ClickHouse 中最重要的表引擎:MergeTree 的深度原理解析
首先我们了解了 MergeTree 的基础属性和物理存储结构;接着,依次介绍了数据分区、一级索引、二级索引、数据存储和数据标记的重要特性;最后总结了 MergeTree 上述特性一起协同时工作过程。掌握了 MergeTree 即掌握了合并树系列表引擎的精髓,因为 MergeTree 本身也是一种表引擎。
1 概述
表引擎是 ClickHouse 中的一大特色,可以说表引擎决定了一张表最终的性格,比如数据表拥有何种特性、数据以何种形式被存储以及如何被加载。ClickHouse 拥有非常庞大的表引擎体系,总共有合并树、外部存储、内存、文件、接口和其它 6 大类 20 多种表引擎,而在这众多的表引擎中,又属合并树(MergeTree)表引擎及其家族系列(*MergeTree)最为强大,在生产环境中绝大部分场景都会使用此引擎。因为只有合并树系列的表引擎才支持主键索引、数据分区、数据副本、数据采样等特性,同时也只有此系列的表引擎支持 ALTER 相关操作。
当然我们说合并树家族自身也有很多表引擎的变种,其中 MergeTree 作为家族中最为基础的表引擎,提供了主键索引、数据分区、数据副本和数据采样等基本能力,而家族中的其它其它表引擎则在 MergeTree 的基础之上各有所长。
比如 ReplacingMergeTree 表引擎具有删除重复数据的特性。
比如 SummingMergeTree 表引擎则会按照排序键自动聚合数据。
如果再给合并树系列的表引擎加上 Replicated 前缀,又会得到一组支持数据副本的表引擎,例如 ReplicatedMergeTree、ReplicatedReplacingMergeTree、ReplicatedSummingMergeTree、ReplicatedAggregatingMergeTree 等等。

虽然合并树的变种有很多,但 MergeTree 表引擎才是根基。作为合并树家族最基础的表引擎,MergeTree 具备了该系列其它表引擎共有的基本特征,吃透了 MergeTree 表引擎的基本原理,就掌握了该系列表引擎的精髓。
docker start docker-clickhouse
docker exec -it docker-clickhouse /bin/bash
clickhouse-client --user default --password bigdata
2 MergeTree的创建方式与存储结构
MergeTree 在写入一批数据时,数据总会以数据片段的形式写入磁盘,且数据片段不可修改。而为了避免数据片段过多,ClickHouse 会通过后台线程定期的合并这些数据片段,属于相同分区的数据片段会被合并成一个新的数据片段,这种数据片段往复合并的过程,正是 MergeTree 名称的由来。
2.1 MergeTree的创建方式
创建数据表的方法我们上面介绍过,而创建 MergeTree 数据表只需要在创建表的时候将 ENGINE 指定为 MergeTree() 即可,其完整语法如下:
CREATE TABLE [IF NOT EXISTS] [db_name.]table_name(
name1 type [DEFAULT|MATERIALIZED|ALIAS expr],
name2 type [DEFAULT|MATERIALIZED|ALIAS expr],
......
) ENGINE = MergeTree()
[PARTITION BY expr]
ORDER BY expr
[PRIMARY KEY expr]
[SAMPLE BY expr]
[SETTINGS name1=value1, name2=value2, ......]
我们看到 MergeTree 表引擎除了常规的参数之外,还有一些独有的配置选项,大致看一下它们的作用。
(1)PARTITON BY:选填,表示分区键,用于指定表数据以何种标准进行分区。分区键既可以是单个字段、也可以通过元组的形式指定多个字段,同时也支持使用列表达式。如果不支持分区键,那么ClickHouse会生成一个名称为all的分区,合理地使用分区可以有效的减少查询时数据量。最常见的莫过于按照时间分区了,数据量非常大的时候可以按照天来分区,一天一个分区,这样查找某一天的数据时直接从指定分区中查找即可。
(2)ORDER BY:必填,表示排序键,用于指定在一个分区内,数据以何种标准进行排序。排序键既可以是单个字段,例如 ORDER BY CounterID,也可以是通过元组声明的多个字段,例如 ORDER BY (CounterID, EventDate)。如果是多个字段,那么会先按照第一个字段排序,如果第一个字段中有相同的值,那么再按照第二个字段排序,依次类推。总之在每个分区内,数据是按照分区键排好序的,但多个分区之间就没有这种关系了。
(3)PRIMARY KEY:选填,表示主键,声明之后会依次按照主键字段生成一级索引,用于加速表查询。如果不指定,那么主键默认和排序键相同,所以通常直接使用ORDER BY代为指定主键,无须使用PRIMARY KEY声明。所以一般情况下,在每个分区内,数据与一级索引以相同的规则升序排列(因为数据是按照排序键排列的,而一级索引也是按排序键、也就是主键进行排列的)。和其它关系型数据库不同,MergeTree允许主键有重复数据(可以通过ReplacingMergeTree实现去重)。
(4)SAMPLE KEY:选填,抽样表达式。用于声明数据以何种标准进行采样,注意:如果声明了此配置项,那么主键的配置中也要声明同样的表达式。例如:
......
) ENGINE = MergeTree()
ORDER BY (CountID, EventDate, intHash32(UserID))
SAMPLE BY intHash32(UserID)
-- 抽样表达式需要配合 SAMPLE子查询使用,该功能对选取抽样数据十分有用
-- 关于抽样查询,后面会在介绍查询的时候说
(5)SETTINGS:选填,用于指定一些额外的参数,以name=value的形式出现,name 主要包含 index_granularity、min_compress_block_size、index_granularity_bytes、enbale_mixed_granularity_parts、merge_with_ttl_timeout、storage_policy,比如:
......
) ENGINE = MergeTree()
......
SETTINGS index_granularity=8192, min_compress_block_size=6536
下面解释一下这些参数的含义:
1)index_granularity:对于MergeTree而言是一个非常重要的参数,它表示索引的粒度,默认值为8192。所以 ClickHouse 根据主键生成的索引实际上稀疏索引,默认情况下是每隔8192行数据才生成一条索引。类似于kafka的日志数据段,kafka 的每个数据段是由存储实际消息的数据文件,和用于加速消息查找的索引文件组成,而kafka的索引文件建立的也是稀疏索引。
2)min_compress_block_size:我们知道ClickHouse是会对数据进行压缩的,而 min_compress_block_size表示的就是最小压缩的块大小,默认值为65536。
3)index_granularity_bytes:在19.11版本之前ClickHouse只支持固定大小的索引间隔,由index_granularity控制,但是在新版本中增加了自适应间隔大小的特性,即根据每批次写入的数据的体量大小,动态划分间隔大小。而数据的体量大小,则由index_granularity_bytes参数控制的,默认为10M,设置为0表示不启用自适应功能。
4)enbale_mixed_granularity_parts:表示是否开启自适应索引的功能,默认是开启的。
5)merge_with_ttl_timeout:从 19.6 版本开始 MergeTree 提供了数据的 TTL 功能,该部分后面详细说。
6)storage_policy:从 19.15 版本开始 MergeTree 提供了多路径的存储策略,该部分同样留到后面详细说。
2.2 MergeTree数据表的存储结构
我们说在ClickHouse中一张表对应一个目录,那么MergeTree数据表对应的目录结构如何呢?我们之前说表对应的目录里面存储的就是文本文件(数据在磁盘上的载体),但对于MergeTree数据表而言还不太一样,因为我们说MergeTree数据表是有分区的,所以表对应的目录里面存储的还是目录。并且每个目录对应一个分区,因此也叫分区目录,而分区目录里面存储的才是负责容纳数据的文本文件。
所以一张MergeTree数据表在磁盘上的物理结构分为三个层级,依次是数据表目录、分区目录、以及各分区目录下的数据文件。
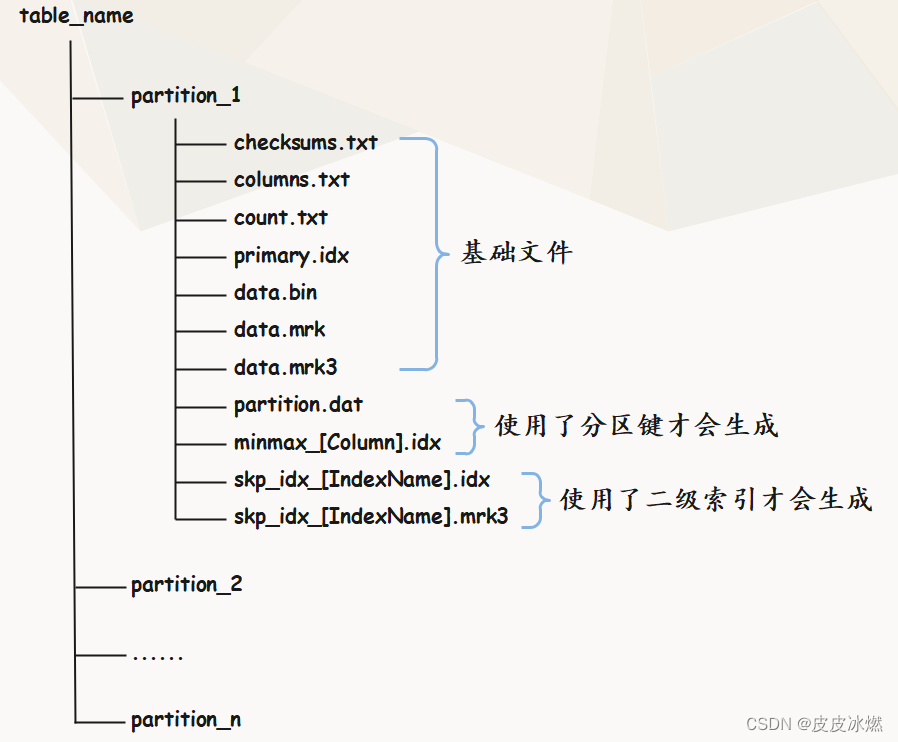
(1)partition:分区目录,里面的各类数据文件(primary.idx、data.mrk、data.bin 等等)都是以分区目录的形式被组织存放的,属于相同分区的数据,最终会被合并到同一个分区目录,而不同分区的数据永远不会被合并在一起。关于数据分区的细节,后面会详细说。
(2)checksums.txt:校验文件,使用二进制的格式进行存储,它保存了余下各类文件(primary.txt、count.txt 等等)的size大小以及哈希值,用于快速校验文件的完整性和正确性。
(3)columns.txt:列信息文件,使用明文格式存储,用于保存此分区下的列字段信息,比如我们创建一张表:
-- 该表负责存储用户参加过的活动,每参加一个活动,就会生成一条记录
CREATE TABLE IF NOT EXISTS user_activity_event (
ID UInt64, -- 表的 ID
UserName String, -- 用户名
ActivityName String, -- 活动名称
ActivityType String, -- 活动类型
ActivityLevel Enum('Easy' = 0, 'Medium' = 1, 'Hard' = 2), -- 活动难度等级
IsSuccess Int8, -- 是否成功
JoinTime DATE -- 参加时间
) ENGINE = MergeTree()
PARTITION BY toYYYYMM(JoinTime) -- 按照 toYYYYMM(JoinTime) 进行分区
ORDER BY ID; -- 按照 ID 字段排序
-- 插入一条数据
INSERT INTO user_activity_event VALUES (1, '张三', '寻找遗失的时间', '市场营销', 'Medium', 1, '2020-05-13')
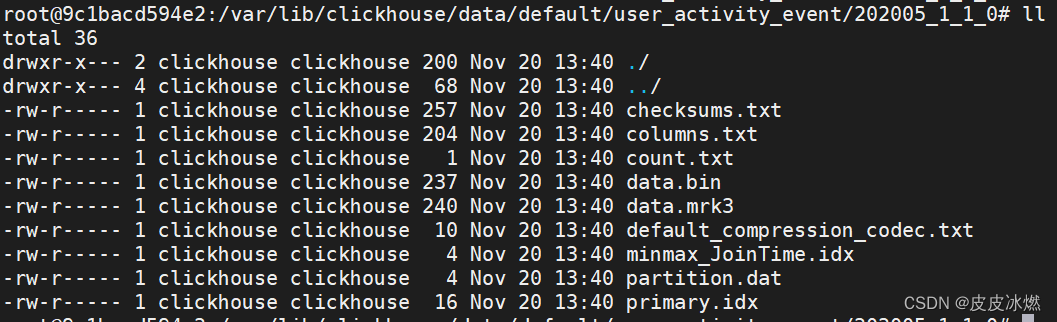
查看相关信息
# cd /var/lib/clickhouse/data/default/user_activity_event/202005_1_1_0
# cat columns.txt
columns format version: 1
7 columns:
`ID` UInt64
`UserName` String
`ActivityName` String
`ActivityType` String
`ActivityLevel` Enum8('Easy' = 0, 'Medium' = 1, 'Hard' = 2)
`IsSuccess` Int8
`JoinTime` Date
(4)count.txt:计数文件,使用明文格式存储,用于记录当前分区下的数据总数。所以后续在查询数据总量的时候可以瞬间返回,因为已经提前记录好了。
# cat count.txt
1
(5)primary.idx:一级索引文件,使用二进制格式存储,用于存储稀疏索引,一张 MergeTree表只能声明一次一级索引(通过ORDER BY或PRIMARY KEY)。借助稀疏索引,在查询数据时能够排除主键条件范围之外的数据文件,从而有效减少数据扫描范围,加速查询速度。
(6)data.bin:数据文件,使用压缩格式存储,默认为LZ4格式,用于存储表的数据。在老版本中每一个列字段都有自己独立的.bin数据文件,并以列字段命名,但是在新版本中只有一个data.bin,也就是合并在一起了。
(7)data.mrk:标记文件,使用二进制格式存储,标记文件中保存了data.bin文件中数据的偏移量信息,并且标记文件与稀疏索引对齐,因此MergeTree通过标记文件建立了稀疏索引(primary.idx)与数据文件(data.bin)之间的映射关系。而在读取数据的时候,首先会通过稀疏索引(primary.idx)找到对应数据的偏移量信息(data.mrk),因为两者是对齐的,然后再根据偏移量信息直接从data.bin文件中读取数据。
(8)data.mrk3:如果使用了自适应大小的索引间隔,则标记文件会以data.mrk3结尾,但它的工作原理和data.mrk文件是相同的。
(9)partition.dat和minmax_[Column].idx:如果使用了分区键,例如上面的 PARTITION BY toYYYYMM(JoinTime),则会额外生成partition.dat与 minmax_JoinTime.idx 索引文件,它们均使用二进制格式存储。partition.dat用于保存当前分区下分区表达式最终生成的值,而minmax_[Column].idx则负责记录当前分区下分区字段对应原始数据的最小值和最大值。
举个栗子,假设我们往上面的 user_activity_event 表中插入了 5 条数据,JoinTime 分别 2020-05-05、2020-05-15、2020-05-31、2020-05-03、2020-05-24,显然这 5 条都会进入到同一个分区,因为toYYYMM 之后它们的结果是相同的,都是 2020-05,而 partition.dat 中存储的就是 2020-05,也就是分区表达式最终生成的值;同时还会有一个 minmax_JoinTime.idx 文件,里面存储的就是 2020-05-03 2020-05-31,也就是分区字段对应的原始数据的最小值和最大值。
在这些分区索引的作用下,进行数据查询时能够快速跳过不必要的分区目录,从而减少最终需要扫描的数据范围。比如我们存储了JoinTime 为 2020-01-01 到 2020-12-31 一整年用户参加活动的数据,那么 toYYYYMM 之后肯定就会有 12 个分区,然后按照 JoinTime 查找数据的时候,比如要查找 JoinTime 为 2020-06-12 的数据,那么直接去指定的分区(2020-06)中查找即可,也就是我们通过分区机制将查询范围限定在 2020-06,其余的 11 个月的数据我们压根不用看,因此大大减少了查询的数据量。
(10)skp_idx_[IndexName].idx 和 skp_idx_[IndexName].mrk3:如果在建表语句中指定了二级索引(后面会说),则会额外生成相应的二级索引文件与标记文件,它们同样使用二进制存储。二级索引在 ClickHouse 中又被称为跳数索引,目前拥有 minmax、set、ngrambf_v1 和 token_v1 四种类型,这些种类的跳数索引的目的和一级索引都相同,都是为了进一步减少数据的扫描范围,从而加速整个查询过程。
3 数据分区
通过之前的介绍我们已经知道在MergeTree数据表中,数据是以分区目录的形式进行组织的,每个分区的数据独立分开存储。借助这种形式,MergeTree在查询数据时,可以跳过无用的数据文件,只在最小分区目录子集中查询。这里再强调一次,在ClickHouse中存在数据分区(partition)和数据分片(shard),但它们是完全不同的概念。数据分区是针对本地数据而言的,相当于是对数据的一种纵向切分,就类似将关系型数据中的一张大高表切成多张个头没那么高的子表。
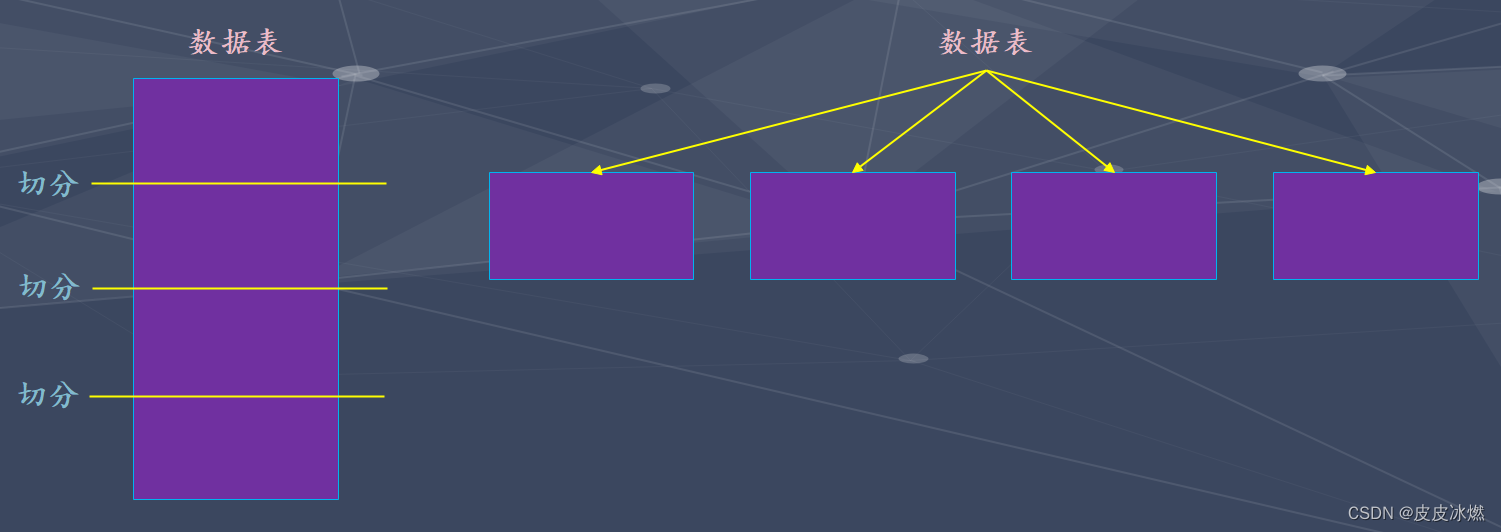
而数据分片则与 ClickHouse 集群相关,我们后面会说,我们目前都是单机的,所以不涉及数据分片。
3.1 数据的分区规则
MergeTree数据表的分区规则由分区ID决定,而具体到每个分区对应的ID则是由分区键的取值决定的。分区键支持使用任何一个或一组字段表达式声明,其业务语义可以是年、月、日或者组织单位等任何一种规则,而针对取值数据的类型不同,分区ID的生成逻辑目前拥有四种规则:
(1)不指定分区键:如果不使用分区键,即不使用PARTITION BY声明任何分区表达式,则分区ID默认为all,所有的数据都会被写入all这个分区。
(2)使用整型:如果分区键的取值为整型(UInt64、Int8等等都算),且无法转成日期类型YYYYMMDD 格式,则直接按照该整型的字符串形式作为分区ID的取值。
(3)使用日期类型:如果分区键取值属于日期类型,或者是能够转换为 YYYYMMDD格式的整型,则使用按照YYYYMMDD进行格式化后的字符串形式作为分区ID的取值。
(4)使用其它类型:如果分区键取值既不是整型、也不是日期类型,比如String、Float等等。则通过128位Hash算法取其Hash值作为分区ID的取值。
如果是PARTITION BY toYYYYMM(JoinTime) 为例,当写入一条 JoinTime为2020-09-18的记录时,该记录就会落在分区ID为 202009 的分区中;
如果是 PARTITION BY JoinTime,那么 JoinTime 为 2020-09-18 的记录就会落在分区 ID 为 20200918 的分区中;
再比如 PARTITION BY age,当写入一条 age 为 16 的记录时,该数据就会落在分区ID为16的分区中;
再比如 PARTITION BY length(name),那么 name 为 “古明地觉” 的记录就会落在分区ID为4的分区中,name为 “雾雨魔理沙” 的记录就会落在分区ID为5的分区中。
相信这个分区ID还是好理解的,但需要注意的是,如果分区字段有多个,那么会按照相同的规则为每个字段都生成一个分区ID,最后再将这些分区ID使用减号合并起来,作为最终的分区ID。
比如:PARTITION BY (length(UserName), toYYYYMM(JoinTime)),那么 UserName为"张三"、JoinTime为2020-05-13的记录就会落在分区ID为2-202005 的分区中。
3.2 分区目录的命名规则
现在我们已经知道了分区ID生成规则,但如果进入数据表所在的磁盘目录时,会发现MergeTree分区目录的完整物理名称并不只有分区ID,在ID的后面还跟着一串奇怪的数字,以我们之前创建的user_activity_event数据表为例,里面有一个分区,其名称就叫202005_1_1_0。前面的202005显然就是分区 ID,那后面的部分代表啥含义呢?
首先对于MergeTree而言,其最大的特点就是分区目录的合并动作,而合并逻辑我们从分区目录的名称便可窥知一二。
首先分区目录的命名规则是:PartitionID_MinBlockNum_MaxBlockNum_Level。

下面来解释一下这几个部分:
(1)PartitionID:分区 ID,这个应该无需多说。
(2)MinBlockNum、MaxBlockNum:最小数据块编号和最大数据块编号,这里的命名很容易让人联想到后面要说的数据压缩块,甚至产生混淆,但实际上这两者没有任何关系。
这里的 BlockNum 是一个自增的整数,从1开始,每当创建一个新的分区时就会自增1,并且对于一个新的分区目录而言,它的MinBlockNum和 MaxBlockNum是相等的。比如 202005_1_1_0、202006_2_2_0、202007_3_3_0,以此类推。但是也有例外,当分区目录发生合并的时候,那么其 MinBlockNum 和 MaxBlockNum 会有另外的规则,一会儿细说。
(3)Level:合并的层级,可以理解为某个分区被合并的次数,这里的 Level 和 BlockNum 不同,它不是全局累加的。对于每个新创建的目录而言,其初始值都为 0,之后以分区为单位,如果相同分区发生合并动作,则该分区对应的 Level 加 1。可能有人不是很理解这里的 “相同分区发生合并” 到底是什么意思,我们下面就来介绍。
3.3 分区目录的合并过程
MergeTree的分区目录和其它传统意义上数据库有所不同,首先MergeTree的分区目录并不是在数据表被创建之后就存在的,而是在数据写入的过程中被创建的,如果一张表中没有任何数据,那么也就不会有任何的分区目录。也很好理解,因为分区目录的命名与分区ID有关,而分区ID又和分区键对应的值有关,而表中连数据都没有,那么何来分区目录呢。
其次,MergeTree的分区目录也不是一成不变的,在其它数据库的设计中,追加数据的时候目录自身不会改变,只是在相同分区中追加数据文件。而MergeTree 完全不同,伴随着每一次数据的写入,MergeTree都会生成一批新的分区目录,即使不同批次写入的数据属于相同的分区,也会生成不同的分区目录。也就是说对于同一个分区而言,会存在对应多个分区目录的情况。而在之后的某个时刻(一般 10 到 15 分钟),ClickHouse 会通过后台任务将属于相同分区的多个目录合并(Merge)成一个新的目录,当然也可以通过 optimize TABLE table_name FINAL 语句立即合并,至于合并之前的旧目录会在之后的某个时刻(默认8分钟)被删除。
属于同一个分区的多个目录,在合并之后会生成一个全新的目录,目录中的索引和数据文件也会相应地进行合并。而新目录的名称的生成方式遵循如下规则:
PartitionID:不变
MinBlockNum:取同一分区内所有目录中最小的 MinBlockNum
MaxBlockNum:取同一分区内所有目录中最大的 MaxBlockNum
Level:取同一分区内最大Level值并加 1
一、假设我们之前的user_activity_event表是空的,然后我们往里面分3批写入3条数据:
INSERT INTO user_activity_event VALUES (1, '张三', '寻找遗失的时间', '市场营销', 'Medium', 1, '2020-05-01');
INSERT INTO user_activity_event VALUES (1, '李四', '寻找遗失的时间', '市场营销', 'Medium', 0, '2020-05-02');
INSERT INTO user_activity_event VALUES (1, '王五', '寻找遗失的时间', '市场营销', 'Medium', 1, '2020-06-01');
根据规则,ClickHouse会创建3个分区目录,分区目录的PartitionID部分依次为202005、202005、202006;
而对于每个新创建的分区目录而言,它们的MinBlockNum和MaxBlockNum都是相等的,并且我们说 MinBlockNum 和 MaxBlockNum 是全局的,从 1 开始自增,所以三个分区目录的MinBlockNum和MaxBlockNum依次是1 1、2 2、3 3;
最后是 Level,每个新建的分区目录的初始 Level 都是0。因此三个分区目录的最终名称就是202005_1_1_0、202005_2_2_0、202006_3_3_0。
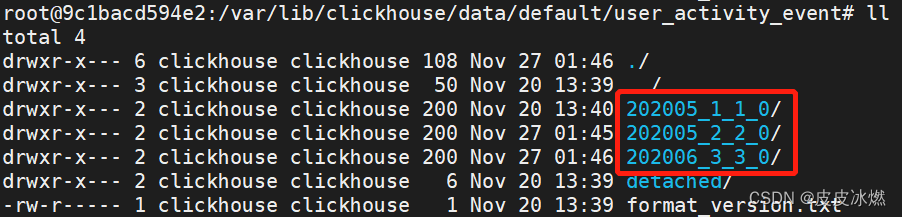
二、之后在某一时刻 MergeTree 的合并动作开始了,那么属于同一分区的202005_1_1_0、202005_2_2_0将会发生合并,得到202005_1_2_1(MinBlockNum取最小值、MaxBlockNum取最大值,Level取最大值加 1)。

三、然后我们再插入三条数据(分3批写入),JoinTime 分别为 2020-05-03、2020-06-02、2020-07-01,那么会再创建 3 个分区目录,分区 ID 分别为 202005、202006、202007:
INSERT INTO user_activity_event VALUES (1, '张1', '寻找遗失的时间', '市场营销', 'Medium', 1, '2020-05-03');
INSERT INTO user_activity_event VALUES (1, '李2', '寻找遗失的时间', '市场营销', 'Medium', 0, '2020-06-02');
INSERT INTO user_activity_event VALUES (1, '王3', '寻找遗失的时间', '市场营销', 'Medium', 1, '2020-07-01');
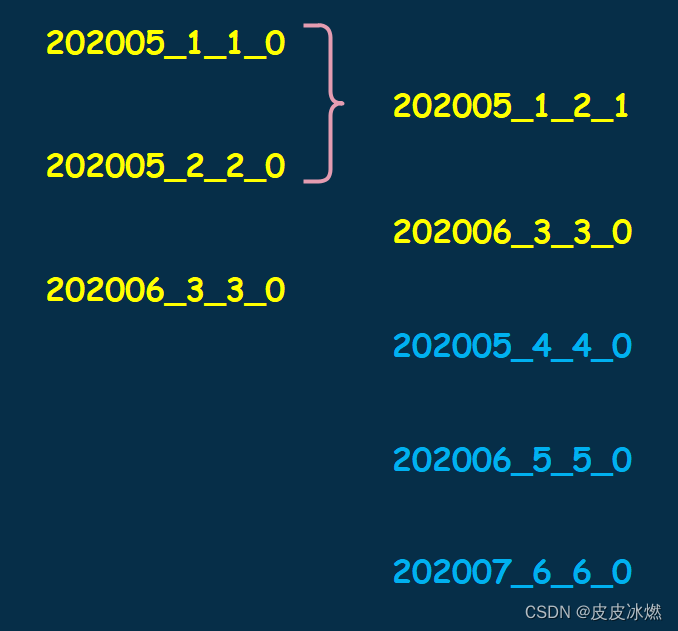
四、之后 MergeTree 的合并动作开始,属于相同分区的目录开始合并,202005_1_2_1 和 202005_4_4_0 会发生合并,得到 202005_1_4_2;202006_3_3_0 和 202006_5_5_0 发生合并,得到 202006_3_5_1。
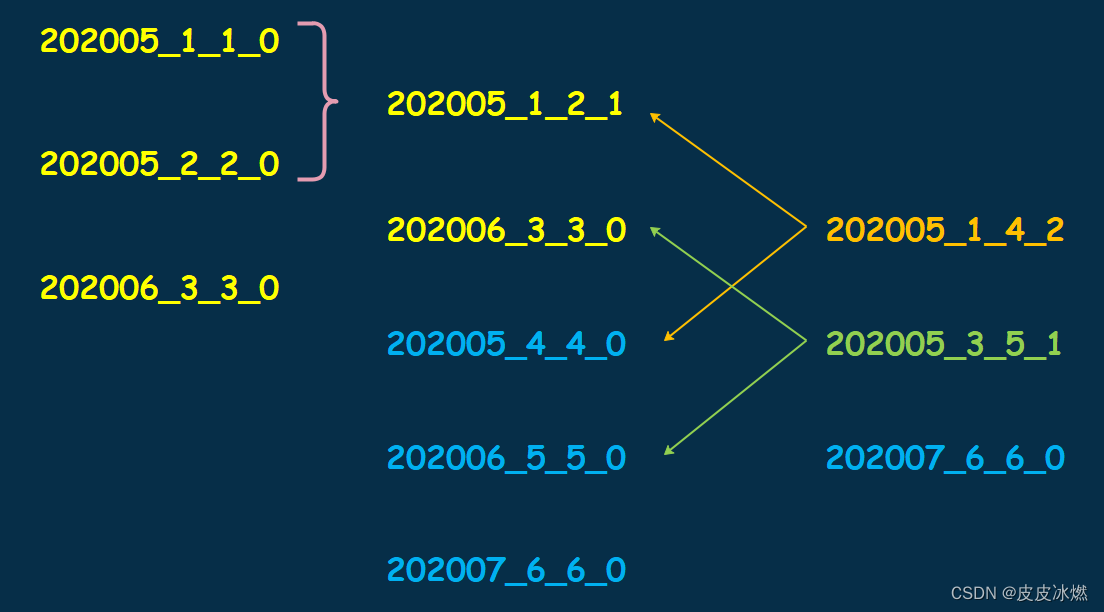
如果再写入数据的话,那么 MergeTree 依旧会发生合并,然后重复和上面的一样的动作。相信到这里已经明白分区 ID、目录命名、以及数据合并的相关规则。
但需要注意的是:我们上面显示的是目录合并之后的结果,至于旧的分区目录、也就是合并之前的目录会依旧保留一段时间,但已不再是激活状态(active = 0),在数据查询的时候会被过滤掉。然后 ClickHouse 有一个后台任务会定时扫描(默认 8 分钟),负责将 active = 0 的目录从物理磁盘上删除。
4 一级索引
MergeTree的主键使用PRIMARY KEY定义,主键定义之后,MergeTree会依据 index_granularity间隔(默认8192行)为数据表生成一级索引并保存至primary.idx文件中,并按照主键进行排序。
如果不指定PAIMARY KEY,那么主键默认和排序键相同,在这种情况下,索引(primary.idx)和数据(data.bin)会按照完全相同的规则排序。
使用PRIMARY KEY定义主键和使用ORDER BY代替定义主键,两者之间还是有点差别的,这个差别会在SummingMergeTree中有所体现,后续介绍 。
4.1 稀疏索引
primary.idx文件内的一级索引采用稀疏索引实现,既然有稀疏索引,那么是不是也有稠密索引呢?答案是还真有,稀疏索引和稠密索引之间的区别如下:
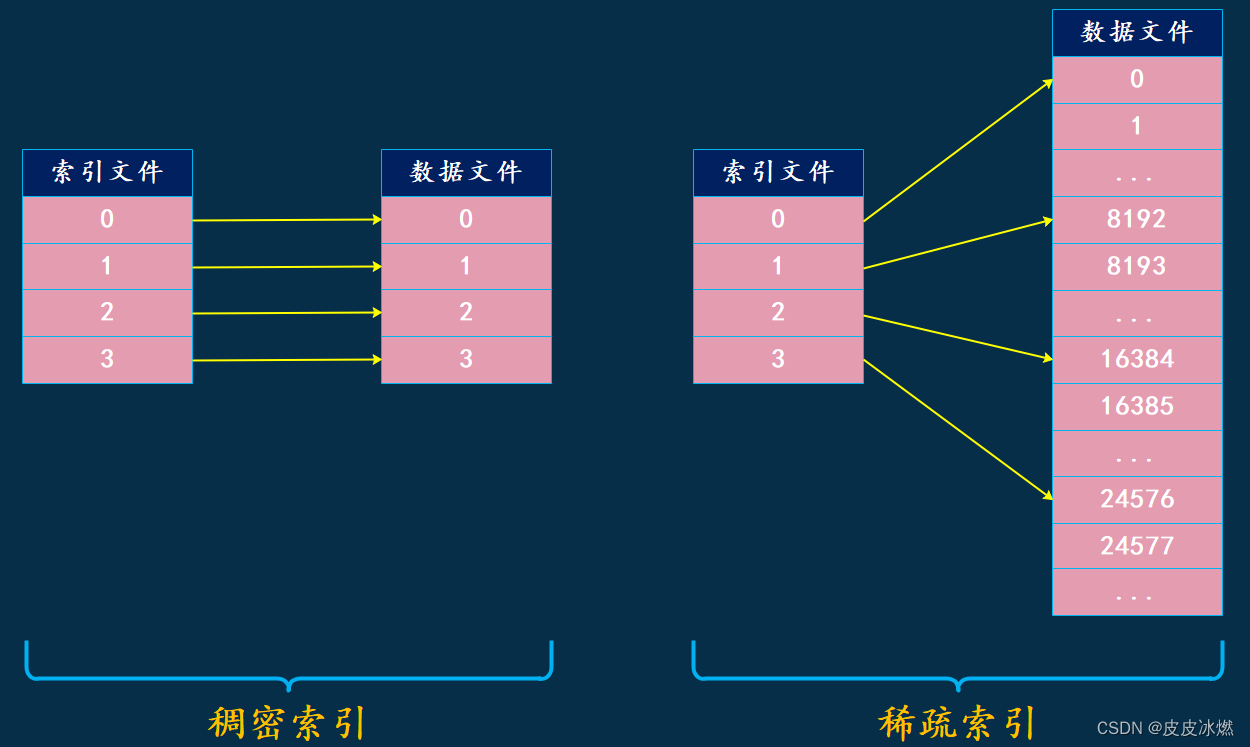
从图中可以看到,在稠密索引中每一行数据都会对应一行唯一的索引;而在稀疏索引中只有部分数据会对应索引,也就是相邻索引对应的数据不相邻,中间会跨越一定行数的数据。那么问题来了,稀疏索引是如何准确定位数据的呢?
假设我要找第10000条数据,那么首先ClickHouse会进行一次二分查找,找到对应的索引。因为0 -> 0、1 -> 8192、2 -> 16384,而第10000条数据位于8192和16384 之间,那么要找的索引就是 1,于是ClickHouse会再通过索引 1 找到第 8192 行数据,然后不断往后遍历,最终找到我们要数据。
如果熟悉kafka的话,kafka底层存储消息也是用到的稀疏索引,还是很好理解的。但是问题来了,为什么不用稠密索引呢?如果使用稠密索引的话,那么直接就可以定位到准确的数据,从而减少后续遍历所带来的磁盘IO,可为什么不这么做呢。其实原因很简单,ClickHouse、kafka都是应用在大数据场景下,由于数据量本身就很大,那么使用稠密索引带来的空间占用也会很大。而稀疏索引占空间小,因为不需要那么多行,以默认的索引粒度(8192)为例,MergeTree只需要12208行索引标记就能为1亿行数据记录提供索引。虽然后续遍历会带来额外的磁盘 IO,但由于是顺序 IO,因此效率实际上是不低的,我们知道机械磁盘虽然不擅长随机读写,但顺序读写还是很快的,SSD就更不必说了。
最关键的是,由于稀疏索引占用空间小,那么可以常驻内存,因此读取的速度非常快。如果使用稠密索引,那么由于空间占用过大而可能导致无法读进内存中,因此只能在磁盘上操作,这样在查找索引的时候也会带来磁盘IO。因此综上所述,使用稀疏索引的性价比相较于稠密索引明显要更高,因为速度相差不大,但省下了大量的磁盘空间。
注意:虽然我们说索引和数据之间是对应的,但我们知道它们不是直接对应的,我们之前介绍数据表的存储结构时说过,除了索引文件(primary.idx)和数据文件(data.bin)之外,还有一个标记文件(data.mrk)。标记文件中保存了 data.bin 文件中数据的偏移量信息,并且标记文件(或者说偏移量)与稀疏索引对齐,因此想要通过索引找到具体的数据还需要借助于data.mrk中偏移量。
4.2 索引粒度
索引粒度是建表的时候,在SETTINGS里面指定index_granularity控制的,虽然 ClickHouse提供了自适应粒度大小的特性,但是为了便于理解,我们会使用固定的索引粒度进行介绍(8192)。索引粒度对于 MergeTree 而言是一个非常重要的概念,它就如同一把标尺,会丈量整个数据的长度,并依照刻度对数据进行标注,最终将数据标记成多个间隔的小段。
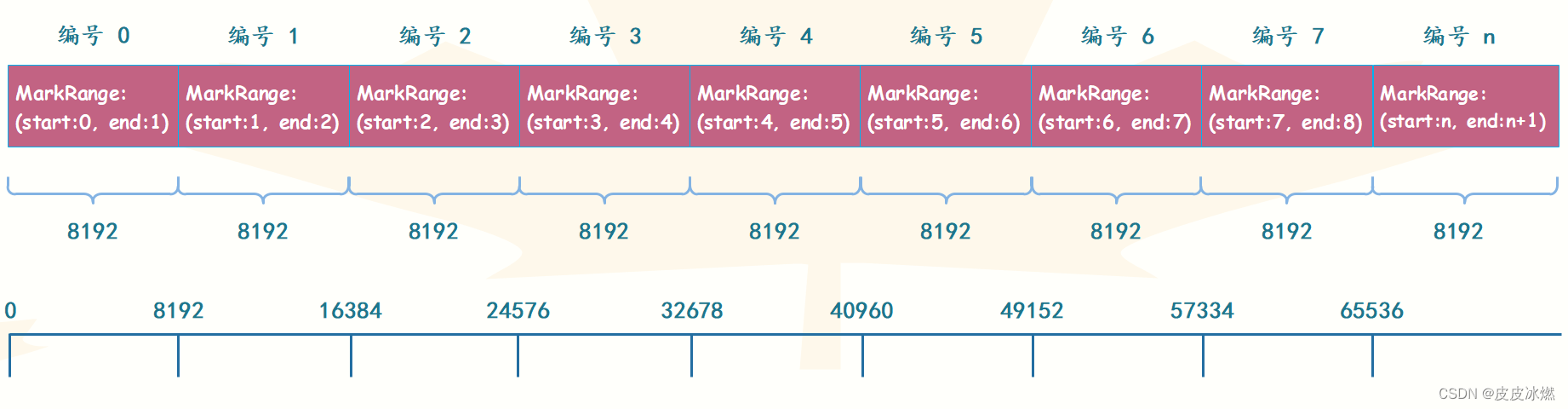
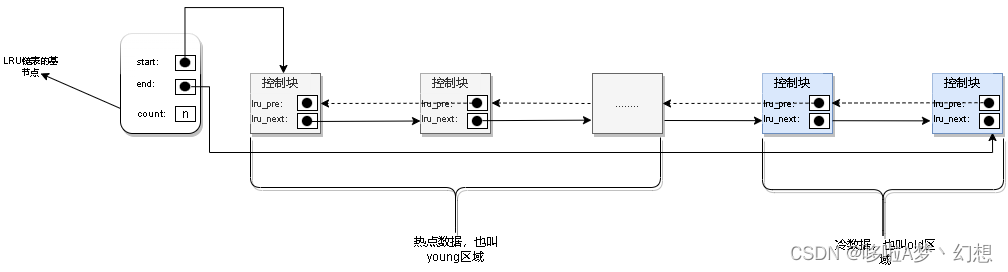
数据以 index_granularity 的粒度(默认 8192)被标记成多个小的区间,其中每个区间最多 8192 行数据,MergeTree 使用 MarkRange 表示一个具体的区间,并通过 start 和 end 表示其具体的范围。index_granularity 的名字虽然取了索引二字,但它不单单只作用于一级索引,同时还会影响数据标记文件(data.mrk)和数据文件(data.bin)。
因为只有一级索引是无法完成查询工作的,它需要借助标记文件中的偏移量才能定位数据,所以一级索引和数据标记的间隔粒度(同为 index_granularity 行)相同,彼此对齐,而数据文件也会按照 index_granularity 的间隔粒度生成压缩数据块。
4.3 索引数据的生成规则
由于是稀疏索引,所以MergeTree需要间隔index_granularity行数据才会生成一条索引记录,其索引值会依据声明的主键字段获取。这里我们创建一张表:
CREATE TABLE hits_v1 (
CounterID Int64,
EventDate Date
) ENGINE = MergeTree()
PRIMARY KEY CounterID -- 也可以不写,默认和排序键保持一致
ORDER BY CounterID
PARTITION BY toYYYYMM(EventDate)
显然 EventDate 为 2020 年 4 月的数据会被划分到同一个分区目录中,并且每隔 8192 条数据就会取一次 CounterID 的值(排好序的)作为索引值,写入 primary.idx 文件进行保存。
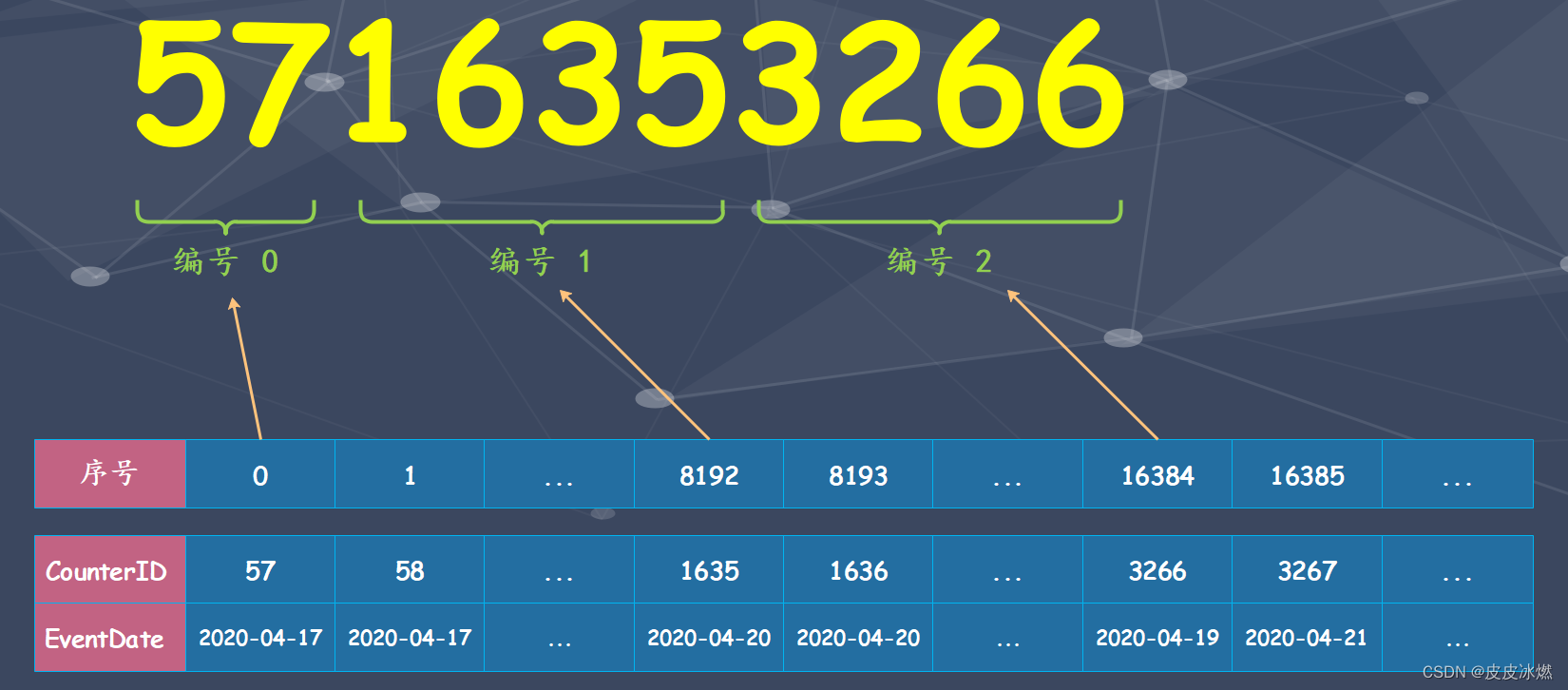
例如第 0 行(8192 * 0)的 CounterID 取值为 57,第 8192 行(8192 * 1)的 CounterID 取值为 1635,第 16384 行(8192 * 2)的 CounterID 取值为 3266,最终索引数据将会是 5716353266…。
可以看到 MergeTree 对于稀疏索引的存储是非常紧凑的,索引值前后相连,按照主键字段顺序紧密地排列在一起。并且不仅是这里,ClickHouse 中很多数据结构都被设计的非常紧凑,比如使用位读取替代专门的标志位或状态码(假设 32 位整型存储的数据最多占用 20 个位,那么就可以只用 20 个位表示数据,然后剩余的位用来表示状态码),不浪费任何一个字节。所以 ClickHouse 性能出众不是没有原因的,每一步都做足了优化。
如果使用多个主键,例如 ORDER BY (CounterID, EventDate),则每间隔 8192 行会同时取 CounterID 和 EventDate 两列的值作为索引值。
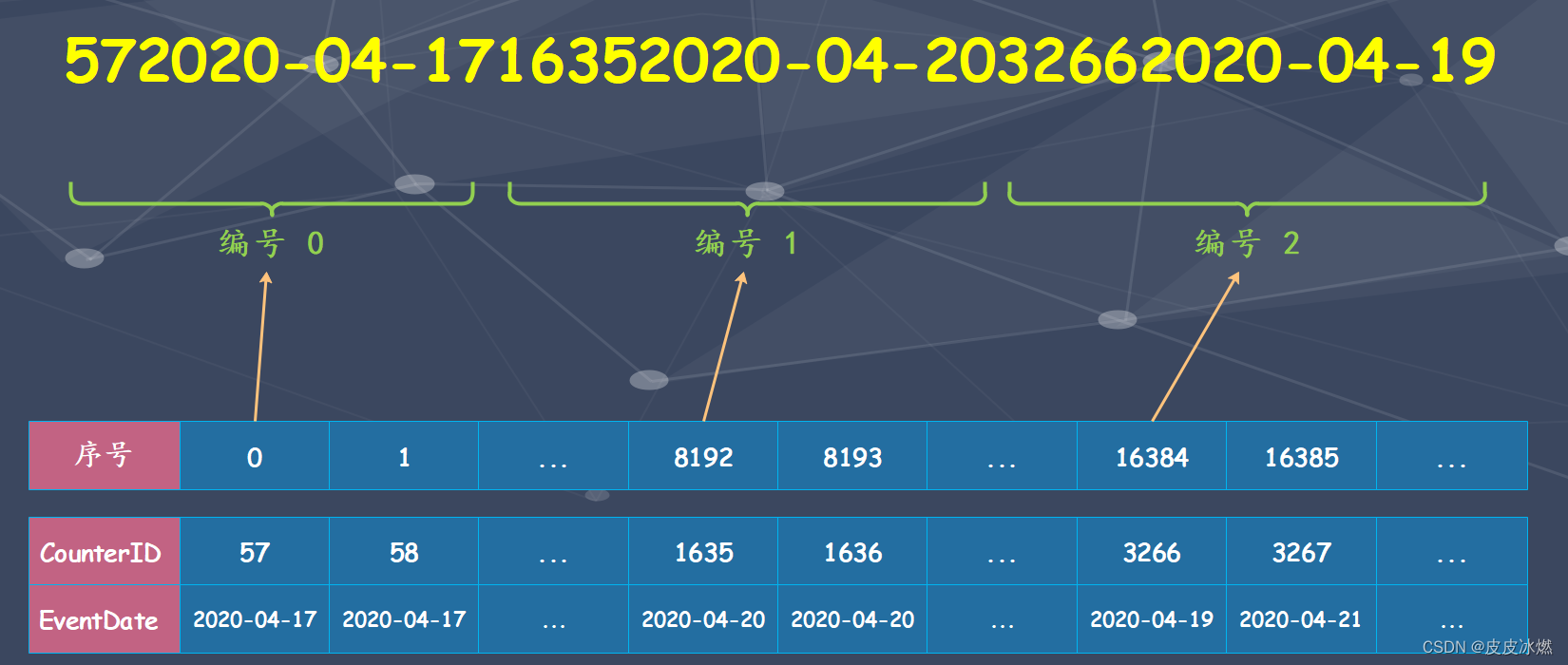
4.4 索引的查询过程
在说完索引的一些概念之后,接下来说明索引具体是如何工作的。首先我们需要了解什么是 MarkRange,MarkRange 在 ClickHouse 中是用于定义标记区间的对象。MergeTree 按照 index_granularity 的间隔粒度,将一段完整的数据划分成了多个小的间隔数据段,一个具体的数据段就是一个 MarkRange,并与索引编号对应,使用start 和 end 两个属性表示其范围。通过 start 和 end 对应的索引编号的取值,即可得到它所对应的数值区间,而数值区别表示了此 MarkRange 的数据范围。
如果只是这么干巴巴的介绍,可能会有些抽象,下面用一份示例数据来说明一下。假如现在有一份测试数据,共 192 行记录,其中主键 ID 为 String 类型,取值从 A000 开始,后面依次为 A001、A002、…,直到 A192 为止。MergeTree 的索引粒度 index_granularity 为 3,根据索引的生成规则,那么 primary.idx 文件的索引如下所示:

根据索引数据,MergeTree 会将此数据片段划分成 192/3=64 个小的 MarkRange,两个相邻的 MarkRange 相距的步长为 1。其中,所有 MarkRange(整个数据片段)的最大数值区间为 [A000, +inf),完整示意图如下:

在引入了数值区间的概念之后,对于索引数据的查询过程就很好解释了,索引查询其实就是两个区间的交集判断。其中一个区间是由基于主键的查询条件转换而来的条件区间;另一个区间就是上面说的与 MarkRange 对应的数值区间。
所以整个查询可以分为三步:
1)生成查询区间:首先将查询条件转换为区间,即使是单个值也会转换为区间的形式,举个栗子:
WHERE ID = 'A003' -> ['A003', 'A003']
WHERE ID > 'A012' -> ('A012', +inf]
WHERE ID < 'A185' -> [-inf, 'A185')
WHERE ID LIKE 'A006%' -> ['A006', 'A007')
2)递归交集判断:以递归的形式,依次对 MarkRange 的数值区间与条件区间做交集判断,从最大的区间 [A000, +inf) 开始:
如果不存在交集,则直接通过剪枝算法优化此整段 MarkRange。
如果存在交集,且 MarkRange 步长大于等于 8(end - start),则将此区间进一步拆分成 8 个子区间(由 merge_tree_coarse_index_granularity 指定,默认值为 8),然后重复此过程,继续做递归交集判断。
如果存在交集,且 MarkRange 不可再分解(步长小于 8),则记录 MarkRange 并返回。
3)合并 MarkRange 区间:将最终匹配的 MarkRange 聚在一起,合并它们的范围。
还以上面的测试数据为例,查询条件为 ID = ‘A003’。
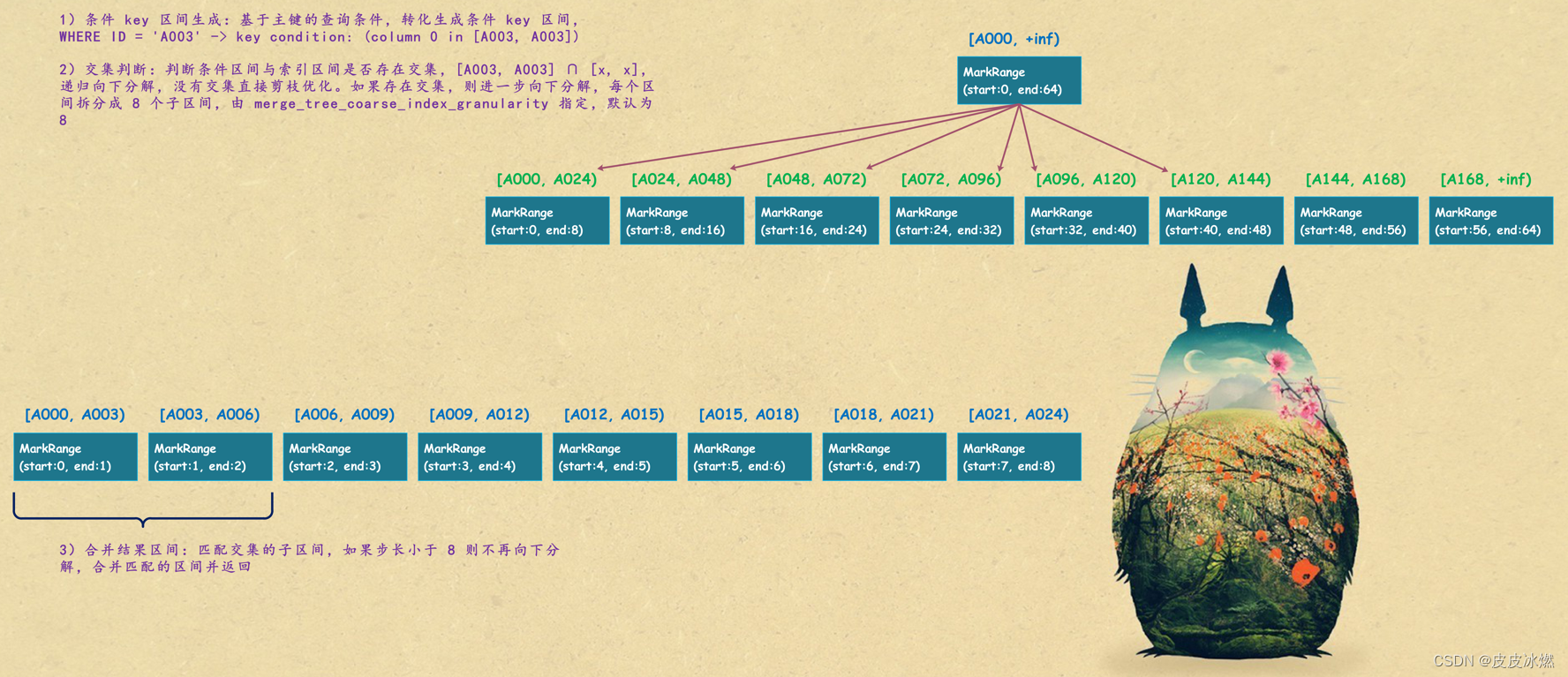
MergeTree 通过递归的形式持续向下拆分区间,最终将 MarkRange 定位到最细的粒度,以便在后续读取数据的时候,能够最小化数据的扫描范围。以上图为例,当查询条件为 ID = ‘A003’ 的时候,最终只需要读取 [A000, A003] 和 [A003, A006] 两个区间的数据,它们对应 MarkRange(start:0, end:2) 范围,而其它无用区间都被裁剪掉了。由于 MarkRange 转换的数值区间是闭区间,所以会额外匹配到临近的一个区间。
5 二级索引
除了一级索引之外,MergeTree 同样支持二级索引,二级索引又称跳数索引,由数据的聚合信息构建而成。根据索引类型的不同,其聚合信息的内容也不同,当然跳数索引的作用和一级索引是一样的,也是为了查询时减少数据的扫描范围。
跳数索引需要在 CREATE 语句内定义,它支持使用元组和表达式的形式声明,其完整的定义语法如下所示:
CREATE TABLE table_name (
column1 type,
column2 type,
......
INDEX index_name expr TYPE index_type(...) GRANULARITY granularity
)
与一级索引一样,如果在建表语句中声明了跳数索引,则会额外生成相应的索引文件和标记文件(skp_idx_[Column].idx 与 skp_idx_[Column].idx)。
5.1 granularity和index_granularity的关系
不同的跳数索引之间,除了它们自身独有的参数之外,还都共同拥有 granularity 参数。初次接触时,很容易将 granularity 和 index_granularity 的概念弄混淆,对于跳数索引而言,index_granularity 定义了数据的粒度,而 granularity 定义了聚合信息汇总的粒度。换言之,granularity 定义了一行跳数索引能够跳过多少个 index_granularity 区间的数据。
要解释清除 granularity 的作用,就要成跳数索引的生成规则说起,其规则大致是如下:首先按照 index_granularity 粒度间隔将数据划分成 n 段,总共有 [0, n - 1] 个区间(n = totol_rows / index_granularity,向上取整);接着根据索引定义时声明的表达式,从 0 区间开始依次按照 index_granularity 粒度从数据中获取聚合信息,每次向前移动一步,聚合信息聚合信息逐步累加。最后当移动 granularity 次区间时,则汇总并声称一行跳数索引数据。
以 minmax 索引为例,它的聚合信息是在一个 index_granularity 区间内数据的最小和最大极值。
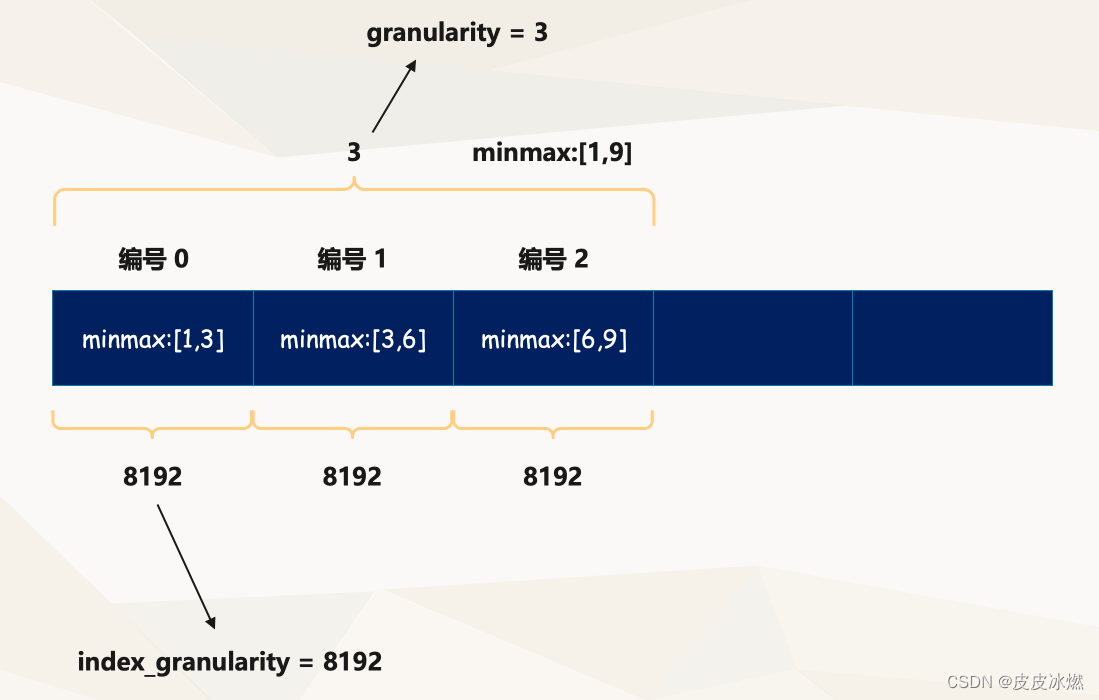
以上图为例,假设 index_granularity = 8192 且 granularity = 3,则数据会按照 index_granularity 划分为 n 等份,MergeTree 从第 0 段分区开始,依次获取聚合信息。当获取到第 3 个分区时(granularity = 3),则会汇总并生成第一行 minmax 索引(前 3 段 minmax 极值汇总后取值为 [1, 9])。
5.2 跳数索引的类型
目前 MergeTree 共支持 4 种跳数索引,分别是:minmax、set、ngrambf_v1 和 tokenbf_v1,一张数据表支持同时声明多个跳数索引,比如:
CREATE TABLE skip_test
(
ID String,
URL String,
Code String,
EventTime Date,
INDEX a ID TYPE minmax GRANULARITY 5,
INDEX b (length(ID) * 8) TYPE set(100) GRANULARITY 5,
INDEX c (ID, Code) TYPE ngrambf_v1(3, 256, 2, 0) GRANULARITY 5,
INDEX d ID TYPE tokenbf_v1(256, 2, 0) GRANULARITY 5
) ENGINE = MergeTree()............
接下来就借助上面的栗子来介绍这几种跳数索引的用法:
1)minmax:minmax 索引记录了一段数据内的最小值和最大值,其索引的作用类似分区目录的 minmax 索引,能够快速跳过无用的数据区间。
INDEX a ID TYPE minmax GRANULARITY 5
上述示例中 minmax 索引会记录这段数据区间内 ID 字段的极值,极值的计算涉及每 5 个 index_granularity 区间中的数据。
2)set:set 索引直接记录了声明字段或表达式的取值(唯一值,无重复),其完整形式为 set(max_rows),其中 max_rows 是一个阈值,表示在一个 index_granularity 内索引最多记录的数据行数。如果 max_rows = 0,则表示无限制。
INDEX b (length(ID) * 8) TYPE set(100) GRANULARITY 5
上述实例中 set 索引会记录数据中 ID 的长度 * 8 后的取值,其中 index_granularity 内最多记录 100 条。
3)ngrambf_v1:ngrambf_v1 索引记录的是数据短语的布隆表过滤器,只支持 String 和 FixedString 数据类型。ngrambf_v1 只能够提升 in、notIn、like、equals 和 notEquals 查询的性能,其完整形式为:
ngrambf_v1(n, size_of_bloom_filter_in_bytes, number_of_hash_functions, random_seed)
这些参数是一个布隆过滤器的标准输入,如果你接触布隆过滤器,应该对此十分熟悉,它们的具体含义如下:
n:token 长度,依据 n 的长度将数据切割为 token 短语
size_of_bloom_filter_in_bytes:布隆过滤器的大小
number_of_hash_functions:布隆过滤器中使用 Hash 函数的个数
random_seed:Hash 函数的随机种子
例如在下面的栗子中,ngrambf_v1 索引会依照 3 的粒度将数据切割成短语 token,token 会经过 2 个 Hash 函数映射之后再被写入,布隆过滤器大小为 256 字节。
INDEX c (ID, Code) TYPE ngrambf_v1(3, 256, 2, 0) GRANULARITY 5
4)tokenbf_v1:tokenbf_v1 索引是 ngrambf_v1 的变种,同样也是一种布隆过滤器索引,但 tokenbf_v1 除了短语 token 的处理方法外,其它与 ngrambf_v1 是完全一样的。tokenbf_v1 会自动按照非字符的、数字的字符串分割 token,具体用法如下所示:
INDEX d ID TYPE tokenbf_v1(256, 2, 0) GRANULARITY 5
6 数据存储
此前已经多次提过,在MergeTree中数据是按列存储的,但具体细节到底如何我们还不清楚,那么下面就来解释一下。因为数据存储就好比一本书中的文字,在排版时不可能直接密密麻麻地把文字堆满,这样会导致难以阅读,正确的做法是将文字按照段落精心组织使其错落有致。数据存储也是同样的到底,数据也需要精心组织之后也存储到磁盘。
6.1 数据按列存储
在MergeTree中数据按列存储,在老版本中每个列也是独立存储的,也就是每个列字段都拥有一个与之对应的.bin 文件;但是在新版本中这些列字段对应的.bin 文件合并在一起了,只有一个data.bin。正是data.bin文件,最终承载着物理存储。
那么按列存储有什么好处呢?首先可以更好的进行数据压缩,因为相同类型的数据放在一起,对压缩更加友好;其实是能够最小化数据扫描的范围。
而对应到存储的具体实现方面,MergeTree 也并不是一股脑地将数据直接写入 data.bin 文件,而是经过了一番精心设计:首先数据是经过压缩的,目前支持LZ4、ZSTD、Multiple 和 Delta几种算法,默认使用LZ4算法;其次,数据会实现按照ORDER BY的声明排序;最后数据以压缩数据块的形式被组织并写入data.bin文件。
压缩数据块就好比一本书的文件段落,是组织文字的基本单元,这个概念非常重要,需要深入说明一下。
6.2 压缩数据块
一个压缩数据块由头信息和压缩数据两部分组成,头信息固定使用 9 位字节表示,具体由 1 个 UInt8(1 字节)和 2 个 UInt32(4 字节)组成,分别代表使用的压缩算法类型、压缩后的数据大小、压缩前的数据大小。所以虽然存储的是压缩后的数据,但是在头信息中将压缩前的数据大小也记录了下来。
我们先创建一张表,然后写入一些数据测试一下。
create table people
(
ID String,
Name String,
Age UInt8,
Place String
)
ENGINE = MergeTree
PARTITION BY Age
ORDER BY Age
6.2.1 模拟数据
然后用 Python 写入写入 10 万条数据:faker是一个生成伪造数据的Python第三方库,可以伪造城市,姓名,等等,而且支持中文。
# -*- coding: UTF-8 -*-
from faker import Faker
from clickhouse_driver import Client
client = Client(host="192.168.1.134", port=9000, user="default", password="bigdata")
f = Faker(locale="zh_CN") # 生成 10 万条测试数据,Age 均为 26
data = [str((f"{i}", f.name(), 26, f.address())) for i in range(100000)]
sql = f"INSERT INTO people VALUES {', '.join(data)}"
client.execute(sql)
显然会创建一个分区,根据我们之前介绍的规则,分区对应的分区目录为 26_1_1_0。但是注意,这里要使用 1 个 INSERT 语句,否则的话数据会分多批导入,这样的就会创建多个分区目录:26_1_1_0、26_2_2_0、26_3_3_0,…。而我们要的是合并后的结果,虽然属于相同分区的分区目录之后会自动合并,但是需要等一段时间,因此这里我们就一批次直接导入。
6.2.2 查看数据大小
然后我们可以使用 clickhouse-compressor 查看数据大小:
# clickhouse-compressor --stat < /var/lib/clickhouse/data/default/people/26_1_1_0/data.bin
39850 32809
65918 44730
8192 52
373938 185683
47344 33090
65861 44330
8192 52
373623 185541
49152 33336
66149 44674
8192 52
372516 185623
49152 33398
66236 44808
8192 52
374085 185714
49152 33324
66026 45022
8192 52
373953 185719
49152 33244
66044 44904
8192 52
373629 185942
49152 33298
66080 44833
8192 52
373002 185786
49152 33450
65867 44494
8192 52
372372 185417
49152 33366
66068 44489
8192 52
373911 185632
49152 33322
65936 44655
8192 52
373797 185622
49152 33267
65810 44562
8192 52
373539 185757
59328 40154
79527 53924
9888 58
450819 223537
其中每一行代表一个数据压缩块的头信息,分别表示该压缩块中 “压缩前的数据大小” 和 “压缩后的数据大小”,并且我们看到总共有 4 个压缩数据块。
为什么有 4 个,原因是我们只有 4 个列,所以 data.bin 里面存储的就是对 4 个列压缩之后的结果,这是显而易见的。像第一列就是 ID,由于我们的 ID 是顺序自增的,几乎没有什么重复,所以压缩之后和压缩之前的的大小差别不大;但是后面几列的数据压缩之后就小很多了,尤其是第三行 Age 字段,因为每个值都是一个 UInt8,1 万条数据所以占 10000 个字节,但由于所有值都是 26,数据全部一样,而数据越相似压缩比越高,因此压缩之后变成了 59 个字节。至于压缩背后的算法我们这里不细究了, 只需要知道数据之间越相似、或者说重复率越高,压缩之后的数据就越小。
但是注意:我们这里的数据量比较少,每一列数据的大小不是很大,因此每一列只用一个压缩数据块即可存储。如果数据量再多一些,一个压缩数据块存储不下,那么就会对应多个压缩数据块。
Column1 压缩数据块0
Column2 压缩数据块0
Column3 压缩数据块0
......
ColumnN 压缩数据块0
Column1 压缩数据块1
Column2 压缩数据块1
Column3 压缩数据块1
......
ColumnN 压缩数据块1

其中每一行数据都代表者一个压缩数据块的头信息,其分别表示该压缩块中未压缩数据和压缩数据的大小,注意:打印信息和物理存储的顺序刚好相反。
但是我们需要注意,之前我们说在早期的 ClickHouse 中每一列数据各自对应一个 .bin 文件,但是在新版本的时候合并在一起了,这是没错的,但前提是数据量不大。如果数据量大到一定程度,那么每一列的数据就会分开存储了,也就是各自对应一个 .bin 文件和一个 .mrk 文件,和 data.bin、data.mrk 的作用是完全等价的, 只不过一个是各列分开存储、一个是所有列合并在一起存储。
我们再执行一次上面的 Python 代码。
7 数据标记文件(.mrk)
如果把 MergeTree 比作一本书,primary.idx(一级索引)就类似书的一级章节目录,但是这个目录具体对应书中( .bin 文件)的哪一页呢?