文章目录
- 多分类问题
- 损失函数
- 课上代码
- transforms的使用方法
- view()函数
- dim维度的理解
- 为什么要使用item()
多分类问题
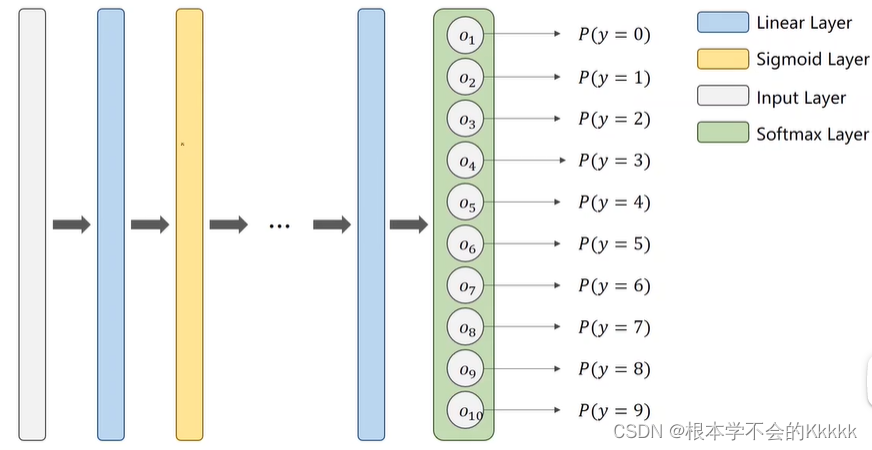
把原来只有一个输出,加到10个 每个输出对应一个数字,这样可以得到每个数字对应的概率值,这里每个输出做的都是sigmoid二分类(即是非1即0),所以只要有一项输出为1时,其他非1的输出都规定为0,以此来判断。
但是这种情况下出现一个问题,每个sigmoid的输出都是独立的,当一个类别的输出概率较高时,其他类别的概率仍然会高,也就是说在输出了1的概率后,2输出的概率不会因为1的出现而受影响,这点说明了所有输出的概率值之和大于1。
&emsp’所以我们希望输出的概括要满足分布性质的要求:

如何来实现上面的两个要求呢,这就用到了Softmax:
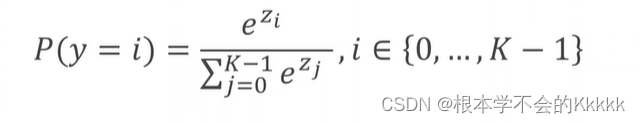
根据公式可以看出来:softmax层接受上一层的输出,分母为上一层每个神经元输出的指数再求和,计算每一个概率分子则为该类的输出指数;指数确保了P(y=i)≥0的条件,该公式能够满足概率和为1
损失函数
使用Cross Entropy Loss Function(交叉熵损失函数):

课上代码
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
batch_size = 64
transform = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
]
)
train_dataset = datasets.MNIST('./dataset/mnist/', train=True, download=True, transform=transform)
train_loader = DataLoader (train_dataset, shuffle = True, batch_size = batch_size)
test_dataset = datasets.MNIST ('./dataset/mnist/', train=True, download=True, transform=transform)
test_loader = DataLoader (test_dataset, shuffle = False, batch_size = batch_size)
class Net (torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.l1 = torch.nn.Linear (784, 512)
self.l2 = torch.nn.Linear (512, 256)
self.l3 = torch.nn.Linear (256, 128)
self.l4 = torch.nn.Linear (128, 64)
self.l5 = torch.nn.Linear (64, 10)
def forward (self, x):
x = x.view (-1, 784)
x = F.relu (self.l1(x))
x = F.relu (self.l2(x))
x = F.relu (self.l3(x))
x = F.relu (self.l4(x))
return self.l5(x)
model = Net()
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
def train (epoch):
running_loss = 0.0
for batch_idx, data in enumerate (train_loader,0):
inputs, target = data
optimizer.zero_grad()
outputs = model (inputs)
loss = criterion (outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch+1, batch_idx+1, running_loss/300))
running_loss = 0.0
def test ():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
outputs = model (images)
_,predicted = torch.max (outputs.data, dim = 1)
total += labels.size (0)
correct += (predicted == labels).sum().item()
print('accuracy on test set: %d %% ' % (100*correct/total))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()
transforms的使用方法
采用transforms.Compose(),将一系列的transforms有序组合,实现时按照这些方法依次对图像操作。
train_transform = transforms.Compose([
transforms.Resize((32, 32)), # 缩放
transforms.RandomCrop(32, padding=4), # 随机裁剪
transforms.ToTensor(), # 图片转张量,同时归一化0-255 ---》 0-1
transforms.Normalize(norm_mean, norm_std), # 标准化均值为0标准差为1
])
还有很多其他的transforms处理方法,总结有四大类:
- 裁剪-Crop
中心裁剪:transforms.CenterCrop
随机裁剪:transforms.RandomCrop
随机长宽比裁剪:transforms.RandomResizedCrop
上下左右中心裁剪:transforms.FiveCrop
上下左右中心裁剪后翻转,transforms.TenCrop
- 翻转和旋转——Flip and Rotation
依概率p水平翻转:transforms.RandomHorizontalFlip(p=0.5)
依概率p垂直翻转:transforms.RandomVerticalFlip(p=0.5)
随机旋转:transforms.RandomRotation
- 图像变换
resize:transforms.Resize
标准化:transforms.Normalize
转为tensor,并归一化至[0-1]:transforms.ToTensor
填充:transforms.Pad
修改亮度、对比度和饱和度:transforms.ColorJitter
转灰度图:transforms.Grayscale
线性变换:transforms.LinearTransformation()
仿射变换:transforms.RandomAffine
依概率p转为灰度图:transforms.RandomGrayscale
将数据转换为PILImage:transforms.ToPILImage
transforms.Lambda:Apply a user-defined lambda as a transform.
- 对transforms操作,使数据增强更灵活
transforms.RandomChoice(transforms), 从给定的一系列transforms中选一个进行操作
transforms.RandomApply(transforms, p=0.5),给一个transform加上概率,依概率进行操作
transforms.RandomOrder,将transforms中的操作随机打乱
view()函数
view()的作用相当于numpy中的reshape,重新定义矩阵的形状。
1.普通用法
#其中v1为1*16大小的张量,包含16个元素。v2为4*4大小的张量,同样包含16个元素。
import torch
v1 = torch.range(1, 16)
v2 = v1.view(-1, 4)
#-1的意思是这个维度的数量是不确定的,对于确定的第二维度4,整个元素一共有16个,因此最后的v4是4*4大小的张量
#如果4换成8的话,第一维度会调整为2
v3 = torch.range(1, 16)
v4 = v1.view(-1, 4)
dim维度的理解
维度为0时,即tensor(张量)为标量。
维度为1时,即tensor(张量)为一维向量。
维度为2时,即tensor(张量)为二维矩阵。
维度为3时,即tensor(张量)为三维空间矩阵。
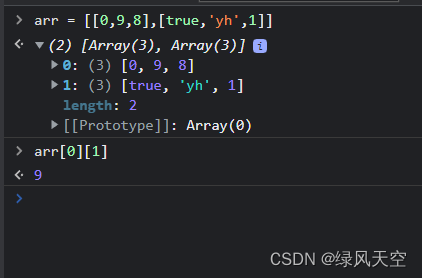
pytorch中的tensor维度可以通过第一个数前面的中括号数量来判断,有几个中括号维度就是多少。拿到一个维度很高的向量,将最外层的中括号去掉,数最外层逗号的个数,逗号个数加一就是最高维度的维数,如此循环,直到全部解析完毕。
dim的使用:只有dim指定的维度是可变的,其他都是固定不变的
- torch.argmax(): 得到最大值的序号索引
a = torch.rand((3,4))
print(a)
b = torch.argmax(a, dim=1) ##指定列,也就是行不变,列之间的比较
print(b)
>>tensor([[0.8338, 0.6953, 0.7558, 0.5803],
[0.2105, 0.7638, 0.0912, 0.3341],
[0.5585, 0.8019, 0.6590, 0.2268]])
>>tensor([0, 1, 1])
说明:dim=1,指定列,也就是行不变,列之间的比较,所以原来的a有三行,最后argmax()出来的应该也是三个值,第一行的时候,同一列之间比较,最大值是0.8338,索引是0,同理,第二行,最大值的索引是1……
2. sum(): 求和
a = t.arange(0,6).view(2,3)
a
>>tensor([[0, 1, 2],
[3, 4, 5]])
a.sum()
a.sum(dim=0) #指定行,行是可变的,列是不变的
a.sum(dim=1)
>>tensor(15.)
>>tensor([3., 5., 7.])
>>tensor([ 3., 12.])
说明:dim=0,指定行,行是可变的,列是不变,所以就是同一列中,每一个行的比较,所以a.sum(dim = 0),第一列的和就是3,第二列的和就是5,第三列的和就是7.
同理,a.sum(dim=1),指定列,列是可变的,行是不变的,所以就是同一列之间的比较或者操作,所以第一行的求和是3,第二行的求和是12
为什么要使用item()
item()的作用是取出单元素张量的元素值并返回该值,保持该元素类型不变。在训练时统计loss变化时,直接将loss加起来,系统会认为这里也是计算图的一部分,也就是说网络会一直延伸变大,那么消耗的显存也就越来越大,loss.item()能够防止tensor无线叠加导致的显存爆炸