写在前面:
闲来无事,因为宿舍每次嫌登录校园网有点免费。然后想着能不能一键自动化实现。然后更麻烦了,哈哈哈。不过倒是写一次代码就可以了。
可能不是特别系统,因为资料太少了。都是案例驱动找的资料。花了3大节课才搞完了。
会用js的话,学起来倒是比较简单一点。(说起来我咋不用js代码去做,有时间去看看)
闲来无事,因为宿舍每次嫌登录校园网有点免费。然后想着能不能一键自动化实现。然后更麻烦了,哈哈哈。不过倒是写一次代码就可以了。
可能不是特别系统,因为资料太少了。都是案例驱动找的资料。花了3大节课才搞完了。
会用js的话,学起来倒是比较简单一点。(说起来我咋不用js代码去做,有时间去看看)
HtmlUnit介绍
HtmlUnit是一个“Java程序的无GUI浏览器”。 它对 HTML 文档进行建模,并提供一个 API,允许您调用页面、填写表单、单击链接等。 就像您在“普通”浏览器中所做的那样。
安装–maven依赖
<dependency>
<groupId>net.sourceforge.htmlunit</groupId>
<artifactId>htmlunit</artifactId>
<version>2.70.0</version>
</dependency>
入门案例
得到xxx页面id为xxx里面所有div内容
网页为
<?xml version="1.0" encoding="GBK"?>
<html xmlns="http://www.w3.org/1999/xhtml" style="background: url("https://api.ixiaowai.cn/mcapi/mcapi.php">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=gb2312"/>
<meta id="viewport" name="viewport" content="target-densitydpi=device-dpi,width=640px,user-scalable=1"/>
<meta name="renderer" content="webkit"/>
<meta http-equiv="X-UA-Compatible" content="IE=9; IE=8; IE=7; IE=EDGE"/>
<title>
unit
</title>
</head>
<body>
<div id="abc">
<a href="www.baidu.com">1231</a>
<div>a</div>
<div>b</div>
<div>c</div>
<div>d</div>
<div>e</div>
<div>f</div>
<div>g</div>
<div>h</div>
<div>i</div>
<div>g</div>
</div>
</body>
</html>
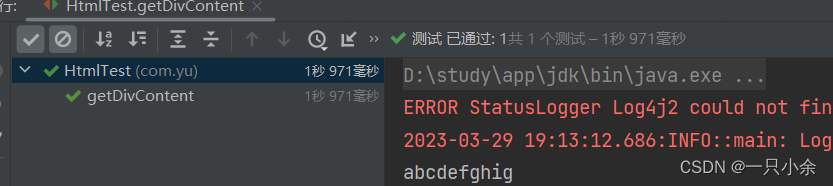
@Test
public void getDivContent() {
//获取webclient浏览器
try (WebClient webClient = new WebClient();) {
//获取对应网站的页面
HtmlPage page = webClient.getPage("http://127.0.0.1:5500/Test.html");
//根据id获取元素
HtmlElement abc = page.getHtmlElementById("abc");
//获取里面所有的div
List<HtmlElement> divs = abc.getByXPath("div");
//收集里面div所有的内容
StringBuilder sb = new StringBuilder();
for (HtmlElement div : divs) {
sb.append(div.getTextContent());
}
//断言
Assert.assertEquals(sb.toString(),"abcdefghig");
} catch (IOException e) {
throw new RuntimeException(e);
}
}
浏览器
创建
try (WebClient webClient = new WebClient()) {}
也可以指定浏览器
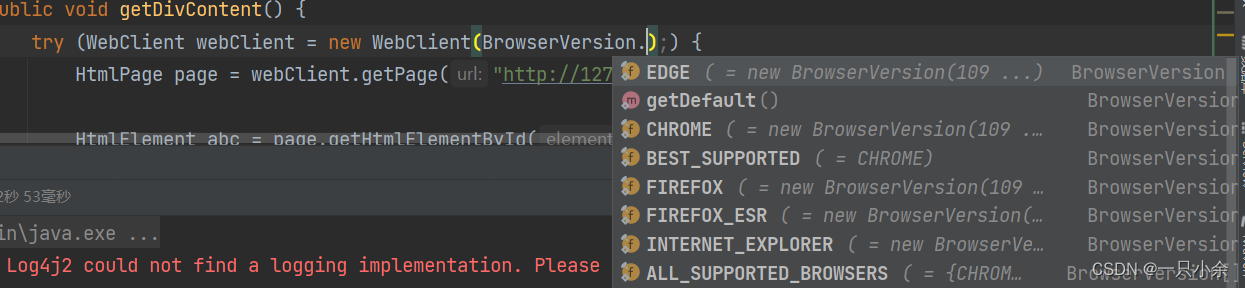
浏览器选项
// 禁用js
webClient.getOptions().setJavaScriptEnabled(false);
// 禁用css
webClient.getOptions().setCssEnabled(false);
//对未处理的js错误执行js
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
// 上面三个好像只是为了更快,减少不需要的
获取页面
HtmlPage page = webClient.getPage(url);
//url为网站的url
页面元素选择器
id选择器
这个是最准确的,但是不是所有的元素都有id。
//获取对应id的元素
<E extends HtmlElement> E page.getHtmlElementById(id)
List<DomElement> getElementsById(final String elementId)
我们选用第一个,可以得到html元素的专门的组件
如下面我们可以得到input组件和password组件,里面的封装的方法更准确。

常见的对应
| html组件 | htmlunit |
|---|---|
| a | HtmlAnchor |
| input | HtmlInput |
| button | HtmlButton |
| image | HtmlImage |
| form | HtmlForm |
| table | HtmlTable |
| label | HtmlLabel |
| option | HtmlOption |
name选择器
这个也比较准确,但一样的也不是都有name
//返回具有指定名称的元素。如果有多个元素具有此名称,那么此方法将返回第一个名称
<E extends DomElement> E getElementByName(final String name)
css选择器
xpath
需要强转。
<T> List<T> getByXPath(final String xpathExpr)
HtmlAnchor anchor = (HtmlAnchor) page.getByXPath("复制过来的xpath");
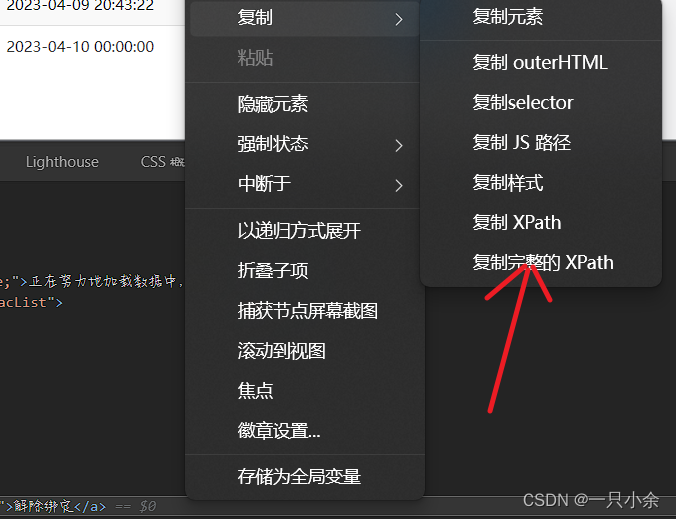
返回文档中与指定选择器组匹配的第一个元素。
<N extends DomNode> N querySelector(final String selectors)
组件操作
每个组件对应操作,如点击输入啥的。
这时候我们如果上面选择的是html对应的组件就很好操作了。
idea会有提示。
如a标签的点击。还有着封装很多的方法,如修改值setvalue,修改id等等。
动态数据加载
需要设置js为true,然后需要等待数据加载完成。
css一定要禁用,不然很难用。
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(true);
Thread.sleep(500);
调试技巧
我们可以选择到一个操作就把这个操作的页面打印出来
这样我们就可以在文件fw中去查看了

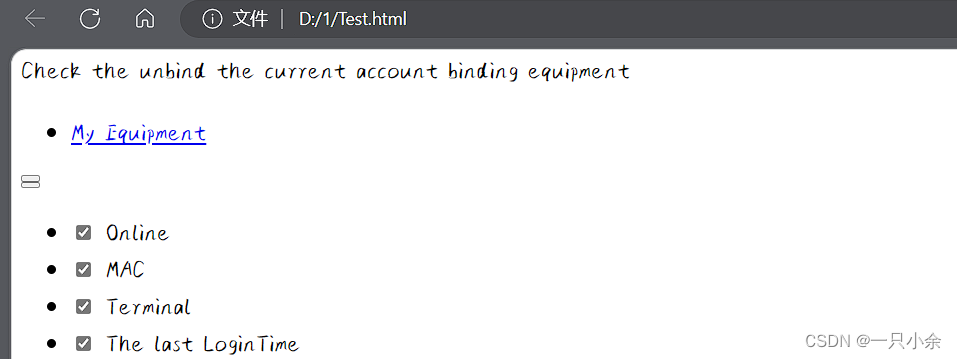
登录案例
登录页面

然后通过F12进行查看。

其有id所以我们可以直接进行id选择,然后设置值。

查看按钮的

有name,然后是button组件
click返回点击后的页面。

这样就登录成功了。
如果需要动态获取的需要等待数据加载。
如这个没有等待的。

这个有等待的,设置的大小自己调试,我这里50就可以加载出来了。





![[目标识别-论文笔记]Object Detection in Videos by Short and Long Range Object Linking](https://img-blog.csdnimg.cn/33936b1aa860497fb985afcd959cff84.png)