爬虫框架的介绍
- Scrapy框架
- Crawley框架
- Portia框架
- Newspaper框架
- Python-goose框架
随着网络爬虫的应用越来越多,一些爬虫框架逐渐涌现,这些框架将爬虫的一些常用功能和业务逻辑进行封装。这些框架的基础上,根据自己的需求添加少量的代码,就可以实现自己想的的一个爬虫。使用Python语言开发的爬虫框架有很多,但是实现方式和原理大同小异,用户只需要深入掌握一种框架,对其他框架做了简单了解即可,常见的Python框架主要有以下几种:Scrapy、Crawley、Portia、Newspaper、和Python-goose。
Scrapy框架
Scrapy是用纯Python实现的一个开源的爬虫框架,是为了高效地爬取网站数据、提取结构性数据而编写地应用框架,用途非常广泛,可用于爬虫开发、数据挖掘、数据检测、自动化测试领域。
Scrapy使用了Twisted异步网络框架来处理网络通信 ,该网络框架可以加快下载速度,并且包含了各种中间件接口,可以灵活地完成各种需求。
Scrapy框架下载安装

Scrapy功能很强大,它支持自定义Item和pipline数据管道;支持在Spider中指定domain(网页域范围)以及相应的Rule(爬取规则);支持XPath对DOM的解析等。而且Scrapy还有自己的shell,可以方便地调试爬虫项目和查看爬虫运行结果。
Crawley框架
Crawley是用Python开发出的、基于非阻塞通信(NIO)的爬虫框架,他能高速爬取对应网站的内容,支持关系型和非关系型数据库,支持输出Json、XML和CSV等各种格式。
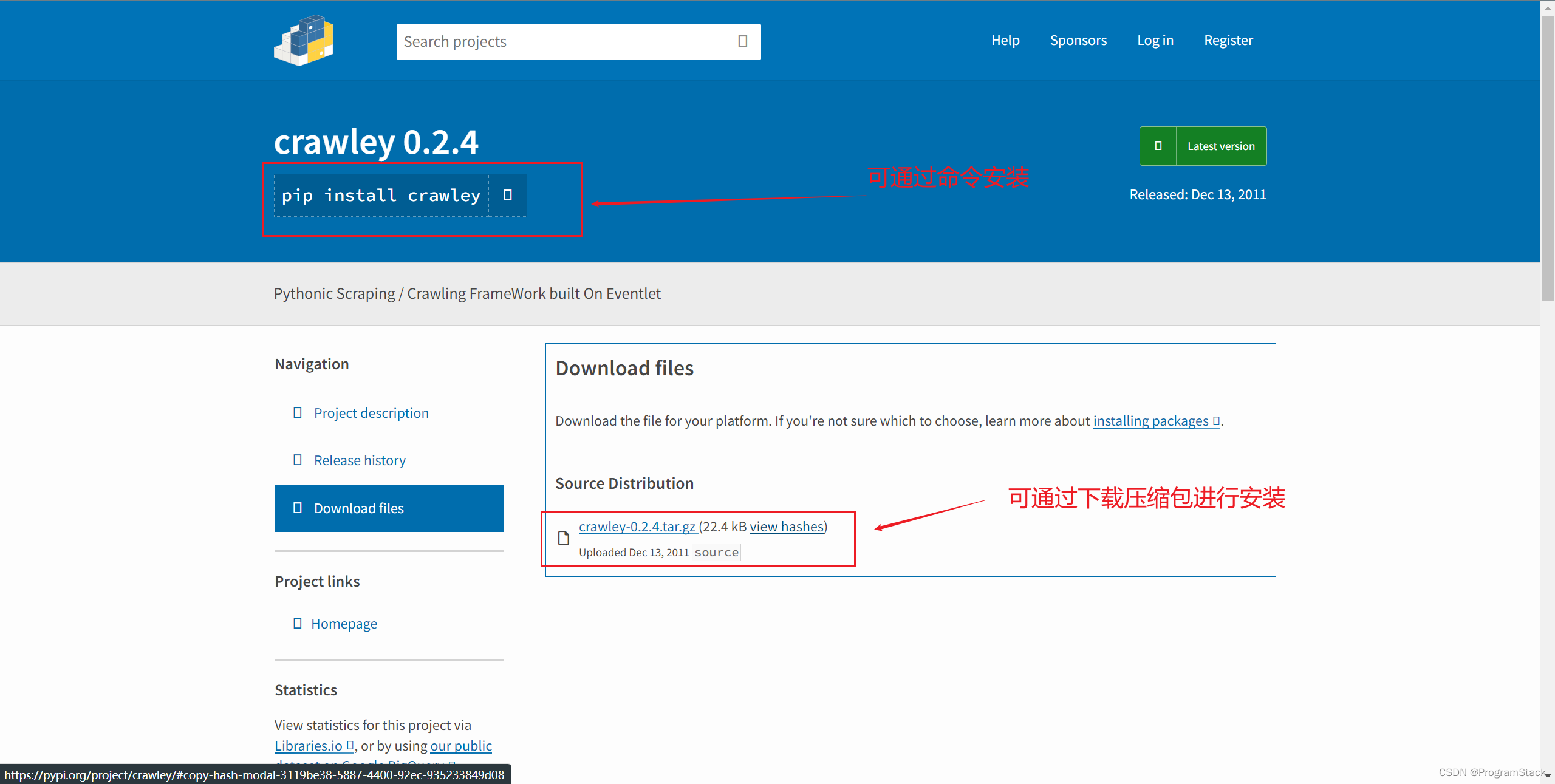
Crawley框架下载安装
Portia框架
Portia框架是scrapyhub开源的一款可视化的爬虫规则编写工具,提供可视化的Web页面,用户只需要点击标注页面需要抽取的数据,不需要任何编程知识即可完成规则的开发(但是动态网页需要自己下载JS解析器)。
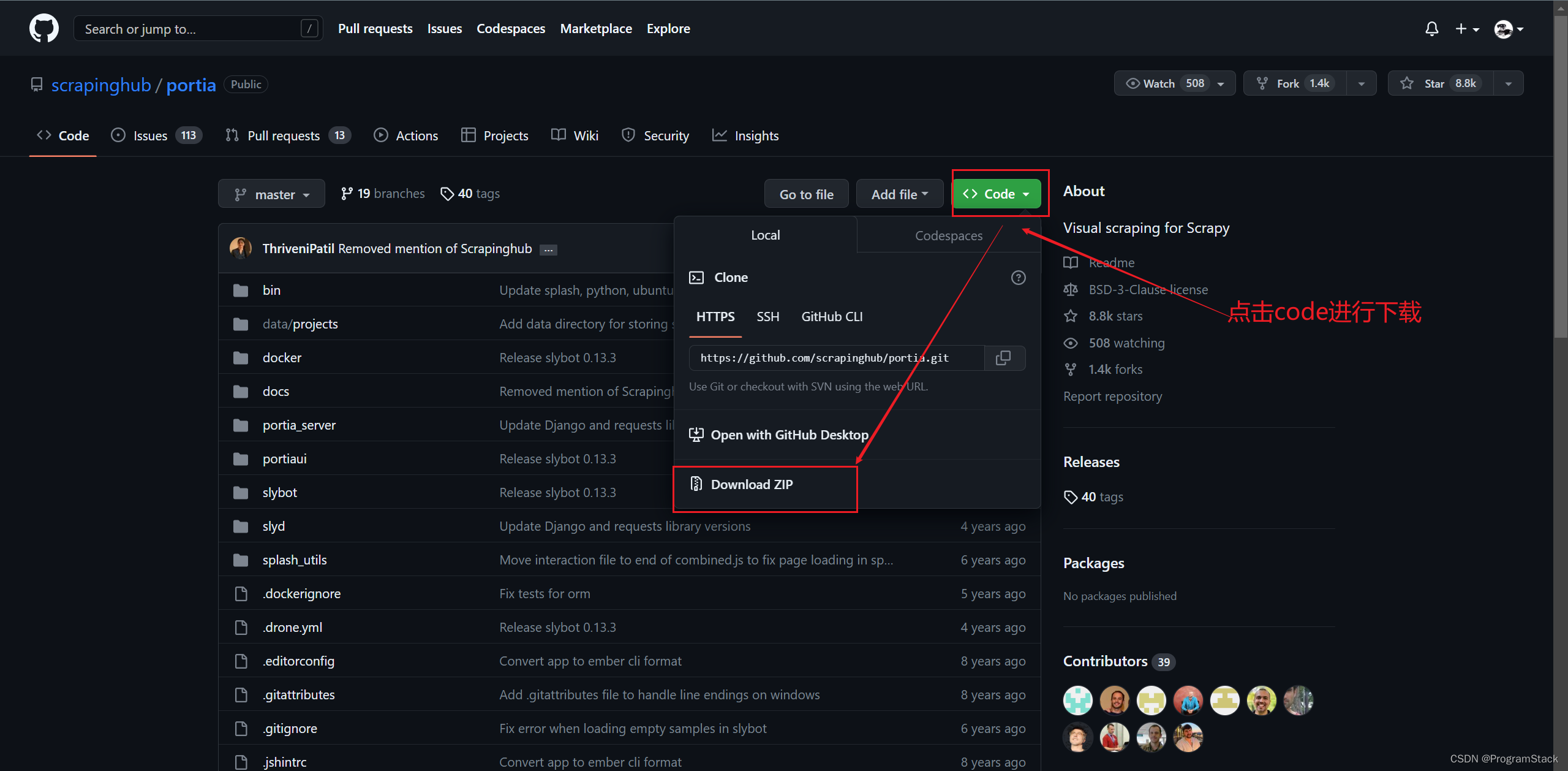
Portia框架下载安装
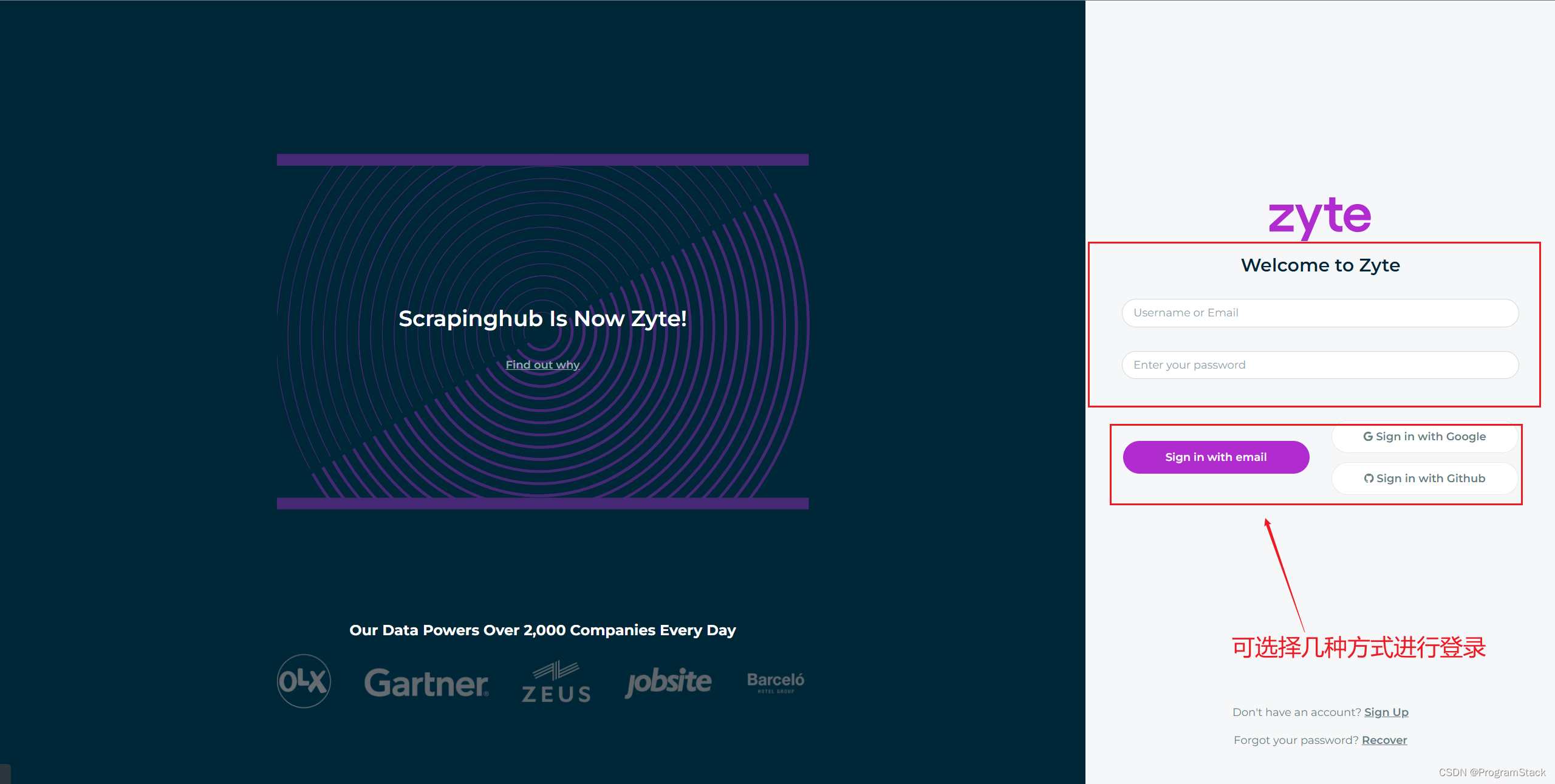
除此之外,Portia框架还提供了网页版,用户只需要住的一个账号,不需要下载框架就就可以直接进行使用。
Portia网页版下载
这里就不进行Portia的具体介绍了,因为它不需要任何编程基础就可使用,如果感兴趣可以去尝试尝试。
Newspaper框架
Newspaper框架专门用于提取新闻、文章内容和内容分析的爬虫框架,该框架有以下特点:
- 支持10多种语言
- 所有内容都是使用Unicode编码
- 使用多线程下载文章
- 能够识别新闻网站的URL
- 能够从网页中提取文本和图片,并且从文本中提取关键词、摘要和作者
Newspaper下载安装
Python-goose框架
goose本身是用Java语言编写的用于提取文章的框架,Python-goose是用Python语言对goose框架的重新实现。Python-goose的设计目的是爬取新闻和网页文章,并从中提取以下内容:
- 文章的主体
- 文章中的图片
- 文章中包含的所有YouTube/Vimeo视频
- 元描述信息
- 元标签
Python-goose框架下载安装








![洛谷P8706 [蓝桥杯 2020 省 AB1] 解码 C语言/C++](https://img-blog.csdnimg.cn/8cca9b2e4e4f4f0b94bf311c0536832a.png)