文章目录
- 1、对索引库的操作:创建、删除、查看
- 2、文档操作
- 3、 RestClient操作索引库
- 4、利用RestClient实现文档的CRUD
- 5、 批量导入功能
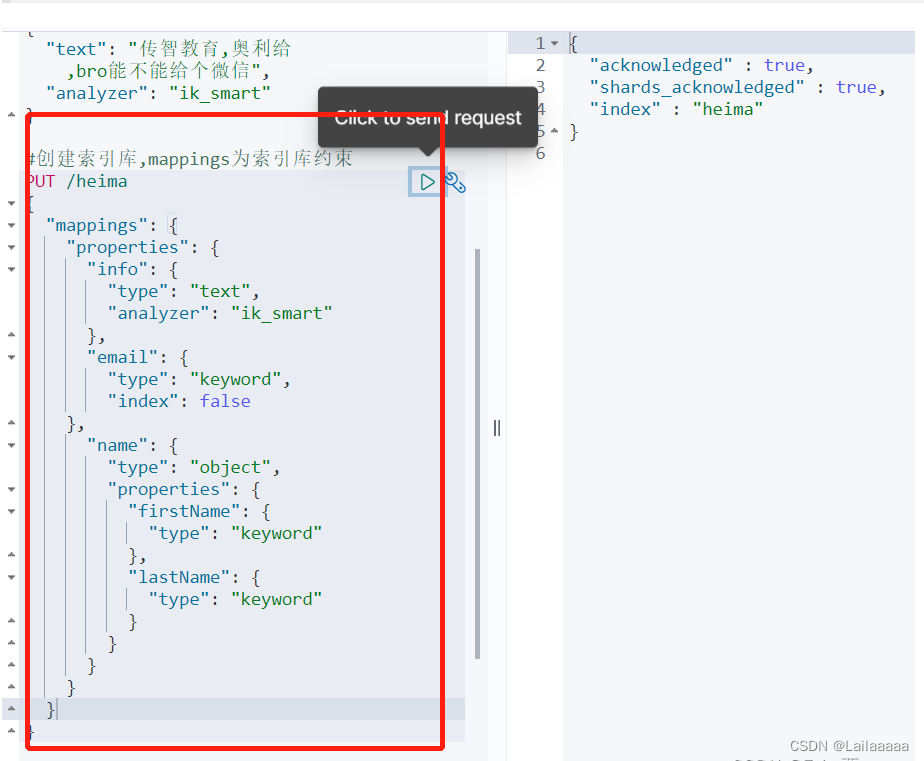
有了索引库相当于数据库database,而接下来,就是需要索引库中的类型了,也就是数据库中的表;创建表——>需要设置字段的约束;索引库也一样——>在创建索引库类型的时候,需要知道这个类型下有哪些字段(每个字段对应一些约束信息)——>这些字段以及对应的约束信息就叫:字段映射

下图右侧为json文档,左侧为约束:

mapping常见属性:
type:数据类型->记住,es中是没有数组的,但是数组中的属性是有类型的
keyword——>不分词
text——>代表要分词
index:是否索引(是否参与搜索)
true:表示字段会被索引(可以用来搜索),false:不能用来搜索;
analyzer:对text可分词文本的一个分词器
Properties:字段的子字段
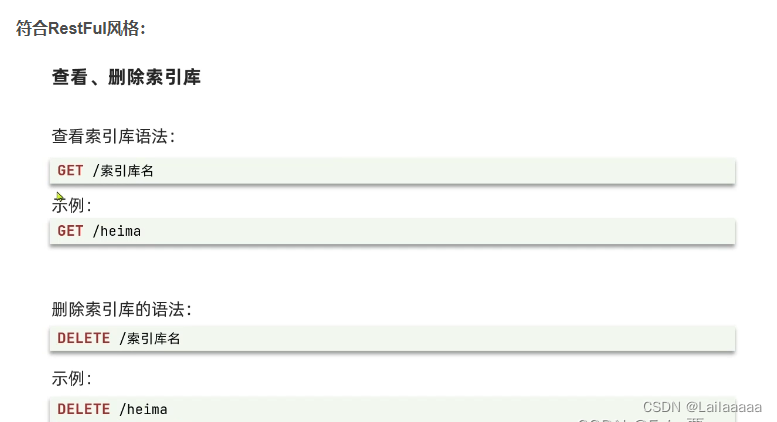
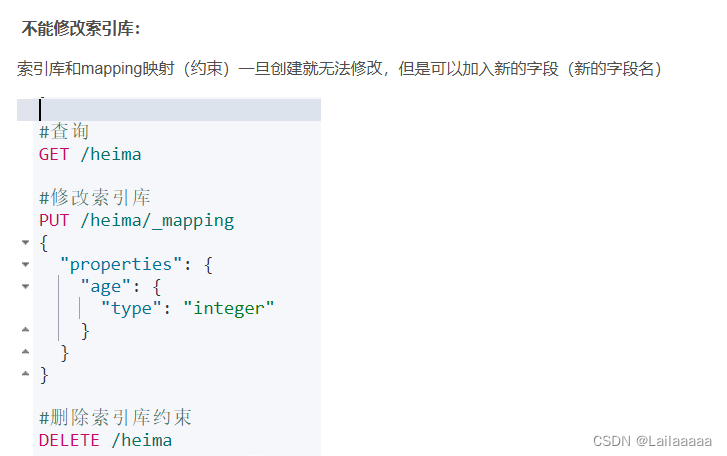
1、对索引库的操作:创建、删除、查看
2、文档操作
根据前面对索引库的操作:对里面的类型(相当于数据库中的表)中的字段映射——>进行赋值,就是文档操作
doc:相当于数据库中的表,也就是这里的类型(type)(里面包含一条条数据)
mappings:字段的数据类型、属性、是否索引、是否存储等特性
doc后面的1:就是一条数据
每次进行写操作(插入),version版本+1
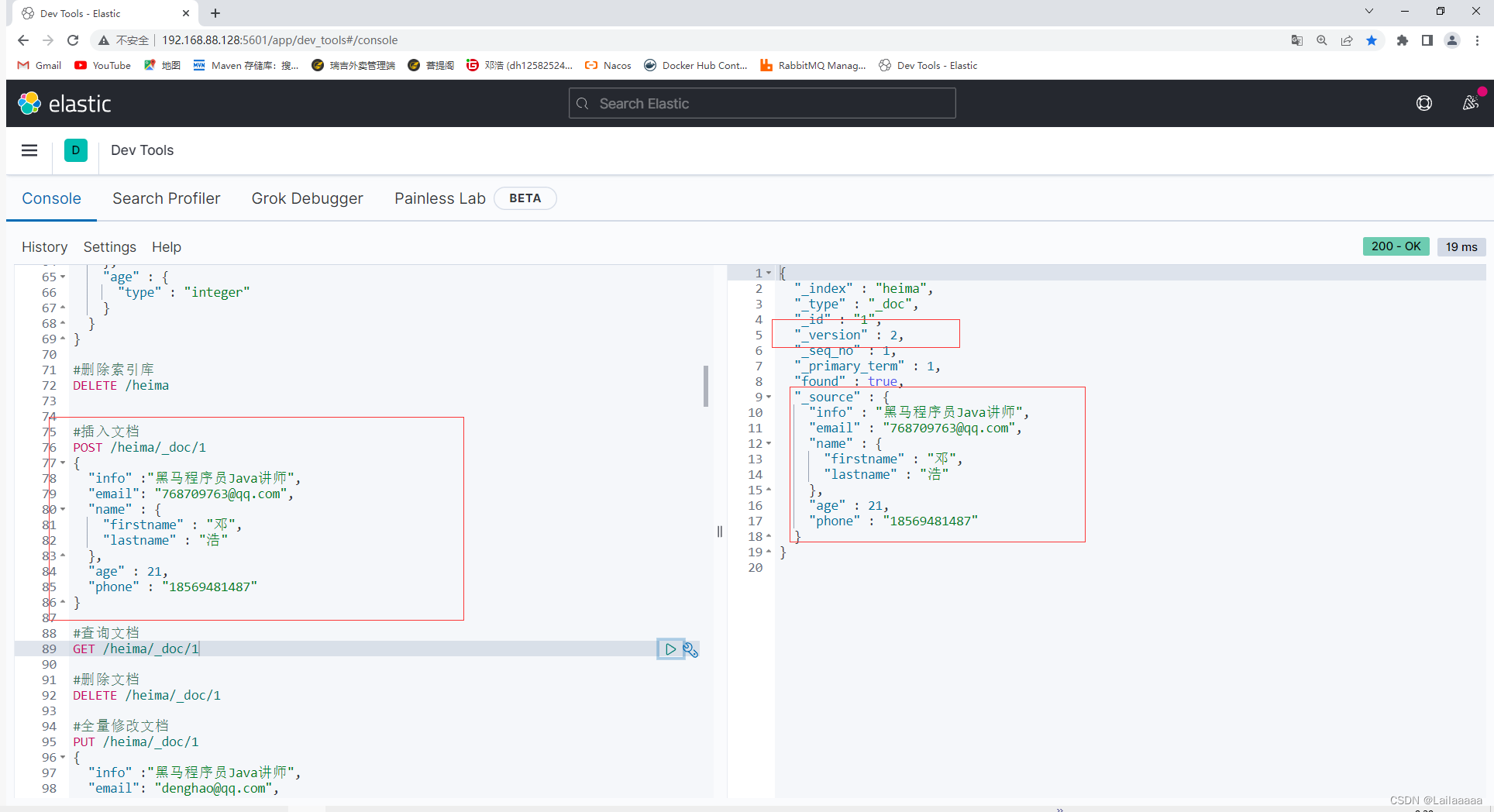

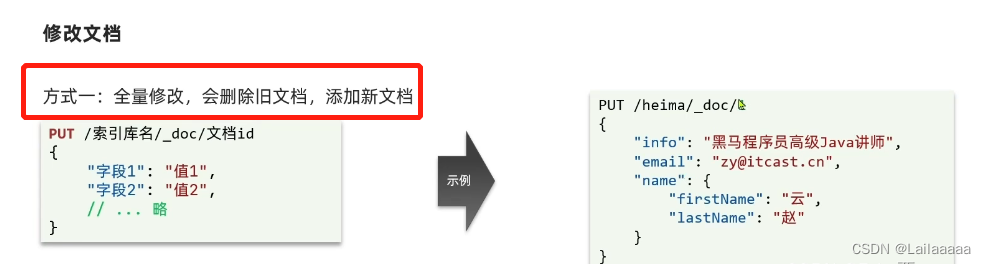
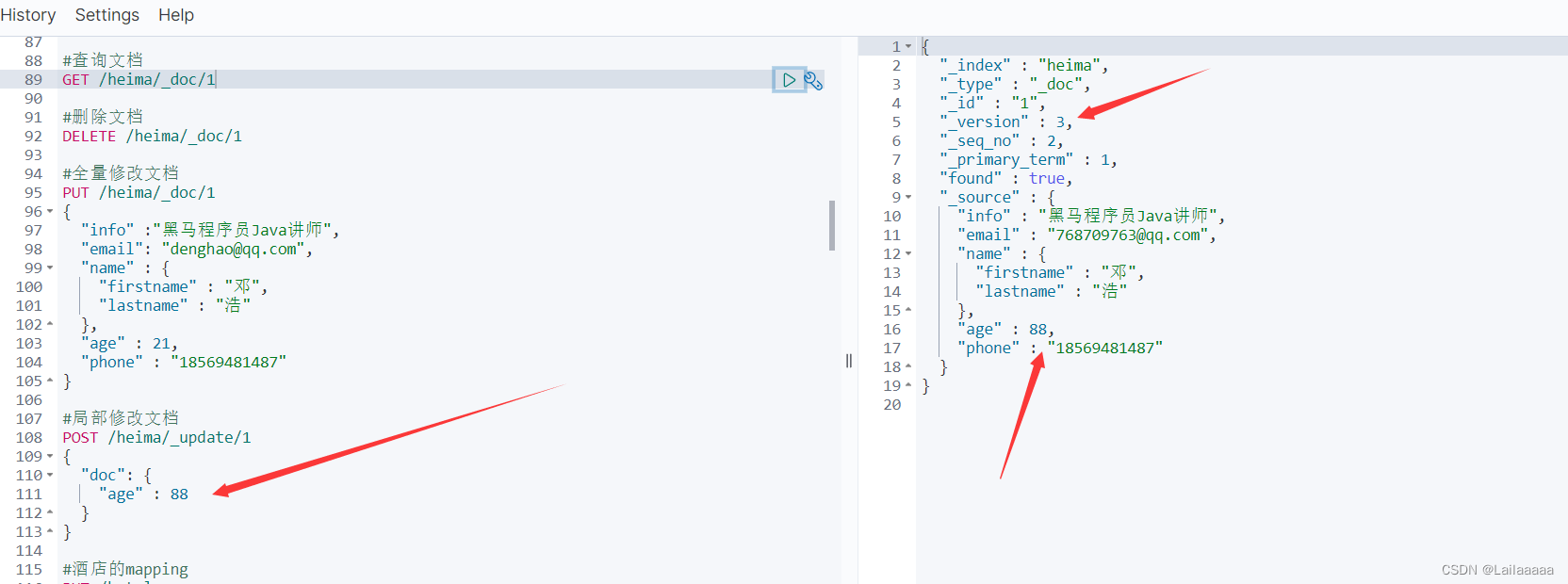

3、 RestClient操作索引库
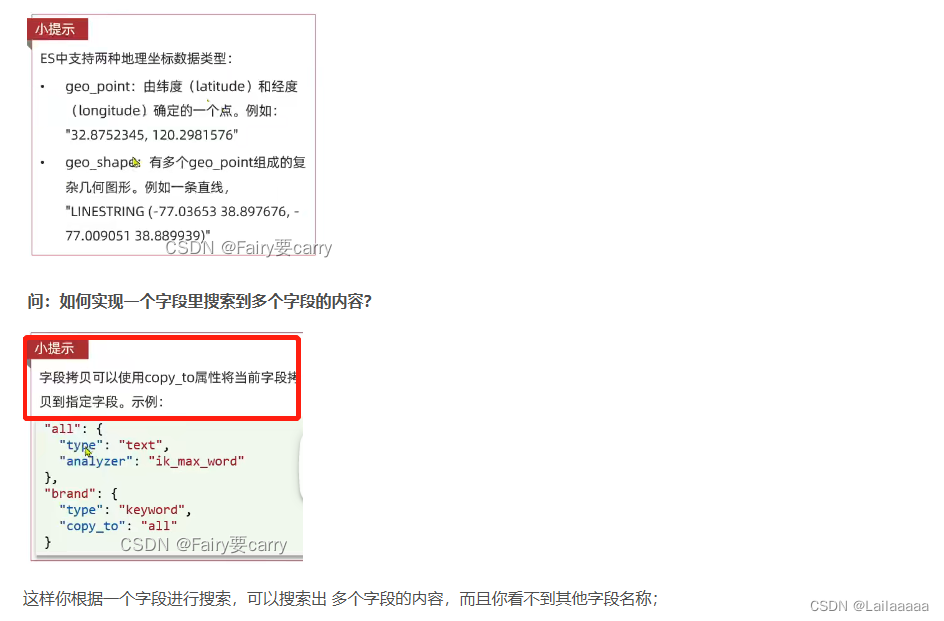
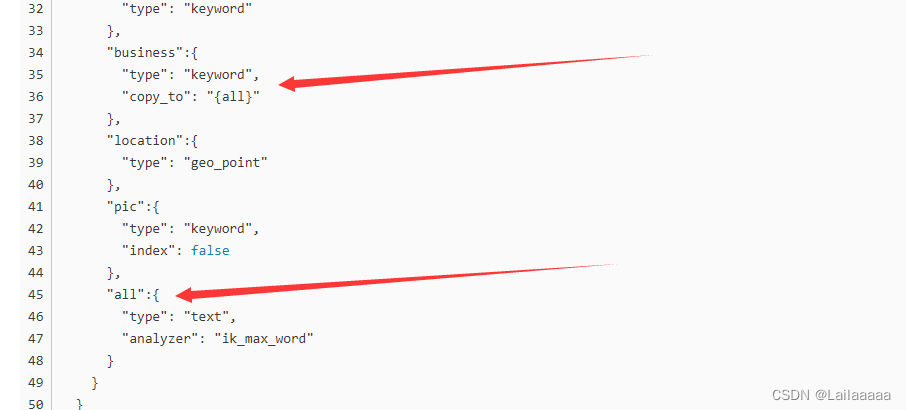
all是自己新增的字段 将其他需要搜索分词的字段全部整合到一起了
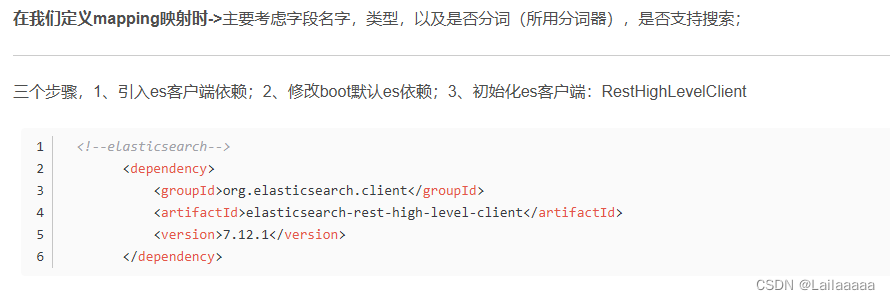
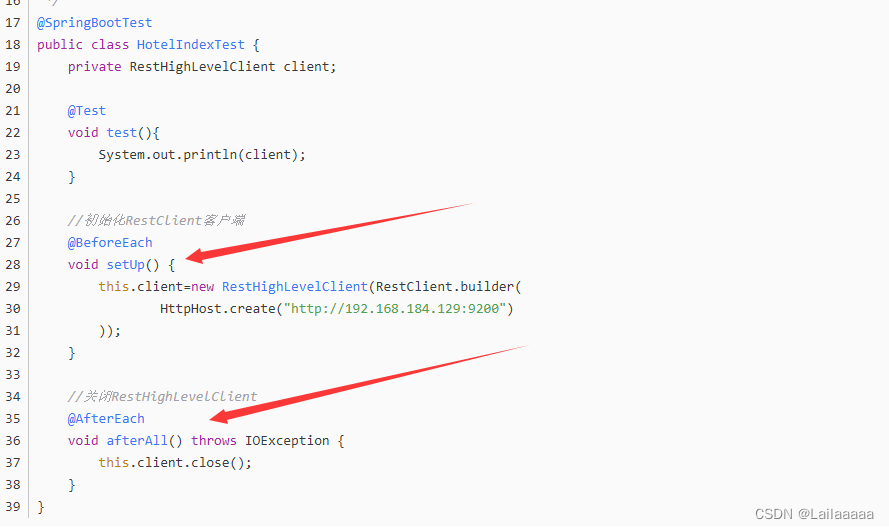


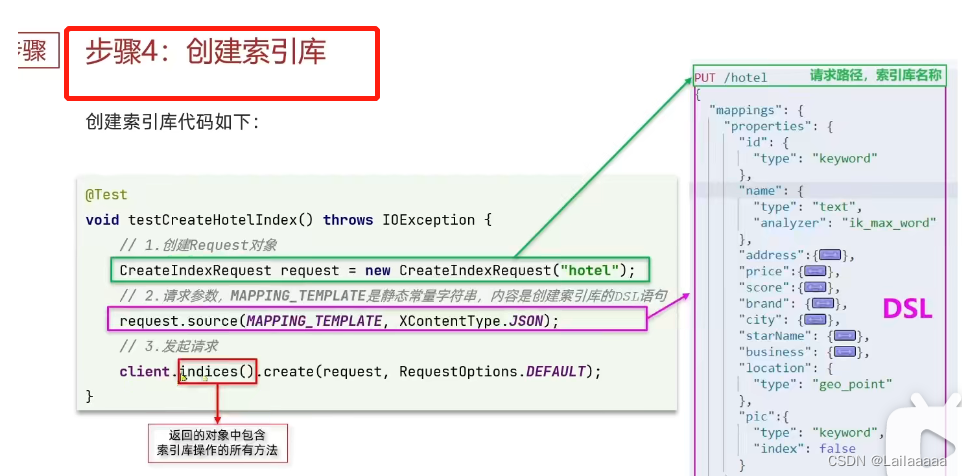
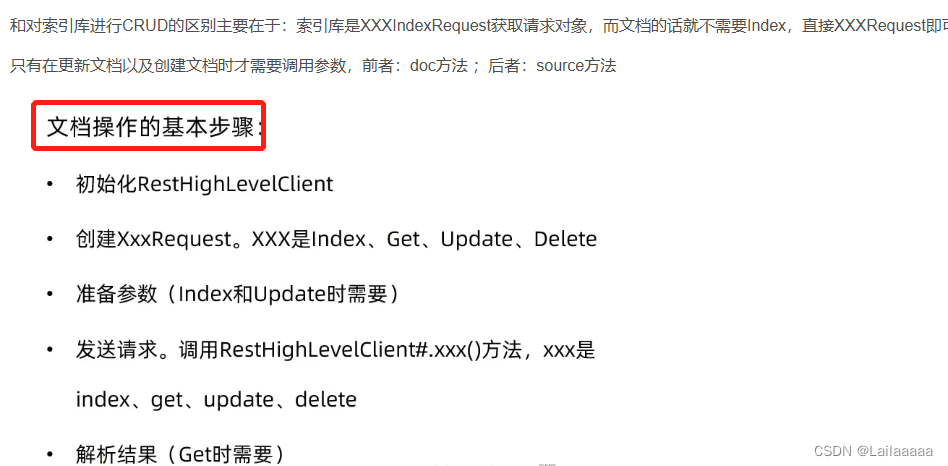
1.首先先初始化RestHighLevelClient:相当于es的客户端,可以利用它完成es的操作
2.创建索引库的请求:xxxIndexRequest,CREATE就是创建锁库,DELETE就是删除…
3.准备mappings,进行约束
4.发送请求,利用RestHighLevelClient.indices()得到索引库信息,里面封装了对于索引库的操作

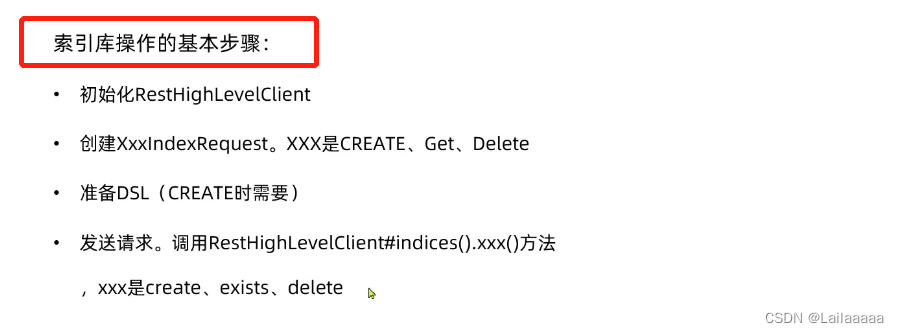
4、利用RestClient实现文档的CRUD

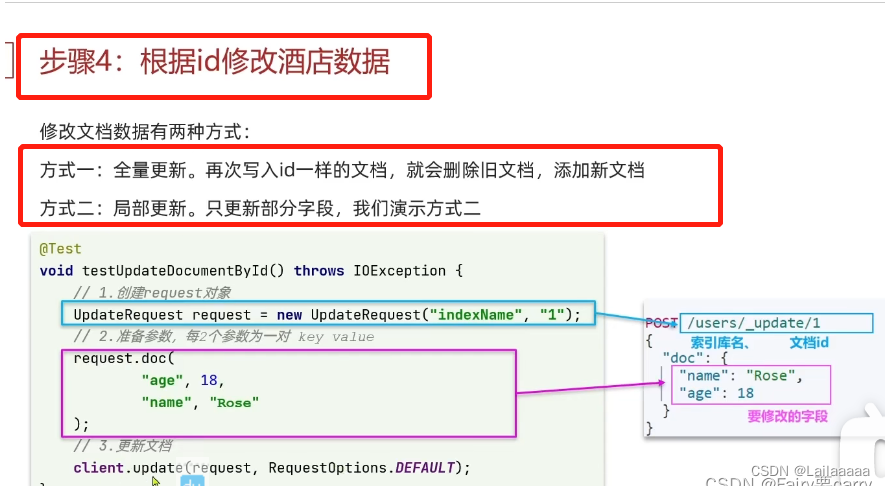
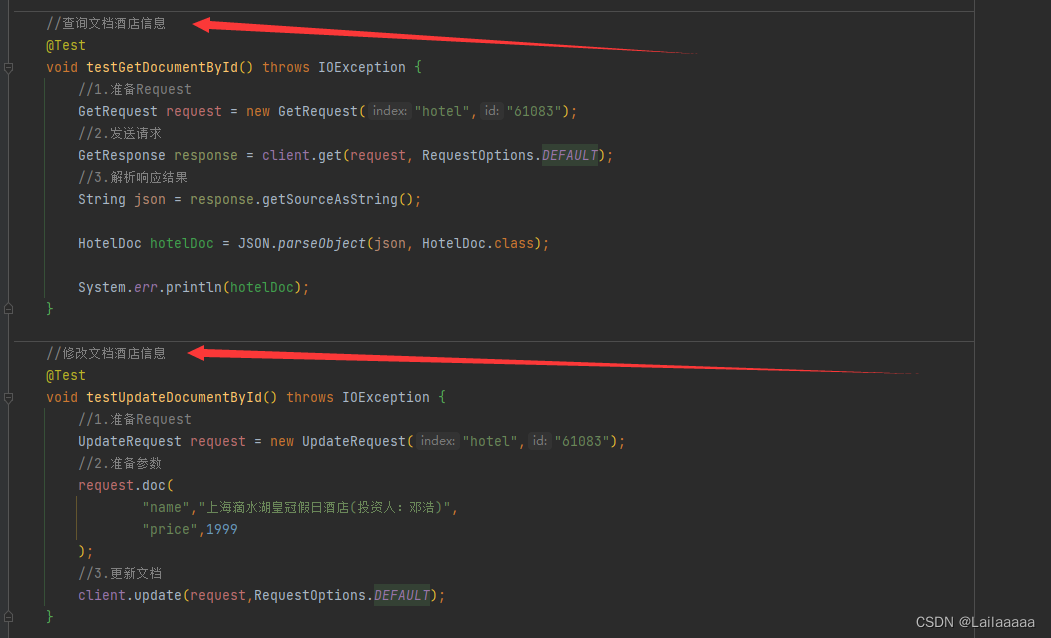
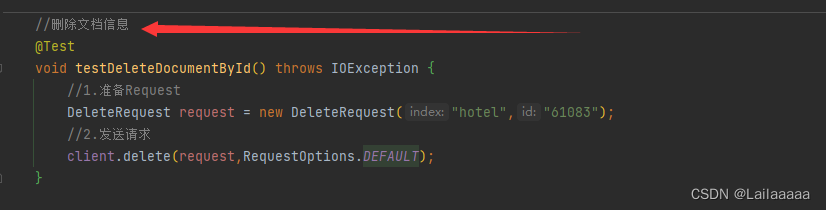
步骤:
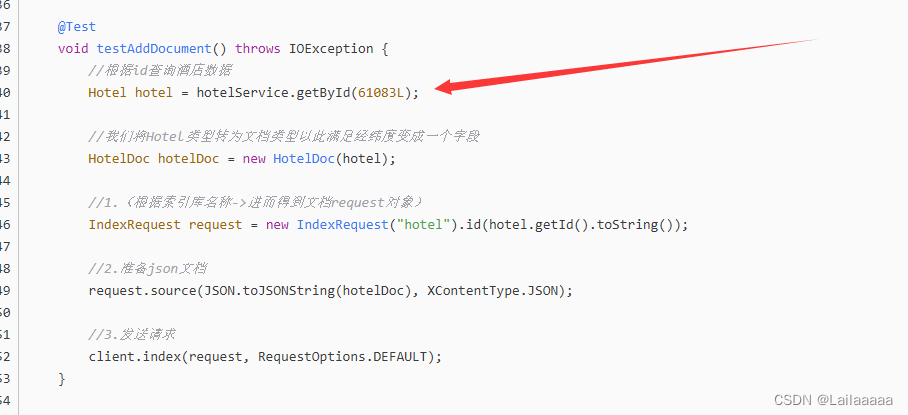
1.先查询得到酒店数据
2.因为es中的字段与数据库中酒店字段不一致,所以我们需要一个中间类去规范
3.得到request对象——>new IndexRequest(“hotel”).id(数据库中酒店id)
4.得到JSON文档——>request.source();
5.最后利用RestClient发出请求即可
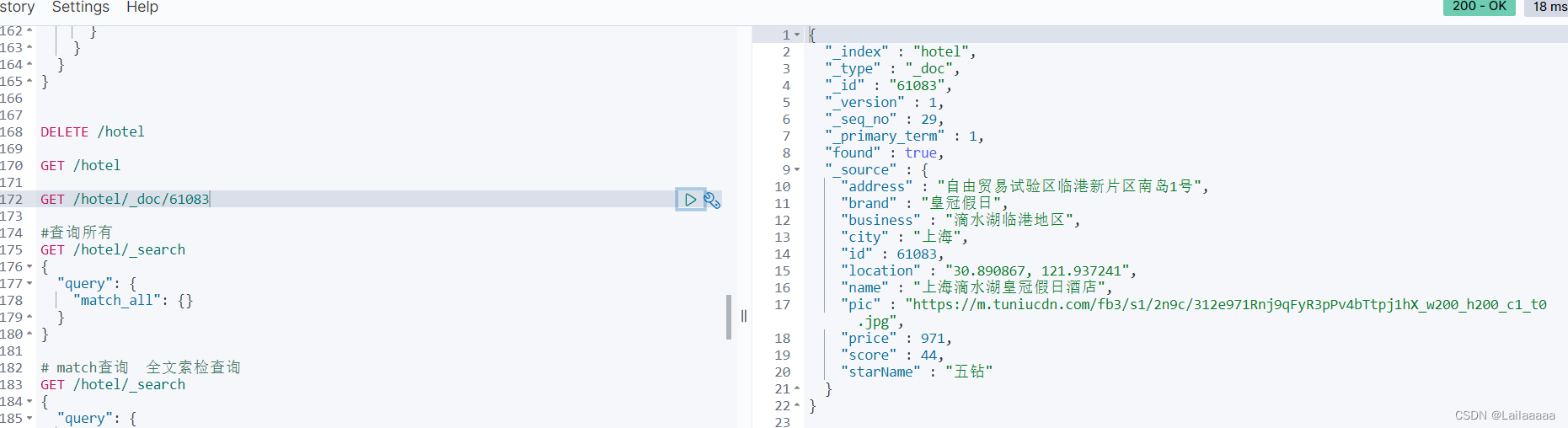
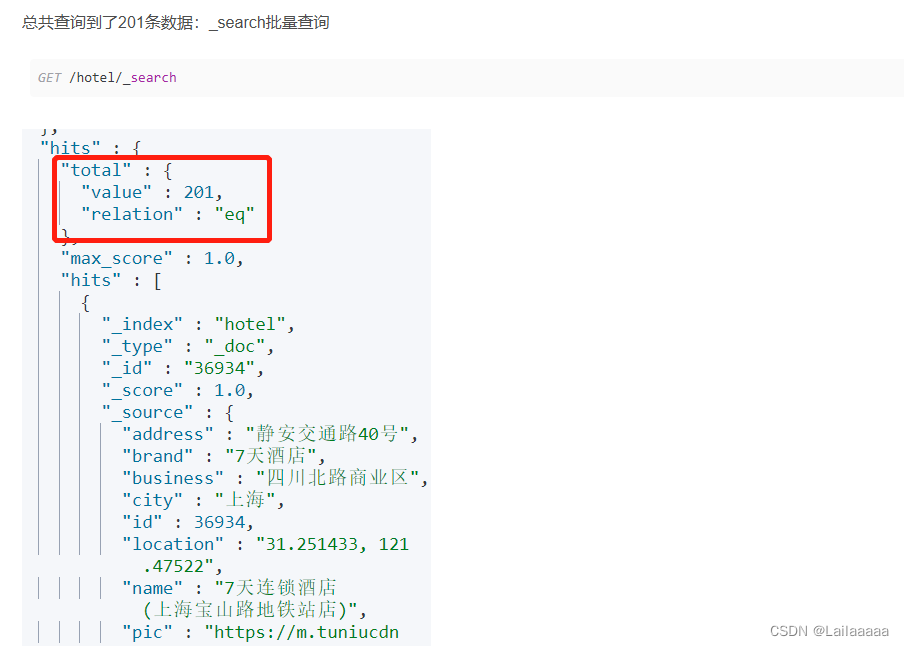
然后我们在Kibana中请求获取文档数据
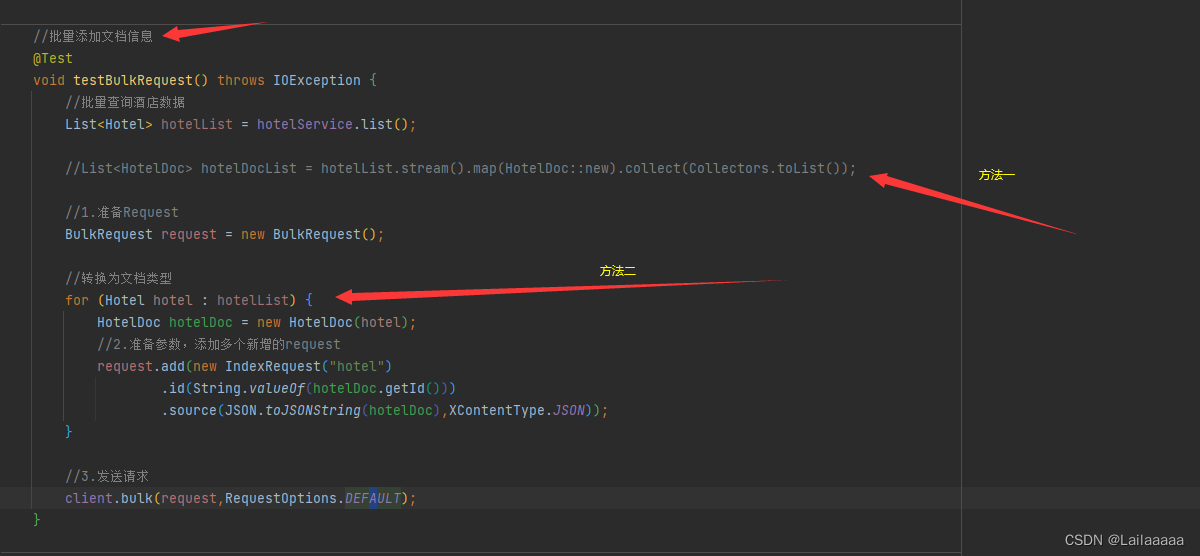
5、 批量导入功能







![数组(九)-- LC[316][321][402] 去除重复字母](https://img-blog.csdnimg.cn/e615e53a150d408ba816dd107293c694.gif#pic_center)