背景
如今,分布式架构已经成为事实上的架构模范,这使得通过 REST API 和 消息中间件来降低微服务之间的耦合变得必然。就消息中间件而言,Apache Kafka 已经普遍存在于如今的分布式系统中。Apache Kafka 是一个强大的、分布式的、备份的消息服务平台,它主要负责以可扩展性、健壮性和容错性的方式来存储和共享数据。站在应用的角度,应用开发者主要利用 Kafka 生产者和 Kafka 消费者去发布和消费消息。因此生产者和消费者对于优化基于 Kafka 的交互都很重要。
这篇文章主要聚焦于以一种易于理解的的方式去提高 Kafka 的生成者和消费者的性能。性能工程作为一个整体有两个正交的维度:
- 吞吐量
- 延迟
Kafka 端到端的延迟
Kafka 端到端的延迟是从应用通过 KafkaProducer.send() 发送一个消息开始到应用通过 KafkaConsumer.poll() 消费发布的消息之间的耗时。下面的图清晰的展示了 Kafka 消息经历的各种阶段:
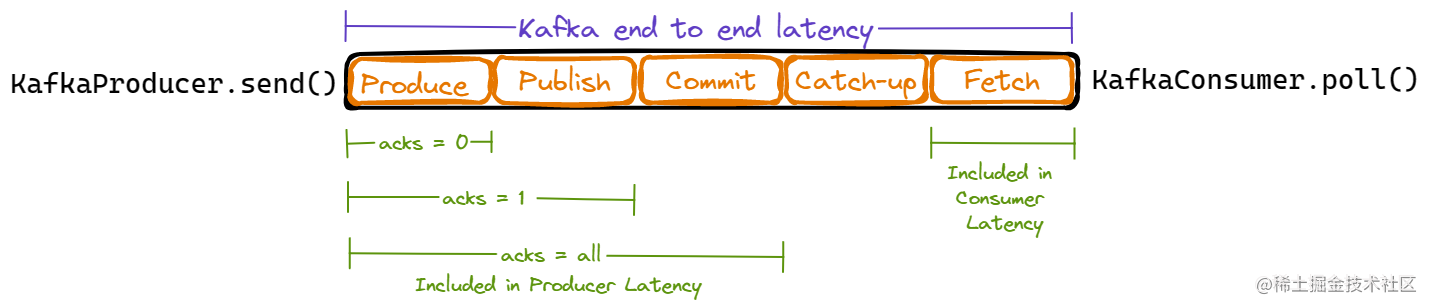
- Produce Time:应用通过 KafkaProducer.send() 发送一个消息到这个消息被发送到主题分区的 leader 之间花费的时间。
- Publish Time:Kafka 内部生产者发布批量消息到 Broker 和发布的消息添加到 leader 的 replica log 两个步骤之间的耗时。
- Commit Time:Kafak 复制消息到所有的 in-sync replicas(ISR) 所花费的时间
- Catch-up Time:一旦消息被提交,如果消费者的偏移量落后于提交的消息 N 条消息,那么,Catch-up Time 就是消费者消费掉这 N 条消息所消耗的时间。
- Fetch Time:Kafka 消费者从 leader broker 获取消息花费的时间。
优化方法
一般来说,通过 Kafka 的消息一般会涉及以下参与者:
- 生产者
- 主题
- 消费者
从系统优化的角度来说,我们会专注于生产者和消费者。
优化 Kafka 的生产者
除了 Kafka 消息经历的上述阶段,从优化的角度来看,理解 Kafka Producer 的交付时间分解也同样重要。

核心配置
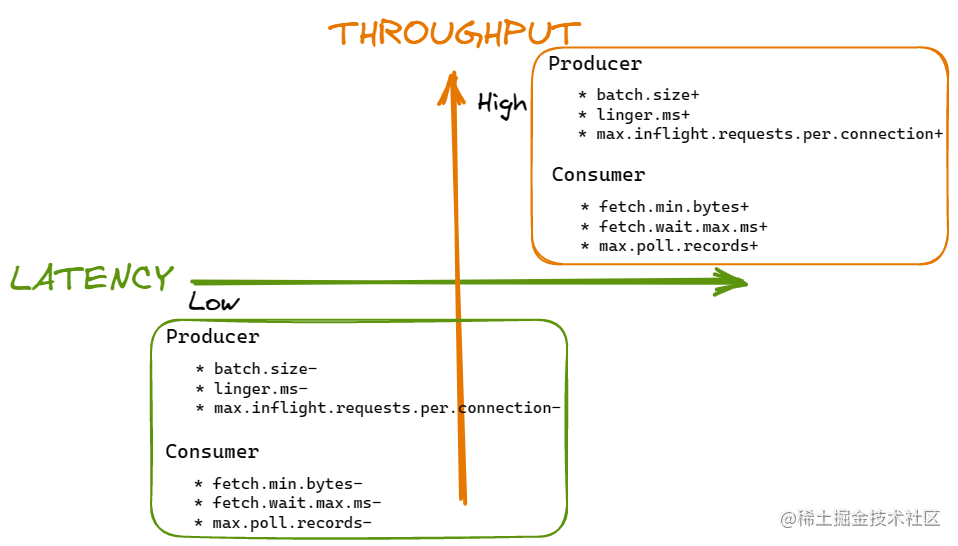
- batch.size:控制生产者每一批次消息使用的内存大小(单位为 byte),增加 batch size 可能会通过消耗更多的内存来提高吞吐量。
- linger.ms:定义了生产者直到一个批量的消息已经凑齐并可以发送到 Broker 等待的时间(单位为毫秒)。增加这个值可以减少网络 IO 并保证更高的吞吐量。然而,更大的值会增加生产者发送消息的延迟。
- max.inflight.requests.per.connection:控制了当生产者没有收到响应时,生产者可以发送的批量消息的数量。更高的值可以提交吞吐量,但是会消耗更高的内存。
优化 Kafka 的消费者
- fetch.min.bytes:定义了消费者打算从 Broker 获取的最小字节数。更小的值会减少延迟,但是会降低吞吐量。
- fetch.wait.max.ms:定义了 Broker 在响应收到的来自消费者的 Fetch 请求之前等待的最大时间。更大的值会以增加延迟为代价来减少网络 IO 和提交吞吐量。
- max.poll.records:控制了消费者单次请求获取到的最大记录数。减少该值会降低延迟,降低吞吐量。
Kafka-生产者消费者优化坐标
从图像绘制上,我们可以在上面的理解上整理并准备 Kafka 生产者消费者轴,以轻松记住关键配置及其对应用性能的影响。
结论
本文,我们通过一个消息会经历的各个阶段解释了什么是 Kafka 中的端到端延迟。现在我们清晰的理解了哪些阶段会影响 Kafka 的生产者和消费者的性能。文中也介绍了一些可以帮助生产者和消费者降低延迟和提交吞吐量的核心配置。通过理解这些配置的影响,可以说,这是在高吞吐量和低延迟之间的一种权衡。通过了解应用的性质(即吞吐量 /延迟敏感)和负载,可以通过实验找到适当的平衡。
PS: Apache Kafka 的默认配置更加倾向于低延迟而非高吞吐