智能网联汽车在车联网的应用上,通常是以智能传感器、物联网、GIS技术为基础,结合大数据、人工智能技术,通过OT(Operation tecnology)和IT(information tecnology)融合的方式,实现智能车辆的辅助驾驶、状态监控、远程管理、数据分析及决策等功能。同时,通过对云端大数据的实时分析,还可以对运营车辆实现行程报警、路径规划、电子围栏、订单跟踪等企业级功能。
车联网云端大数据最重要的工作之一,是处理海量的GPS轨迹数据。GPS轨迹数据本质上是带时间标签的时序数据(time series data),市面上很多时序数据库都能够满足时序数据的简单存储和简单查询需求。
但在完整的车联网应用场景中,绝大部分时序数据库是无法直接输出最终业务所需结果的,也无法将时序数据与业务数据进行关联查询。
因此通常做法是在时序数据库的基础上,配合复杂的系统架构来支撑业务需求。例如,当我们想要将GPS轨迹跟车辆识别码、订单关联时,需要将GPS轨迹数据提取到应用端,使用关系数据库和编程工具进行二次处理。
这种方式虽然能解决业务查询问题,但是在一定程度上增加了系统的复杂性,并且在性能、开发难度、数据挖掘等方面受到架构限制。
有没有更简单、更轻量化的架构呢?
作为一个基于时序数据库管理系统,支持数据分析、流计算的低延时平台,DolphinDB 具有轻量化、一站式的特点,不仅可以高速存储海量结构化数据,还能在库内直接进行复杂计算,内置的高性能流数据处理框架满足了实时流计算的需求,且脚本语言对标准 SQL 高度兼容,简单易上手。
这里我们给大家介绍一个基于 DolphinDB 的车联网大数据处理架构。
在这一架构中,时间信息、车牌、经纬度、速度等多数据源的海量数据从采集层进入 DolphinDB 大数据平台,注入流数据表中。DolphinDB 通过订阅流数据表,并与订单业务、车辆配置等数据进行关联查询,实现分析与监测预警。输出的结果进入应用层,对接业务系统、消息中间件,或通过多种接口进行可视化展示。架构图如下所示:
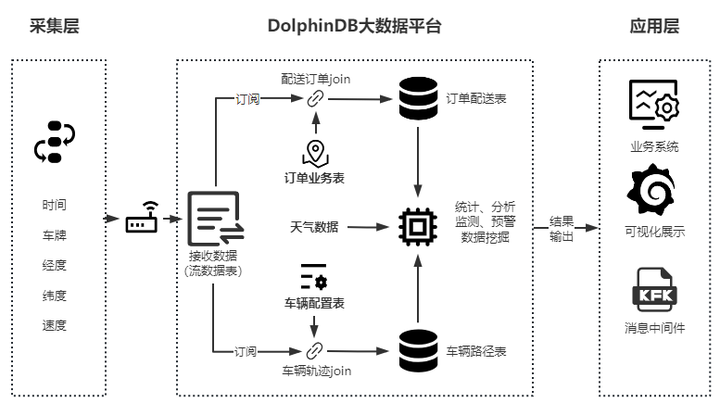
基于 DolphinDB 的车联网大数据处理架构图
使用这一架构可以实现海量轨迹数据的存储,车辆、订单的关联聚合查询,以及结果直接输出的完整流程。
下面我们给出一段查询案例,完整的脚本代码在附件中,任何开发人员都可以花10分钟左右的时间进行复现。
数据集
| 表描述 | 表名 | 数据量 |
|---|---|---|
| 车辆信息表 | t_car | 10万 |
| 订单信息表 | t_order | 100万 |
| 订单信息表 | t_drive | 8.64亿 |
环境配置
| 项目 | 参数 |
|---|---|
| 操作系统 | DELL Latitude 5420 笔记本电脑 windows 11 (22621.521) |
| CPU | 11th Gen Intel® Core™ i5-1145G7 @ 2.60GHz 1.50 GHz |
| 内存 | 16G |
| 磁盘 | SSD 512G |
| 服务端 | DolphinDB 2.00.9 |
SQL语句及参考耗时
| 序号 | 场景 | 耗时 | SQL 语句 |
|---|---|---|---|
| 1 | 统计车辆经纬数据总数 | 1ms | select count(*) from drives |
| 2 | 按车牌+时间,查询车辆经纬数据 | 4ms | select * from drives where ts=2022.07.01 22:10:10.000 , code=”浙A100207” |
| 3 | 按车牌,统计数据总数 | 5ms | select count(*) from drives where code=”浙A100207” |
| 4 | 按车牌,查看车辆与总部距离 | 3ms | select ts,code,string(long(distance(poi,point(lng, lat)))/1000)+“km” as distance from drives where ts=2022.07.01 22:10:10.000 , code=“浙A105207” |
| 5 | 按车牌,查询一天的所有数据 | 3ms | select * from drives where code=“浙A165207” and ts between 2023.01.01 00:00:00.000:2023.01.01 23:59:59.999 |
| 6 | 按车牌按每小时统计平均车速 | 12ms | select avg(velocity) from drives where code=“浙A165207” group by bar(ts,1H) |
| 7 | 按订单ID,查询该订单所有路径 | 112ms | //定义存储过程orderQuery orderQuery(1000006) |
| 8 | 以60倍速回放某订单的车辆行驶轨迹 | - | replay函数 |
以场景7为例,将轨迹表(8.6亿)和订单表(100w)进行关联,返回某个配送订单的全部车辆运行轨迹,耗时在112毫秒左右:
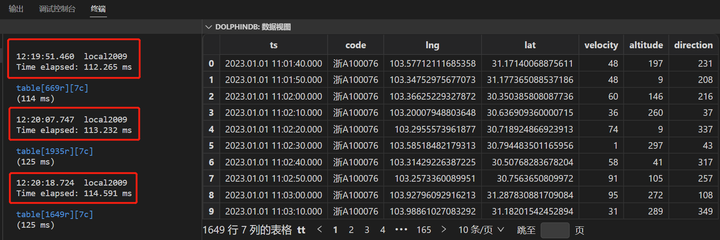
场景8中,将某个订单的数据,按60倍速持续写入一个新表中,读取新表数据并输出到GIS系统的地图中,就可以非常方便的实现某个订单车辆配送轨迹的实时播放,轻松回放行驶路径,用于异常排查。
10 分钟轻松验证(Windows 版)
| 步骤 | 任务 | 预计耗时 | 操作描述 |
|---|---|---|---|
| 1 | 部署DolphinDB大数据环境 | 1分钟 | 下载 DolphinDB,并解压(免安装) |
| 2 | 运行 | 1秒 | 双击 dolphindb.exe 文件,开启实例 |
| 3 | 运行开发环境 | 10秒 | 打开 http://localhost:8848, 网页上可执行 SQL 等脚本 |
| 4 | 模拟生成8.64亿数据 | 8分钟 | 复制《data.txt》脚本,执行(注意,此处模拟的是仿真数据,即每一条数据都是单独生成的,而不是简单的把一份数据重复复制。) |
| 5 | 验证查询性能 | 3分钟 | 复制《query.txt》脚本,依次执行,观察耗时 |
安装部署
1.下载官网社区最新版,建议2.00.9及以上版本。
传送门:https://www.dolphindb.cn/downloads/DolphinDB_Win64_V2.00.9.3.zip
2.windows解压路径,不能有空格,避免安装到Program Files路径下。
官网教程:standalone_server.md · dolphindb/Tutorials_CN - Gitee.com
3.本次测试使用免费的社区版,企业版license可申请免费试用。
联系方式:DolphinDB丨高性能分布式时序数据库
4.安装及测试过程中,有任何问题,可添加小助手微信(dolphindb1)咨询。
验证说明
1.统计耗时使用 timer 函数,即排除网络传输和序列化影响,仅统计服务端全部数据处理完成的时间。
2.性能受磁盘 IO、CPU、网络等系统资源的影响,如测试环境不同,表格中的性能实测数据可能会有差异。
3.web 端的交互编程执行方式,可以框选单条脚本,按 Ctrl-E 执行。也可以全选,按 Ctrl-E 执行。
4.模拟车辆轨迹写入的性能接近200万条/秒(1000万点/秒),可以作为真实数据写入性能的参考(排除协议连接、网络传输、序列化等耗时)。
5.性能测试优先保障性能,配置文件 dolphindb.cfg 中可以限制资源(核数、内存等)。
欢迎大家动手尝试,一起来验证一下吧!
附录
《data.txt》:建库建表,模拟数据生成
//步骤一:登录
login(`admin,`123456)
//步骤二:建库、建表
//1.车辆信息表:t_car
if(existsDatabase("dfs://t_car")){dropDatabase("dfs://t_car")}
create database "dfs://t_car" partitioned by VALUE([`code])
create table "dfs://t_car"."car" (
code SYMBOL, //车牌
model SYMBOL, //型号
emissions SYMBOL, //排量
brand SYMBOL //品牌
)
//2.配送订单表:t_order
if(existsDatabase("dfs://t_order")){dropDatabase("dfs://t_order")}
create database "dfs://t_order" partitioned by VALUE([date(now())]), engine="TSDB"
create table "dfs://t_order"."order" (
orderid LONG, //订单号
ts TIMESTAMP, //下单时间
btime TIMESTAMP, //配送起始时间
etime TIMESTAMP, //配送截止时间
code SYMBOL, //车牌
blng DOUBLE, //起始经度
blat DOUBLE, //起始纬度
elng DOUBLE, //目的地经度
elat DOUBLE //目的地纬度
)
partitioned by ts
sortColumns=[`orderid,`ts],
sortKeyMappingFunction=[hashBucket{,9}]
//3.车辆行驶路径表:dfs_drive
if(existsDatabase("dfs://dfs_drive")){dropDatabase("dfs://dfs_drive")}
create database "dfs://dfs_drive" partitioned by VALUE([date(now())]),HASH([SYMBOL,30]),engine="TSDB"
create table "dfs://dfs_drive"."drive" (
ts TIMESTAMP, //时间戳
code SYMBOL, //车牌
lng DOUBLE, //经度
lat DOUBLE, //纬度
velocity INT, //速度
altitude INT, //海拔
direction INT //方向
)
partitioned by ts,code
sortColumns=[`code,`ts],
sortKeyMappingFunction=[hashBucket{,99}]
//步骤三:模拟写入仿真数据
//写入车辆信息表:t_car(1万条)
n=100000
code=100001..200000 //产生序列数据
code="浙A"+string(code)
model=rand(`搅拌车`泵车`砂石车,n) //rand随机函数,用于产生数量为 n 的向量值
emissions=string(rand(5..10,n))+`升
brand=rand(`SANY`ZOOMLION`XCMG`LOXA`FANGYUAN`RJST,n)
t=table(code,model,emissions,brand)
t_car=loadTable("dfs://t_car",`car)
t_car.append!(t)
select count(*) from t_car //数据检查
select top 10 * from t_car
//写入订单信息表:t_order(100万条)
n=1000000
orderid=1000001..2000000 //产生序列数据
ts=take(2023.01.01..2023.01.10,n) //产生10天的订单
ts=sort(ts) //向量结构排序:10w条1月1日+10w条1月2日...+10w条1月10日
codes=select code from loadTable("dfs://t_car",`car) //获取1万车牌号码
code=take(codes.code,n) //向量结构:10w条车牌序列 x 10天=100w
btime=temporalAdd(datetime(ts),rand(14400,n)+32400,"s") //开始配送时间:9点~13点随机
etime=temporalAdd(datetime(btime),rand(18000,n)+3600,"s") //配送时间:1小时~5小时随机
blng=103.60972+rand(1.0,n)-0.5
blat=30.81841+rand(1.0,n)-0.5
elng=103.60972+rand(1.0,n)-0.5
elat=30.81841+rand(1.0,n)-0.5
t=table(orderid,ts,btime,etime,code,blng,blat,elng,elat)
t_order=loadTable("dfs://t_order",`order)
t_order.append!(t)
select count(*) from t_order //数据检查
select top 10 * from t_order
//写入车辆轨迹数据,8.64亿/天
def write_data(){
for(ts in 2023.01.01..2023.01.01){
//将10w车牌拆分成50份,写入50次(可通过降低拆分数量,进一步提高速度。如内存不支持,可能会Out Of Memory)
for(i in 1..50){
n=8640
j=(i-1)*2000
codes=select code from loadTable("dfs://t_car",`car) limit j , 2000*i
time = datetime(ts)+ 10*(0..(n-1))
lng=103.60972+rand(1.0,n)-0.5
lat=30.81841+rand(1.0,n)-0.5
velocity=rand(100,n)
altitude=rand(300,n)
direction=rand(360,n)
t=table(time as ts,lng,lat,velocity,altitude,direction)
tt = cj(t,codes) //关联车牌和数据,每次写入量:2000*8640
reorderColumns!(tt,loadTable("dfs://dfs_drive",`drive).schema().colDefs.name)
loadTable("dfs://dfs_drive",`drive).append!(tt)
tt=NULL
}
}
}
submitJob(`write_data,`write_data,write_data) //后台执行写入操作
drives=loadTable("dfs://dfs_drive",`drive) //数据检查
select count(*) from drives
《query.tx》:性能测试
// 步骤四:数据准备工作
//检查作业状态(预计执行8分钟)
select jobId,startTime as 开始时间,endTime as 结束时间,(endTime-startTime)/1000 as 执行秒数 from getRecentJobs(1)
//确定作业完成后,执行刷盘,LevelFile合并,清除缓存,确保性能测试的准确。
//因为短时间导入了大量数据,部分数据还在内存(CacheEngine)中,并逐步写入磁盘。为确保性能测试时,数据是从磁盘中读取,需要进行刷盘操作。
flushTSDBCache()
//LevelFile合并:优化历史数据的查询性能
chunkIds = exec chunkId from getChunksMeta() where type=1
for (x in chunkIds) {
triggerTSDBCompaction(x)
}
//清除缓存,确保测试性能准确
clearAllCache()
// 步骤五:查询统计
//全量数据检查:
/*1. 统计车辆经纬数据总数*/
drives=loadTable("dfs://dfs_drive",`drive)
timer t=select count(*) from drives
t
select top 10 * from drives
/*2. 按车牌+时间,查询车辆经纬数据*/
timer t=select * from drives where ts=2023.01.01 22:10:10.000 , code="浙A100207"
t
/*3 按车牌,统计数据总数*/
timer t=select count(*) from drives where code="浙A100207"
t
/*4 按车牌,查看车辆与总部距离*/
poi=point(104.102683,30.482596) //总部经纬度
timer t=select ts,code,string(long(distance(poi,point(lng, lat)))/1000)+`km as distance from drives where ts=2023.01.01 22:10:10.000 , code="浙A105207"
t
/*5 按车牌,查询一天的所有数据*/
timer t=select * from drives where code="浙A165207" and ts between 2023.01.01 00:00:00.000:2023.01.01 23:59:59.999
t
/*6 按车牌查询每小时的平均车速 */
timer t=select avg(velocity) from drives where code="浙A165207" group by bar(ts,1H)
t
/*7 按订单ID,查询某订单所有路径*/
//新建自定义函数,用来查询订单(100w)的轨迹(8.6亿)
def orderQuery(oid){
t=select code,btime,etime from loadTable("dfs://t_order",`order) where orderid=oid
carcode = t.code[0]
tt=select * from loadTable("dfs://dfs_drive",`drive) where code=carcode,ts between t.btime[0]:t.etime[0]
return tt
}
//执行订单查询
timer t=orderQuery(1000006)
t
//添加存储过程(函数视图):执行后,可通过api调用此函数
try{dropFunctionView(`orderQuery)}catch(x){}
addFunctionView(orderQuery)
/*8 以60倍速(每秒钟播放真实时间1分钟的轨迹数据)的速率,播放某订单的车辆行驶轨迹*/
rate=60 //回放倍速
t=orderQuery(1000006) //需要回放的数据
show=table(1:0,t.schema().colDefs.name,t.schema().colDefs.typeInt)
submitJob("replay_drive","回放订单轨迹", replay, t,show, `ts, `ts, rate,false)
//持续执行(可通过share函数将表共享,以输出到GIS系统的可视化地图)
select * from show order by ts desc






![[图神经网络]视觉图神经网络ViG(Vision GNN)--论文阅读](https://img-blog.csdnimg.cn/181c35f2d8cf4bc3b252f1eb9d3d1140.png)
![Docker快速搭建SkyWalking[ OAP UI[登录] Elasticsearch]](https://img-blog.csdnimg.cn/9c29e07ba0144fb6a772715540c6550f.png)


