后在声明set的时候传入multiset<int, MyCompare> set1,模板类第二个参数也是可以传参的。这样就可以办到递减排序。
class MyCompare
{
public:
bool operator()(int v1, int v2)
{
return v1 > v2;
}
};
multiset<int, MyCompare> set1 = { 0,1,3,3,3,3,3,4,8,7 };
for (multiset<int>::iterator it = set1.begin(); it != set1.end(); it++) {
cout << *it << " ";
}
//8 7 4 3 3 3 3 3 1 0
map映射(类似于python中的字典)
map基本概念
map是具有唯一键值对的容器,通常使用红黑树实现。
map中的键值对是 key value 的形式,都是pair结构,并且所有的元素都会根据元素的键值自动排序;
map不允许两个元素有相同的键值;但是multimap可以拥有相同的键值。使用时需要包含头文件:#include <map>
map的声明初始化操作
定义形式如下所示:必须遵循pair结构,第一个是key的数据类型,第二个是value的数据类型。
map<key_type, value_type>变量名
初始的方式有两种,一种是默认的构造函数,一种是拷贝构造函数
map<T1, T2> mapTT; // map默认构造函数
map(const map& mp); // 拷贝构造函数
下面的例子展现了初始化以及赋值的一些操作:
map<string, int> map1;
map1["ZMM"] = 18;
map1["XHB"] = 18;
map<string, int> map2(map1);
cout << map2["ZMM"] << endl;//18
遍历map里的元素
使用迭代器遍历,想要打印key那就打印it->first,想要打印value那就打印it->second。
map<string, int> map1;
map1.insert(pair<string, int>("ZMM-EGA", 18));
map1.insert(pair<string, int>("XHB-EGA", 18));
map1.insert(pair<string, int>("ZMM-MONEY", 0));
map1.insert(pair<string, int>("XHB-MONEY", 0));
for (map<string, int>::iterator it = map1.begin(); it != map1.end(); it++)
{
cout << "key = " << it->first << " value = " << it->second << endl;
}
//key = XHB - EGA value = 18
//key = XHB - MONEY value = 0
//key = ZMM - EGA value = 18
//key = ZMM - MONEY value = 0
map会自动的按照key进行排序,所以,实际的map跟初始化的map顺序可能不一致。
map插入数据的操作
- 直接增通过下标法,插入数据(在这个过程中就表明了
key和value都是啥)
map<string, int> map1;
map1["ZMM-EGA"] = 18;
map1["XHB-EGA"] = 18;
map1["ZMM-MONEY"] = 0;
map1["XHB-MONEY"] = 0;
- 通过函数
insert函数来插入,传的参数要是pair类型的,并在括号里表明key和value。
map<string, int> map1;
map1.insert(pair<string, int>("ZMM-EGA", 18));
map1.insert(pair<string, int>("XHB-EGA", 18));
map1.insert(pair<string, int>("ZMM-MONEY", 0));
map1.insert(pair<string, int>("XHB-MONEY", 0));
map删除数据操作
- 使用的还是
erase函数,本例是直接根据key删除一个map元素
map<string, int> map1;
map1.insert(pair<string, int>("ZMM-EGA", 18));
map1.insert(pair<string, int>("XHB-EGA", 18));
map1.insert(pair<string, int>("ZMM-MONEY", 0));
map1.insert(pair<string, int>("XHB-MONEY", 0));
cout << "size = " << map1.size() << endl; //size = 4
map1.erase("ZMM-EGA");
cout << "size = " << map1.size() << endl; //size = 3
- 本例是通过
find函数找到key,然后返回迭代器,然后再删除
map<string, int> map1;
map1.insert(pair<string, int>("ZMM-EGA", 18));
map1.insert(pair<string, int>("XHB-EGA", 18));
map1.insert(pair<string, int>("ZMM-MONEY", 0));
map1.insert(pair<string, int>("XHB-MONEY", 0));
cout << "size = " << map1.size() << endl; //size = 4
map<string, int>::iterator it = map1.find("ZMM-EGA");
map1.erase(it);
cout << "size = " << map1.size() << endl; //size = 3
- 清空
map,用的还是clear函数
map<string, int> map1;
map1.insert(pair<string, int>("ZMM-EGA", 18));
map1.insert(pair<string, int>("XHB-EGA", 18));
map1.insert(pair<string, int>("ZMM-MONEY", 0));
map1.insert(pair<string, int>("XHB-MONEY", 0));
cout << "size = " << map1.size() << endl; //size = 4
map1.clear();
cout << "size = " << map1.size() << endl; //size = 0
修改map里的数据
注意:修改数据仅能修改value的值,key是不能修改的。如果非要修改key,只能通过增加和删除来实现修改key。本例中我们修改了key="ZMM-EGA"的value。
map<string, int> map1;
map1.insert(pair<string, int>("ZMM-EGA", 18));
map1.insert(pair<string, int>("XHB-EGA", 18));
map1.insert(pair<string, int>("ZMM-MONEY", 0));
map1.insert(pair<string, int>("XHB-MONEY", 0));
for (map<string, int>::iterator it = map1.begin(); it != map1.end(); it++)
{
cout << "key = " << it->first << " value = " << it->second << endl;
}
//key = XHB - EGA value = 18
//key = XHB - MONEY value = 0
//key = ZMM - EGA value = 18
//key = ZMM - MONEY value = 0
map1["ZMM-EGA"] = 17;
for (map<string, int>::iterator it = map1.begin(); it != map1.end(); it++)
{
cout << "key = " << it->first << " value = " << it->second << endl;
}
//key = XHB - EGA value = 18
//key = XHB - MONEY value = 0
//key = ZMM - EGA value = 17
//key = ZMM - MONEY value = 0
其中,我们遍历打印了map,通过迭代器指针it指向first和second来获取key和value值。至于为什么打印出来顺序不一样,那是因为map会自动根据key值进行排序。字符串的排序规则可能就是按照A~Z的顺序。
查找map中的数据
只能通过key来查找map元素,返回的是迭代器,如果没查到那就返回end迭代器。
map<string, int> map1;
map1.insert(pair<string, int>("ZMM-EGA", 18));
map1.insert(pair<string, int>("XHB-EGA", 18));
map1.insert(pair<string, int>("ZMM-MONEY", 0));
map1.insert(pair<string, int>("XHB-MONEY", 0));
map<string, int>::iterator it_find = map1.find("XHB-EGA");
if (it_find != map1.end()) {
cout << it_find->second << endl;//18
}
为了更加直观的感受按照key值排序,接下来的查找例子我们将key设置为int类型
- 查找恰好大于等于的最小元素
lower_bound(),恰好大于的最小元素upper_bound()。
map<int, string> map2;
map2[18] = "a";
map2[19] = "b";
map2[20] = "c";
map2[21] = "d";
map2[22] = "e";
map<int, string>::iterator iter = map2.lower_bound(18);
cout << "key = " << iter->first << " value = " << iter->second << endl;//key = 18 value = a
iter = map2.upper_bound(18);
cout << "key = " << iter->first << " value = " << iter->second << endl;//key = 19 value = b
其中lower_bound(18)的意思是:查找map中key值大于等于18的map元素,且是第一个出现的,因此就找到了key = 18 value = a这一map元素;
upper_bound(18)的意思是:查找map中key值严格大于18的map元素,且是第一个出现的,因此就找到了key = 19 value = b这一map元素;
交换两个map
用的还是swap函数,本质就是交换指向两个map的指针。
map<string, int> map1;
map1.insert(pair<string, int>("ZMM-EGA", 18));
map1.insert(pair<string, int>("XHB-EGA", 18));
map1.insert(pair<string, int>("ZMM-MONEY", 0));
map1.insert(pair<string, int>("XHB-MONEY", 0));
map<string, int> map2;
map2["ZMM"] = 1888;
map2["XHB"] = 1888;
map1.swap(map2);
for (map<string, int>::iterator it = map1.begin(); it != map1.end(); it++)
{
cout << "key = " << it->first << " value = " << it->second << endl;
}
//key = XHB value = 1888
//key = ZMM value = 1888
返回当前map所能容纳的最大容量
使用的是max_size()函数
map<string, int> map1;
map1.insert(pair<string, int>("ZMM-EGA", 18));
map1.insert(pair<string, int>("XHB-EGA", 18));
map1.insert(pair<string, int>("ZMM-MONEY", 0));
map1.insert(pair<string, int>("XHB-MONEY", 0));
//返回当前容器的可以容纳的最大元素个数,来看一个例子。
cout << "size = " << map1.max_size() << endl; //size = 89478485
map不允许两个相同的key出现
当插入map元素时,插入了相同的key,就会默认去掉后来插入的。
map<string, int> map1;
map1.insert(pair<string, int>("ZMM-EGA", 18));
map1.insert(pair<string, int>("ZMM-EGA", 17));
map1.insert(pair<string, int>("ZMM-MONEY", 0));
map1.insert(pair<string, int>("XHB-MONEY", 0));
cout << "size = " << map1.size() << endl; //size = 3
for (map<string, int>::iterator it = map1.begin(); it != map1.end(); it++)
{
cout << "key = " << it->first << " value = " << it->second << endl;
}
//key = XHB - MONEY value = 0
//key = ZMM - EGA value = 18
//key = ZMM - MONEY value = 0
但是multimap允许有相同的key
multimap<string, int> map1;
map1.insert(pair<string, int>("ZMM-EGA", 18));
map1.insert(pair<string, int>("ZMM-EGA", 17));
map1.insert(pair<string, int>("ZMM-MONEY", 0));
map1.insert(pair<string, int>("XHB-MONEY", 0));
cout << "size = " << map1.size() << endl; //size = 3
for (multimap<string, int>::iterator it = map1.begin(); it != map1.end(); it++)
{
cout << "key = " << it->first << " value = " << it->second << endl;
}
//key = XHB - MONEY value = 0
//key = ZMM - EGA value = 18
//key = ZMM - EGA value = 17
//key = ZMM - MONEY value = 0
不同容器的使用场景(容器的总结)
| vector | deque | list | set | map | |
|---|---|---|---|---|---|
| 内部实现 | 单端数组 | 双端数组 | 双向链表 | 二叉树 | 二叉树 |
| 元素搜索速度 | 慢 | 慢 | 慢 | 快 | 对key而言快 |
| 元素增删速度 | 尾端快头部慢 | 头尾两端都快 | 任何位置都快 | 慢 | 慢 |
vector 可以涵盖其他所有容器的功能,只不过实现特殊功能时效率没有其他容器高。但如果只是简单存储,vector效率是最高的。
- deque 相比于 vector 支持头端元素的快速增删,这也是deque的一大优势。
- list 支持频繁的不确定位置元素的移除插入。
- set 会自动排序。
- map 是元素为键值对组并按键排序的set。
vector<元素类型>
用于需要快速定位(访问)任意位置上的元素以及主要在元素序列的尾部增加/删除元素的场合。
list<元素类型>
用于经常在元素序列中任意位置上插入/删除元素的场合。
deque<元素类型>
用于主要在元素序列的两端增加/删除元素以及需要快速定位(访问)任意位置上的元素的场合。
stack<元素类型>
用于仅在元素序列的尾部增加/删除元素的场合。
queue<元素类型>
用于仅在元素序列的尾部增加、头部删除元素的场合。
map<关键字类型,值类型>
用于需要根据关键字来访问元素的场合。容器中每个元素是一个pair结构类型,该结构有两个成员:first和second,关键字对应first,值对应second,元素是根据其关键字排序的。对于map,不同元素的关键字不能相同;对于multimap,不同元素的关键字可以相同。它们在头文件map中定义,常常用某种二叉树来实现。
set<元素类型>
它们分别是map和multimap的特例,每个元素只有关键字而没有值,或者说,关键字与值合一了。在头文件set中定义。




![[图神经网络]视觉图神经网络ViG(Vision GNN)--论文阅读](https://img-blog.csdnimg.cn/181c35f2d8cf4bc3b252f1eb9d3d1140.png)
![Docker快速搭建SkyWalking[ OAP UI[登录] Elasticsearch]](https://img-blog.csdnimg.cn/9c29e07ba0144fb6a772715540c6550f.png)