ES查询
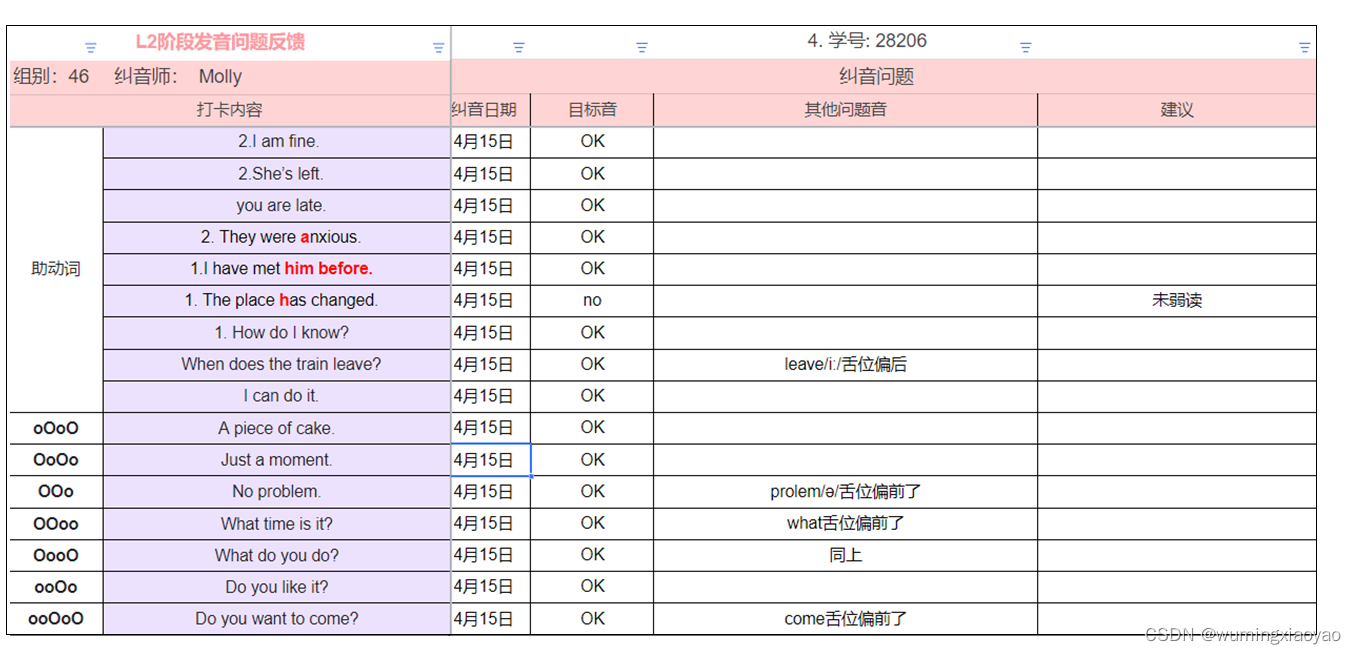
一般我们使用ES最多的就是查询,今天就讲一下ES的查询。这里我是建了一个person的索引。
"person" : {
"aliases" : { },
"mappings" : {
"properties" : {
"address" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"age" : {
"type" : "long"
},
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}基本查询操作
1.查询所有数据并进行排序
GET person/_search
{
"query":{
"match_all": {}
},
"sort":{
"age":"desc"
}
}说明:这里是一个GET请求,person代表索引,_search表示搜索(固定写法)。
"query"表示查询。“match_all”表示查询所有。后面的sort就表示要对查询结果进行排序。age 表示要排序的字段。而desc表示降序排序。asc升序排序。

结果说明:took表示查询花费时间(ms),_shards分片信息。搜索了多少个分片。hits查询结果,tatoal.value搜索到了几个文档。
2.分页查询
主要就是用到一个from(第几页),size(每页大小)。
GET person/_search
{
"query":{
"match_all": {}
},
"sort":{
"age":"desc"
},
"from":1,
"size":1
}3.查询段落匹配
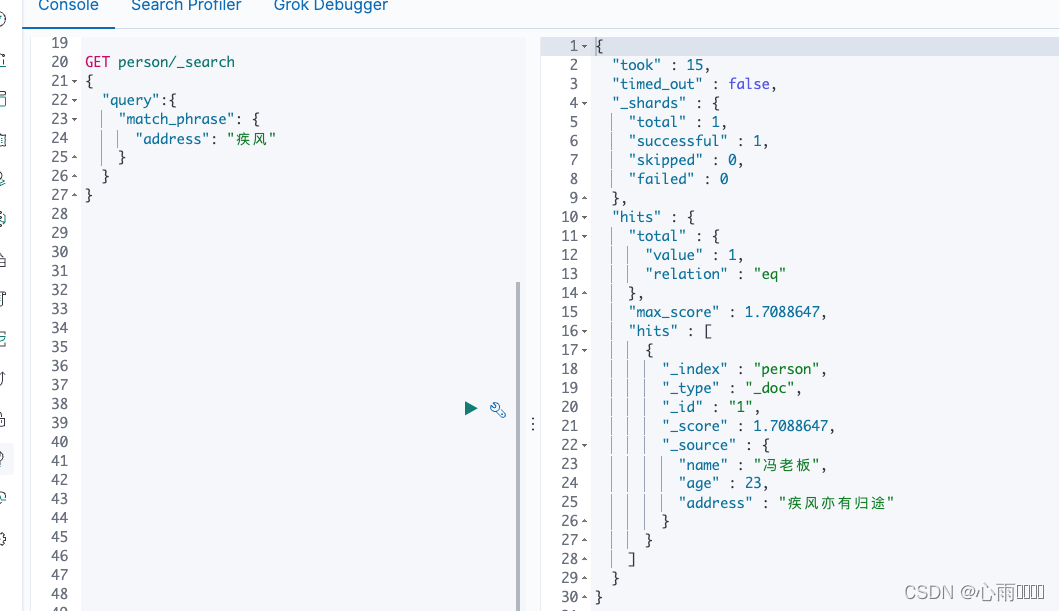
比如我们想查某个字段里面包好了某个字符串的话,就可以使用这种查询。比如我想查地址里面包含疾风的数据。
GET person/_search
{
"query":{
"match_phrase": {
"address": "疾风"
}
}
}
复合查询
1.多条件bool查询
通过布尔将较小的查询组合成大的查询。
如果存在多个查询条件就需要用到这种查询。比如我要查年龄为23岁,并且地址不在海南的人。这里查询注意格式,方括号大括号不能少,这是我觉得比较难受的一个点。
GET person/_search
{
"query":{
"bool":{
"must":[
{"match":{"age":"23"}}
],
"must_not": [
{"match": {
"address": "海南"
}}
]
}
}
}bool表示这是一个布尔查询,must和must_not表示必须满足和不满足,而里面的就是条件,必须匹配条件为年龄23,且地址不为海南的人。

特点:
-
子查询可以任意顺序出现。
-
可以嵌套多个查询,包括布尔查询
除了上面的must和must_not,还有should(选择性匹配至少满足一条),filter过滤,必须匹配。
全文搜索
1.Match类型
使用match全文搜索
GET person/_search
{
"query": {
"match": {
"name": "冯"
}
}
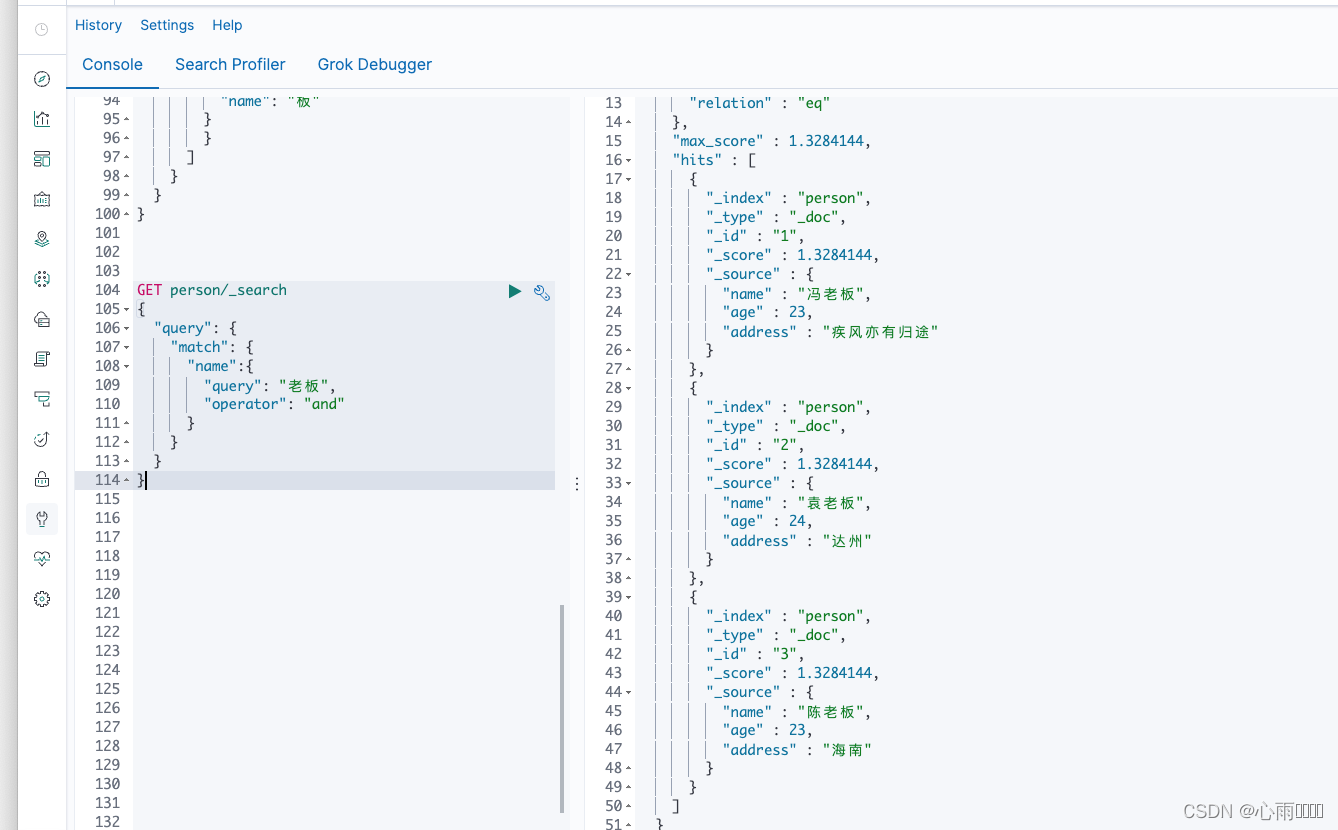
}这个查询首先回去判断name是text类型,text类型是会被分词的,那么查询字符串本身也会被分词。然后查询字符串会被传入标准分析器中,因为自由一个字所以这个查询的底层是单个的term查询。term查询会计算每个文档的相关度评分_score,如果是多个汉字是怎样?
GET person/_search
{
"query": {
"match": {
"name": "老板"
}
}
}结果:
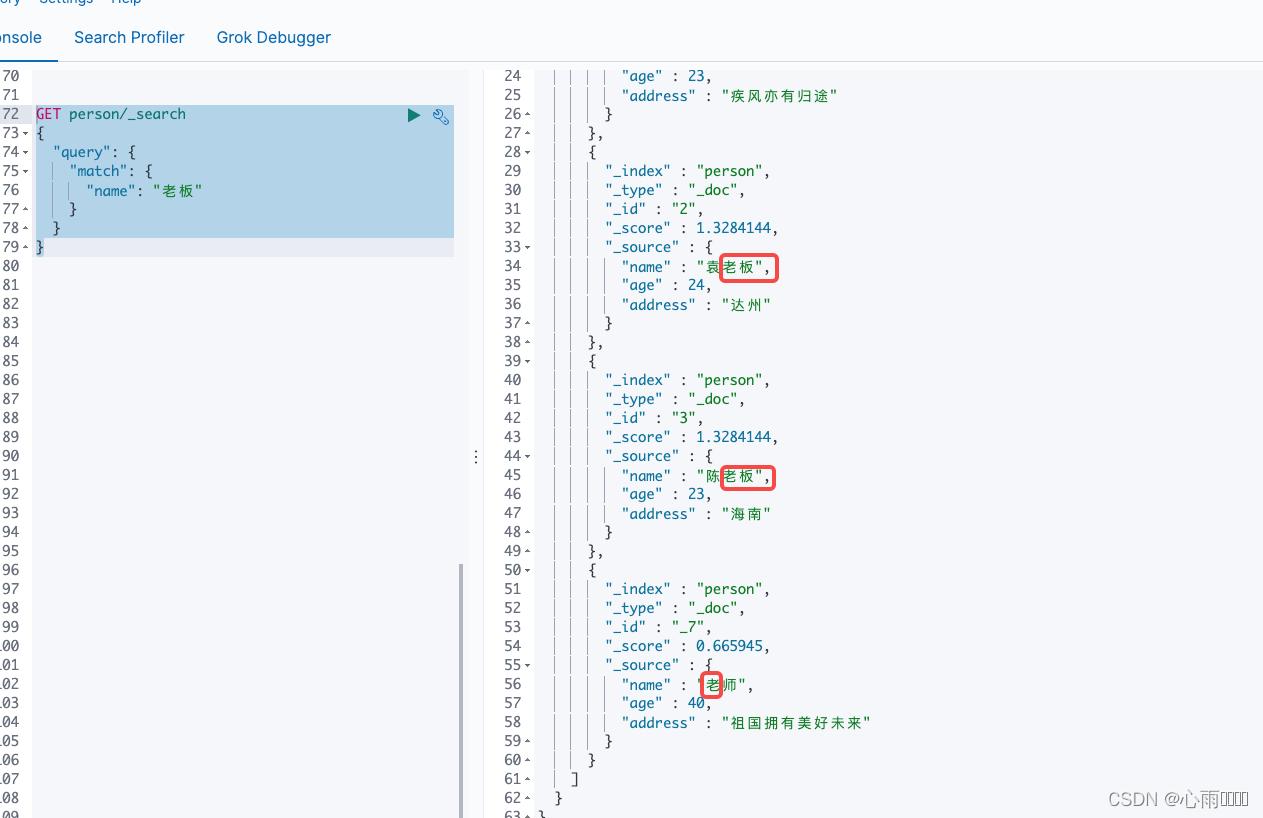
这里我并没有安装新的分词器,默认是一个汉字分成一个词。他可以等同如下查询:

他等同于should的两个term查询,只要满足任意一个就可以。其实match还有一个operator参数,默认是or,所以should也能查询出来,如果改成and就是需要同时满足.
 等同于:
等同于:

2.quert string类型
首先看例子
GET person/_search
{
"query": {
"query_string": {
"default_field": "address",
"query": " 疾风 OR 达州"
}
}
}
GET person/_search
{
"query": {
"query_string": {
"default_field": "address",
"query": "疾风 AND 归途"
}
}
}
上面两个查询仔细看很容易理解,query_string查询就是 根据运算符(and 或者 or)来解析和拆分字符串。然后查询在返回匹配的文档前独立分析每个拆分的文本。
除了这些查询外还有许多其他查询方式,这里这是讲了一种,以后再使用其他的时候可以对照理解。
term查询
1.基于单词的查询,基于id查询。
GET person/_search
{
"query": {
"ids":{
"values":[1,2,3]
}
}
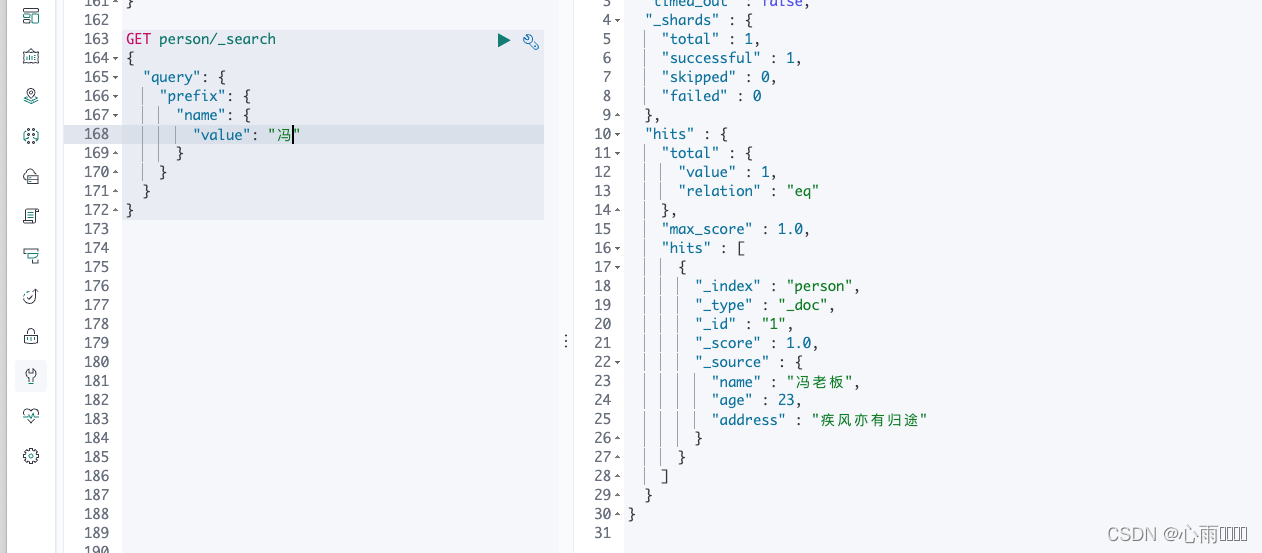
}2.通过前缀查询
GET person/_search
{
"query": {
"prefix": {
"name": {
"value": "冯"
}
}
}
}
3.分词匹配查询
GET person/_search
{
"query": {
"term": {
"name": {
"value": "老"
}
}
}
}
多个分词匹配
这里我之前在项目代码里面遇到过,查询对接人通过职位编码来进行匹配,利用了这种查询。还是比较多用的
GET person/_search
{
"query": {
"terms": {
"name": [
"冯",
"陈"
]
}
}
} 
4.通配符:wildcard
GET person/_search
{
"query": {
"wildcard": {
"name": {
"value": "冯*"
}
}
}
}范围查询
GET person/_search
{
"query": {
"range": {
"age": {
"gte": 20,
"lte": 30
}
}
}
}5.正则:regexp
get person/_search
{
"query":{
"regexp": {
"name": "冯*"
}
}
}6.模糊匹配:fuzzy
get person/_search
{
"query":{
"fuzzy": {
"address": {
"value": "疾"
}
}
}
}聚合查询
聚合查询就是类似我们在SQL中的group by。聚合查询中有两个概念,一个是桶:满足特定条件的文档的集合。还有一个是指标:就是对桶内的文档进行统计计算。所以在ES里面有三种聚合方式:
1.桶聚合
2.指标聚合
3.管道聚合
首先准备一批数据:
POST /test-agg-cars/_bulk
{ "index": {}}
{ "price" : 10000, "color" : "red", "make" : "honda", "sold" : "2014-10-28" }
{ "index": {}}
{ "price" : 20000, "color" : "red", "make" : "honda", "sold" : "2014-11-05" }
{ "index": {}}
{ "price" : 30000, "color" : "green", "make" : "ford", "sold" : "2014-05-18" }
{ "index": {}}
{ "price" : 15000, "color" : "blue", "make" : "toyota", "sold" : "2014-07-02" }
{ "index": {}}
{ "price" : 12000, "color" : "green", "make" : "toyota", "sold" : "2014-08-19" }
{ "index": {}}
{ "price" : 20000, "color" : "red", "make" : "honda", "sold" : "2014-11-05" }
{ "index": {}}
{ "price" : 80000, "color" : "red", "make" : "bmw", "sold" : "2014-01-01" }
{ "index": {}}
{ "price" : 25000, "color" : "blue", "make" : "ford", "sold" : "2014-02-12" }1.标准聚合
比如说我们想得到每个颜色的销量
GET test-agg-cars/_search
{
"size":0, //siz指定为0,hits不会返回搜索结果
"aggs": { //聚合查询
"pop_colors": { //为聚合查询的结果指定一个想要的名称
"terms": { //定义桶的类型为terms(桶:满足特定条件的文档集合)
"field": "color.keyword" //每个桶的key都与color字段里找到的唯一词对应
}
}
}
}查询结果:

doc_count告诉我们每个包含该词项的文档数量。
2.多个聚合
计算两种桶的结果
GET /test-agg-cars/_search
{
"size": 0,
"aggs":{
"pop_colors":{
"terms": {
"field": "color.keyword"
}
},
"make_by":{
"terms": {
"field": "make.keyword"
}
}
}
}查询结果

3.聚合嵌套
比如我们要查询每种颜色的平均价格,首先使用聚合查询每种颜色,然后再嵌套一个聚合查询每种颜色的平均价格。
GET test-agg-cars/_search
{
"size": 0,
"aggs": {
"colors": {
"terms": {
"field": "color.keyword"
},
"aggs":{
"avg_price":{
"avg": {
"field": "price"
}
}
}
}
}
}查询结果:
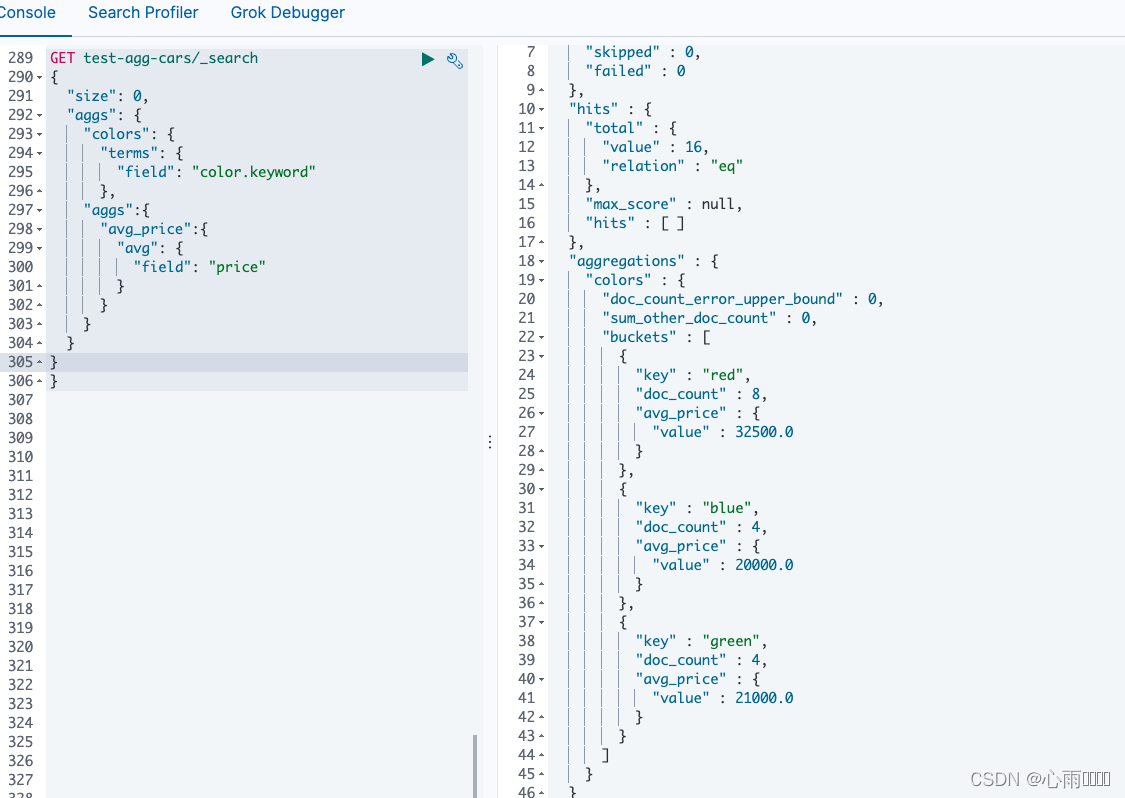 4.前置过滤条件:filter
4.前置过滤条件:filter
比如我们只想查某一个类型的平均价格,可以先使用filter过滤出来,然后再使用一个嵌套聚合计算平均价格。
GET test-agg-cars/_search
{
"size": 0,
"aggs":{
"make_by":{
"filter": {
"term": {
"make": "honda"
}
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}查询结果:
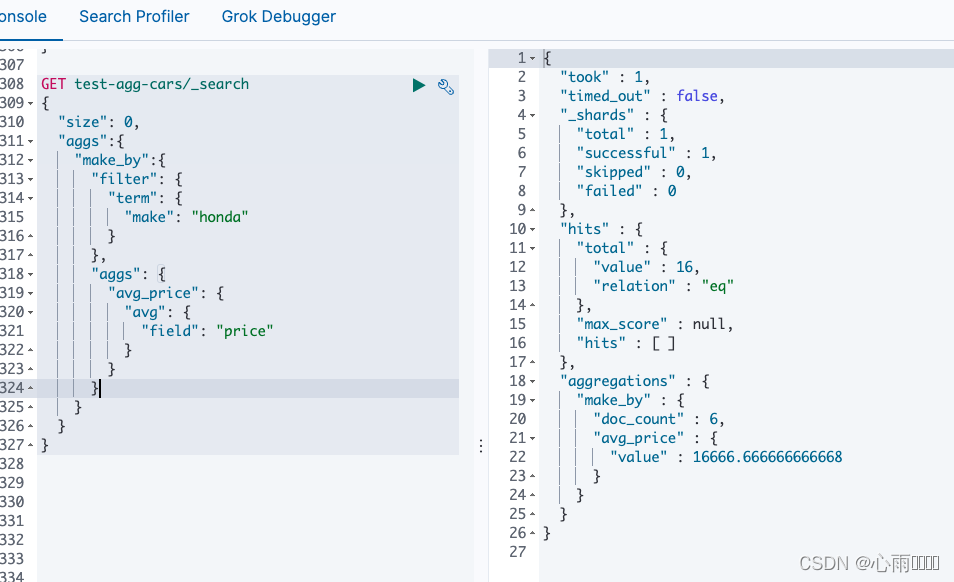 5.对number类型聚合:range
5.对number类型聚合:range
查询某一个范围。
{
"size":0,
"aggs": {
"price_ranges": {
"range": {
"field": "price",
"ranges": [
{
"from": 10000,
"to": 15000
}
]
}
}
}
}结果:
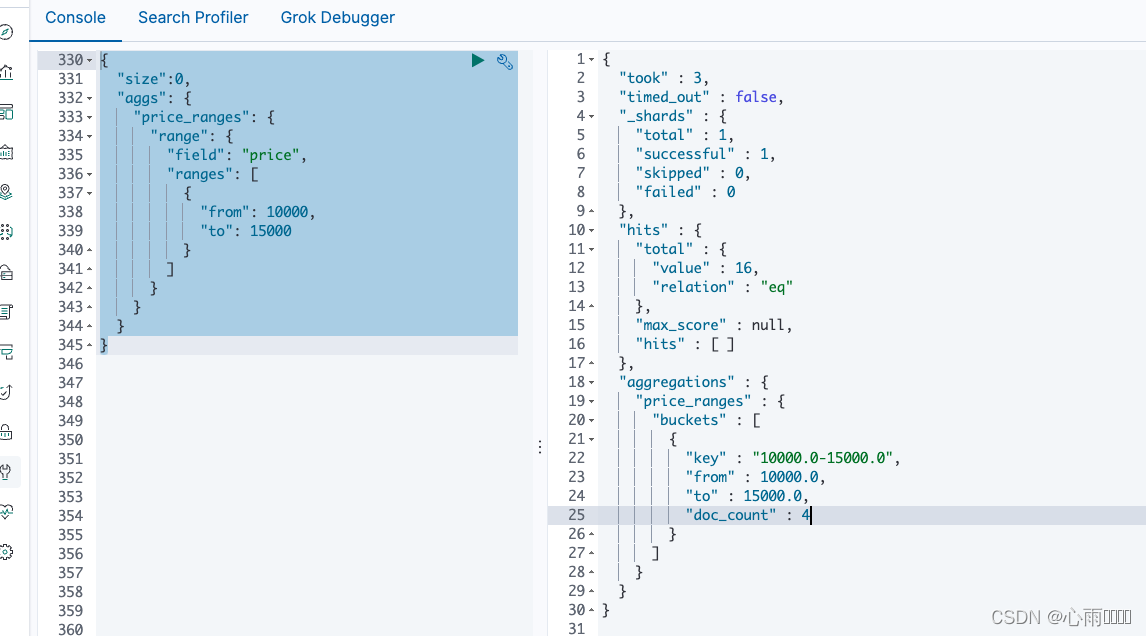 6.对日期类型聚合
6.对日期类型聚合
我觉得这种聚合查询应用的场景会比较多。查询某个时间范围内的数据。
GET test-agg-cars/_search
{
"size":0,
"aggs": {
"range": {
"date_range": {
"field": "sold",
"ranges": [
{
"from": "2014-10-28",
"to": "2014-11-05"
}
]
}
}
}
}结果:
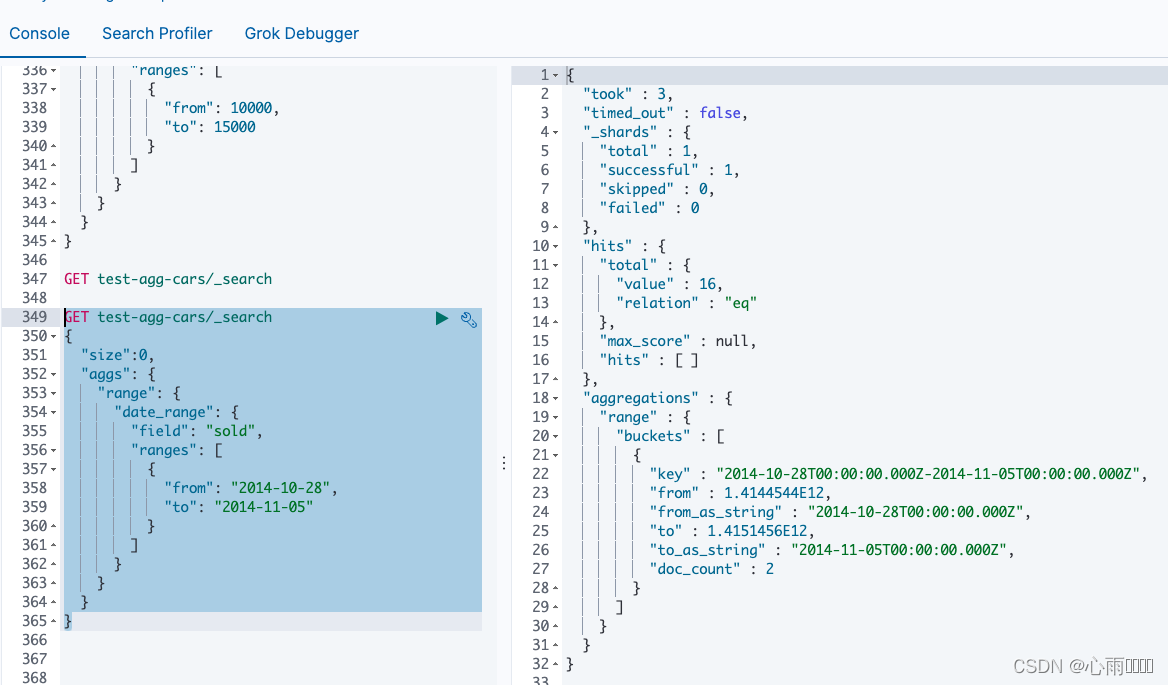
聚合查询之metric聚合
metric聚合从分类上来看,可以分为单值分析和多值分析。
-
单值分析就是只输出一个分析结果,标准的stat型。
1.avg 平均值
2.max 最大值
3.min 最小值
4.sum 和
5.value_count 数量
其他类型 cardinality记述(distinct去重),weighted_avg 带权重的avg。。。
-
多值分析
省略,因为我觉得不是很常用,到时候会查文档就行。
单值分析
avg平均值:计算平均值
GET person/_search
{
"size": 0,
"aggs":{
"avg_age":{
"avg": {
"field": "age"
}
}
}
}
//返回结果
"aggregations" : {
"avg_age" : {
"value" : 30.857142857142858
}
}max最大值:
GET person/_search
{
"size":0,
"aggs": {
"max_age": {
"max": {
"field": "age"
}
}
}
}
//返回结果
"aggregations" : {
"max_age" : {
"value" : 40.0
}min最小值:与最大值类似
sum求和:
GET person/_search
{
"size":0,
"aggs": {
"sum_age": {
"sum": {
"field": "age"
}
}
}
}
//返回结果
"aggregations" : {
"sum_age" : {
"value" : 216.0
}
}Value_count数量
GET person/_search?size=0
{
"aggs": {
"name_count": {
"value_count": {
"field": "age"
}
}
}
}
//返回结果
"aggregations" : {
"sum_age" : {
"value" : 216.0
}
}目前就简单介绍了这些查询,其实在es官网可以看到很多不同的查询,包括管道啥之类的,但是我们以后使用的时候要知道大致的查询分为哪几类,然后每种查询得能在官网快速定位,然后通过例子学会使用并理解。
![[LeetCode周赛复盘] 第 102 场双周赛20230415](https://img-blog.csdnimg.cn/79f5b2b669354d7c8bdad400c5e70b6d.png)