在之前的文章 “Elasticsearch:集群管理” ,我们对集群管理做了一些介绍。在今天的文章中,我们接着来聊一下有关配置的方面的问题。这在很大程度上取决于你的用例,是索引还是搜索繁重。 我们将在这里讨论在集群设置方面我们需要关注的最佳实践是什么。
避免脑裂
在一个由多个 master 符合条件的节点组成的集群中,我们总是担心,如果网络出现分区或不稳定,那么集群会意外地选举出多个 master,这被称为 “脑裂” 场景。 因此,为了避免这种情况,我们至少需要最少的主节点投票才能赢得主节点选举。 创建 3 个专用主节点。
Elasticsearch 要求半数 +1 的符合主节点资格的节点必须投票选举新的主节点,从而避免了这种情况。 因此,强烈建议使用 3 个节点来提供能够失去 1 个主节点并保持稳定的结构。
注意:集群在负载过重时会变得不稳定。
如果主节点除了其常规任务之外还必须执行索引和搜索操作,它可能最终没有足够的资源来执行和监视对集群稳定性至关重要的其他操作,例如创建或删除索引,决定哪些分片应该 分配到哪些节点上,并在每个节点上维护集群状态。
主节点通常比数据节点需要更少的资源。 在其余节点上将 node master 设置为 false。
node.master: false更多阅读,请参考文章 “Elasticsearch:理解 Master,Elections,Quorum 及 脑裂”。
JVM heap 大小设置
Elasticsearch 和 Lucene 是用 Java 编写的,我们需要调整最大堆空间和 JVM 统计信息。 需要注意的是,Elasticsearch 可用的堆越多,它可以用于过滤、缓存和其他进程以提高查询性能的内存就越多。 此外,过多的堆空间会导致大量垃圾回收。
将 Xms 和 Xmx 设置为不超过总内存的 50%。 Elasticsearch 需要内存用于 JVM 堆以外的用途。 例如,Elasticsearch 使用堆外缓冲区来实现高效的网络通信,并依赖于操作系统的文件系统缓存来实现对文件的高效访问。
禁用交换
操作系统尝试将尽可能多的内存用于文件系统缓存,并急切地换出未使用的应用程序内存。 当操作系统决定这样做时,Elasticsearch 性能可能会受到严重影响,因为它甚至可以将 Elasticsearch 可执行页面换出磁盘。 禁用操作系统级交换并启用内存锁可以帮助我们避免这种情况。
Just add the below in your elasticsearch.yml file.
Set bootstrap.memory_lock: true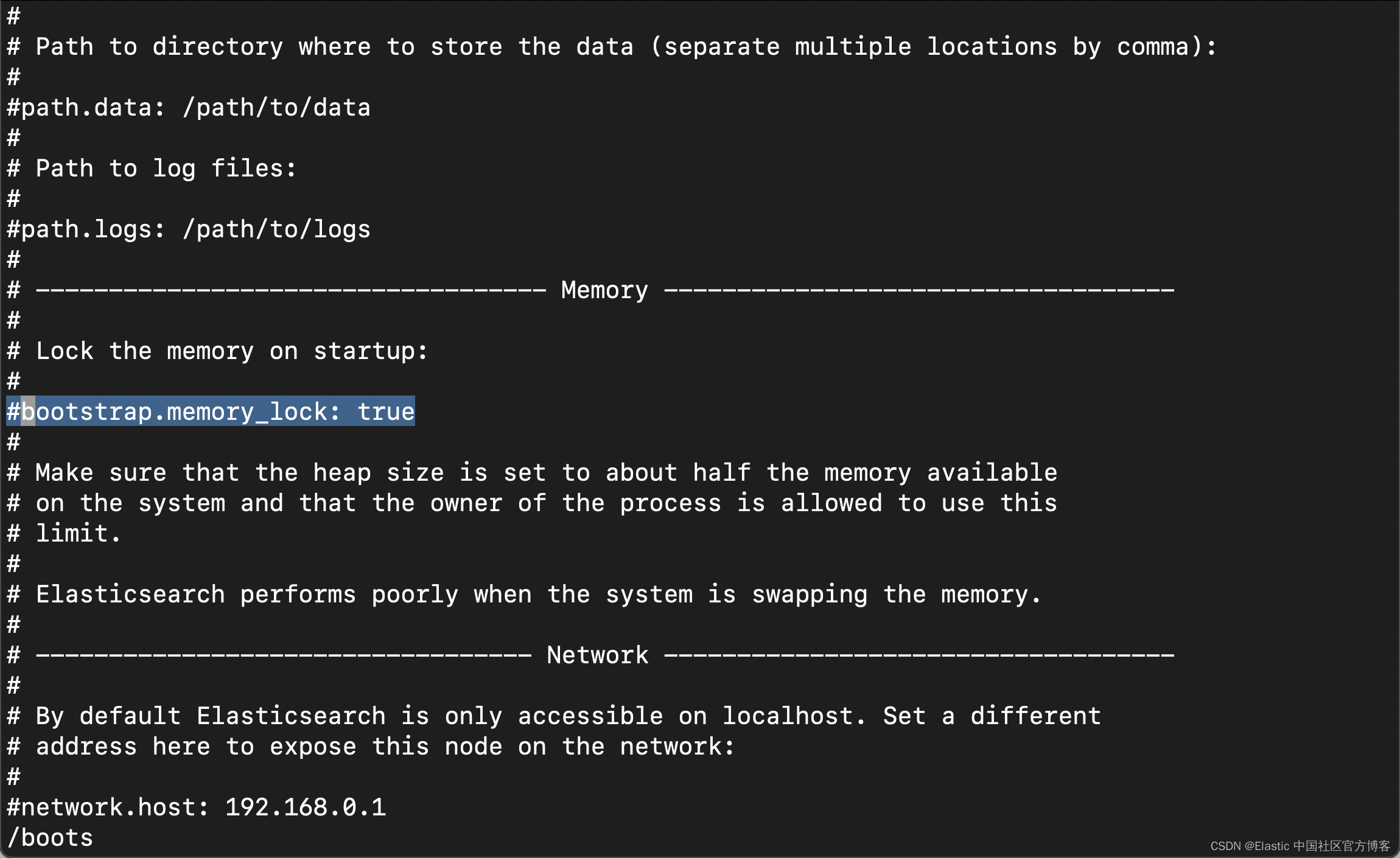
虚拟内存调整
Elasticsearch 默认使用 mmaps 目录来存储其索引。 默认操作系统限制 mmap 计数并且可能太低,这可能导致内存不足异常。 因此,为避免虚拟内存耗尽,请增加对 mmap 计数的限制。
/etc/sysctl.conf file
Set vm.max_map_count=262144注意:通常情况下,deb 及 rpm 安装包可以帮我们自动配置这些。我们不需要手动来配置,但是当我们使用解压缩包的情况下来进行安装,那么我们需要进行手动配置。详细情况,请参考文章链接 “如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch”。
打开文件描述符限制
确保将运行 Elasticsearch 的用户的打开文件描述符数量限制增加到 65,536 或更高。
You can get from:
http://IP:PORT/_nodes/stats/process?filter_path=**.max_file_descriptorsGET _nodes/stats/process?filter_path=**.max_file_descriptors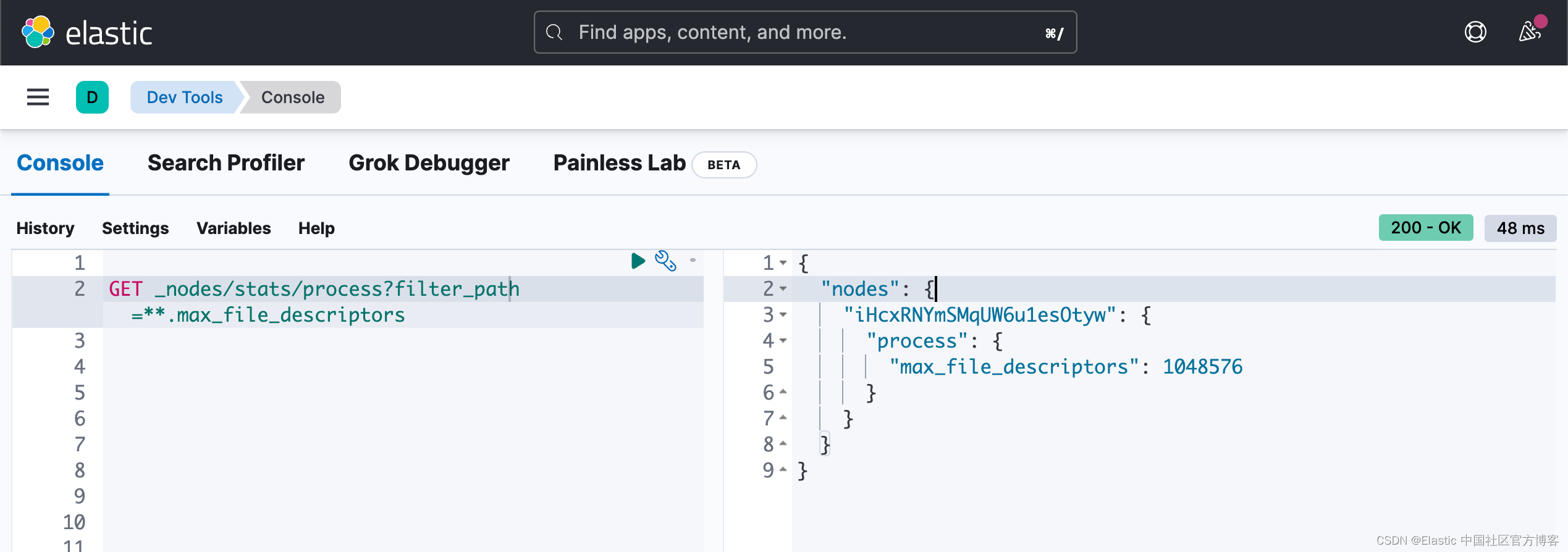
我们可以在如下的文件中进行设置:
set nofile to 65535 in /etc/security/limits.conf禁用通配符
由于无法检索从 Elasticsearch 集群中删除的数据,因此要确保有人不会对所有索引(* 或 _all)发出 DELETE 操作,请禁用通过通配符查询删除所有索引。
Set action.destructive_requires_name to true我们可以通过如下的命令来进行设置:
PUT /_cluster/settings
{
"transient": {
"action.destructive_requires_name":true
}
}如果你想设置为允许,你可以通过如下的命令来进行设置:
PUT /_cluster/settings
{
"transient": {
"action.destructive_requires_name":false
}
}Elasticearch 分片大小
分片大小没有硬性限制,但经验表明,10GB 到 50GB 之间的分片通常适用于日志和时间序列数据。 它的大小太大会在节点发生故障时花费太多时间来恢复,Elasticsearch 会在数据层的剩余节点之间重新平衡节点的分片,并且也需要时间来运行,但这并不意味着较小的分片在所有情况下都表现良好。
更多信息,请详细阅读 “Elasticsearch:我的 Elasticsearch 集群中应该有多少个分片?”。
垃圾收集器
Old generation 收集暂停发生在重负载下,此时所有去往该节点上分片的请求都被冻结,直到垃圾收集完成。 在繁重的索引负载下,这些集合可能需要几秒钟或更长时间。
Elasticsearch 中的默认垃圾收集器是 Concurrent Mark and Sweep (CMS)。 直到 old generation 的收集器占用率达到 CMSInitiatingOccupancyFraction 中设置的值,CMS才会启动。 当此值过高时会出现问题,从而导致 GC 延迟。 将会有很多长寿命对象,这意味着 CMS 将需要更多时间来清除 old generation。 较新版本的 Java 中最近的 GC 选项是 Garbage First Garbage Collector (G1GC),它旨在最大限度地减少垃圾收集器必须停止所有应用程序线程的时间。 G1GC 将堆分成更小的区域,每个区域可以是年轻代或老年代。 GC 可以决定分析有更多垃圾的区域,通过避免一次收集整个老年代来减少 GC 暂停时间。 查看分片的当前大小
查看分片的当前大小:
http://IP:PORT/_cat/shards?v=true&h=index,prirep,shard,store&s=prirep,store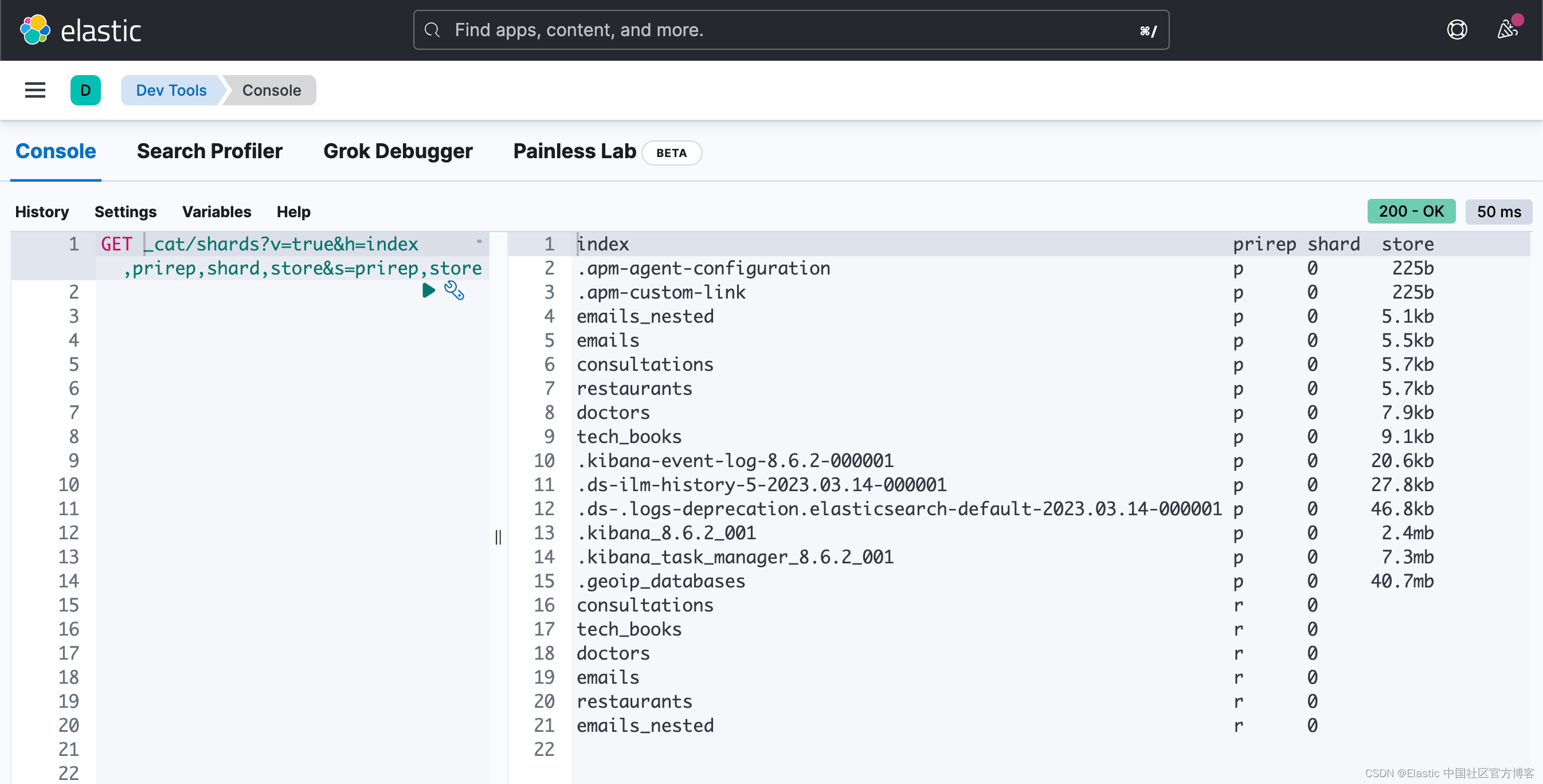
查看每个节点的分片数:
http://IP:PORT/_cat/shards?v=true
获取集群设置:
http://IP:PORT/_cluster/settings?pretty&include_defaults
检查节点统计信息:
http://IP:PORT/_nodes/stats?metric=adaptive_selection,breaker,discovery,fs,http,indices,jvm,os,process,thread_pool,transport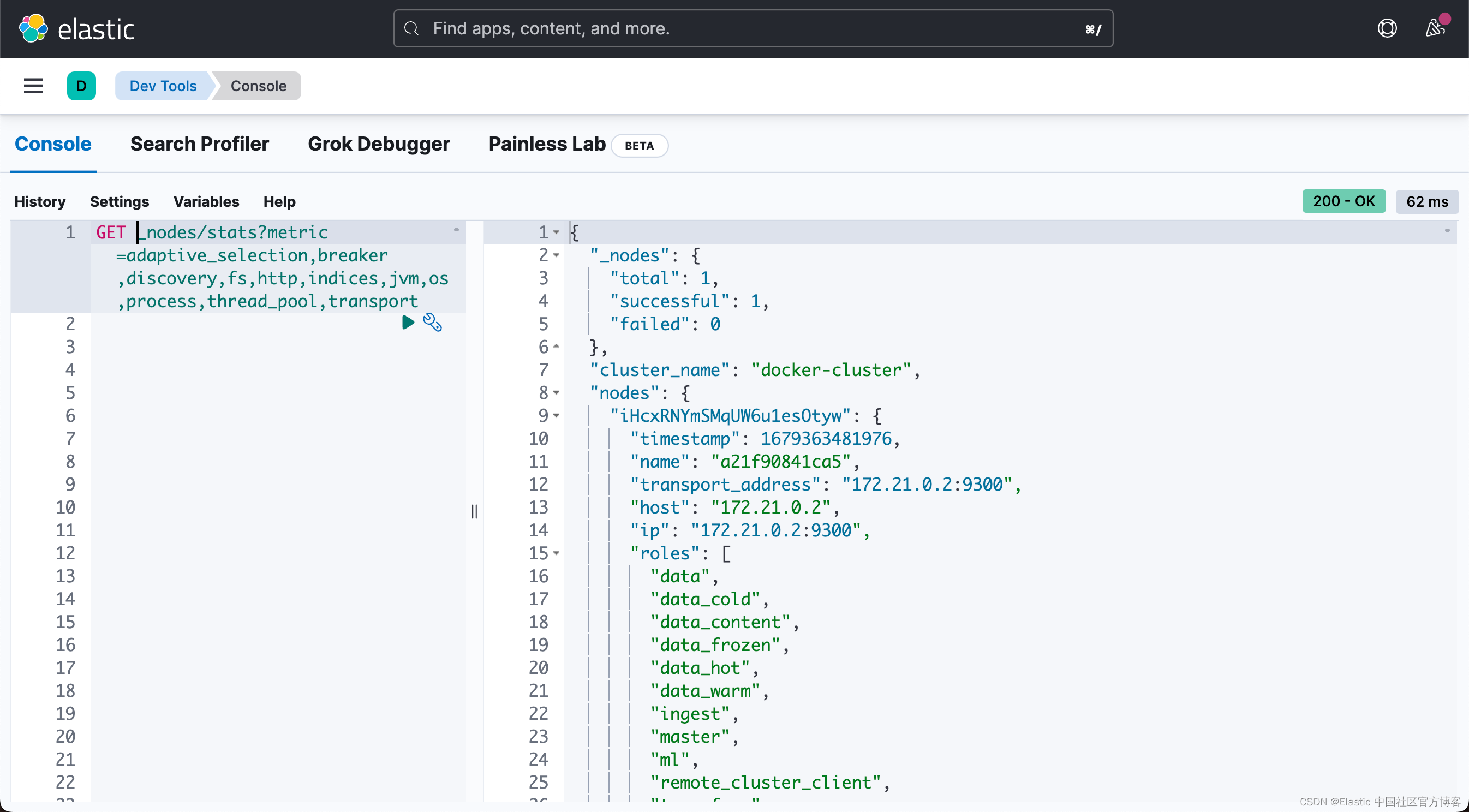




![[ 应急响应基础篇 ] 使用 Autoruns 启动项分析工具分析启动项(附Autoruns安装教程)](https://img-blog.csdnimg.cn/6c995927a42a4e7f972f5914e33f2050.png)