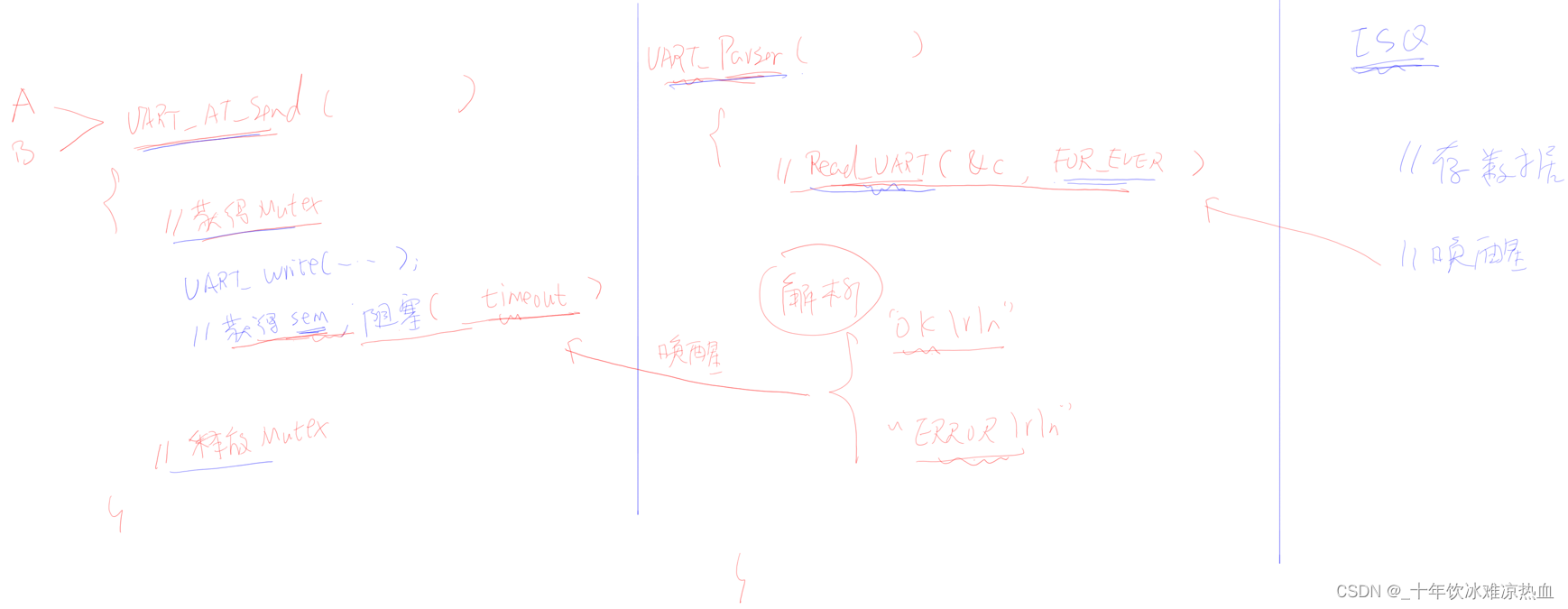
之前几篇我们一直在研究如何从网站上快速、方便的获取数据,并将获取到的数据存储在数据库中。但是将数据存储在数据中并不是我们的目的,获取和存储数据的目的是为了更好的利用这些数据,利用这些数据的前提首先需要从数据库按一定的格式来读取数据,这一篇主要介绍如何实现通过 RESTful API 来获取数据库中的数据。
好吧,废话有点多,到此介绍吧,接来下进入技术细节。

RESTful 是一种软件架构风格、设计风格,而不是标准,只是提供了一组设计原则和约束条件。它主要用于客户端和服务器交互类的软件。基于这个风格设计的软件可以更简洁,更有层次,更易于实现缓存等机制。
匹配REST设计风格的Web API称为RESTful API。它从三个方面资源进行定义。第一,直观简短的资源地址:URI;第二,传输的资源:Web服务接受与返回的互联网媒体类型,比如:JSON,XML,YAML等;第三,对资源的操作:Web服务在该资源上所支持的一系列请求方法(比如:POST,GET,PUT或DELETE)。
实现 RESTful API 需要先实现一个 web 服务器,在本篇中我们通过已有的框架 Flask 来实现 web 服务器,然后在 Flask 的基础上连通数据库,实现 RESTful API 的访问。
至于 Flask 框架在这里就不做介绍了「其实是我自己也不太懂」,但是你可以在这里https://dormousehole.readthedocs.io/en/latest/index.html 获取更多信息。
建立 Flask 基础服务
Flask 是一个轻量级的 Web 应用框架。通过 Flask 来实现一个 Web 服务非常简单,简单到只需要五行代码。
from flask import Flask
app = Flask(__name__)
@app.routr('/')
def hello_world():
return 'Hello World!'
上面使用 Flask 的一个最简单的示例,我们的示例没有这么简单,但是也差不多:)。在这个示例中我们需要创建一个 Flask 的实例、初始化数据库控制和 API 控制框架。代码如下:
from flask import Flask
import logging
from .module import (
db,
api,
)
logger = logging.getLogger(__name__)
def create_app(config=None):
app = Flask(
'pycrawler', instance_relative_config=True
)
config_app(app, config)
configure_module(app)
return app
def config_app(app, config):
app.config.from_object("pycrawler.configs.default.DefaultConfig")
def configure_module(app):
# initialization database
db.init_app(app)
api.init_app(app)
在程序中通过 app.config.from_object 从配置文件中读取相关的配置内容,在配置文件中完成数据及 flask 的配置。
数据库初始化及数据类型的实现
我们使用 Flask 的扩展 Flask-sqlalchemy 来实现数据的操作。
Flask-SQLAlchemy 是一个为您的 Flask 应用增加 SQLAlchemy 支持的扩展,它致力于简化在 Flask 中 SQLAlchemy 的使用,提供了有用的默认值和额外的助手来更简单地完成常见任务。
flasksqlalchemy 的使用非常的简单,仅仅需要简单的初始化,然后在配置文件加入数据库的 URI 配置即可实现数据库的 CRUD。在这个示例中我们在两个地方对 flasksqlalchemy 进行初始化。
首先是初始化 SQLAlchemy 本身,初始化代码如下:
from flask_sqlalchemy import SQLAlchemy
from sqlalchemy import MetaData
from flask_restful import Api
metadata = MetaData(
naming_convention={
"ix": "ix_%(column_0_label)s",
"uq": "uq_%(table_name)s_%(column_0_name)s",
"fk": "fk_%(table_name)s_%(column_0_name)s_%(referred_table_name)s",
"pk": "pk_%(table_name)s",
}
)
db = SQLAlchemy(metadata=metadata)
其次是将 flask 的实例传入给 flask_sqlchemy。代码如下:
# initialization database
db.init_app(app)
最后在配置文件中增加 SQLAlchemy 的配置选项。
#Database
# For SQLite:
SQLALCHEMY_DATABASE_URI = 'sqlite:///' + basedir + '/' + \
'prcrawler-web.sqlite'
# This option will be removed as soon as Flask-SQLAlchemy removes it.
# At the moment it is just used to suppress the super annoying warning
SQLALCHEMY_TRACK_MODIFICATIONS = False
# This will print all SQL statements
SQLALCHEMY_ECHO = False
做完上面的工作以后,数据库已经可以正常的工作起来,可以开始着手实现数据模型,我们需要连接到前面爬虫存储数据的数据库,因此需要维持两个数据模型的一致,这里就不再贴出数据模型的代码了。
RESTful API 的实现
在这里使用 flask-restful 扩展来实现 RESTful API。flask-restful 的初始同 flask-sqlalchemy 的初始化方法相同。
#创建 api 的实例
api = Api()
#向 api 实例传入 flask 实例
api.init_app(app)
flask-restful 初始完成后,即可建立 api 的类,以获取一个元件的信息为例来介绍 api 的建立过程。
from flask_restful import Resource, reqparse
from sqlalchemy import func
from pycrawler.module import db, api
from pycrawler.material.models import Brands, Materials, Price
from flask import jsonify
class CrawlerApi(Resource):
def get(self, id):
material = db.session.query(Materials).filter(Materials.id==id).first()
if material is not None:
return material.to_json()
return '', 404
api.add_resource(CrawlerApi, '/api/v0.1/crawler/material/<int:id>')
在 add_resource 中我们设置 API 的路径为 /api/v0.1/crawler/material/id 可以通过该 API 来获取固定 id 的元件的信息。在类 CrawlerApi 中我们实现了一个 get 函数,该函正如其名对应了 http 的 get 方法,除了 get 方法我们还能够以相同的方法来实现 post、put、patch、delete 等方法。在 get 函数中,通过传入的 id 编号,从数据库中读出该元件的完整信息,并转换为 json 数据返回给客户端,当 id 不存在是将返回一个 404 错误。
在 add_resource 中将 id 设置为一个整数,在 get 函数中传入的 id 参数即为一个整数,当然我们也可以设置为字符串类型。
完成以上代码后,我们可以通过以下命令来获取 id 为 100 的元件的信息。
curl http://127.0.0.1:5000/api/v0.1/crawler/material/100
完整的代码可以通过 api 来访问所有的元件信息、生产商信息,并可以查看同一个生产商所生产的所有元件。完整的代码可以在 GitHub 上搜索 keinYe 查看。
![[ 应急响应基础篇 ] 使用 Autoruns 启动项分析工具分析启动项(附Autoruns安装教程)](https://img-blog.csdnimg.cn/6c995927a42a4e7f972f5914e33f2050.png)